基于深度学习的三维脸部重建的系统的制作方法
1.本发明关于脸部重建,特别是一种基于深度学习的三维脸部重建的系统。
背景技术:
2.计算机视觉中的三维人脸重建技术及表情跟踪技术都是获取及建立人脸脸型及外表的程序,应用于人脸识别及表情驱动等领域。现有的三维人脸重建技术及表情跟踪技术普遍存在重建精度不高,表情区分性不大的问题,需要对重建后的影像进一步处理才能获得准确的三维重建影像。
技术实现要素:
3.本发明实施例提供一种基于深度学习的三维脸部重建的系统,包括主要彩色深度相机、多个辅助彩色相机、处理器及内存。主要彩色深度相机设置于正视角位置,用以从正视角位置获取参考用户的主要彩色影像及主要深度影像。多个辅助彩色相机设置于多个侧视角位置,用以从多个侧视角位置获取参考用户的多个辅助彩色影像。处理器耦接于主要彩色深度相机及多个辅助彩色相机。内存耦接于处理器,储存有多个指令。处理器执行多个指令以依据主要彩色影像及主要深度影像建立基准真相(ground truth)三维模型的正视角三维影像;依据正视角三维影像及多个辅助彩色影像生成基准真相三维模型的多个侧视角三维影像;及依据训练影像及基准真相三维模型训练人工神经网络模型。
附图说明
4.图1是本发明实施例中一种三维脸部重建系统的方块图。
5.图2是图1的系统中主要彩色深度相机及辅助彩色相机的设置的示意图。
6.图3是图1的系统中人工神经网络模型的训练方法的流程图。
7.图4是图3的步骤s302的流程图。
8.图5是图3的步骤s304的流程图。
9.图6是图3的步骤s306的流程图。
10.图7是图4的步骤s404的流程图。
11.图8是步骤s602中之裁剪后训练影像的示意图。
12.图9是图1的系统中的人工神经网络模型的示意图。
13.图10是使用图1中训练完成的人工神经网络模型的三维影像重建方法的流程图。
14.其中,附图标记说明如下:
15.1:三维脸部重建系统
16.10:处理器
17.100:人工神经网络模型
18.102:三维变形模型
19.104:基准真相三维模型
20.12:内存
21.14:主要彩色深度相机
22.16(1)至16(n):辅助彩色相机
23.18:显示器
24.19:影像传感器
25.300:训练方法
26.s302至s306,s402至s406,s502至s508,s602至s608,s702至s722,s1002至s1008:步骤
27.900:第一阶段
28.902:第二阶段
29.904:第三阶段
30.906:第四阶段
31.908:全连接阶段
32.910:卷积阶段
33.912:全连接阶段
34.1000:三维影像重建方法
35.ip:主要彩色影像
36.is(1)至is(n):辅助彩色影像
37.dp:主要深度影像
38.r:参考使用者
39.tex:表情系数
40.tid:脸型系数
具体实施方式
41.图1是本发明实施例中一种三维脸部重建系统1的方块图。三维脸部重建系统1可接收二维人脸影像,及依据二维人脸影像进行三维人脸重建及表情跟踪。三维脸部重建系统1也可应用于三维人脸重建、表情驱动、人脸(avatar)动画驱动,并用重建的人脸得到三维特征点、人脸屏蔽贴图、人脸分割,及使用脸型系数进行人脸识别及驾驶员人脸属性分析。三维脸部重建系统1可拟合三维变形模型(3d morphable model,3dmm)至二维人脸影像以重建三维人脸模型。三维变形模型可以主成分分析(principal component analysis,pca)为基础,使用多个模型系数来生成三维人脸模型的脸部特征,例如使用脸型系数控制三维人脸模型的脸型及使用表情系数控制三维人脸模型的表情。此外,三维脸部重建系统1可使用人工神经网络模型生成所需的模型系数,人工神经网络模型可使用基准真相(ground truth,gt)三维模型作为训练目标而加以训练。基准真相三维模型可为依据实际量测生成的三维模型,及可具有对应多个视角的多个准确三维影像,多个视角可涵盖-90
°
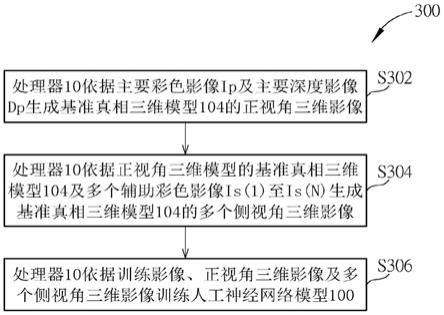
至90
°
的偏航(yaw)角范围及-45
°
至45
°
的俯仰(pitch)角范围。由于基准真相三维模型涵盖大角度的三维影像,使用基准真相三维模型训练完成的人工神经网络模型可准确预测大视角三维人脸模型的模型系数。人工神经网络模型可分开训练脸型系数及表情系数,增加表情初始化及个别表情的精准度。
42.三维脸部重建系统1可包括处理器10、内存12、主要彩色深度相机14、辅助彩色相机16(1)至16(n)、显示器18及影像传感器19,n为正整数,例如n=18。处理器10可耦接于内存12、主要彩色深度相机14、辅助彩色相机16(1)至16(n)、显示器18及影像传感器19。处理器10、内存12、显示器18及影像传感器19可整合于共同装置上,共同装置可例如是手机、计算机或嵌入式设备。处理器10可包括人工神经网络模型100、三维变形模型102及gt三维模型104。人工神经网络模型100可以是卷积神经网络模型。在一些实施例中,人工神经网络模型100可以是视觉几何研究群(visual geometry group,vgg)模型、alexnet模型、googlenet inception模型、resnet模型、densenet模型、senet模型、特征金字塔网络(feature pyramid network,fpn)模型或mobilenet模型。
43.三维脸部重建系统1可以训练阶段及脸部重建阶段运作。在训练阶段,三维脸部重建系统1可生成gt三维模型104及依据训练影像及gt三维模型104训练人工神经网络模型100。在脸部重建阶段,三维脸部重建系统1可将用户的二维影像输入训练完成的人工神经网络模型100以生成用户的三维模型,及在显示器18显示用户的三维模型。处理器10可控制内存12、主要彩色深度相机14、辅助彩色相机16(1)至16(n)、显示器18及影像传感器19的运作以执行训练阶段及脸部重建阶段。在gt三维模型104生成后,主要彩色深度相机14及辅助彩色相机16(1)至16(n)到处理器10之间的连接可以被切断。
44.图2是三维脸部重建系统1中主要彩色深度相机14及辅助彩色相机16(1)至16(18)的设置的示意图。主要彩色深度相机14可设置于参考用户r的正视角位置,辅助彩色相机16(1)至16(18)可分别设置于参考使用者r的18个侧视角位置。正视角位置及侧视角位置可由参考用户r的偏航角及俯仰角定义。偏航角是参考使用者r的头部绕z轴的旋转角度,俯仰角是参考使用者r的头部绕y轴的旋转角度。主要彩色深度相机14可设置于偏航角是0
°
及俯仰角是0
°
的位置。18个侧视角位置可平均分配于-90
°
至90
°
偏航角及-45
°
至45
°
俯仰角的范围,举例而言,辅助彩色相机16(6)可设置于偏航角是-90
°
及俯仰角是0
°
的位置。辅助彩色相机16(1)至16(18)的设置不限于图2的实施例,也可以其他分布方式设置,例如设置于其他偏航角或俯仰角范围内。
45.主要彩色深度相机14及辅助彩色相机16(1)至16(18)可实质上同时从不同角度获取参考用户r的影像,一次拍摄获得参考使用者r人脸的19张彩色相机影像及1张深度影像。主要彩色深度相机14可从正视角位置获取参考用户r的主要彩色影像ip及主要深度影像(depth map)dp。辅助彩色相机16(1)至16(18)可分别从多个侧视角位置获取参考用户r的多个辅助彩色影像is(1)至is(18)。
46.内存12可储存有多个指令。处理器10可执行内存12储存的多个指令以在训练阶段执行训练方法300及在脸部重建阶段执行三维影像重建方法1000。
47.图3是三维脸部重建系统1中人工神经网络模型100的训练方法300的流程图。训练方法300包括步骤s302至s306。步骤s302及s304用以准备gt三维模型104。步骤s306用以训练人工神经网络模型100。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s302至s306:
48.步骤s302:处理器10依据主要彩色影像ip及主要深度影像dp生成gt
49.三维模型104的正视角三维影像;
50.步骤s304:处理器10依据正视角三维影像及多个辅助彩色影像is(1)至is(n)生成
gt三维模型104的多个侧视角三维影像;
51.步骤s306:处理器10依据训练影像、正视角三维影像及多个侧视角三维影像训练人工神经网络模型100。
52.在步骤s302,处理器10使用从正视角位置获得的主要彩色影像ip及主要深度影像dp进行高精度表情拟合以生成准确的正视角三维影像。接着在步骤s304,处理器10使用准确的正视角三维影像及辅助彩色相机16(1)至16(n)的标定参数针对辅助彩色相机16(1)至16(n)的视角进行基准真相迁移,藉以生成其它准确的多个侧视角三维影像。最后在步骤s306,处理器10使用准确的正视角三维影像及准确的多个侧视角三维影像训练出准确的人工神经网络模型100。
53.在一些实施例中,步骤s304中gt三维模型104中侧视角三维影像的生成可更换为利用现有预训练好的模型对大位姿的影像进行预处理,再人为调整,或其它各种利用正视角与其它视角的一致性约束进行基准真相迁移的方法。
54.训练方法300利用了主要深度影像dp进行了高精度表情拟合以生成准确的正视角三维影像,再进行基准真相迁移以将正视角三维影像迁移到其它相机视角来生成准确的侧视角三维影像,藉以训练准确的人工神经网络模型100,避免了传统脸部重建方式中大角度三维模型拟合不准的缺点。
55.图4是图3的步骤s302的流程图,包括步骤s402至s406。步骤s402至s406用以生成正视角三维影像。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s402至s406:
56.步骤s402:主要彩色深度相机14从正视角位置获取参考用户r的主要彩色影像ip及主要深度影像dp;
57.步骤s404:处理器10对主要彩色影像ip及主要深度影像dp进行优化拟合以生成位姿、正视角脸型系数组及正视角表情系数组;步骤s406:处理器10依据位姿、正视角脸型系数组及正视角表情系数组使用三维变形模型102生成正视角三维影像。
58.在步骤s402,主要彩色深度相机14拍摄参考用户r的正视角人脸得到彩色影像ip及主要深度影像dp。在步骤s404,处理器10对彩色影像ip进行特征点(landmark)检测,再结合主要深度影像dp进行优化拟合,即可获得位姿、正视角脸型系数组及正视角表情系数组。位姿可为三维模型的头部位姿,表示头部相对于主要彩色深度相机14的方向及位置。正视角脸型系数组可包括多数个脸型系数,例如100个脸型系数,分别表示人脸脸型特征,例如胖瘦脸型。正视角表情系数组可包括多数个表情系数,例如48个表情系数,分别表示人脸表情特征,例如眯眼表情及嘴角小幅度上扬表情。最后在步骤s406,处理器10依据位姿、正视角脸型系数组及正视角表情系数组生成准确的正视角三维影像。
59.和单利用主要彩色影像ip的方式相比,采用主要深度影像dp及主要彩色影像ip得到的正视角脸型系数组及正视角表情系数组更准确,藉以生成更准确的正视角三维影像。
60.图5是图3的步骤s304的流程图,包括步骤s502至s508。步骤s502用以生成辅助彩色相机16(n)的对应标定参数。步骤s504至s508用以依据辅助彩色相机16(n)的对应标定参数针对辅助彩色相机16(n)的视角进行基准真相迁移,藉以生成准确的侧视角三维影像。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s502至s506:
61.步骤s502:依据主要彩色深度相机14对辅助彩色相机16(n)进行标定以生成辅助
彩色相机16(n)的对应标定参数;
62.步骤s504:辅助彩色相机16(n)获取参考用户r的辅助彩色影像is(n);
63.步骤s506: 处理器10依据辅助彩色相机16(n)的对应标定参数迁移正视角三维影像以生成对应侧视角脸型系数组及对应侧视角表情系数组;
64.步骤s508:处理器10依据辅助彩色影像is(n)、对应侧视角脸型系数组及对应侧视角表情系数组使用三维变形模型102生成对应侧视角三维影像。
65.辅助彩色相机16(n)是辅助彩色相机16(1)至16(n)其中之一,n为1到n之正整数。在步骤s502,辅助彩色相机16(n)可以主要彩色深度相机14作为参考相机进行标定生成标定参数。标定参数可包括辅助彩色相机16(n)的外参数,外参数可包括旋转(rotation)参数、平移(translation)参数、缩放参数、仿射变换(affine translation)参数及其他外部像机参数。主要彩色深度相机14及辅助彩色相机16(n)可各自具有内参数,内参数可包括镜头变形参数、焦距参数及其他内部像机参数。在步骤s506,处理器10依据位姿、正视角脸型系数组及正视角表情系数组生成正视角三维影像,及依据辅助彩色相机16(n)的对应标定参数将正视角三维影像迁移至辅助彩色相机16(n)的角度以生成对应侧视角脸型系数组及对应侧视角表情系数组。在步骤s508,处理器10依据对应侧视角脸型系数组及对应侧视角表情系数组生成准确的对应侧视角三维影像。步骤s502至s508可轮流针对辅助彩色相机16(1)至16(n)执行以生成辅助彩色相机16(1)至16(n)的对应侧视角三维影像。
66.步骤s304依据标定参数对辅助彩色相机16(n)的视角进行基准真相迁移,藉以生成准确的对应侧视角三维影像。
67.图6是图3的步骤s306的流程图,包括步骤s602至s608。步骤s602用以裁剪训练影像以获得稳定的裁剪后训练影像。步骤s604至s608用以训练人工神经网络模型100。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s602至s608:
68.步骤s602:处理器10裁剪训练影像以生成裁剪后训练影像;
69.步骤s604:处理器10将裁剪后训练影像输入人工神经网络模型100以生成脸型系数组及表情系数组;
70.步骤s606:处理器10依据脸型系数组及表情系数组使用三维变形模型102生成三维预测影像;
71.步骤s608:处理器10调整人工神经网络模型100的参数以减低三维预测影像及gt三维模型104之间的差值。
72.在步骤s602,处理器10对训练影像进行人脸检测,然后侦测人脸的二维特征点,依据二维特征点选取最小包围矩形,适当放大最小包围矩形,及依据放大的最小包围矩形裁剪训练影像。训练影像可为二维影像,及可由影像传感器19、主要彩色深度相机14及辅助彩色相机16(1)至16(n)其中之一拍摄。图8是步骤s602中之裁剪后训练影像的示意图,其中圆点是二维特征点,二维特征点包括二维轮廓点80及其他多个内点,8是放大的最小包围矩形。二维轮廓点80可包括下颚轮廓点,其他多个内点可包括眼睛轮廓点、眉毛轮廓点、鼻子轮廓点及嘴轮廓点。处理器10可依据二维轮廓点80选取最小包围矩形。在一些实施例中,为了使得输入人工神经网络模型100的影像稳定,处理器10可对裁剪后训练影像进行翻转(roll)角的归一化处理,接着将归一化的影像输入训练完成的人工神经网络模型100以生成用户的三维影像。在另一些实施例中,处理器10可对裁剪后训练影像进行归一化大小处
理以生成预定大小的裁剪后训练影像,例如128-bit
×
128-bit
×
3-bit的二维三原色(red,green,blue,rgb)影像,接着将归一化的影像输入训练完成的人工神经网络模型100以生成用户的三维影像。在另一些实施例中,处理器10可对训练影像的最小包围矩形进行扰动来提高算法鲁棒性。扰动方式可以是平移、旋转、缩放等仿射变换。
73.在步骤s604,处理器10将裁剪后训练影像输入人工神经网络模型100,进行前向传播以生成脸型系数组及表情系数组。接着在步骤s606,处理器10在以主成分分析为基础的三维变形模型102中使用脸型系数组和表情系数组以得到三维模型点云作为三维预测影像。在步骤s608,三维预测影像经过gt三维模型104的监督在人工神经网络模型100里进行反向传播,最终使三维预测影像越来越接近gt三维模型104的正视角三维影像及多个侧视角三维影像其中一者。人工神经网络模型100使用损失函数调整人工神经网络模型100的参数以减低三维预测影像及gt三维模型104的正视角三维影像及多个侧视角三维影像其中一者之间的差值。人工神经网络模型100的参数可由回归脸型系数矩阵及回归表情系数矩阵表示。处理器10可依据回归脸型系数矩阵计算脸型损失,依据回归表情系数矩阵计算表情损失,及藉由调整回归脸型系数矩阵及回归表情系数矩阵中的参数来分别减低脸型损失及表情损失,藉以减低脸型损失及表情损失的总和。训练完成的人工神经网络模型100能分开生成三维变形模型102的脸型系数和表情系数,具有更精细的表情的表达能力,无三维影像初始化问题,及具有更佳的大视角的表情跟踪能力。
74.图7是图4的步骤s404的流程图,包括步骤s702至s722,用以执行优化拟合程序以生成位姿、正视角脸型系数组及正视角表情系数组。步骤s702至s708用以生成对应主要彩色影像ip的特征点的深度点云。步骤s710至s710用以依据深度点云生成位姿、正视角脸型系数组及正视角表情系数组。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s702至s722:
75.步骤s702:处理器10接收主要彩色影像ip;
76.步骤s704:处理器10侦测主要彩色影像ip的特征点;
77.步骤s706:处理器10接收主要深度影像dp;
78.步骤s708:处理器10依据主要彩色影像ip的特征点及主要深度影像dp生成主要彩色深度相机14的坐标系下的深度点云;
79.步骤s710:处理器10使用迭代最近点(iterative closest point,icp)算法依据深度点云及平均三维模型的内点生成位姿;
80.步骤s712:处理器10依据位姿生成正视角三维影像的三维轮廓点;
81.步骤s714:处理器10依据正视角三维影像的三维轮廓点及内点更新位姿;
82.步骤s716:处理器10依据更新的位姿生成正视角三维影像的三维轮廓点;
83.步骤s718:处理器10寻找对应三维轮廓点的深度点云的对应点;
84.步骤s720:处理器10依据深度点云的对应点更新正视角脸型系数组;步骤s722:处理器10依据深度点云的对应点更新正视角表情系数组;继续步骤s714。
85.处理器102对主要彩色影像ip进行特征点检测(步骤s704),并将主要深度影像dp及主要彩色影像ip进行对齐。然后利用主要彩色深度相机14的内参数将主要彩色影像ip的二维特征点的内点,依据主要深度影像dp转换成彩色深度相机14坐标系下的深度点云(步骤s708),再与人脸数据库三维内点进行迭代最近点(iterative closest point,icp)算法
用以初始化位姿(步骤s710)。处理器102依据初始化的位姿找到gt三维模型104的正视角三维影像上并行线的极值点作为和二维特征点的二维轮廓点的对应三维轮廓点(步骤s712)。然后处理器102使用三维内点及三维轮廓点重新更新位姿(步骤s714),进而依据更新的位姿再更新正视角三维影像的三维轮廓点(步骤s716)。接着处理器102依据当前位姿在深度点云里找到和正视角三维影像中顶点的对应点对来更新脸型系数组(步骤s720)及表情系数组(步骤s722)。处理器102使用更新的脸型系数组及表情系数组更新正视角三维影像,及使用更新的正视角三维影像的新三维轮廓点及新三维内点重新更新位姿(步骤s714)。如此重复步骤s714至s722迭代几次,即可得到较为准确的正视角三维影像。在一些实施例中,脸型系数组及表情系数组可再经人为进行调整以获得更准确的正视角三维影像。
86.步骤s404使用深度信息,经过优化拟合程序后生成更准确的正视角三维影像。
87.图9是人工神经网络模型100的示意图。人工神经网络模型100包括第一阶段900、第二阶段902、第三阶段904、第四阶段906、全连接阶段908、卷积阶段910及全连接阶段912。第一阶段900、第二阶段902及第三阶段904依序执行。接续第三阶段904是第四阶段906及卷积阶段910。第四阶段906之后是全连接阶段908。卷积阶段910之后是全连接阶段912。
88.人工神经网络模型100可以是shufflenet v2轻量级网络。训练影像可以是128-bit
×
128-bit
×
3-bit的二维rgb影像。训练影像将输入第一阶段900,经过第一阶段900、第二阶段902、第三阶段904,在第三阶段904之后人工神经网络模型100的网络分为2条路径,第一路径包括第四阶段906及全连接阶段908,第二路径包括卷积阶段910及全连接阶段912。通过第一路径可得到48个表情系数tex。通过第二路径的卷积阶段910会经过两个3
×
3的卷积核进行处理,接着在经过全连接阶段908之后可得到100个脸型系数tid。由于脸型系数tid是回归人脸脸型比如胖瘦等特征,所以在第三阶段904之后即可分离出来。而表情系数tex需要更精细的特征来回归,比如眯眼,嘴角小幅度上扬等需要的特征更加抽象,所以再经过第四阶段906再进行全连接输出。
89.人工神经网络模型100可利用不同深度网络的特征实现网络最佳性能。
90.图10是使用训练完成的人工神经网络模型1的三维影像重建方法1000的流程图。三维影像重建方法1000包括步骤s1002至s1008,用以依据用户影像产生用户的三维影像。任何合理的技术变更或是步骤调整都属于本发明所揭露的范畴。以下解释步骤s1002至s1008:
91.步骤s1002:影像传感器109获取用户的用户影像;
92.步骤s1004:处理器10侦测用户影像中的多个特征点;
93.步骤s1006:处理器10依据多个特征点裁剪用户影像以生成用户的裁剪影像;
94.步骤s1008:处理器10将裁剪影像输入训练完成的人工神经网络模型100以生成用户的三维模型。
95.在步骤s1008,经过裁剪的用户影像输入到训练完成的人工神经网络模型100中,得到对应的脸型系数组和表情系数组,最后再依据对应的脸型系数组和表情系数组利用三维变形模型102即可生成用户三维模型的三维影像。由于人工神经网络模型100使用gt三维模型104及损失函数进行训练,训练完成的人工神经网络模型100能分开生成三维变形模型102的脸型系数和表情系数,产生的用户三维影像具有更精细的表情,无三维影像初始化问题,及具有更佳的大视角表情跟踪表现。
96.以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1