一种基于多尺度特征融合的行人重识别特征提取方法与流程
本发明涉及计算机视觉技术和行人重识别领域。特别是涉及一种多尺度特征融合的行人特征提取方法。
背景技术:
利用高科技手段加强社会管理预防犯罪行为发生已成为共识。为此,各地政府都在公共场所关键点、交通路口、生活小区、停车场等安装了大量摄像头,加强对行人行为的观察及身份识别。摄像头每天产生巨量数据,对这些数据进行分析具有重要意义。但复杂场景下获取人脸、步态等生物特征特别困难,为此出现了行人重识别技术。不同于传统意义上的人脸图像识别技术,行人重识别(reid)建立来自不同摄像头的同一行人图像间的对应关系。当前,行人重识别主要依靠人体外表视觉信息,但视频图像受光照、流明变化、行人姿态及拍摄视角度等因素影响,即使是同一行人,不同摄像头拍摄的身体外表图像也存在很大差异;同一行人,在不同时间由同一摄像头拍摄的图像同样也存在很大差异,因此,行人重识别面临巨大挑战,已成为当前视频识别领域的热点研究问题,在社会管理、突发事件重构、智能无人超市、人机交互等方面具有广阔应用前景。
行人重识别对无重叠的多个摄像头拍摄的行人图像进行识别,是将一个摄像头拍摄的目标行人作为检索对象,从其他摄像头拍摄的图像中准确识别行人,由提取健壮表示特征及采用有效度量模型实现识别两个过程组成。目前研究主要围绕图像特征学习和相似性度量方面展开。特征提取是特征工程的重要问题。特征提取是从原始数据出发构造新特征的过程,一般数据转化到特征空间以后,舍弃了某些对识别无关或造成干扰的信息,保留相关的信息,如对于行人重识别,理想的描述子应该对光照、行人姿势变化、视角变化等不敏感,而保留颜色、纹理、空间结构等信息。早期特征的构造由专家借助相关领域知识,在对数据的分析、判断和思考下,抽取、组合各类特征得到。随着各行各业的数据爆发式增长累积,原有的人工特征方法难以满足日益增长的需求。此外手工设计的特征往往使用领域较窄,在其目标领域表现良好,迁移到其他领域往往效果会大打折扣。然而,深度学习的兴起和大规模应用,不仅减轻了特征方法的难度,还可以利用海量数据,通过自动筛选特征和特征组合,进而学习到更加鲁棒的特征。在模式识别领域中,对样本进行分类识别的时候,把计算样本间的距离称为样本间的相似性度量。相似性度量是机器学习中一个新兴领域,在计算机视觉中有广泛的应用。它能有效地改善行人跟踪、图像检索、人脸识别、聚类分析、以及行人重识别的效果。基于相似性度量学习方法的中心思想是利用行人图像的标签信息来计算相似性度量函数的参数,使得相同类别行人图像对的距离小于不同类别行人图像对的距离。尽管近年来在图像特征学习和相似度量方面科研工作取得了长足的进步,但是仍然有提升的空间。本发明就通过图像特征的研究,提升提取图像特征的鲁棒性,进而提升检索的精度。
行人重识别(reid)是指判断来自不同摄像头所拍摄到的行人图像是否属于同一个行人的技术。基本工作流程主要分为五个阶段:数据收集和预处理,模型训练,特征提取,相似性度量,相似性重排序。行人重识别技术对智能安防和智能商业有着无可限量的应用价值。可以实现跨摄像头快速识别和追踪嫌疑人,有效协助警方部署安防或破案;可以帮助零售经营者、大型展馆管理者等实现精准统筹顾客轨迹、深入挖掘潜在的商机;还可以运用到手机相册聚类、人机交互等场景中。
特征表达和距离度量是行人重识别过程中的两个核心模块。传统方法无法对这两个核心模块进行协同优化。随着深度学习技术的出现,同时学习图像表达和图像间的相似性度量成为可能。得益于深度学习在行人重识别的发展,基于表征学习的方法成为一类非常常用的行人重识别方法,尤其是卷积神经网络的快速发展。由于卷积神经网络可以自动从原始的图像数据中根据任务需求自动提取出表征特征(representation),所以一部分研究者把行人重识别问题作为分类(classification/identification)问题或者验证(verification)问题,其中分类问题是指利用行人的id或者属性等作为训练标签来训练模型,而验证问题是指输入一对(两张)行人图片,让网络来学习这两张图片是否属于同一个行人。
众所周知,目前的行人重识别技术主要抽取全局特征和局部特征,通过融合全局特征和局部特征,作为行人的特征进行相似性计算。通过对全局特征图和局部特征图可视化发现,利用卷积神经网络在数据预处理后的图像上进行卷积、池化等特征提取操作,逻辑流程容易理解且简单,而且提取出的全局特征基本上可以代表目标行人。但是通过观察特征图发现,目标行人的某些实时属性(发卡、商标、眼镜等)会出现由于所占像素较少而无法响应在最终的特征图上。因此只单一使用全局特征进行行人重识别,会出现模型无法高精度分辨出相似行人。后来,人们发现通过修改卷积神经网络最后一层的stride为1,不仅不会增加运算负载,而且还可以保留更多的微小细节信息。更进一步,通过对提取的特征图进行硬划分,分成n个水平块,对每一块进行行人id分类,采用softmaxloss进行监督,具体如图3所示,这样不仅会促使卷积神经网络自动关注行人图像中微小的细节信息,还可以使提取的特征鲁棒性增强。
技术实现要素:
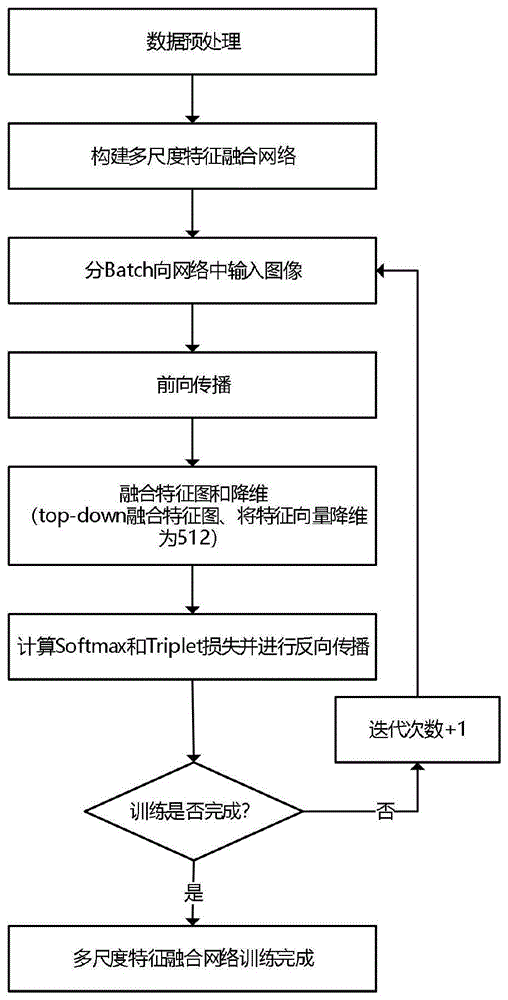
本发明针对目前行人重识别领域现有算法提取的特征仍存在鲁棒性不高,模型泛化能力较弱的情况,通过整合多尺度的特征,提取健壮的行人表示,算法架构如图2所示,可以提高行人重识别技术在智能安防和智能商业的应用价值。本发明多尺度特征融合网络的训练流程如图1所示,包括:
1.对数据的预处理包括:
数据集包括训练集、查询集和查询库;训练数据图像的名称格式为行人id_摄像头id视频id_视频帧数_检测框;数据集进行resize,对图像进行预处理包括:旋转、totensor、遮挡、对比度、翻转、锐化增强、噪声、滤波、倾斜、图像色彩空间转换、图片叠加与融合、颜色抖动、gamma变换、图片混合。
2.构建多尺度融合网络:
通过观察行人图像发现,行人在图像中存在尺度不一,例如有的行人完整填充在图像中,而有的行人仅仅占据图像某一角落,大部分都是背景。对于尺度存在差异的数据集,即使融合全局特征和局部特征,仍无法得到健壮的行人特征,不能克服尺度变化带来的问题。因此本发明提出抽取卷积神经网络中间层特征图,采用top-down的方式实现多尺度特征融合。本发明在实验中进行top-down特征图融合时发现,中间特征图由于卷积、池化等操作不完善,导致特征图包含过多背景信息,如果直接进行特征融合,会出现融合后特征包含过多杂波而影响相似性的度量,因此构建多尺度融合网络如下:
(1)以resnet为backbone,在其基础上进行修改。将backbone的layer3层提取的特征作为共享特征,其后接两个分支,分别为global分支和part分支;
(2)part分支将resnet最后一层的stride由2降为1,使特征图的大小和layer3提取的特征图大小一致,该分支提取到的特征记为layer4.4(part);global分支使用原resnet的layer4层的操作,该分支提取到的特征记为layer4.4(global);part分支和global分支行人图像特征图大小分别为(8,4)和(16,8),在两个分支的特征图上使用全局平均值池化;
(3)抽取layer3.1和layer4.1的特征图,其大小分别为(16,8)和(8,4);
(4)通过分别将global分支和part分支与layer3.1和layer4.1的特征图进行融合,分别标记为layer3.1_p和layer4.1_g;
(5)将以上4个特征向量(layer4.4(part)、layer4.4(global)、layer3.1_p、layer4.1_g)降维成512的特征,进行特征融合,组成2048维的特征进行相似性度量。此特征向量既包含低层特征又包含高层语义,具有较强的鲁棒性,可以提升行人重识别的精度。
3.对多尺度融合特征网络进行训练:
分batch向网络中输入训练图像,在多尺度特征融合网络中提取特征、融合特征图和降维,将特征进行前向传播输出预测值;根据预测值与真实值计算softmax和triplet损失,反向传播更新模型参数,迭代训练直到满足结束训练的条件。
通过分析和实验证明,在中间特征图上使用全局最大值池化可以抑制背景杂波,使提取的特征图主要关注在行人肢体和实时属性上;而在最终的特征图上使用全局平均池化,可以充分利用提取的目标行人特征,提高特征的鲁棒性。
附图说明
图1:系统流程图;
图2:多尺度特征融合框架图;
图3:局部特征监督流程图;
图4:数据集及命名格式实例图;
图2中的字母分别代表如下含义:
inputimages:输入图像;
p*k:p个id,每个idk张图像;
rsenetbackbone:resnet骨干网络;
gmp:全局最大池化;
gap:全局均值池化;
training:训练;
inference:推举。
具体实施方式
本发明的硬件环境主要是一台pc主机。其中,pc主机的cpu为intel(r)core(tm)i7-7000,3.70ghz,gpu为nvidiagtx1080ti,内存为4gbram,显存为32gb,64位操作系统。
本发明的软件实现以ubuntu18.04为平台,在pycharm环境下,使用python语言和pytorch深度学习框架开发。pycharm版本为2019社区版,pytorch版本为1.1.0,python版本为3.6.1。
实验数据为公有数据集,包括market-1501(清华大学)、dukemtmc-reid(美国杜克大学)、msmt17(北京大学)等,数据集包括训练集、查询集和查询库,其图像命名格式各不相同。以market-1501为例,行人id_摄像头id视频id_视频帧数_检测框,具体例子如图4所示。
本发明提出的图像特征提取方法,通过多尺度特征融合,进行行人重识别。所述多尺度特征融合采用融合提取网络中的多个特征图进行处理,在低层特征图上使用全局最大值池化以抑制背景杂波提高特征的鲁棒性,在高层特征上使用全局平均值池化以充分利用提取的特征。将高层特征图和大小一致的低层特征图进行融合,融合成鲁棒性强的特征向量。步骤如下:
多尺度特征图融合
本发明以resnet为backbone,通过在其基础上进行修改实现多尺度特征的融合,算法架构如图2所示,提高提取特征鲁棒性,提高行人重识别的精度。假设送入卷积神经网络的图大小为(256,128,3)。通过修改将layer3层提取的特征作为共享特征,其后接两个分支,分别为global分支和part分支。part分支通过将resnet最后一层的stride由2降为1,使特征图的大小和layer3提取的特征图大小一致,保留更多行人图像微小特征。global分支使用原resnet的layer4层的操作。经过global分支和part分支行人图像特征图大小分别为(8,4)和(16,8),而且在以上两个特征图上使用全局平均值池化,可以充分利用网络提取的特征。已知卷积神经网络提取特征过程中,存在尺度变化,由大到小变化。因此抽取layer3.1和layer4.1的特征图,其大小分别为(16,8)和(8,4),通过分别将part分支和global分支与layer3.1和layer4.1的特征图进行融合,分别标记为layer3.1_p和layer4.1_g,此特征图既包含高层语义又含有低层特征。而且在以上特征图上使用全局最大值池化,可以消除背景杂波的影响,使网络更加关注目标行人肢体特征和实时特征。为了不增加算法运行负载,本发明分别将以上池化后的特征向量进行降维,实现了精度和效率的平衡。通过融合以上特征向量,本发明可以克服尺度变化和相似行人误检,提高了行人重识别的精度。
与现有技术相比,本发明的有益效果是:本发明提出了一个新颖的行人重识别特征提取网络。通过利用底层特征图,可以包含更多行人图像的微小细节信息,使提取的特征更易于区分相似行人;通过将高层特征图和底层特征图的融合,使提取的特征克服尺度变化。在训练过程中,使网络更关注微小细节信息和克服尺度变化带来的影响,提升了卷积提取特征的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!