基于DSL的网络配置文件测试方法与流程
本发明属于计算机分析检测技术领域,具体说是基于dsl的网络配置文件测试方法,基于断言语句测试方法,以及语义学习方法的设计。
背景技术:
领域特定语言(domain-specificlanguages,dsl)是针对某一特定领域,具有受限表达性的一种计算机程序设计语言,分为外部dsl与内部dsl。领域特定语言具有三大优点:(1)提高开发效率:利用dsl建构模型,将公共代码放在一起可以避免重复,从而极大地提升了生产率;(2)增加系统功能:通过了解dsl代码,可利用dsl编写大量系统功能;(3)适应执行环境:dsl可以弥补宿主语言的局限性,将事物以适宜的dsl形式表示出来,生成可用于实际执行环境的代码。
断言(assertion)是一种编程中常用的手段,将一个返回值总是需要为真的判别式放入程序语句中,用于排除在设计的逻辑上不应该产生的情况。目前,断言方法主要用于检测软件中潜在的漏洞,将断言与软件测试相结合更有助于进行程序分析。
现阶段,通常使用代码的复制粘贴来改进软件开发的有效性,若该开发过程缺少管理将会引入大量的易受攻击代码。语义学习方法主要用于检测程序代码中是否存在已知错误。与基于克隆技术的检测方法和模糊测试方法相比,语义学习方法具有更高的准确性与有效性。
技术实现要素:
由于网络配置文件潜在的错误会导致网络中断或异常等问题,因此,为了保障网络的正常运行,本发明针对思科配置文件设计了一种基于dsl的网络配置文件测试方法。
本发明采用的技术方案:
一种基于dsl的网络配置文件测试方法,包括错误配置文件集和学习模式的构建、抽象语法树的静态匹配、可疑错误的验证,以及基于语义的相似性计算,其主要步骤包括:
步骤1:包含错误的配置文件数据集的准备;
步骤2:用于执行静态错误匹配的相关内容的准备,包括解析错误配置文件集中的每个配置文件与待测配置文件,构建用于可疑错误检测的学习模式和用于可疑错误验证的断言模板;
步骤3:可疑错误的检测及验证,包括与学习模式的匹配、基于断言模板和形式化验证器以便验证可疑错误;
步骤4:基于步骤3的验证结果,利用语义分析技术来判断其他配置文件中是否存在该相同的错误;
所述步骤1中的包含错误的配置文件数据集需要深度调研并收集思科配置文件中的常见错误类型,以此来构建配置文件数据集;
所述步骤2中的详细步骤包括:
步骤2.1:将待测配置文件和错误配置文件集中的每个配置文件分别解析为抽象语法树;
步骤2.2:对步骤2.1得到的抽象语法树进行语法树遍历,收集错误的相关信息,如错误类型和错误位置等信息。最后,根据错误类型来构建学习模式。构建的学习模式中不仅包括错误类型,错误变量等信息,还包括用于检测可疑错误的断言语句模板。
所述步骤3中的详细步骤包括:
步骤3.1:将解析出的待测配置文件的抽象语法树与步骤2.2中构建好的学习模式进行静态模式匹配,若匹配成功,则说明该待测配置文件中存在可疑错误;
步骤3.2:基于步骤3.1查找到的可疑错误信息,根据其错误类型在学习模式中找到相应的模式内容,并在该配置文件中适当的位置处自动地推荐、插入相应的面向错误的断言语句,最后,根据插入的断言语句判断该可疑错误是否为真实错误;
步骤3.3:通过步骤3.2得到了插入断言语句的配置文件,在本步骤中,将通过利用测试用例执行断言语句和形式化验证器来验证该可疑错误是否为真实错误,若插入的断言语句能够被测试用例所触发,则说明该可疑错误为真实错误,否则,将包含可疑错误的配置文件发送至形式化验证器,若该配置文件能够通过形式化验证器的验证,则说明该可疑错误不是真实错误;若该配置文件不能够通过验证器的验证,则说明配置文件中潜在的可疑错误就是潜在的真实错误,最后,输出包含该真实错误的配置文件;
所述步骤4中的详细步骤包括:
步骤4.1:由于标记的语义流图,既包括控制流图,也包括数据流图,因此利用它可以获取更多的语义信息,在本发明中,需要为包含真实错误的配置文件与待测配置文件集中的每个配置文件创建标记的语义流图。
步骤4.2:将包含真实错误的配置文件与待测配置文件集中的任一个配置文件作为输入,对这两个文件中的每个基本块进行特征提取,并编码为初始数值向量。
步骤4.3:利用深度神经网络来构建语义感知深度神经网络模型,并将步骤4.2中获取的初始数值向量发送至该模型,通过多次迭代计算得到相应的嵌入式向量,该嵌入式向量即为配置文件的语义。
步骤4.4:将步骤4.3获取的两个配置文件的嵌入式向量利用余弦定理进行两者之间的相似性计算,并将相似性得分降序排列,分别于预定义的阈值作比较,若得分大于阈值,则说明待测配置文件集中的这一配置文件最有可能包含同样的真实错误,最后,输出该配置文件。
本发明的优点是:基于语义学习的方法检查其他配置文件中是否存在相同的错误,从而更加全面、快速地检测错误,提高工作效率。
附图说明
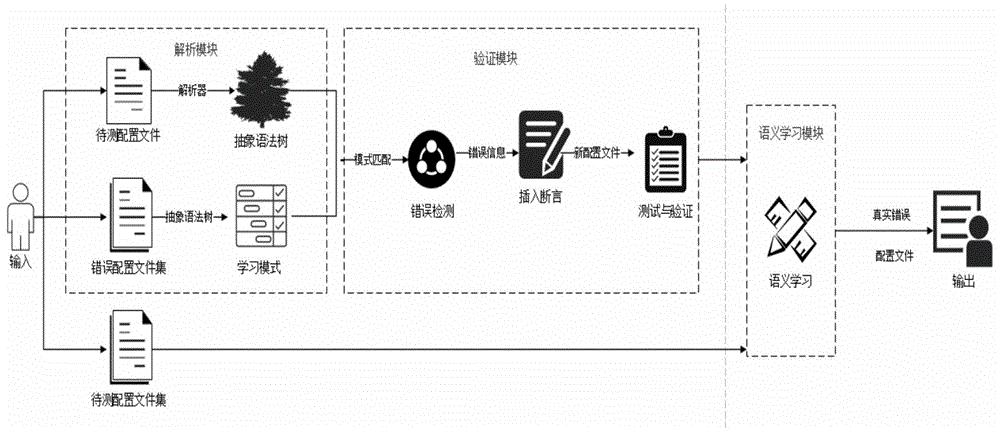
图1为基于dsl的网络配置文件测试方法的整体框架图。
图2为解析模块的实现方案框架图。
图3为验证模块的实现方案流程图。
图4为语义学习模块的实现方案流程图。
具体实施方式
下面结合说明书附图1-4对本发明进一步说明。为了可以全面地检测配置文件中潜在的错误,将静态模式匹配与动态验证技术相结合以检测配置文件中的错误。同时,对于大型配置文件,引入语义学习方法来检测其他配置文件中是否包含已检测出的错误,从而加速检测速度,提高方法效率。
基于dsl的网络配置文件测试方法的整体框架。在整体框架中,共具有三个主要功能模块,即解析模块、验证模块和语义学习模块。通过解析模块将包含错误的配置文件集中的每个配置文件与待测配置文件分别解析为抽象语法树,通过遍历抽象语法树来构建用于匹配的学习模式;在验证模块进行模式匹配以确认可疑错误,并利用断言语句以确定可疑错误是否为真实错误;语义学习模块基于余弦定理和检测出的真实错误来判断其他待测配置文件中是否含有该已知错误,最终输出最有可能包含该已知错误的配置文件。
在解析模块工作开展之前,深度调研并收集思科配置文件中常见的错误类型,根据收集的错误相关信息构建错误配置文件集。
解析模块实现方案如图2所示。该模块主要负责将错误配置文件集中的每个配置文件与待测配置文件分别解析为抽象语法树,通过遍历包含错误的配置文件的抽象语法树收集错误的相关信息,之后根据错误的相关信息来构建用于可疑错误匹配的学习模式。在学习模式中,除了包括错误类型,错误变量等信息之外,还包括相应的用于判断可疑错误是否为真实错误的断言模板。
抽象语法树(abstractsyntaxtree,ast)是一种中间表示形式,通过构建抽象语法树能够清晰明了地了解源文件中的主要内容。抽象语法树的结构不依赖于宿主语言的文法,其采用的是语法分析阶段所使用的上下文无关文法。领域特定语言分为外部dsl和内部dsl,其中外部dsl是一种“不同于应用系统主要使用语言”的语言,通常采用自定义语法,不会受限于宿主语言的语法结构,提供了更大的语法自由度。因此,在本发明中,利用外部dsl来描述配置文件的语法结构。之后,利用解析器将输入文本转换为抽象语法树。将配置文件解析为抽象语法树的过程如下:
步骤1:根据思科配置文件的特点,基于外部dsl编写配置文件相关的词法规则和语法规则。根据上述内容,通过词法分析与语法分析来构建每个配置文件相应的抽象语法树之后,基于语法分析树的监听器机制来自动遍历每个语法树。通过遍历语法树收集配置文件中存在的错误的相关信息,例如错误类型、错误位置等重要信息。
步骤2:根据编写的词法规则进行词法分析,词法分析过程主要负责将输入的配置文件中的字符聚集为词法符号,并消除源文件中的空白符、换行符等无意义字符。通过词法分析可以简化语法分析,提高工作效率。将收集到的与错误相关的信息后,按照错误类型进行分类,将其编写为用于匹配的学习模式。
步骤3:根据编写的语法规则进行语法分析,语法分析主要负责接收词法分析得到的词法符号,解析词法符号以识别配置文件中的语句结构,最终构建成相对应的抽象语法树。
所述步骤2中的详细步骤包括:
步骤2.1:将待测配置文件和错误配置文件集中的每个配置文件分别解析为抽象语法树;
步骤2.2:对步骤2.1得到的抽象语法树进行语法树遍历,收集错误的相关信息,如错误类型和错误位置等信息。最后,根据错误类型来构建学习模式,构建的学习模式中不仅包括错误类型,错误变量信息,还包括用于检测可疑错误的断言语句模板。
学习模式主要用于静态模式匹配,根据匹配结果确定待测源文件中是否存在可疑错误。在构建错误配置文件集中每个配置文件的抽象语法树之后,根据解析器中自带的语法树遍历器来遍历抽象语法树,收集错误的相关信息。最后根据错误类型进行分类以构建学习模式。
构建学习模式的过程如下:断言模板形式化程序验证是一项确保程序正确性的有力技术,为了更好地执行此项技术,通常需要手动指定断言语句,这通常是浪费时间且易出错的任务。在本发明中,首次将断言方法应用于配置文件的检测中。为了节省并确保断言语句的准确性,本发明将在配置文件中的适当位置自动地推荐,并插入相应的断言语句。断言模板根据错误类型进行分类,利用机器学习的方法实现断言语句的设计,最终构建为断言模板。制定断言模板的过程如下:
步骤2.3:判断是否需要断言:根据学习模式的匹配结果判定该配置文件中是否存在可疑错误。若文件中存在可疑错误,则说明在该配置文件中确实需要插入断言语句。
步骤2.4:推荐断言变量:断言语句通常以布尔表达式形式表示,通过判断该表达式中的变量是否在任何情况下始终表示为真来决定该断言语句是否为真,因此,在确定需要插入断言之后,仍需判断哪个变量是最有可能在该断言中发生的。本发明中为每个变量定义一个“score”,通过计算“score”的分数并按照降序排列,具有高分数的变量就是最有可能出现在断言语句中的变量。
步骤2.5:推荐变量值范围:确定配置文件中的断言变量之后,根据配置文件中的变量值规则并利用验证工具来计算出变量值的最大值和最小值,以此来推荐变量值的合规范围。
步骤2.6:按照错误类型编写好每种错误相对应的断言语句,汇总成学习模式中的断言模板。
所述步骤3中的详细步骤包括:
步骤3.1:将解析出的待测配置文件的抽象语法树与步骤2.2中构建好的学习模式进行静态模式匹配,若匹配成功,则说明该待测配置文件中存在可疑错误;
步骤3.2:基于步骤3.1查找到的可疑错误信息,根据其错误类型在学习模式中找到相应的模式内容,并在该配置文件中适当的位置处自动地推荐、插入相应的面向错误的断言语句,最后,根据插入的断言语句判断该可疑错误是否为真实错误;
步骤3.3:通过步骤3.2得到了插入断言语句的配置文件,在本步骤中,将通过利用测试用例执行断言语句和形式化验证器来验证该可疑错误是否为真实错误,若插入的断言语句能够被测试用例所触发,则说明该可疑错误为真实错误,否则,将包含可疑错误的配置文件发送至形式化验证器,若该配置文件能够通过形式化验证器的验证,则说明该可疑错误不是真实错误;若该配置文件不能够通过验证器的验证,则说明配置文件中潜在的可疑错误就是潜在的真实错误,最后,输出包含该真实错误的配置文件。
验证器,采用验证模块,包括三部分内容,主要负责确认待测配置文件中是否存在可疑错误;若存在可疑错误,则需根据学习模式中相对应的断言模板在配置文件适当的位置处自动推荐、插入相关的断言语句;最后,利用形式化验证器验证包含断言语句的配置文件以判断可疑错误是否为真实错误。
步骤3.4:模式匹配将解析模块发送来的待测配置文件的抽象语法树和学习模式作为输入,最终输出该待测配置文件中潜在的可疑错误。
步骤3.5:解析模块中将待测配置文件解析为相应的抽象语法树,基于该抽象语法树和构建的学习模式,收集抽象语法树中的重要信息,二者进行静态模式匹配。
步骤3.6:查看静态模式匹配结果,若匹配成功,则说明待测配置文件中存在可疑错误;否则,不存在。
步骤3.7:插入断言,若待测配置文件确认存在可疑错误,则根据错误类型在构建的学习模式中找到相应的模式内容,在该配置文件中适当的位置处自动地推荐,并插入相应的面向错误的断言语句。之后,将根据插入的断言语句判断检测出的可疑错误是否为真实错误。
步骤3.8:验证配置文件,在此部分中,需要通过两种方式判断检测出的可疑错误是否为真实错误,这两种方式分别为执行断言语句和验证断言语句。
步骤3.8.1:首先,利用测试用例自动生成器生成能够触发配置文件中的面向错误的断言的测试用例。若插入的断言语句能够被真实的测试用例所触发,则说明待测配置文件中检测出的可疑错误为真实错误;若不能由真实的测试用例所触发,则将包含可疑错误的配置文件发送至步骤2中进行验证。
步骤3.8.2:此步骤中主要应用形式化验证器自动验证含有可疑错误的配置文件。若该配置文件能够通过形式化验证器的验证,则说明该可疑错误不是真实错误;若该配置文件不能够通过验证器的验证,则说明配置文件中潜在的可疑错误就是潜在的真实错误。输出该真实错误发送至语义学习模块。
步骤3.9:语义学习模块实现方案,语义学习模块实现方案该模块主要基于检测出的真实错误来判断其他待测配置文件中是否含有该已知错误。主要利用语义生成模型来生成两个配置文件的语义,并根据余弦定理计算两个语义之间的相似性得分,与预定义的阈值相比较,根据分数降序排列,最终输出最有可能包含该已知错误的配置文件。语义学习模块的引入将会加快检测速度,提高方法的整体效率。
步骤3.10:创建标记的语义流图,将包含真实错误的配置文件与待测配置文件集作为该模块的输入,分别为包含真实错误的配置文件与待测配置文件集中的每个配置文件创建标记的语义流图(labeledsemanticflowgraph,lsfg)。标记的语义流图既包括控制流图(controlflowgraph,cfg),也包括数据流图(dataflowgraph,dfg),利用标记的语义流图能够获取更多的语义信息。在本发明中,预计利用工具idapython为配置文件中的每个基本块创建控制流图,基于创建的控制流图来推测两个基本块之间的数据流图。
步骤3.10.1提取特征,为输入的两个配置文件中的每个基本块进行特征提取,所提取的特征均具有轻量的、健壮的和易于提取等特点,并将提取的特征编码为基本块的初始数值向量。对于每个配置文件,其中所有基本块的初始数值向量均存储在一个独立文件中,将该文件发送至语义生成模型中以生成配置文件语义。
步骤3.10.2构建语义生成模型,语义生成模型的目的是获取一个更高维的特征表示,该特征表示可以用作语义嵌入向量来表示整个配置文件的语义。基于深度神经网络来构建语义感知深度神经网络模型,将配置文件的初始数值向量发送至该模型中,通过多次迭代计算以获取嵌入式向量,即二者的配置文件语义。
步骤3.10.3相似性计算,利用语义生成模型输出的两个配置文件的嵌入式向量,基于余弦定理进行两者之间的相似性计算。将相似性得分按照降序排列,分别与预定义的阈值进行比较,相似性得分大于阈值的配置文件即为最有可能包含该已知真实错误的配置文件,并将该配置文件输出。针对大型配置文件集,利用语义学习模块将快速检测出配置文件集中都有哪些配置文件具有已知错误,将提高整个方法的工作效率。
- 还没有人留言评论。精彩留言会获得点赞!