基于深度学习及代码上下文结构和文本信息的API推荐方法与流程
本发明属于软件工程技术领域,具体涉及软件开发中的智能化推荐和辅助编码技术,尤其涉及实现软件编码过程中的api推荐方法。
背景技术:
在软件开发任务中,软件开发人员依赖api(applicationprogramminginterface,即应用编程接口)(如jdk、android所提供的api)来实现所需要的软件特性。然而,api数量繁多并且每个api中又包含数量众多的方法调用和成员变量,这使得开发人员难以熟知所有api的功能及其使用场合。此外,众多api都有其特定的使用方式要求,例如api之间的使用组合、调用顺序、相应的控制结构(如条件判断、循环等)等。因此,如何在特定的代码上下文中选择合适的api来完成特定的开发任务经常成为开发人员遇到的难题。
针对这一问题的一个有效解决方案是在软件集成开发环境等开发工具中提供智能化api推荐能力。这种智能化api推荐应当通过对开发人员正在编写的代码上下文的分析推测进行api(如api方法调用,成员变量等)推荐,从而辅助开发人员选择正确的api来高效、高质量地完成自己的开发任务。
软件代码包含两种核心类型的信息:结构信息和文本信息。代码结构信息(如控制流和数据流)通过图的形式来表示所需实现的软件特性的程序逻辑。代码文本信息(如代码注释、方法名、变量名)反映了所需实现的软件特性在自然语言中的语义。为此,本发明设计了一种深度学习网络来融合代码结构信息和文本信息,从而实现更有效的api推荐。
技术实现要素:
本发明的目的是为软件开发人员提供基于代码上下文的智能化api推荐方法,在开发人员已经编写好的代码的基础上为其逐行推荐可能会用到的api,包括api方法调用、成员变量访问,控制语句(if、while等)以及变量和对象实例声明等。
本发明提供的api推荐方法,是基于自主设计的深度学习网络并融合代码结构和文本信息的,具体是通过对大量包含目标api(如jdk、android中的api)的源代码(开源代码或企业代码)进行解析,来构造大量的训练样本;构造融合代码结构和文本信息的深度学习网络;通过训练样本对深度学习网络进行训练,得到训练好的深度学习网络;用训练好的深度学习网络进行智能化api推荐。
本发明中,设计了一种用于表示代码上下文结构的api上下文图。api上下文图是一个有向图(n,e),其中,n表示结点的集合,
本发明中,设计了一种处理代码文本信息的方法,得到代码token词袋,包括以下步骤:
(1)将代码文本信息中的方法名、参数名和变量名中的数字裁减掉,如“file2”会被裁剪变为“file”;
(2)两个特殊的字符”_”和“$”将方法名、参数名和变量名进行分词,如“file_name”会被分为“file”和“name”两个token;
(3)进一步,根据驼峰命名法(见参考文献12),将得到的token进行分词,如“filename”会被分为“file”和“name”两个token;
(4)对得到的每一个token进行词形还原,如“files”会被还原为“file”;
(5)过滤掉重复以及无意义的token。无意义的token包括单字符的token(如“i”和“j”)以及glove词表中没有包含的token,得到代码token词袋。glove词表包含从wikipedia和gigaword获得的400k个独特的token。
本发明中,设计了一种对上下文代码结构和文本信息进行融合学习的深度学习网络,如图2所示;包括api上下文图网络(其中api上下文图网络中的门控图神经网络见参考文献1)。代码token网络,联合层以及softmax函数。api上下文图网络用于学习代码结构信息特征。api上下文图网络由嵌入层和门控图神经网络gg-nns组成,并基于给定的api上下文图会学习得到api上下文图向量。代码token网络用于学习代码文本信息特征。代码token网络由嵌入层、多层隐藏层以及sum操作组成,并基于给定的代码token词袋学习得到token向量。联合层用于融合代码结构信息和代码文本信息特征型,形成联合向量。softmax函数基于联合向量计算出每一个候选api的概率,用于api推荐。
本发明提出的基于深度学习的融合代码结构和文本信息的api推荐方法,具体步骤为:
(一)构造训练样本,用于深度学习网络的训练,包括以下子步骤:
(1)以方法为最小单位,对代码库中每一个源代码文件中的每一个方法进行解析,得到api上下文图以及代码token词袋;
(2)对每一个解析得到的api上下文图,迭代式地从其根结点开始遍历,移除与当前遍历到的结点存在控制流关系的后n个结点,并用一个表示窟窿的hole结点取代被移除掉的n个结点,从而得到带有窟窿的api上下文图;对于带有窟窿的api上下文图,重新解析获得其对应的剩余的代码token组成的词袋;于是,带有窟窿的api上下文图,剩余的代码token组成的词袋,以及第一个被替换(移除)的结点的标签,构成了一个训练样本;重复这个过程,可以构造得一定数量的训练样本;
(二)构造融合代码结构和文本信息的深度学习网络;
(三)进行深度学习网络的训练
将所有训练样本输入该学习模型,进行训练,得到训练好的深度学习模型;具体地,将所有训练样本按照9:1的比例分为训练集和验证集输入该学习模型,进行训练,得到训练好的深度学习模型。其中,训练集用于训练和优化模型参数,验证集用于验证经过每一轮训练后模型的效果。如果模型在连续训练5轮后,在验证集上的效果没有提升,那么就停止训练,并且取5轮之前的模型作为最终的模型;
(四)用得到训练好的深度学习模型,进行api预测推荐,包括以下子步骤:
(1)用户输入带有窟窿的程序;
(2)将用户输入解析为api上下文图和代码token词袋,输入到深度学习模型中;
(3)运行模型深度学习模型,给出api推荐结果;
(4)用户根据api推荐结果进行选择;
(5)根据用户的选择,更新当前用户输入的程序。
基于深度学习的融合代码结构和文本信息的api推荐方法的特点如下:
(1)设计了一种用于表示代码上下文(即代码api上下文及结构信息)的api上下文图。api上下文图是一个有向图(n,e),其中n表示结点的集合,
(2)设计了一种处理代码文本信息的方法将代码中的方法名,参数名和变量名进行分词,从而实现token化;
(3)设计了一种对代码结构和文本信息进行融合学习的深度学习网络,包括api上下文图网络,代码token网络,联合层以及softmax函数。
现有的api推荐方法仅仅独立地利用代码结构信息或代码文本信息。基于对源代码语言自然性的观察(见参考文献2),很多方法(见参考文献2-5)提出了使用统计语言模型来实现api推荐。这些方法中所采用的统计语言模型可以是简单的或增强的n-gram模型,也可以是复杂的深度学习模型(如循环神经网络(rnn))(见参考文献6-8)。然而,无论使用哪种类型的统计语言模型,这些方法本质上都将代码视为文本token序列(可能使用简单的程序语法信息(如程序构造关键字和数据类型)来丰富相关token),而没有利用源代码的代码结构信息。为了克服上述基于token序列的api推荐的局限性,另一类重要的api推荐方法(见参考文献9-10)分析了用于推荐api的控制流和数据流图,即考虑代码结构信息。然而这类方法只考虑了控制流和数据流图的子图的局部语义,没有将控制流和数据流图作为一个整体,并且这类方法没有考虑代码文本信息。另一种基于深度学习的api推荐方法(见参考文献11)考虑了代码的结构信息,并且将代码作为树进行整体学习,然而该方法中的树表示缺少了数据流信息并且也没有考虑代码文本信息。与这些方法相比,本发明解决了现有方法独立建模代码结构信息和代码文本信息的局限,以及缺少从整体视角对代码结构进行学习推理的局限。本发明设计的深度学习的模型基于api上下文图网络和代码token网络来联合api用法和代码中的文本信息,从而同时学习用于api推荐的代码结构特征和文本特征。与现有的两种先进的api推荐方法gralan(见参考文献9)以及tree-lstm(见参考文献11)相比,本发明在api推荐的top-1,top-5,以及top-10的准确率上分别达到了58.6%,81.4%,以及87.9%,而gralan为31.5%,64.5%,以及77.6%,tree-lstm为46.7%,70.4%,以及79.3%。
附图说明
图1为本发明所使用的api上下文图的示例。
图2为本发明所使用的深度学习网络结构图。
具体实施方式
针对java程序及jdkapi的一个实施例,具体如下:
(1)api上下文图的实现是用javaparser以语句为基本单位解析java代码得到ast(抽象语法树),用visitor模式遍历每条语句所对应的ast的结点,并利用java的反射机制获得api的完整列表来抽取api,从而得到api的完整的方法签名并作为结点加入到当前api上下文图上,并在结点间建立控制流关系。基于ast分析代码中所有变量和对象被调用的情况,从而可以得到数据依赖关系,以此为依据在结点间建立数据流关系。
(2)代码中的方法名,参数名和变量名的分词是基于java实现的。其中词形还原是利用stanfordcorenlp实现的,glove词表是从glove官方网站上获取得到。
(3)api上下文图网络中的嵌入层将api上下文图中的每个结点所表示的api转换为一个300维的向量,然后输入到门控图神经网络gg-nns中得到300维的api上下文图向量(门控图神经网络gg-nns见参考文献1)。代码token网络中的嵌入层将输入的每一个代码token转换为一个300维的向量,然后通过隐层大小为300的三层全连接隐藏层进一步学习代码token中的语义信息(其中每层隐藏层的激活函数均为tanh),最后通过sum操作将所有通过最后一层隐藏层得到的代码token向量求和得到最终300维的token向量。联合层首先将300维的api上下文图向量和300维的token向量拼接为一个600维的向量,然后通过一层全连接层(激活函数均为tanh)进一步学习api上下文图和代码token的联合语义并得到最终的600维向量。softmax函数将联合层得到的600维向量作为输入进行分类的归一化概率计算,公式如下:
其中,p(y|x)表示当输入为x时,y这个类可能的概率,exp表示以e为底的指数函数,wy表示y这个类对应的深度学习网络中的参数,wc表示某一类c所对应的深度学习网络中的参数。
(4)深度学习网络基于tensorflow所提供的api进行深度学习网络代码的编写,其中门控图神经网络的实现基于微软开源的代码进行修改。
(5)代码推荐的具体实施方式。用户将光标放在代码编辑器中需要进行api推荐的位置,并点击代码编辑器中的推荐按钮或按下推荐快捷键,从而在代码编辑器会弹出一个包含n个推荐结果的推荐列表。用户可从推荐列表中选取一个推荐结果,此推荐结果会自动填充到光标所在位置。
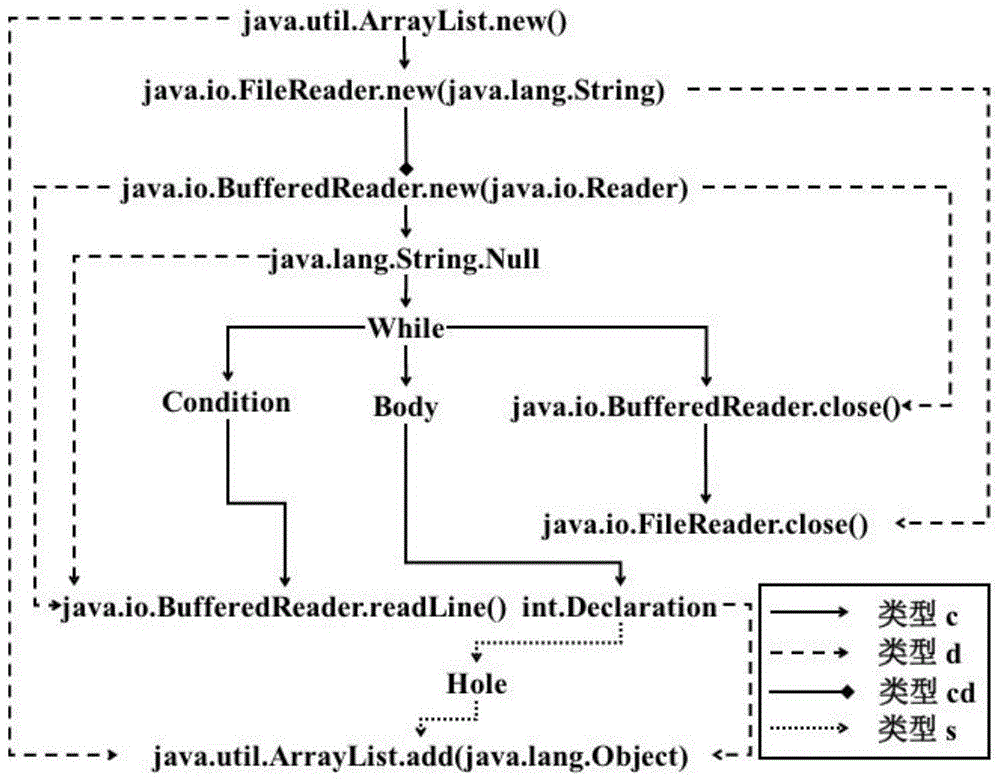
jdk中包含大量的api,并且java程序中经常会用到jdk中的api,然而开发人员却难以熟记并掌握所有的api使用方法,因此本发明可以在开发过程中为开发人员提供api推荐。本发明解决了现有方法独立建模代码结构信息和代码文本信息的局限,以及缺少从整体视角对代码结构进行学习推理的局限。本发明设计的深度学习的模型基于api上下文图网络和代码token网络来联合api用法和代码中的文本信息,从而同时学习用于api推荐的代码结构特征和文本特征。本发明通过javaparser解析代码构造出api上下文图从而可以输入到深度学习网络中进行预测。基于tensorflow实现深度学习网络可以充分利用gpu进行加速,从而提高预测推荐的速度。以附录中的代码为例。用户在代码编辑器(如intellijidea)中编写了附录中的代码,并且该用户不知道第8行应该用什么api来获取一个字符串的hash值,因此用户可以将光标放在第8行的位置并点击代码编辑器中的推荐按钮来调用本发明的推荐服务。当接收到调用服务时,本发明首先利用javaparser可以准确地将附录中的代码解析为图1所示的api上下文图,该api上下文图中包含了两种明显的语义:语义1)使用reader按行读取文件内容;语义2)将值添加到已创建的列表中。从整体视角观察,可以发现在语义1)中声明为string类型的变量“str”仅仅被用于存储来自文件的内容,而之后再也没有被使用。此外,在语义2)中声明为int类型的变量“hashcode”还未被赋值。另外,在语义1)和语义2)之间缺少了连接它们的api来保持程序逻辑的完整性。从以上的整体视角出发,可以推测出窟窿位置需要对一个string类型的变量进行某种处理来获取一个int类型的值。这些语义通过api上下文图网络都可以学习得到。然而,如果仅仅依靠api上下文图网络只能推测出窟窿位置需要对一个string类型的变量进行某种处理来获取一个int类型的值,但具体是何种操作并不能确定,因此本发明中引入了代码token网络来获取代码文本信息。在解析附录中的代码时,除了解析得到图1所示的api上下文图,还会解析得到compute,hash,code,path,result,rd,br,str这些代码token,其中compute,hash,code这三个代码token包含了计算hash值的语义,并且可以通过代码token网络学习得到。结合api上下文图网络以及代码token网络,并进行联合学习,可以推测窟窿位置需要计算一个string类型变量的hash值。从而,本发明可以成功的推荐出窟窿位置所需要的api为java.lang.string.hashcode()。
参考文献:
1.danielbeck,gholamrezahaffari,trevorcohn:
graph-to-sequencelearningusinggatedgraphneuralnetworks.acl(1)2018:273-283.
2.abramhindle,earlt.barr,zhendongsu,markgabel,premkumart.devanbu:onthenaturalnessofsoftware.icse2012:837-847.
3.miltiadisallamanis,charlesa.sutton:
miningsourcecoderepositoriesatmassivescaleusinglanguagemodeling.msr2013:207-216.
4.tungthanhnguyen,anhtuannguyen,hoananhnguyen,tienn.nguyen:astatisticalsemanticlanguagemodelforsourcecode.esec/sigsoftfse2013:532-542.
5.zhaopengtu,zhendongsu,premkumart.devanbu:
onthelocalnessofsoftware.sigsoftfse2014:269-280.
6.veselinraychev,martint.vechev,eranyahav:
codecompletionwithstatisticallanguagemodels.pldi2014:419-428.
7.hoakhanhdam,truyentran,trangpham:
adeeplanguagemodelforsoftwarecode.corrabs/1608.02715(2016).
8.anhtuannguyen,trongducnguyen,hungdangphan,tienn.nguyen:
adeepneuralnetworklanguagemodelwithcontextsforsourcecode.saner2018:323-334.
9.anhtuannguyen,tienn.nguyen:
graph-basedstatisticallanguagemodelforcode.icse(1)2015:858-868.
10.xiaoyuliu,liguohuang,vincentng:
effectiveapirecommendationwithouthistoricalsoftwarerepositories.ase2018:282-292.
11.chichen,xinpeng,junsun,zhenchangxing,xinwang,yifanzhao,hairuizhang,wenyunzhao:
generativeapiusagecoderecommendationwithparameterconcretization.sci.chinainf.sci.62(9):192103:1-192103:22(2019).
12.“camelcase,”2020.[online].available:
https://en.wikipedia.org/wiki/camelcase。
附录:
- 还没有人留言评论。精彩留言会获得点赞!