一种基于Text-Rank和Logistic回归的文本分类方法及系统与流程
本发明涉及自然语言处理中的文本分类领域,具体地说是一种基于text-rank和logistic回归的文本分类方法及系统。
背景技术:
互联网时代,我们身处的环境周围每时每刻都在产生海量的非结构化文本数据,各种社交媒体、电商网站、社会服务网站等,都有大量关于用户对商品、服务等不同事物的评论以及各类新闻等文本信息,通过分析评论信息,我们可以从中得到人们对各种事物的个人态度和情感倾向,对于新闻等文本信息,我们可以从中挖掘新闻分类、新闻摘要等重要信息,这些文本信息挖掘对社会发展、科技进步都有着至关重要的意义。
虽然现在深度学习占据着人工智能的主流地位,深度学习也是一个较为活跃的领域,但深度学习模型的复杂性和模型可解释性仍然是目前一个比较棘手的问题,因此,使用简单、可解释性强且可并行处理的方法对文本信息分类具有十分重要的意义。
技术实现要素:
本发明的技术任务是解决现有技术的不足,考虑使用比较简单、可解释性强且可并行处理的logistic回归模型用于文本信息的分类,同时考虑到文本信息中可能存在大量的冗余信息,采用text-rank算法对文本信息进行提取关键词,以使后续模型训练时所需的参数更少,模型更简单轻量。
本发明解决其技术问题所采用的技术方案是:
1、本发明提供一种基于text-rank和logistic回归的文本分类方法,包括如下步骤:
步骤s1.收集各种类型的文本资料;
步骤s2.对收集的文本资料中的信息进行预处理;
步骤s3.利用text-rank算法,对处理好后的文本数据进行关键词提取;
步骤s4.训练logistic回归模型用于文本资料的分类。
方案优选地,步骤s2对初始文本数据集进行预处理包括:去除无用的符号信息,对文本进行分词,去除停用词,对类别数据进行量化处理,对分词后的文本数据进行序列化处理。
方案优选地,步骤s4具体包括如下步骤:
步骤s401.利用分割函数将步骤s3处理后的训练数据集随机分割为训练集、测试集、验证集;
步骤s402.将输入数据转换为固定尺寸的稠密向量;
步骤s403.定义训练停止函数用于模型训练中,训练停止函数能够及时将训练中的logistic回归模型及时停止,以防logistic回归模型出现过拟合或欠拟合;
步骤s404.获得训练好的logistic回归训练模型。
方案优选地,步骤s401具体步骤为:
利用分割函数train_test_split()对步骤s3处理后的训练数据集按给定的比例0.85进行随机分割为训练集和测试集,以用于后续的模型训练和模型预测;然后将分割出的训练集再按照给定的比例0.10进行随机分割出验证集,以在模型训练阶段验证模型的有效性。
方案优选地,执行步骤s402时,输入数据通过embedding层转换为固定尺寸的稠密向量。
方案优选地,执行步骤s403时,具体步骤为:
每次全部训练数据训练结束后,logistic回归模型会在验证文本集上进行验证,并记录验证集损失;随着训练epoch的增加,验证集损失会先逐渐降低,后逐渐上升,经过一定次数的epoch训练后,如果验证集损失仍然处于上升趋势,训练停止函数会及时停止模型的训练,并将停止训练后的模型参数作为最终logistic回归模型学习到的权重参数。
方案优选地,步骤s404具体步骤为:
在每次epoch训练中,将把s401中分割出的训练集和验证集分批次送入logistic回归模型,用于模型训练和效果验证,通过s403中的训练停止函数有效控制模型训练的及时停止,尤其避免过拟合,最终将训练好的logistic回归模型用于文本信息分类的应用。
2、本发明另提供一种基于text-rank和logistic回归的文本分类系统,包括:
数据收集模块:
收集各种类型的文本资料信息;
数据预处理模块:
对收集的文本资料中的信息进行预处理;
利用text-rank算法,对处理好后的文本数据进行关键词提取;
模型系统:
训练logistic回归模型用于文本资料的分类。
本发明的一种基于text-rank和logistic回归的文本分类方法及系统与现有技术相比所产生的有益效果是:
1、本发明利用text-rank算法进行关键词提取,去除了文本中大量的重复冗余信息,使后续模型训练时所需的参数更少,使logistic回归训练模型更简单轻量;
2、本发明使用复杂性低、可解释性强且能并行处理数据的logistic回归算法进行模型训练,使分类结果简单明了,易于解释;
3、本发明的一种基于text-rank和logistic回归算法的文本分类方法及系统,为文本类的非结构化数据分类提供了一个有价值的参考。
附图说明
为了更清楚地描述本发明一种基于text-rank和logistic回归的文本分类方法及系统的工作原理,下面将附上简图作进一步说明。
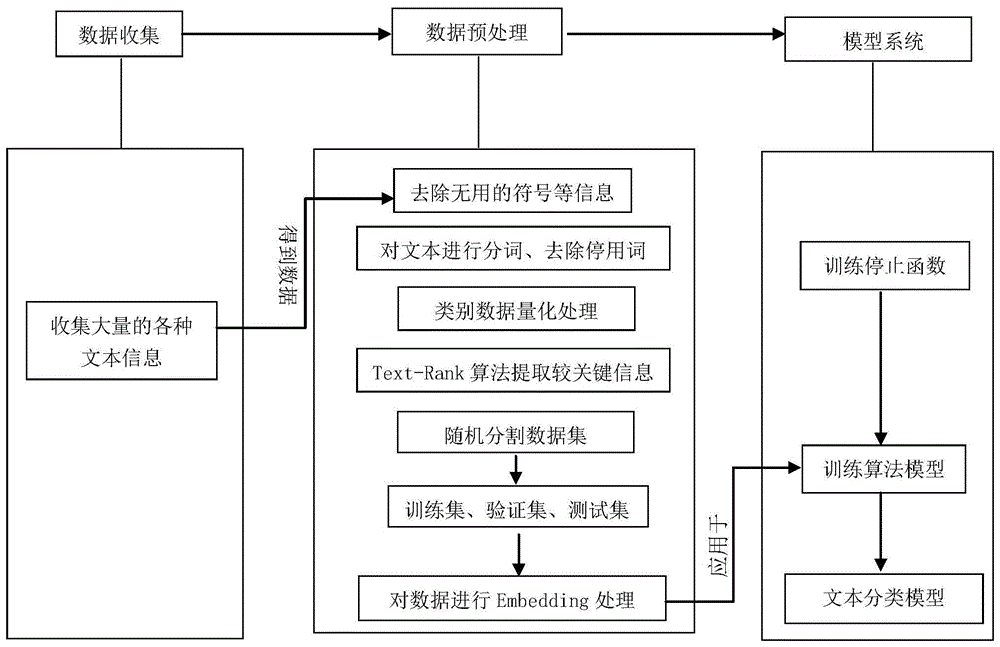
附图1是本发明基于text-rank和logistic回归算法的文本分类方法流程图。
具体实施方式
下面将结合本发明实施例中的附图1,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
大数据时代,文本信息的产生无处不在,无论个人还是企业,如果能从大量的文本信息中挖掘出对自己有益的信息,将具有重要的意义。所以,本专利中将结合text-rank和logistic回归算法对文本信息进行分类。
实施例一
如附图1所示,本发明提供一种基于text-rank和logistic回归的文本分类方法,包括如下步骤:
步骤s1.首先收集大量的各种文本信息,得到初始的文本数据集;
步骤s2.对初始文本数据集进行预处理,实施步骤如下:
去除无用的符号等信息,对文本进行分词,去除停用词,对类别数据进行量化处理,对分词后的文本数据进行序列化处理等步骤,得到预处理后的文本分词数据集;
步骤s3.对预处理后的文本数据集的词向量应用text-rank算法提取出文本中较关键的信息,去除一些冗余信息,以减少训练模型中的参数个数,降低训练模型的复杂性;
步骤s4.训练logistic回归模型用于文本资料的分类,具体步骤为:
步骤s401.利用分割函数将步骤s3处理后的训练数据集随机分割为训练集、测试集、验证集,实施步骤如下:
利用分割函数train_test_split()对步骤s3处理后的训练数据集按给定的比例0.85进行随机分割为训练集和测试集,以用于后续的模型训练和模型预测;然后将分割出的训练集再按照给定的比例0.10进行随机分割出验证集,以在模型训练阶段验证模型的有效性;
步骤s402.将输入数据通过embedding层转换为固定尺寸的稠密向量,减少资源占用,提高计算资源的利用率;
步骤s403.定义训练停止函数用于模型训练中,训练停止函数能够及时将训练中的logistic回归模型及时停止,以防logistic回归模型出现过拟合或欠拟合;具体步骤为:
每次全部训练数据训练结束后(即一个epoch),logistic回归模型会在验证文本集上进行验证,并记录验证集损失;随着训练epoch的增加,验证集损失会先逐渐降低,后逐渐上升,经过一定次数的epoch训练后,如果验证集损失仍然处于上升趋势,训练停止函数会及时停止模型的训练,并将停止训练后的模型参数作为最终logistic回归模型学习到的权重参数。
步骤s404.获得训练好的logistic回归训练模型,具体步骤为:
在每次epoch训练中,将把s401中分割出的训练集和验证集分批次送入logistic回归模型,用于模型训练和效果验证,通过s403中的训练停止函数有效控制模型训练的及时停止,尤其避免过拟合,最终将训练好的logistic回归模型用于文本信息分类的应用。
实施例二
本发明提供一种基于text-rank和logistic回归的文本分类系统,包括:
数据收集模块:
收集各种类型的文本资料信息;
数据预处理模块:
对收集的文本资料中的信息进行预处理;
利用text-rank算法,对处理好后的文本数据进行关键词提取;
模型系统:
训练logistic回归模型用于文本资料的分类。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!