一种适用于监拍装置的深度学习网络模型快速迭代训练方法及设备与流程
本申请涉及深度学习技术领域,尤其涉及一种适用于监拍装置的深度学习网络模型快速迭代训练方法及设备
背景技术:
近年来,人工智能技术发展迅速,特别是以深度学习技术为核心的智能监控设备终端得到广泛应用。现有的监控设备终端产生大量图像数据回传云端服务器,网络带宽与计算吞吐量均成为云计算服务性能瓶颈。因此,将智能分析模型从服务器端移植到设备前端,基于设备前端的智能分析方式正越来越流行。然而,随着深度学习的网络结构越来越复杂,网络参数越来越多,资源需求越来越大,严重阻碍了深度学习网络模型在移动设备的可部署性。当前基于设备终端的智能分析方式,由于受到设备本身硬件资源的限制,无法有效利用服务器端的大型复杂模型。因此,当前部署在设备终端的都是轻量化网络模型,算力和识别精度都远远低于服务器端模型,对目标对象的检测效果与服务器端模型也存在较大差异。
而且大规模的设备终端面临的检测场景多样,环境错综复杂,目前部署的模型大都基于大量不同场景的标注数据进行基础训练,强化其泛化能力,对于部署到实际检测一线的每一场景而言,检测效果不佳。如果针对每一个设备单独进行标注训练,人工成本高,耗时费力。随着设备终端的数量越来越多,对于场景多样化的应用场景仅靠人工二次标注训练来定制化模型的工作量也呈现指数级增长,如何快速迭代设备终端模型使其适应单一场景,是目前实现模型批量定制化服务的一大阻碍。
技术实现要素:
针对上述现有技术中存在的问题,本发明实施例提出一种适用于监拍装置的深度学习网络模型快速迭代训练方法及设备,解决了对线上部署模型进行单独标注训练人工成本高、模型训练周期长的问题。
一方面,本发明实施例提供了一种适用于监拍装置的深度学习网络模型快速迭代训练方法,方法包括:分别训练离线复杂模型和线上部署模型;其中,所述离线复杂模型是深度神经网络模型或者由多个深度神经网络模型级联后组成的神经网络模型,且其部署在服务器上,所述线上部署模型是轻量级神经网络模型且其部署在所述服务器对应的多个监拍装置上;基于预设时间,通过所述离线复杂模型识别来自监拍装置的并经由所述线上部署模型识别后的图像数据;确定所述多个监拍装置分别对应的线上部署模型中需要升级的线上部署模型;基于预设条件的触发,锁定需要升级的线上部署模型的网络特征提取层中预设层及预设层之前的所有层,并对所述网络特征提取层中所述预设层之后的若干层,以及所述线上部署模型的检测头网络层进行训练。
本申请实施例通过离线复杂多模型级联检测线上部署模型识别后的图像,确定需要进行升级的线上部署模型,并针对性地对需要升级的线上部署模型进行快速迭代训练,通过高精度的深度神经网络模型标注代替人工标注,使得线上部署模型的定制化升级不再需要大量的人力;另外,在线上部署模型升级时锁定指定层数的网络特征提取层,只训练未锁定的网络特征提取层和检测头网络层,也大大缩短了线上部署模型的训练周期。
在一个实施方式中,对所述网络特征提取层当前所处层数之后的若干层,以及所述线上部署模型的检测头网络层进行训练之后,所述方法还包括,将锁定的网络特征提取层的层数、训练后的网络特征提取层每层的网络权重以及训练后的检测头网络层每层的网络权重写入更新文件;通知所述需要升级的线上部署模型所在的监拍装置,以使该监拍装置获取所述更新文件,以锁定所述线上部署模型网络特征提取层中预设层及预设层之前的所有层,对预设层之后的所有网络特征提取层以及检测头网络层,根据对应的网络权重进行逐层初始化,完成模型升级。
本申请实施例通过将升级完成的线上部署模型的锁定的网络特征提取层数、训练后的未锁定网络特征提取层每层的网络权重以及检测头网络层每层的网络权重都写入更新文件进行保存,线上部署模型只需要读取更新文件里的数据,对原线上部署模型未锁定的网络层根据对应的网络权重进行逐层初始化,即可完成模型升级,极大地减少了数据传输量,无需传输整个模型,每次模型升级只需要传输一个更新文件即可。
在一个实施方式中,所述锁定需要升级的线上部署模型的网络特征提取层中预设层及预设层之前的所有层,并对所述网络特征提取层中所述预设层之后的若干层,以及所述线上部署模型的检测头网络层进行训练,具体包括:基于预设条件的触发,锁定所述线上部署模型的全部网络特征提取层,只训练检测头网络层;对训练完成后的模型进行准确率检测,若所述准确率没有达到第一预设值,则逐层减小所述预设层的数值,继续训练所述预设层之后的的网络特征提取层以及全部检测头网络层,直到训练完成后的模型准确率达到或超过第一预设值,则停止训练。
本申请实施例通过动态调整锁定的网络特征提取层的层数,在只训练检测头网络层得到的模型准确率不达标时,逐层减小锁定的网络特征提取层的层数,将剩余的网络特征提取层和检测头网络层一起训练,直到得到的线上部署模型准确率达到预设值,则停止训练,这样能够保证训练后的线上部署模型准确度接近深度神经网络的准确度,在目标检测时能够更精确地检测出目标对象,使模型更加融入所在场景。
在一个实施方式中,所述方法还包括:在初次训练线上部署模型时,将线上部署模型的网络层数据保存到网络配置文件和原始权重文件中;所述网络配置文件中包含所述线上部署模型当前使用的深度学习算法,以及所述深度学习算法的网络配置文件;所述原始权重文件包含所述线上部署模型初始状态下每层网络层的网络权重;根据所述网络配置文件和所述原始权重文件对初始线上部署模型网络结构逐层进行初始化,并将所述线上部署模型安装在各监拍装置中。
在一个实施方式中,所述通过所述离线复杂模型识别来自监拍装置的并经由所述线上部署模型识别后的图像数据之后,所述方法还包括:对由所述复杂离线模型识别后的图像数据进行目标对象的标注;将所述标注后的图像数据与对应的经由所述监拍装置上的线上部署模型识别后的图像数据作对比;若对于同一张图像,由所述复杂离线模型识别到的目标对象的类型和位置,与由所述线上部署模型识别出的类型和位置不同,则所述图像为误报图像;若对于同一张图像,由所述复杂离线模型识别出了目标对象,而所述线上部署模型未识别出目标对象,则所述图像为漏报图像。
在一个实施方式中,所述预设条件的触发,具体为:由预设周期内各线上部署模型隐患识别的漏报率和误报率确定所述各线上部署模型隐患识别的准确率;在预设周期内,任一线上部署模型的所述准确率低于相应预设值,激活所述线上部署模型的升级任务。
在一个实施方式中,所述各线上部署模型隐患识别的准确率,具体为:在所述线上部署模型升级时,在所述离线复杂模型标注后的数据中,抽取一部分作为训练样本,另一部分作为第一测试样本,在所述训练样本中再取出一部分作为第二测试样本;在对所述线上部署模型每次训练完成后,使用所述第一测试样本及第二测试样本对训练后的模型进行交叉数据验证,得到所述线上部署模型的识别准确率,以确定是否对所述线上部署模型进行更新。
在一个实施方式中,所述分别训练离线复杂模型和线上部署模型,具体包括:基于相同的大规模人工标注数据集,分别训练离线复杂模型和线上部署模型;所述离线复杂模型遍历所述大规模人工标注数据集中的图像数据;抽取识别结果中识别精度低于第二预设值的困难实例样本;针对所述困难实例样本增加新的深度学习算法,集成到所述离线复杂模型中。
本申请实施例通过同一个已经经过标注的大规模数据集来训练离线复杂模型和线上部署模型,而离线复杂模型再经过困难样本的训练,使得离线复杂模型的精确度达到一个较高的标准,能够近似代替人工标注,从而节省了大量的人力,为工作人员减轻了工作压力。
在一个实施方式中,所述方法还包括:在所述大规模标注数据集的图片中,抠取若干不同类型的目标对象,将所述抠取的若干不同类型的目标对象通过数据增强、风格迁移技术融合到所述监拍装置采集图像中的无目标图像中,得到新的有目标图像,以扩充训练样本。
另一方面,本发明实施例提供了一种基于深度学习网络模型快速迭代训练的监拍装置,包括:处理器;及存储器,其上存储有计算机可执行代码,当所述计算机可执行代码被执行时,使得所述处理器执行如权利要求1-9任一项所述的一种适用于监拍装置的深度学习网络模型快速迭代训练方法。
本发明实施例通过采用离线复杂多模型级联检测方式,与线上部署模型相结合,对场景进行联合检测。通过快速迭代线上部署模型使其适应终端设备单一场景,并能提升其检测指标,实现针对不同场景的差异化定制检测优化升级能力。随着设备终端的数量越来越多,对于场景多样化的应用场景,能够有效降低人工成本,缩短训练周期,快速模型调优升级迭代,实现模型批量定制化服务。
附图说明
此处所说明的附图用来提供对本发明的进一步理解,构成本发明的一部分,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。在附图中:
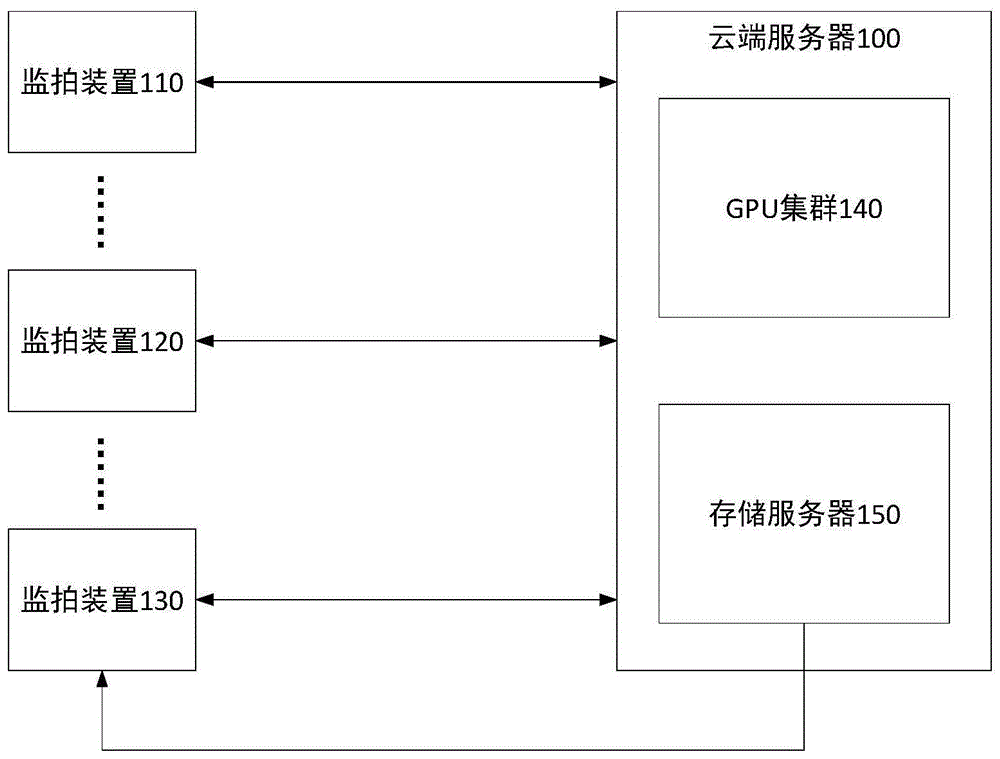
图1为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练系统示意图;
图2为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练方法流程图;
图3为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练设备示意图。
具体实施方式
为使本申请的目的、技术方案和优点更加清楚,下面将结合本申请具体实施例及相应的附图对本申请技术方案进行清楚、完整的描述。显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
现有的以深度学习技术为核心的智能监控技术,部署在设备终端的都是轻量化网络模型,检测效果与服务器端模型存在较大差异。而且部署到设备终端的模型大都是基于大量不同场景进行基础训练,泛化能力强而针对性差,对于实际单一设备下的场景目标而言检测效果不佳,漏报误报较高,需要有针对性的进行模型差异化训练。
且当前定制差异化模型训练需要大量人工二次标注确认,对于大规模设备应用场景来说工作量极大,不利于模型快速升级迭代优化。
为解决上述问题,本发明实施例提供了一种适用于监拍装置的深度学习网络模型快速迭代训练方法及设备。
下面通过附图对本申请实施例提出的技术方案进行详细的说明。
图1为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练系统示意图。
如图1所示,监拍系统包括云端服务器100和若干监拍装置,其中云端服务器100包括gpu集群140和存储服务器150;若干监拍装置包括监拍装置110、监拍装置120以及监拍装置130等。
需要说明的是,在本申请实施例的监拍系统中设置有若干监拍装置,若干监拍装置中各监拍装置与云端服务器100分别通信,监拍装置的数量可以是一个,也可以设置有多个,如图1所示,分别设置有监拍装置110、监拍装置120以及监拍装置130。本申请实施例中,各监拍装置的功能、结构以及连接关系均相同,为方便描述,以下以监拍装置110为例进行解释说明。
在一个实施例中,gpu集群140首先基于相同的大规模人工标注数据集,分别训练离线复杂模型和线上部署模型。线上部署模型是轻量级神经网络模型,安装于监拍装置110中,用于对监拍装置采集的场景图像进行目标检测。离线复杂模型是深度神经网络模型或者由多个深度神经网络模型级联后组成的神经网络模型,离线复杂模型部署在云端服务器100上,用于对线上部署模型检测后的图像进行二次检测,并标注目标对象。
具体地,监拍装置110根据预设时间间隔采集场景图像,监拍装置110上安装的线上部署模型对监拍装置110采集的场景图像进行目标检测,并标注出目标对象。监拍装置110将一个预设周期内的所有经由线上部署模型识别后的图像数据发送到云端服务器100的gpu集群140。基于预设时间间隔,或者基于触发,或者基于预设时刻,gpu集群140通过离线复杂模型对线上部署模型识别过的图像再次进行检测,并标注出目标对象。gpu集群140确定监拍装置110对应的线上部署模型是否需要升级,如果需要升级,则激活该线上部署模型的升级任务。其中,gpu集群140对线上部署模型识别图像的二次检测时间间隔,长于所述监拍装置110对采集的场景图像进行目标检测的时间间隔。
gpu集群140在确定监拍装置110对应的线上部署模型需要升级后,gpu集群140首先获取该线上部署模型,锁定该线上部署模型的全部网络特征提取层,只对该线上部署模型的检测头网络层进行迭代训练。训练结束后,gpu集群对训练后的线上部署模型进行交叉数据验证,得到线上部署模型准确率。若训练后的线上部署模型准确率没有达到预设值,则将锁定的网络特征提取层的层数减一,训练未锁定的网络特征提取层和全部的检测头网络层,循环执行锁定的网络特征提取层减一和对未锁定网络层训练,直到线上部署模型准确率达到预设值为止。
gpu集群140将更新后的线上部署模型最终锁定的网络特征提取层的层数、训练后的网络特征提取层每层的网络权重以及训练后的检测头网络层每层的权重数据写入更新文件,并将更新文件保存到存储服务器150中。监拍装置110在存储服务器150中获取对应的更新文件,按照更新文件中记载的内容,锁定指定层数的网络特征提取层,对训练后的网络特征提取层和检测头网络层,根据对应的网络权重进行逐层初始化,初始化完成后,线上部署模型更新完成。
因此,本申请实施例中的gpu集群140通过离线复杂模型与线上部署模型识别结果的对比,对线上部署模型的准确率进行判断,并对线上部署模型进行定制化升级,能够使得神经网络模型快速迭代调优,进而实现模型批量定制化服务。
图2为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练方法流程图。
s201、监拍装置定时采集场景图像,并通过线上部署模型进行目标检测。
具体地,监拍装置110按照预设时间间隔采集场景图像,并通过安装的线上部署模型对采集的场景图像进行目标检测。线上部署模型将检测出的目标对象用标注框框出,并标注目标类型,检测后图像保存到监拍装置110中。监拍装置110定时向云端服务器100发送一个周期内经线上部署模型检测后的图像。
例如,监拍装置110每间隔一小时采集一次场景图像,场景图像经线上部署模型识别后暂时保存在监拍装置110中。监拍装置110每周上传一次一周内采集并经由线上部署模型检测后的所有图像以及图像对应的目标位置和目标类型到云端服务器100。
s202、基于预设时间间隔或者基于预设时刻或者基于触发,离线复杂模型检测场景图像,生成标注数据。
具体地,离线复杂模型主要以高检测精度为目的进行设计,gpu集群140基于大规模标注数据集,利用当前检测精度高的目标检测算法训练离线复杂模型,并将几个复杂模型组合成复杂网络级联检测模型。再用这个复杂网络级联检测模型遍历大规模标注数据集中的样本,将大规模标注数据集中识别精度较低,比如低于预设值的困难样本选出,使用这些困难样本数据训练一个困难样本检测模型,并集成在该复杂网络级联检测模型中,得到最终的离线复杂模型。
可见,本申请实施例中提到的离线复杂模型并不限于指一个神经网络模型,也可以是多个深度神经网络模型级联后组成的神经网络模型。
在一个实施例中,云端服务器100基于监拍装置110上传图像的周期,或者收到监拍装置110图像传输行为的触发,启动离线复杂模型对监拍装置110上传的图像再次进行目标检测,同样将检测出的目标对象用标注框框出,并标注目标类型。经离线复杂模型标注后的图像作为标注数据,存入已标注数据集。
s203、gpu集群140确定需要升级的线上部署模型。
具体地,gpu集群140将离线复杂模型检测后的标注数据作为标准数据,与监拍装置110上传的图像数据进行一一对比。若对于同一张图像,由离线复杂模型识别出的目标对象的位置和类型,与监拍装置110的线上部署模型识别出的目标对象位置和类型不同,则该图像为误报图像。若对于同一张图像,离线复杂模型识别出了目标对象,而监拍装置110的线上部署模型未识别出目标对象,则该图像为漏报图像。除漏报图像和误报图像之外的图像即为准确图像,准确图像的数量占预设周期内监拍装置110上传的图片数量的比值,即为线上部署模型的准确率。若该准确率低于预设值,则激活对该线上部署模型的升级任务。
例如,准确率预设值为90%。若监拍装置110上传的一周内采集并识别的图像共168张,其中有12张漏报图像,8张误报图像,则准确图像为148张,得到监拍装置110对应的线上部署模型的识别准确率为
s204、gpu集群140抽取已标注数据集中该线上部署模型场景下的标注数据。
具体地,gpu集群140在已标注数据集中抽取监拍装置110对应的标注数据。需要说明的是,此处的标注数据包括在此之前的若干个周期内监拍装置110对应的所有标注数据。
例如,监拍装置110投入使用的时间为10周,相应地,已标注数据集中保存了10周中监拍装置110对应的标注数据。若第11周时线上部署模型需要训练,gpu集群需要将前11周内监拍装置110对应的标注数据全部取出。
s205、gpu集群对训练样本进行数据增强、样本增广。
由于训练神经网络模型需要大量的样本,只使用监拍装置110对应的标注数据,样本数量远远不够,因此需要对训练样本进行数据增强和扩充。具体地,gpu集群抠取大规模人工标注数据集中的各类目标对象,利用数据增强、风格迁移等技术将目标对象一一融合到监拍装置110对应的无目标图像中。
需要说明的是,抠取的各类目标对象的数量要保持相同或相近,比如各类目标对象数量之差小于某个预设值,以此均衡扩充各类训练样本。
s206、gpu集群基于当前线上部署模型,锁定指定网络层,对未锁定网络层进行调优训练。
具体地,线上部署模型文件包括网络配置文件deploy.prototxt、原始权重文件deploy.caffemodel和更新文件update.caffemodel三个文件。其中,网络配置文件中包含训练初始线上部署模型使用的深度学习算法,以及深度学习算法对应的网络配置文件;原始权重文件中包含训练完成的线上部署模型每层网络的网络权重;更新文件是后期需要升级时使用的文件,包含线上部署模型更新后每层网络的网络权重。网络配置文件和更新文件中加入超参数lock_layer,并设置初始值为0,超参数是指锁定的网络特征提取层数。
在一个实施例中,在初次训练线上部署模型时,gpu集群使用大规模人工标注数据集训练线上部署模型的所有网络特征提取层和所有检测头网络层。训练完成后的相应线上部署模型信息存入网络配置文件和原始权重文件,此时由于未锁定任何一层网络层,超参数为0。各监拍装置在云端服务器100中获取网络配置文件和原始权重文件,按照网络结构加载原始权重文件中所有层的网络权重,得到初始线上部署模型。需要说明的是,各监拍装置上初始的线上部署模型是相同的。
在确定监拍装置110的线上部署模型需要升级后,gpu集群拉取监拍装置110当前使用的线上部署模型,锁定当前线上部署模型的所有网络特征提取层,只对当前线上部署模型的检测头网络层进行训练。此时,超参数等于当前线上部署模型所有网络特征提取层数。
例如,假设该线上部署模型结构layers共有135层,其中网络特征提取层有114层,那么gpu集群则锁定该线上部署模型的前114层网络层,只对后面的21层检测头网络层进行训练,此时超参数等于114。
s207、gpu集群对训练后的线上部署模型进行交叉数据验证。
具体地,在线上部署模型升级训练时,选择一部分s204中抽取的监拍装置110对应的标注数据和s205中扩充的各类样本作为训练样本,另一部分为测试样本,并在训练样本中再取出一部分也作为测试样本,使用测试样本对训练好的线上部署模型进行交叉数据验证。将训练样本和测试样本交叉混合进行准确率验证,可以在一定程度上减小过拟合。
例如,在抽取的监拍装置110对应的标注数据和s205中扩充的各类样本中,抽取75%作为训练样本,剩余25%作为测试样本,再在训练样本中抽取10%作为测试样本,两部分测试样本混合在一起对训练好的线上部署模型进行测试。
s208、gpu集群判断训练后的线上部署模型识别准确率是否达到预设值。
具体地,gpu集群根据交叉数据验证的结果计算训练后的线上部署模型识别准确率,所述准确率为识别准确的测试样本数量占总测试样本数量的百分比。将准确率与预设值做比较,若准确率等于或大于预设值,则执行s210,若准确率小于预设值,则执行s209。
例如,预设值为90%,若计算出的准确率为85%,小于90%,则执行s209。若计算出的准确率为95%,大于90%,则执行s210。
s209、gpu集群动态调整线上部署模型锁定网络特征提取层数。
具体地,若训练后的线上部署模型准确率小于预设值,gpu集群将锁定的网络特征提取层数在当前锁定的网络特征提取层数的基础上减一,相应地,超参数也减一。调整锁定的网络特征提取层之后循环执行s206-s209,直到训练后的线上部署模型准确率达到预设值,即执行s210。
例如,当前锁定的网络特征提取层数为114层,gpu集群将锁定的网络特征提取层数调整为113层,超参数变为113。gpu集群锁定前113层网络特征提取层,训练最后一层网络特征提取层和全部的检测头网络层,得到新的线上部署模型,再对这个线上部署模型进行准确率检测,若准确率还是不达标,再将锁定的网络特征提取层数变为112,训练后两层网络特征提取层和全部的检测头网络层,以此类推,直到线上部署模型准确率达到预设值,则停止这个循环。
s210、gpu集群保存准确率达到预设值的线上部署模型,输出模型更新文件。
具体地,线上部署模型训练完成后,gpu集群将最终的超参数写入更新文件,将未锁定的网络特征提取层训练后的网络权重存入更新文件,将训练后检测头网络层的网络层权重数据存入更新文件。将上述更新文件保存在存储服务器150中。
s211、监拍装置110获取更新文件,完成升级。
云端服务器100向监拍装置110发送升级指令以及更新文件存储地址,监拍装置110根据存储地址获取更新文件。监拍装置110对应的线上部署模型保持超参数所指示的网络特征提取层不变,根据对应的网络权重对超参数之后的所有层进行逐层初始化,完成线上部署模型升级。
例如,更新文件中超参数lock_layer等于100,监拍装置110读取更新文件内容后,对应的线上部署模型锁定前100层网络特征提取层,对100层之后的网络特征提取层根据对应的网络权重逐层初始化。
需要说明的是,本申请提供的一种适用于监拍装置的深度学习网络模型快速迭代训练方法及设备不限于应用于何种场景,所检测的目标对象也不限于为何种对象,在一个实施例中,应用场景可以为输电线路,目标对象可以为隐患目标。在另一个实施例中,应用场景也可以为道路监控,目标对象可以为行人、交通工具等等。
图3为本申请实施例提供的一种适用于监拍装置的深度学习网络模型快速迭代训练设备示意图。
如图3所示,该设备包括处理器320、存储器310。
处理器320用于分别训练离线复杂模型和线上部署模型,还用于通过离线复杂模型识别来自监拍装置110的并经由线上部署模型识别后的图像数据,确定若干监拍装置分别对应的线上部署模型中哪些需要升级。
处理器320还用于锁定需要升级的线上部署模型的网络特征提取层中预设层及预设层之前的所有层,并对网络特征提取层中预设层之后的若干层以及检测头网络层进行训练。
存储器310,其上存储有计算机可执行代码,当上述计算机可执行代码被执行时,使得上述处理器310执行以上所描述的一种适用于监拍装置的深度学习网络模型快速迭代训练方法。
以上所述仅是本申请的优选实施方式,并不用于限制本申请。应当指出,对于本领域的普通技术人员来说,本申请可以有各种更改和变化。凡在不脱离本发明原理的前提下所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!