通过对时序时间相关性建模的会话表示学习方法与流程
本发明涉及会话推荐
技术领域:
,具体涉及一种通过对时序时间相关性建模的会话表示学习方法。
背景技术:
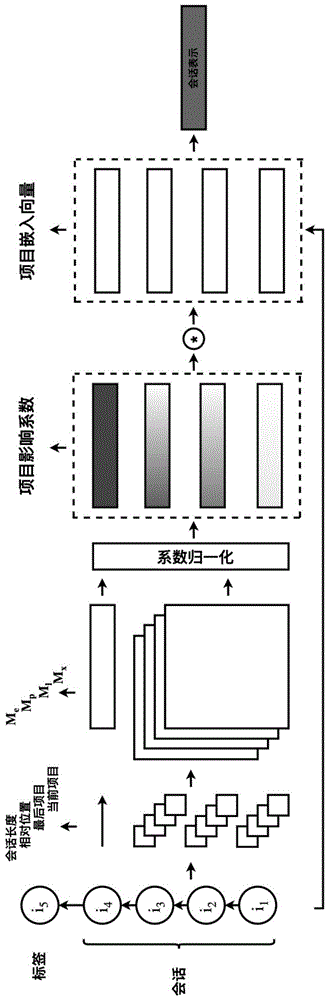
:互联网的诞生催生了海量数据,这让人们难以选择有用的信息。会话推荐是一种短期推荐,通常不跟踪用户id,仅使用短期历史记录进行推荐。由于许多平台都支持匿名访问,因此这种情况已在社交平台上广泛出现。当会话关闭时,平台将丢失匿名用户的身份。因此,关键是要利用现有会话之间的相似行为,估计用户兴趣并预测其后续行为。协同过滤是推荐系统中经典的算法之一,该算法通过用户和项目之间的交互记录来分析用户的兴趣并做出预测。协同过滤也可以在会话推荐中使用。较为常见的是item-knn方法。item-knn根据项目之间的相似性做出预测,这种方法通常仅考虑会话中用户最后一次与之交互的项目,而忽略历史交互项目对当前预测的影响。session-knn基于会话之间的相似性做出预测,通常会考虑整个会话序列,但不考虑会话中项目的时序关系。矩阵分解也是推荐系统中的经典算法,它将用户与项目之间的交互矩阵分解为用户与项目的潜在因子矩阵,然后通过内部积进行预测。在会话推荐中,我们通常使用会话和项目之间的交互矩阵,而不是用户和项目之间的交互矩阵。由于会话并不完全等同于用户,因此在实践中,该方法的实用性将降低。后来,马尔可夫链应用于会话推荐中。马尔可夫链通常只能基于局部序列构造模型,而忽略序列的历史记录。近年来,随着深度学习的发展,基于神经网络的模型已广泛应用于各种任务之中。同样的,该模型也应用于会话推荐。由于会话固有的时序性质,一些工作尝试使用递归神经网络(rnn)解决此类推荐问题。gru4rec首先将rnn应用于会话推荐,并取得了良好的效果。之后,一些工作尝试在gru4rec的基础上进行改进,包括分层rnn,数据增强,融合注意力机制,融合邻居会话和融合图网络。这些方法本质上都是基于rnn的。经实践证明,rnn可以很好地解决序列推荐问题。但是,逐次融合项目的rnn策略,始终在寻找局部最优融合策略,很难找到长序列项目的最优融合方式。技术实现要素:本发明的目的在于提供一种通过对时序时间相关性建模的会话表示学习方法,方法整体上采用前馈神经网络构建,通过大量的学习样本来学习网络中各个部分的参数。实现本发明目的的技术方案为:一种通过对时序时间相关性建模的会话表示学习方法,包括以下步骤:步骤1,项目影响系数学习:根据会话序列的当前项目、最后项目、项目位置、会话长度共同学习项目影响系数并进行归一化;步骤2,会话表示学习:利用学习好的项目影响系数融合会话中所有的项目,得到最终的会话表示;步骤3,构建一个多分类的分类器,获得会话的预测概率。本发明与现有技术相比,其显著优点为:(1)在获得项目的融合系数的过程中,本发明比其他方法多考虑了项目之间的相对位置和会话长度这两个会话特征;(2)本发明提出了一种向量级的融合系数来融合序列中的项目,这种方法能够充分考虑项目分量对于最终预测的影响;(3)本发明的方法可以整体考虑会话项目的融合方案,而不是像rnn一样需要逐次融合,这样能够更容易的找到最优融合策略。附图说明图1为本发明通过对时序时间相关性建模的会话表示学习方法的流程图。具体实施方式结合图1,本发明提出一种通过对时序时间相关性建模的会话表示学习方法,该方法用于解决会话推荐问题,会话推荐的定义是预测会话下一个可能被单击的项目;已知会话点击过的项目序列,项目以索引号的形式给出;项目的其他信息和用户信息均为未知;让i={i1,i2,...,in}代表由n个项目组成的集合,∑={s1,s2,...,sm}表示由m个会话组成的集合;包含着b个项目的会话∑a即为,∑a=[ia,1,ia,2,...,ia,b],其中ia,j∈i;需要预测会话∑a下一个可能交互的项目的概率排序预测概率生成推荐列表从而进行top-k推荐。本发明的具体步骤如下:步骤1,项目影响系数学习:根据会话序列的当前项目、最后项目、项目位置、会话长度共同学习项目影响系数并进行归一化;设有一个包含k个项目的会话序列,∑1=[i1,i2,...,ik],其中ij∈i。会话中除去最后一项的项目影响系数向量的公式如下:对于序列∑1,上述公式可以计算项目ia的影响系数向量;cp表示除最后一项之外的其他项目的影响系数向量,其中cp∈rd,d是项目的嵌入维度;表示项目ia的影响系数向量。mx,ml,mp,me是四个影响系数矩阵,我们将在后面详细介绍。ia,ik,k-1,k分别表示项目a的索引号,项目k的索引号,项目a和项目k之间的距离,会话的长度。bx,bl,bp,be代表相应的偏置参数,其中bx∈rd,bl∈rd,bp∈rd,be∈rd。σ表示非线性激活函数。mx为项目自身影响系数矩阵,表示项目本身对影响系数的影响。mx是一个从项目索引号到系数向量的映射集,包含着所有项目的系数向量。mx∈rn×d,其中n表示项目的数量,d表示项目的嵌入维度。mx是一个可学习的参数矩阵。ml为会话最后一项影响系数矩阵,表示会话序列中最后一项项目对影响系数的影响。ml是一个从项目索引号到系数向量的映射集,包含着所有项目的系数向量。ml∈rn×d,其中n表示项目的数量,d表示项目的嵌入维度。ml是一个可学习的参数矩阵。mp为会话项目位置影响系数矩阵,表示会话序列中任意一个项目与最后项目的距离对影响系数的影响。mp是一个从距离到系数向量的映射集,包含着数据集中所有距离的系数向量。mp∈r(maxlen-1)×d,其中maxlen表示会话的最大长度,d表示项目的嵌入维度。mp是一个可学习的参数矩阵。me为会话长度影响系数矩阵,表示会话序列长度对影响系数的影响。me是一个从长度到系数向量的映射集,包含着数据集中所有序列长度的系数向量。me∈rmaxlen×d,其中maxlen表示会话的最大长度,d表示项目的嵌入维度。me是一个可学习的参数矩阵。会话中最后一项的项目影响系数向量的表达式如下:对于序列∑1,上述公式可以计算项目ik的影响系数向量,也就是会话最后一项项目的影响系数向量。cl表示最后一项的影响系数向量,其中cl∈rd,d是项目的嵌入维度。表示ik的影响系数向量。1d表示维度为d且每个分量都为1的向量。σ表示cp的非线性激活函数。影响系数的归一化公式如下:对于序列∑1,上述公式可以计算项目ix经过归一化的影响系数向量。ix表示序列中的任意项目。n表示经过归一化的影响系数向量,其中n∈rd,d表示是项目嵌入维度。步骤2,会话表示学习:利用学习好的项目影响系数融合会话中所有的项目,得到最终的会话表示;在会话推荐中,通常使用嵌入层把项目转化成一个高维稠密向量。这里本发明使用了同样的方法。嵌入层是一个前馈神经网络,它将项目的索引号投射到高维空间。会话表示公式如下:序列∑1的会话表示如上式所示,其中表示项目ij经过归一化后的影响系数向量,其中e表示项目的嵌入矩阵,其e∈rn×d,n表示项目的数量,d表示项目的嵌入维度。根据项目的索引号找到对应项目的嵌入向量。表示项目ij的嵌入向量。*表示哈德玛积。步骤3,构建多分类器,进行模型预测;在获得会话表示之后,计算所有候选项目的得分其中会话预测得分公式如下:这里,使用批梯度下降法进行训练。应该注意的是,本发明首先提取了序列的相应特征。序列特征包括当前项目的索引号,最后一个项目的索引号,项目的位置信息和序列的长度信息。这些序列特征是模型的输入。序列的真实标签是该序列下一次点击的项目。使用softmax函数作为损失函数,使用adam作为优化器。损失函数公式如下:其中p代表会话的真实概率分布,也就是独热向量,p∈rn。表示会话的预测分布,最后,我们可以学习反向传播(bptt)得到所有的参数值。下面结合实施例对本发明进行详细说明。实施例1本实施例采用2015年recsys挑战赛的yoochoose数据集。数据过滤掉长度为1的会话和出现次数小于5次的项目,测试集为最后一天的会话,共55,898个,训练集为离最后一天最近的1/64时间切片,共369,859个。项目嵌入矩阵维度为150,激活函数为sigmoid,训练epoch为100,学习率为0.001。本实施例的测试结果使用recall和mrr进行评估,结果如下:recallmrr71.7730.55实施例2本实施例采用2016年cikm挑战赛的dignetica数据集。数据过滤掉长度为1的会话和出现次数小于5次的项目,测试集为最后七天的会话,共60,858个,训练集为剩余的其他会话,共369,859个。项目嵌入矩阵维度为150,激活函数为sigmoid,训练epoch为100,学习率为0.001。本实施例的测试结果使用recall和mrr进行评估,结果如下:recallmrr54.5618.74本发明对序列中时序相关性建模来学习会话表示,考虑了会话的序列性质;充分考虑了不同时序特性对于会话表示的贡献,可以获得更高的预测结果。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1