一种字符识别方法、装置及存储介质与流程
本发明涉及工业互联网的字符处理技术领域,尤其涉及一种加字符识别方法、装置及存储介质。
背景技术:
工业互联网是全球工业系统与高级计算、分析、感应技术以及互联网连接融合的一种结果。可以是通过开放的、全球化的工业级网络平台把设备、生产线、工厂、供应商、产品和客户紧密地连接和融合起来,高效共享工业经济中的各种要素资源,帮助制造业延长产业链。而在各种要素资源中有可能存在非法字符,所谓的非法字符可以是测试数据中需要进行识别的字符,以避免测试数据出现问题,或者及时识别测试过程中出现的问题。
目前,常用的字符识别算法是将字符打包成传统的打包形式,例如jar包的形式,因为这么做会导致每个需要进行非法字符过滤的服务,都要加载非法字符的词库,比如有10个服务集成了该jar包,如果非法词库的容量是1g,这样就有9g内存的浪费,可见现有技术中的非法字符过滤方式会导致内存被占用,而且降低过滤效率。
技术实现要素:
本发明的目的在于提供一种字符识别方法、装置及存储介质,旨在保证工业物联网领域中大数据的采集做到规范合法、节省内存空间且高效的qps,本发明采用be-tree的算法搭建起来微服务,可以有效防范对网站的xss攻击和非法字符的录入;避免了现有的工业场景下微服务架构中每个微服务都要加载海量词库,从而节省大量的内存空和提升服务的可用性。
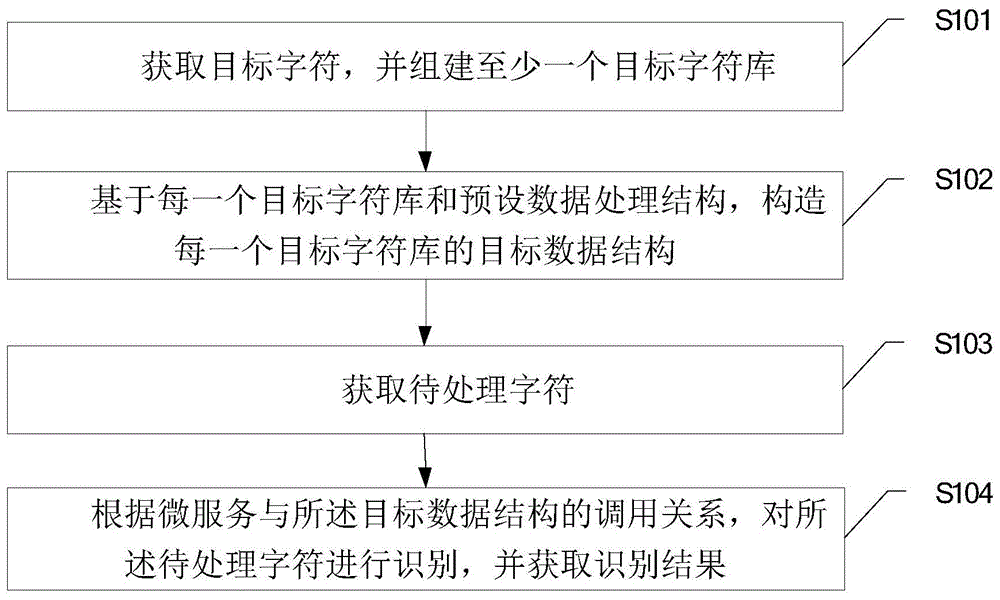
为了实现上述目的,提供了一种字符识别方法,所述方法包括:
获取目标字符,并组建至少一个目标字符库;
基于每一个目标字符库和预设数据处理结构,构造每一个目标字符库的目标数据结构;
获取待处理字符;
根据微服务与所述目标数据结构的调用关系,对所述待处理字符进行识别,并获取识别结果。
一种实现方式中,所述获取目标字符,并组建至少一个目标字符库的步骤包括:
获取非法字符,其中,所述非法字符为预先设定的字符;
将所述非法字符确定为目标字符;
将所述目标字符组成目标字符库;
将所述目标词库对应的数据加载到数据处理的内存中。
一种实现方式中,所述基于每一个目标字符库和预设数据处理结构,构造每一个目标字符库的目标数据结构的步骤,包括:
确定预设数据处理结构为be_tree数据结构;
根据所述be_tree数据结构,将每一个目标字符库构造成树形数据结构。
一种实现方式中,所述根据微服务与所述目标数据结构的调用关系,对所述待处理字符进行识别,并获取识别结果的步骤,包括:
基于所述数据处理的内存调取所述树形数据结构;
对所述待处理字符进行过滤,获取字符过滤结果;
判断所述字符过滤结果中是否包含与所述待处理字符相同的字符;
如果是,则确认所述待处理字符包含非法字符。
一种实现方式中,所述对所述待处理字符进行过滤,获取字符过滤结果的步骤,包括:
当所述待处理字符为多个字符时,获取所述待处理字符中的第一字符;
基于所述第一字符进行过滤,并获取字符过滤结果;
如果所述字符过滤结果中包含与所述第一字符相同的字符,则获取所述待处理字符中的第二字符;
基于所述第一字符子在所述树形数据结构中的位置,对所述第二字符进行过滤处理,并获取过滤结果;
其中,所述第一字符的顺序在所述第二字符之前。
一种实现方式中,所述将每一个目标字符库构造成树形数据结构的步骤,包括:
采用hashmap,将每一个目标字符库构造成树形数据结构。
一种实现方式中,所述方法还包括:
获取第一字符在所述树形数据结构中的行位置;
判断是否为树形数据结构的该行位置的最后一个字;
如果否,则在树形结构中设置该字符的位置为第一标志位;
否则,在树形结构中设置该字符的位置为第二标志位。
一种实现方式,所述方法还包括:
若为第二标志位,则结束该行搜索;
否则,基于第二字符继续执行对该行的搜索。
所述树形此外,本发明还公开了一种字符识别装置,所述装置包括处理器、以及通过通信总线与所述处理器连接的存储器;其中,
所述存储器,用于存储字符识别程序;
所述处理器,用于执行所述字符识别程序,以实现任一项所述的字符识别步骤。
以及公开了一种存储装置,所述存储装置为计算机存储装置,其上存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以使所述一个或者多个处理器执行任一项所述的字符识别步骤。
应用本发明实施例提供的字符识别方法,具有有益效果如下:
(1)通过采用词库的预加载和be-tree的算法,解决了工业场景中信息录入后,解决了如何在海量词库中检索快速响应的问题。
(2)通过采用独立搭建服务把需要进行非法字符过滤的服务通过feign接口的形式调用本服务。避免了工业场景下微服务架构中每个微服务都要加载海量词库,从而节省大量的内存空和提升服务的可用性。
(3)通过采用自定义注解的方式,方便集成到需要进行非法词过滤的服务。
(4)旨在保证工业物联网领域中大数据的采集做到规范合法、节省内存空间且高效的qps,本发明采用be-tree的算法搭建起来微服务,可以有效防范对网站的xss攻击和非法字符的录入。
附图说明
图1是本发明实施例字符识别方法的一种流程示意图。
图2是本发明实施例字符识别方法的一个具体实施例。
图3是本发明实施例字符识别方法的另一个具体实施例。
图4是本发明实施例字符识别方法的再一个具体实施例。
具体实施方式
以下通过特定的具体实例说明本发明的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本发明的其他优点与功效。本发明还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本发明的精神下进行各种修饰或改变。
请参阅图1-4。需要说明的是,本实施例中所提供的图示仅以示意方式说明本发明的基本构想,遂图式中仅显示与本发明中有关的组件而非按照实际实施时的组件数目、形状及尺寸绘制,其实际实施时各组件的型态、数量及比例可为一种随意的改变,且其组件布局型态也可能更为复杂。
如图1本发明提供了一种字符识别方法,所述方法包括:
s101,获取目标字符,并组建至少一个目标字符库。
需要说明的是,在工业场景中,非法字符的词库是海量的。因此,可以根据过往经验收集非法字符,具体的还可以根据实际的需求将非法字符进行分类分组,将分类后的字符作为目标字符,获得目标字符库。
本发明的一种实现方式中,所述获取目标字符,并组建至少一个目标字符库的步骤包括:
s1011,获取非法字符,其中,所述非法字符为预先设定的字符。
可以理解的是,用户可以将预先收集的字符作为非法字符,例如设置于一非法字符数据库中。
s1012,将所述非法字符确定为目标字符。
需要说明的是,目标字符为一字符识别或者过滤的依据,由于其自身是非法字符,所以在获得其他字符与其相同时,那么则视为识别到相同的违法字符,所以将预先设定的非法字符作为目标字符。
s1013,将所述目标字符组成目标字符库。
然后将目标字符组成目标字符库,使其形成一个整体,例如一个目标字符库对应一道测试工序的非法数据,或者对应一个产品的测试工具,这样便于在工业物联网中顺利进行测试,而不用中途更换非法字符,还可以在非法字符更新的时候人为的将非法字符纳入目标字符库中,形成更新后的目标字符库。
s1014,将所述目标词库对应的数据加载到数据处理的内存中。
本发明实施例中,为了进一步提高目标字符库在服务中的运行效率和速率,把目标字符库加载到内存中,这可以加快读取的效率从而缩短响应时间。因此,每次无需在到数据库中去检索输入项是否为非法字符,这样的检索的速度会提高,所以提高了非法字符的检索效率和速率。
s102,基于每一个目标字符库和预设数据处理结构,构造每一个目标字符库的目标数据结构。
本发明的一种实现方式中,所述基于每一个目标字符库和预设数据处理结构,构造每一个目标字符库的目标数据结构的步骤,包括:确定预设数据处理结构为be_tree数据结构;根据所述be_tree数据结构,将每一个目标字符库构造成树形数据结构。
本发明实施例中,通过预设的数据处理结构对数据进行处理,以利于后面的数据识别或者过滤过程。
需要说明的是,数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
因此,通过预先设置的数据处理结构与目标字符库中每一个字符之间存在的数据元素关系,从而便于查找字符。
s103,获取待处理字符。
可以理解的是,待处理字符为工业互联网系统的运行过程中所产生的字符,以便在待处理字符的处理结果产生后确认该过程是否产生非法字符。
s104,根据微服务与所述目标数据结构的调用关系,对所述待处理字符进行识别,并获取识别结果。
一种实现方式中,所述根据微服务与所述目标数据结构的调用关系,对所述待处理字符进行识别,并获取识别结果的步骤,包括:
基于所述数据处理的内存调取所述树形数据结构;对所述待处理字符进行过滤,获取字符过滤结果;判断所述字符过滤结果中是否包含与所述待处理字符相同的字符;如果是,则确认所述待处理字符包含非法字符。
本发明实施例中,在工业场景中,微服务架构下把非法字符过滤的功能搭建为一个独立的服务而节约了内存空间,通过微服务调用目标字符库,从而在需要的时候启动目标字符库,则不会持续占用内存。
从而解决了现有技术中导致每个需要进行非法字符过滤的服务,都要加载非法字符的词库,比如有10个服务集成了该jar,如果非法词库的容量是1g,这样就有9g内存的浪费,造成内存浪费,运行效率较低的问题。
应用本发明实施例,非法字符过滤服务可以做到集群化,从而应对高qps,提升系统的可用性。内存中的非法字符的词库使用be_tree的数据结构,如果词库在java中使用的是一整个字符串而要检索某个输入项是否合法效率是极低的。词库构建成树形的数据结构,这样判断一个词是否为非法词时就大大减少了检索的匹配范围。
如图3所示一种实现方式中,所述对所述待处理字符进行过滤,获取字符过滤结果的步骤,包括:
当所述待处理字符为多个字符时,获取所述待处理字符中的第一字符;
基于所述第一字符进行过滤,并获取字符过滤结果;如果所述字符过滤结果中包含与所述第一字符相同的字符,则获取所述待处理字符中的第二字符;基于所述第一字符子在所述树形数据结构中的位置,对所述第二字符进行过滤处理,并获取过滤结果;其中,所述第一字符的顺序在所述第二字符之前。
如图3所示,比如要判断”老师”是否为非法词,根据第一个字就可以确认需要检索的是那棵树如图3得树,然后通过进一步检索识别获得“老”字确定在第一行,由于字符之间的关联性,如果存在老师这两个相邻的字符,那么师不然在老的下一个字符,这样只要先检索“老”的第一个字符,也就是第一字符即可,第二字符就可以随时确定。由于,则可以减少检索的数据量,提高检索的效率。
另外需要说明的是,一种实现方式中,当字符为3个,4个或者5个甚至于更多个时,其第一字符不是顺序上的第一个字符,而是其他任意一个字符,例如当为3个字符时,可以定义其第二个字符为第一字符,那么第三个字符则为第二字符。另一种实现方式中,本发明实施例中提到第一字符和第二字符,那么实际上也可以按照字符的数量按照顺序进行定义,例如当为3个字符时,则可以按照顺序设置第一字符、第二字符和第三字符,当为4个字符时,则可以按照顺序设置第一字符、第二字符和第三字符和第四字符,按照图3所示的实施例既可以实现,本发明实施例在此不做赘述。
一种实现方式中,所述将每一个目标字符库构造成树形数据结构的步骤,包括:
采用hashmap,将每一个目标字符库构造成树形数据结构。以及,获取第一字符在所述树形数据结构中的行位置;判断是否为所述树形数据结构的该行位置的最后一个字;如果否,则设置为第一标志位;否则,设置为第二标志位。
本发明实施例中,使用hashmap来构建这个树形结构,例如:
{一={位={老={isend=0,师={isend=1}},isend=0},isend=0}
判断该字是否为该词中的最后一个字。若是表示敏感词结束,设置标志位isend=1,否则设置标志位isend=0。
通过检索”老师”如果在hashmap中查找到了,表明存在以“老”开头的非法词,设置hashmap=hashmap.get("老")。
一种实现方式中,所述方法还包括:
若为第二标志位,则结束该行搜索;
否则,基于第二字符继续执行对该行的搜索。
如上进行检索,当hashmap=hashmap.get("师"),由于师isend=1,则表示改行搜索结束。
综上所述,在图4中,首先非法词服务端形成步骤1,也就是通过加载非法词库到内存,然后将非法字符库封装成b_tree的数据结构,这个是本发明实施例的关键步骤,形成字符识别的基础。在用户端,步骤2位通过用户提交信息至微服务;然后微服务通过步骤3调用词库验证提交的信息,也就是提交待处理的字符,在非法词服务端(也就是继承了非法词库的服务的一端)在b_tree中检索非法词,然后到达步骤5返回验证结果至微服务,微服务自身执行步骤6:进行提交用户请求或者拒绝用户请求的判断,并向用户端返回提交结果,整个过程结束。
此外,本发明还公开了一种字符识别装置,所述装置包括处理器、以及通过通信总线与所述处理器连接的存储器;其中,
所述存储器,用于存储字符识别程序;
所述处理器,用于执行所述字符识别程序,以实现任一项所述的字符识别步骤。
以及公开了一种存储装置,所述存储装置为计算机存储装置,其上存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以使所述一个或者多个处理器执行任一项所述的字符识别步骤。
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何熟悉此技术的人士皆可在不违背本发明的精神及范畴下,对上述实施例进行修饰或改变。因此,举凡所属技术领域中具有通常知识者在未脱离本发明所揭示的精神与技术思想下所完成的一切等效修饰或改变,仍应由本发明的权利要求所涵盖。
- 还没有人留言评论。精彩留言会获得点赞!