一种基于单张人脸图片的三维人脸重建方法和系统与流程
本发明涉及计算机视觉与曲面重建
技术领域:
,更具体地说,涉及一种基于单张人脸图片的三维人脸重建方法和系统。
背景技术:
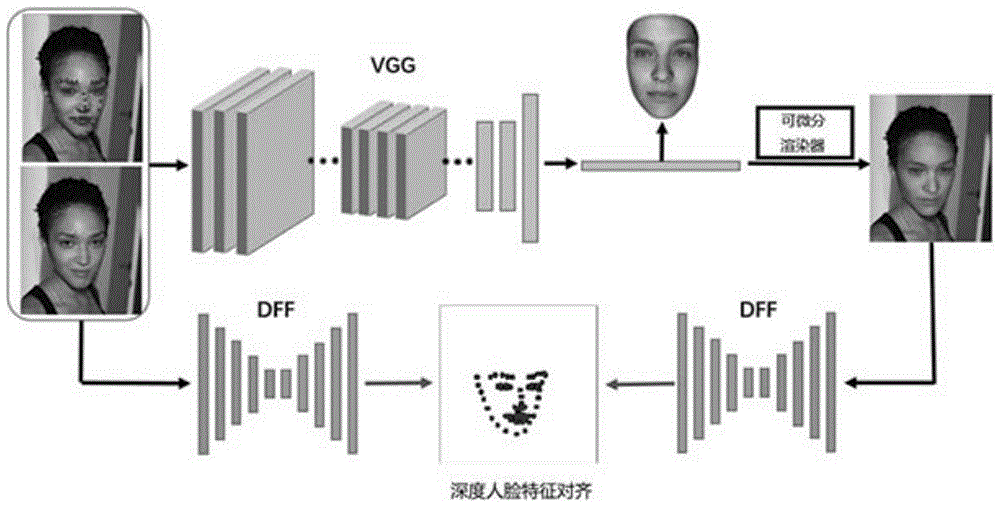
:在卷积神经网络(convolutionalneuralnetworks,cnns)出现之后,基于卷积神经网络的方法在三维人脸重建方面取得了显著的成功,这些方法通常使用卷积神经网络来预测三维形变模型(3dmorphablemodel,3dmm)的系数。三维形变模型采用网格模型,和点云模型相比,网格模型拥有更好的人脸先验拓扑关系,显著提高了三维人脸重建的质量和效率。基于卷积神经网络的方法通常需要大量的数据集。这些数据集采集往往代价较高,甚至在很多场景下无法实现。最近一些方法使用合成数据进行训练,也有例如300w-lp这样的公开合成人脸数据集。但是通过合成方法生成的人脸图片通常与真实图片之间存在一定的差距,它们在表情、光照、背景方面缺乏多样性,这往往导致训练好的卷积神经网络模型泛化性能较差。为了解决三维人脸重建数据集缺失的问题,一些最近工作使用弱监督学习的方法。这些方法仅需要二维人脸图片以及其对应的二维人脸特征点。使用此方法,经过训练的三维人脸重建模型可以很好地进行三维人脸重建以及密集三维人脸对齐。现阶段很容易获得带有二维人脸特征点的人脸图片数据集,因此可以建立大量训练集以满足卷积神经网络的需要。此外,这些二维人脸特征点也可以提供很有价值的人脸信息。目前使用弱监督的三维人脸重建方法的关键是使用一种可微分渲染器将重建好的三维人脸渲染到像素层面,并且比较该渲染后图片与输入图片之间的差异。例如tewari等人在‘self-supervisedmulti-levelfacemodellearningformonocularreconstructionatover250hz’(《超250赫兹单目重建的自我监督多层次人脸模型学习》)和‘mofa:model-baseddeepconvolutionalfaceautoencoderforunsupervisedmonocularreconstruction’(《mofa:用于无监督单目重建的基于模型的深度卷积人脸自动编码器》)论文中使用渲染后图片与输入图片在像素颜色之间的差异建立损失函数;genova等人在‘unsupervisedtrainingfor3dmorphablemodelregression’(《三维形变模型回归的无监督训练》)论文中使用人脸识别网络来建立渲染后图片与输入图片之间的损失。现有技术中由于点云数据缺乏点与点之间的拓扑关系,通过点云进行三维人脸重建的方法计算量大,重建出的模型较为粗糙。仅使用像素层面的信息建立损失函数,往往会导致卷积神经网络模型陷入局部次优解,且在人脸角度较大的图片上进行三维人脸重建效果不够鲁棒,三维人脸重建质量不高。技术实现要素:针对现有技术中存在的点云重建出的模型较为粗糙,像素层面信息建立的损失函数会导致卷积神经网络模型陷入局部次优解,人脸角度较大的图片上进行三维人脸重建效果不够鲁棒的问题,本发明提供一种基于单张人脸图片的三维人脸重建方法和系统,它可以实现充分利用输入人脸图片和渲染人脸图片在深层特征空间的对应关系,训练端到端的三维人脸重建回归网络,提高三维人脸重建的质量,使计算结果更加准确,且只需用单张人脸图片作为网络输入,成本低。本发明的目的通过以下技术方案实现。一种基于单张人脸图片的三维人脸重建方法,包括以下步骤:步骤s1:输入人脸图片,对图片进行人脸检测和特征点检测,裁剪人脸区域;具体分别为通过人脸检测方法对输入图片进行人脸检测,以及通过人脸特征点检测方法进行特征点检测,裁剪出正方形的人脸区域,调整图片大小为224×224;步骤s2:回归三维人脸参数,所述三维人脸参数包括三维形变模型的系数、相机系数和球谐光照系数;根据步骤s1得到大小为224×224×3的人脸图片以及其对应的68个二维人脸特征点信息,将对应参数输入到回归模块,回归出人脸图片对应的三维人脸参数;步骤s3:通过步骤s2得到的三维人脸参数重建出对应的三维人脸模型,通过加入球谐光照系数模拟环境光的变化,重建出对应的三维人脸模型的形状和纹理。然后通过渲染器将重建出的三维人脸模型渲染到二维平面上,将输入人脸图片和渲染后的人脸图片反馈到深度人脸特征模型,建立损失函数,最后训练整体的卷积神经网络框架。人脸图片渲染时使用全透视投影经过一个可微分的渲染器将重建出的三维人脸模型渲染到二维平面上。更进一步的,步骤s3中损失函数为:lloss(x)=ωlandlland(x)+ωphotolphoto(x)+ωdffldff(x)+ωreglreg(x),其中,x表示三维人脸参数,lland(x)为特征点对齐的损失函数,lphoto(x)为像素之间差异的损失函数,ldff(x)为深度人脸特征(dff)模型在深层特征空间建立的损失函数,lreg(x)为正则化项,ωland、ωphoto、ωdff和ωreg均为损失函数的权重系数。本发明提出了一种鲁棒的损失函数,端到端地训练三维人脸重建回归网络,该损失函数不仅考虑特征点和像素层面,还在深层特征空间建立损失。正则化项的设置是为了让三维形变模型的参数满足统计意义的分布。更进一步的,深度人脸特征模型在深层特征空间建立的损失函数为:其中i包括1至68的自然数,表示人脸特征点,和分别为人脸特征点在特征图d和特征图d’中对应的特征向量,fi∈{0,1}为人脸特征点的可见性权重。ldff(x)为深度人脸特征模型(boyijiang,juyongzhang,bailindeng,yudongguo,andligangliu.《用于人脸对齐和重建的深度人脸特征》(deepfacefeatureforfacealignmentandreconstruction.arxiv:computervisionandpatternrecognition,2017.)在深层特征空间建立的损失函数。该损失函数的目标是寻找输入的单张人脸图片和渲染人脸图片在卷积神经网络深层特征空间的对应关系,从而优化三维人脸模型参数以及相机参数。深度人脸特征模型是一种基于深度卷积神经网络的端到端的方法,为每个人脸图像像素提取一个考虑全局信息的特征向量。在得到预测的三维人脸之后,将该三维人脸渲染到像素空间上,得到的图像记为i’,输入的单张人脸图片记为i。将i和i’输入到深度人脸特征模型中,得到和原图一样大小的特征图d和特征图d’,输入的图片大小同为224×224×3,输出的特征图大小同为224×224×32。更进一步的,人脸特征点可见时可见性权重fi=1,人脸特征点不可见时可见性权重fi=0。更进一步的,损失函数的权重系数中,ωland=400、ωphoto=100、ωdff=10-6以及ωreg=1。根据有限次的实验结果分析,为了平衡各个部分的损失函数,本发明的权重系数设置所述数值。更进一步的,步骤s2中采用vgg-16卷积神经网络回归出人脸图片对应的三维人脸参数。更进一步的,所述三维形变模型的系数包括三维形变模型形状参数、三维形变模型纹理参数和三维形变模型表情参数;所述相机系数包括相机旋转参数和相机平移参数。更进一步的,步骤s1中采用dlib作为人脸检测算法,使用2d-to-3d-fan(二维至三维人脸对齐网络,2d-to-3dfacealignmentnetwork)进行特征点检测。其中,2d-to-3d-fan(二维至三维人脸对齐网络,2d-to-3dfacealignmentnetwork)出自bulata,tzimiropoulosg.的论文howfararewefromsolvingthe2d&3dfacealignmentproblem?(《我们距离解决二维和三维人脸对齐问题还有多远?》)。dlib的核心原理是使用了图像方向梯度直方图(hog)特征来表示人脸,和其他特征提取算子相比,它对图像的几何和光学的形变都能保持很好的不变形。本发明使用的人脸特征点检测方法,结合已有的最优的关键点检测的网络结构,在一个大规模综合扩展了二维数据集上进行训练,训练了一个三维人脸对齐网络,充分利用影响三维人脸对齐性能的因素,如姿态、初始值、分辨率以及网络的尺寸等,区别于现有技术中的二维人脸特征点检测,本发明基于三维人脸特征点进行检测,检测精度更高,效果更好,且适合在深层特征空间进行对比计算。本发明三维人脸重建方法直接使用单张人脸图片作为输入,不需要复杂昂贵的三维扫描设备,降低三维人脸重建的成本。回归模块基于弱监督学习的卷积神经网络,提高三维模型重建的精度,计算时充分利用输入人脸图片和渲染人脸图片在深层特征空间的关系,训练端到端的三维人脸重建回归网络,提高三维人脸重建的质量。通过建立大规模的人脸图片训练集,训练出的模型对于不同角度的人脸图片保持鲁棒性,重建结果更加准确,更符合需要。一种基于单张人脸图片的三维人脸重建系统,使用所述的一种基于单张人脸图片的三维人脸重建方法,系统包括回归模块和深度人脸特征提取模块,人脸图片通过回归模块回归三维人脸参数,训练时通过深度人脸特征提取模块提取的人脸图片在深度卷积层上的特征改进回归模块的重建效果。更进一步的,所述深度人脸特征提取模块采用深度人脸特征(dff)模型,将输入人脸图片和三维人脸模型渲染得到的图片同时输入到深度人脸特征(dff)模型中,在深层特征空间建立损失函数,优化卷积神经网络模型。本发明三维人脸重建系统包括一种基于弱监督学习的卷积神经网络(cnn)模型,用于回归三维形变模型(3dmm)的系数,以便从单张人脸图片进行准确的三维人脸重建。同时,本发明设计了一种新的损失函数,该损失函数不仅考虑了输入人脸图片和渲染人脸图像在特征点和像素层面的差异,也考虑在卷积神经网络深层特征空间的差异。本发明损失函数中,在深层特征空间建立的损失函数的目标是寻找输入的单张人脸图片和三维人脸渲染得到的图片在卷积神经网络深层特征图的对应关系,进而优化三维人脸模型参数,提高三维人脸重建的质量。本发明有益效果:1、本发明设计一个可以端到端训练的三维人脸重建回归网络。只需要一张人脸图片就可以实现三维人脸重建,减少对复杂的高精度三维扫描设备的依赖,降低三维人脸重建的成本。在大角度人脸图片上也可以保持三维人脸重建的鲁棒性。2、本发明三维人脸重建时在卷积神经网络中加入深度人脸特征提取模块,在损失函数中设置深度人脸特征模型在深层特征空间的损失函数,通过在深层特征空间进行人脸特征向量对齐,为输入人脸图片和渲染人脸图片中的每一个像素提取一个考虑全局特征的特征向量,提高三维人脸重建的质量,使计算结果更加准确。附图说明图1为本发明三维人脸重建方法的框架图。图2为本发明三维人脸重建方法的流程图。图3为本发明一实施例三维人脸重建实验结果示意图。具体实施方式在下文中将结合附图对本发明的示范性实施例进行详细描述。为了清楚和简明起见,在说明书中并未描述实际实施方式的所有特征。然而,应该了解,在开发任何这种实际实施方式的过程中必须做出很多特定于实施方式的决定,以便实现开发人员的具体目标,例如,符合与系统及业务相关的那些限制条件,并且这些限制条件可能会随着实施方式的不同而有所改变。此外,还应该了解,虽然开发工作有可能是非常复杂和费时的,但对得益于本公开内容的本领域技术人员来说,这种开发工作仅仅是例行的任务。在此,还需要说明的一点是,为了避免因不必要的细节而模糊了本发明,在附图中仅仅示出了与根据本发明的方案密切相关的装置结构和/或处理步骤,而省略了与本发明关系不大的其他细节。另外,还需要指出的是,在本发明的一个附图或一种实施方式中描述的元素和特征可以与一个或更多个其它附图或实施方式中示出的元素和特征相结合。图1所示为本实施例算法流框架图,一种基于单张人脸图片的三维人脸重建系统,包括回归模块和深度人脸特征提取模块,人脸图片通过回归模块回归三维人脸参数,训练时通过深度人脸特征提取模块提取的人脸图片在深度卷积层上的特征改进回归模块的重建效果。所述回归模块输入人脸图片及对应的特征点信息,通过vgg-16卷积神经网络返回人脸的三维形变模型(3dmm)的系数、相机系数和球谐光照系数。所述深度人脸特征提取模块提取人脸图片在深度卷积层上的特征,并在深层特征空间建立损失函数,优化卷积神经网络模型,通过一个可微分的渲染器将重建出的三维人脸模型渲染到二维平面上,将输入人脸图片和渲染后的人脸图片反馈到深度人脸特征(dff)模型,在深层特征空间建立损失函数,优化卷积神经网络模型,训练整体的卷积神经网络框架。图2为该算法对应流程图,结合图1和图2,所述三维人脸重建方法具体包括以下步骤:步骤s1:输入人脸图片,对图片进行人脸检测和特征点检测,裁剪人脸区域;具体为采用dlib作为人脸检测算法,裁剪出正方形的人脸区域,并且调整图片大小为224×224。同时使用2d-to-3d-fan(二维至三维人脸对齐网络,2d-to-3dfacealignmentnetwork)进行特征点检测。其中,2d-to-3d-fan(二维至三维人脸对齐网络,2d-to-3dfacealignmentnetwork)出自bulata,tzimiropoulosg.的论文howfararewefromsolvingthe2d&3dfacealignmentproblem?(《我们距离解决二维和三维人脸对齐问题还有多远?》)。所述特征点检测算法提取68个特征点,其中包括52个固定的特征点和16个人脸轮廓特征点。步骤s2:回归人脸参数;将一张224×224×3大小的人脸图片以及其对应的68个二维人脸特征点信息输入到回归模块,经过回归模块中的vgg-16卷积神经网络回归出人脸图片对应的三维人脸参数如下面公式(1)所示,所述三维人脸参数主要包括三类,分别是三维形变模型(3dmm)的系数、相机系数和球谐光照系数。具体的包括:3dmm形状参数3dmm纹理参数3dmm表情参数相机旋转参数r∈so(3)、相机平移参数和球谐光照系数x=(α,β,δ,r,m,γ)(1)。本实施例使用3dmm三维形变模型来进行三维人脸重建,不仅能够保证人脸重建中不会出现非人脸的情况,也可以建立不同脸型直接的对应关系。本实施例采用输入人脸图片和其对应的68个二维人脸特征点作为弱监督信息来训练卷积神经网络模型。在基于单张人脸图片的三维人脸重建中,弱监督学习的关键是建立三维空间和二维空间的对应关系。相机模型就用于将重建好的三维人脸网络模型从三维空间转化到二维平面。为了估计人脸的姿态,还需要估计三维人脸在世界坐标系中的位置。随着阴影、镜面反射和阴影图案的变化,照明可能会对三维物体表面的外观产生重大的影响。同一个人在不同光照下的差异通常比不同的人在相同光照下的差异还要大,因此光照在人脸图片中是一个不可忽视的因素。本文选择球谐光照函数来估计光照的变化,球谐光照函数通过对于周围的环境光进行采样,生成一组系数,通过这一组系数,在渲染的过程中就可以估计出物体表面的光照,对周围的环境光进行简化。步骤s3:三维人脸重建;通过步骤s2得到的三维人脸参数重建出对应的三维人脸模型。通过加入球谐光照系数模拟环境光的变化,调整人脸姿态和光照,重建出对应的三维人脸模型的形状和纹理。随后使用全透视投影经过一个可微分的渲染器将重建出的三维人脸模型渲染到二维平面上,将输入人脸图片和渲染后的人脸图片反馈到深度人脸特征模型。分别在特征点、像素空间和深层特征空间这三方面建立损失函数。所述损失函数可以端到端地训练神经网络,所述损失函数如公式(2)所示:lloss(x)=ωlandlland(x)+ωphotolphoto(x)+ωdffldff(x)+ωreglreg(x)(2)。公式(2)中,lland(x)为特征点对齐的损失函数,lphoto(x)为像素之间差异的损失函数,ldff(x)为深度人脸特征(dff)模型在深层特征空间建立的损失函数,lreg(x)为正则化项,正则化项的设置让三维形变模型的参数满足统计意义的分布。为了平衡各个部分的损失函数,本发明将权重设置为ωland=400、ωphoto=100、ωdff=10-6以及ωreg=1。作为本实施例的进一步改进,损失函数中还可以包括特征点增强训练的损失函数。进一步对本实施例深度人脸特征模型在深层特征空间建立的损失函数进行阐述,深度人脸特征损失函数的目标是寻找输入的单张人脸图片和重建的三维人脸渲染得到的图片在卷积神经网络深层特征图的对应关系,从而优化三维人脸模型参数以及相机参数。深度人脸特征(dff)模型是一种基于深度卷积神经网络的端到端的方法,为每个人脸图像像素提取一个考虑全局信息的特征向量,深度人脸特征(dff)模型使用卷积神经网络将人脸图片的每个像素映射到一个高维点,然后将其标准化为单位长度的向量。为了有效地提取和区分人脸特征,归一化的dff特征描述子保留三维人脸表面的度量结构。在人脸特征点提取的过程中,对于在相同解剖区域的两个像素,即使它们来自具有不同姿势、比例和光照条件的不同图像,其归一化的dff特征描述子也应该彼此接近。另一方面,对于在不同面部解剖区域的两个像素,即使它们的周围像素区域具有相似的外观,其归一化的dff特征描述子也应该彼此距离足够远。为了避免人脸模型偏向针对特定特征的分割,对每张人脸生成大量的随机分割,并使用其分类损失函数之和作为训练dff特征提取网络的总体损失函数。深度人脸特征模型对人脸图片中的每一个像素都能提取一个考虑全局信息的特征向量,而特征点损失函数和像素损失函数主要考虑的是局部信息,对于具有较大姿态的人脸图片时效果不佳。在卷积神经网络的优化过程中,增加深度人脸特征提取模块能够避免仅考虑局部信息导致卷积神经网络陷入局部次优解的问题。同时,深度人脸特征提取模块受到光照、姿态以及环境等因素的影响较小,人脸特征点提取的鲁棒性较好。如表1所示,本实施例方法和3ddfa方法(出自xiangyuzhu,zhenlei,xiaomingliu,hailinshi,andstanzli,‘facealignmentacrosslargeposes:a3dsolution’(《大姿态人脸对齐:一种三维解决方案》),inproceedingsoftheieeeconferenceoncomputervisionandpatternrecognition,pp.146–155,(2016).)以及defa方法(出自yaojieliu,aminjourabloo,williamren,andxiaomingliu,‘densefacealignment’(《密集人脸对齐》),inproceedingsoftheieeeinternationalconferenceoncomputervisionworkshops,pp.1619–1628,(2017).)的实验结果对比,本实施例设置深度人脸特征模型后,面部的归一化平均误差(nme)(%)最小,表示本发明的方法效果最好,有效提升三维人脸重建的质量。表13ddfadefa本实施例nme(%)2.434.332.19本实施例的人脸图片输入三维人脸重建系统,输入人脸图片和三维人脸模型渲染得到的图片同时输入到深度人脸特征模型中,在深层特征空间建立损失函数,优化卷积神经网络模型。在得到预测的三维人脸之后,本发明将该三维人脸渲染到像素空间上,得到的图像记为i’,输入的单张人脸图片记为i。将i和i’输入到深度人脸特征模型中,得到和原图一样大小的特征图d和特征图d’,输入的图片大小同为224×224×3,输出的特征图大小同为224×224×32,深度人脸特征模型在深层特征空间建立的损失函数ldff(x)如公式(3)所示:其中i包括1至68的自然数,表示人脸特征点,和分别为人脸特征点在特征图d和特征图d’中对应的特征向量,fi∈{0,1}为人脸特征点的可见性权重,如果该特征点为可见的则fi=1,否则fi=0。特征点的可见性由三维人脸上对应点的法向量决定。最后通过反向传播训练整体的卷积神经网络框架,对单张人脸图片进行三维人脸重建。本实施例采用celeba(celebfacesattributes)和300w-lp(300wacrosslargeposes)作为训练数据集训练本方法的卷积神经网络,采用aflw2000-3d数据集进行测试,衡量本方法在三维人脸重建上的性能。celeba是一个大型人脸数据集,包括丰富的背景信息以及多样的人脸姿态,被广泛应用于人脸属性识别、人脸检测、人脸特征点检测等多个领域。300w-lp人脸数据集是对300w数据集的扩展,在300w的基础上,使用人脸解析来生成具有大姿态人脸的61225张图片,并通过人脸左右反转扩展到122450张人脸图片。aflw2000-3d数据集用于评估在具有挑战的无约束人脸图像上的三维人脸对齐,该数据集通过选择aflw中前2000张图片构建,每张图片有对应的三维点云坐标、3dmm的系数以及68个三维人脸特征点的位置。本实施例所述三维人脸模型重建实验结果如图3所示,第一行为输入的二维人脸图片,第二行为重建出的三维人脸模型渲染到原图上的效果,第三行为重建出的三维人脸模型。在多媒体视频会议中,使用本发明的三维人脸重建方法,视频会议设备中摄像头可以安装在任意处,保证三维人脸重建的精度和质量,不限制摄像头的安装位置,保证在线视频会议的稳定性。在小区、商场等安保系统中,使用本发明的三维人脸重建方法,可以快速高质量的匹配人脸信息,即使在用户佩戴口罩、墨镜等遮挡物品时,也可以准确识别,做到人员行程的准确追溯,结合大数据的运用,方便安保人员的工作。在电影电视等影像资料拍摄时,应用本发明三维人脸重建方法可以快速根据需求进行人脸修饰美化甚至在制作方需要时进行人脸替换,为后期制作人员提供便利。本发明的三维人脸重建方法,在损失函数中设置深度人脸特征模型在深层特征空间的损失函数,在回归模块设计一个端到端训练的三维人脸重建回归网络,通过在深层特征空间进行人脸特征向量对齐,提高三维人脸重建的质量。本实施例三维人脸重建方法只需要一张二维人脸图片即可实现三维人脸重建,减少对复杂的高精度三维扫描设备的依赖,成本降低,实用性强。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1