一种基于kubernetes平台的集群状态自动获取方法及装置与流程
本发明涉及kubernetes平台集群领域,具体涉及一种基于kubernetes平台的集群状态自动获取方法及装置。
背景技术:
相比虚拟机上运行业务,通过容器进行业务的运转,明显的优点是轻量化,容器是基于基础操作系统的复用,不需要太多的庞大的镜像。但针对日益复杂庞大的云平台系统,各功能模块日益复杂,系统的规模无论从数量还是规模和之前都不在一个数量级,这就导致机器再启动时间慢,机器启动后集群恢复慢,而目前用户还无法监测启动过程,无法获知集群何时已启动成功,启动不成功时也无法获知故障点。
技术实现要素:
为解决上述问题,本发明提供一种基于kubernetes平台的集群状态自动获取方法及装置,在集群启动时监测集群状态,及时发出提醒。
本发明的技术方案是:一种基于kubernetes平台的集群状态自动获取方法,在集群所在主机启动时执行以下步骤:
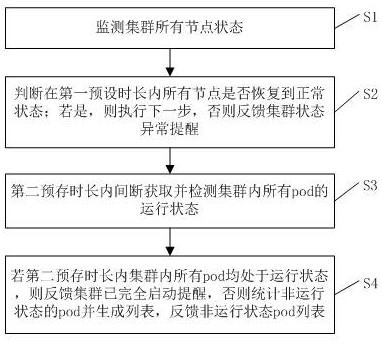
监测集群所有节点状态;
判断在第一预设时长内所有节点是否恢复到正常状态;若是,则执行下一步,否则反馈集群状态异常提醒;
第二预存时长内间断获取并检测集群内所有pod的运行状态;
若第二预存时长内集群内所有pod均处于运行状态,则反馈集群已完全启动提醒,否则统计非运行状态的pod并生成列表,反馈非运行状态pod列表。
进一步地,该方法还包括:
获取处于非运行状态pod的日志信息;
将非运行状态pod日志信息的后n行保存至一文本。
进一步地,通过调用kubelet错误排查命令获取非运行状态pod的日志信息;通过调用kubelet保存命令将获取的处于非运行状态pod相关信息保存至一文本。
进一步地,n的取值范围为10-30。
进一步地,通过kubelet的pod获取命令获取集群内所有pod的运行状态。
进一步地,该方法还包括:
获取非运行状态pod对应kubelet的服务状态信息;
获取etcd数据库内成员的状态信息;
将所获取对应kubelet的服务状态和etcd数据库内成员的状态信息保存至另一文本。
进一步地,监测集群所有节点状态,具体为:
通过网络诊断工具不断轮流发送通信包检测集群各个节点;
当某节点有返回时,表示该节点状态正常。
本发明的技术方案还包括一种基于kubernetes平台的集群状态自动获取装置,包括,
节点状态监测模块:监测集群所有节点状态;
集群状态判断模块:判断在第一预设时长内所有节点是否恢复到正常状态,若是则集群状态正常,否则集群状态异常;
第一信息反馈模块:反馈集群状态异常提醒;
pod运行状态获取模块:获取集群内所有pod的运行状态;
pod运行状态检测模块:检测集群内所有pod是否均处于运行状态;
第二信息反馈模块:反馈集群已完全启动提醒;
pod统计模块:统计非运行状态的pod并生成列表;
第三信息反馈模块:反馈非运行状态pod列表。
进一步地,还包括,
日志信息获取模块:获取处于非运行状态pod的日志信息;
日志信息保存模块:将非运行状态pod日志信息的后n行保存至一文本;其中n的取值范围为10-30。
进一步地,还包括,
kubelet服务状态信息获取模块:获取非运行状态pod对应kubelet的服务状态信息;
etcd数据库内成员状态信息获取模块:获取etcd数据库内成员的状态信息;
状态信息保存模块:将所述获取对应kubelet的服务状态和etcd数据库内成员的状态信息保存至另一文本。
本发明提供的一种基于kubernetes平台的集群状态自动获取方法及装置,在机器启动时,在预设时长内监测集群节点状态和节点内所有pod信息,在正常启动时给出启动提醒,在未正常启动时,获取到未正常启动原因,将所获取异常原因反馈给用户,当pod非正常时,还将非正常的pod列表反馈给用户。本发明供用户及时监测集群节点和pod信息,获知集群启动状况和启动异常状况,优化用户使用体验,节省启动时间。
附图说明
图1是本发明具体实施例一方法流程示意图;
图2是本发明具体实施例一一具体实现方式方法流程示意图;
图3是本发明具体实施例二结构示意框图。
具体实施方式
下面结合附图并通过具体实施例对本发明进行详细阐述,以下实施例是对本发明的解释,而本发明并不局限于以下实施方式。
以下对本发明涉及的英文进行解释。
kubernetes:简称k8s,是一个开源的,用于管理云平台中多个主机上的容器化的应用,kubernetes的目标是让部署容器化的应用简单并且高效(powerful),kubernetes提供了应用部署,规划,更新,维护的一种机制。
pod:k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被集群主节点(master)调度到一个节点(node)上运行。
kubelet:在kubernetes集群中,在每个node上都会启动一个kubelet服务进程。kubelet作为连接kubernetesmaster和各node之间的桥梁,用于处理master下发到本节点的任务,管理pod及pod中的容器。每个kubelet进程都会在api-server上注册本节点自身的信息,定期向master汇报节点资源的使用情况,并通过cadvisor监控容器和节点资源。进而实现pod的启停任务。
etcd:kubernetes提供默认的存储系统,保存所有集群数据。
实施例一
如图1所示,本实施例提供一种基于kubernetes平台的集群状态自动获取方法,在集群所在主机启动时执行以下步骤:
s1,监测集群所有节点状态;
s2,判断在第一预设时长内所有节点是否恢复到正常状态;若是,则执行下一步,否则反馈集群状态异常提醒;
s3,第二预存时长内间断获取并检测集群内所有pod的运行状态;
s4,若第二预存时长内集群内所有pod均处于运行状态,则反馈集群已完全启动提醒,否则统计非运行状态的pod并生成列表,反馈非运行状态pod列表。
本发明首先确认集群节点状态是否均正常,并做出相应提示;若集群状态正常,则继续监控集群pod状态(例如每隔1分钟进行一次k8s指令);当检测到所有pod状态为running时,则做出相应的提示,除却running以外的状态,计算非running状态的pod个数,进行计数,最终给出不正常pod的列表。
本实施例中,可通过调用相关kubernetes平台的相关命令获取pod状态等,为进一步方便运维人员进行问题诊断,具体实施时,还可记录pod日志、kubelet和ectd状态等。
为进一步对本发明进行解释,以下结合上述步骤,基于本发明原理提供一具体实现方法,如图2所示,该方法包括以下步骤。
s101,通过网络诊断工具不断轮流发送通信包检测集群各个节点,当某节点有返回时,表示该节点状态正常;
该步骤即通过ping操作不断轮流去ping集群节点,检测集群各节点是否正常重启。
s102,判断在第一预设时长内所有节点是否恢复到正常状态;若是,则执行下一步,否则反馈集群状态异常提醒;
持续ping操作十分钟,若仍有节点未返回信息(即未重启),说明集群状态异常,反馈提醒给用户,以便用户及时获知信息。若集群正常的话,则进一步检测各节点的pod状态。
s103,第二预设时长内间断获取并检测集群内所有pod的运行状态;
通过kubelet的pod获取命令获取集群内所有pod的运行状态,该命令为kubectlgetpo–nns|grep0/1,若所获取信息为running,则说明pod处于运行状态。
需要说明的是,在第二预设时长内间断发送命令获取状态信息,如10分钟内每隔1分钟发送一次命令获取pod运行状态。
s104,若第二预设时长内集群内所有pod均处于运行状态,则反馈集群已完全启动提醒,否则统计非运行状态的pod并生成列表,反馈非运行状态pod列表;
若所有pod均处于运行状态,则说明所有节点启动成功,此时集群已完成启动。若第二预设时长后,仍有pod未运行,则说明有异常pod,则统计所有异常pod,生成相关列表发送给用户,供用户了解异常点。
本实施例在预设时长内监测集群节点和pod,避免集群在异常状况下,一直处于启动状态,使用户及时了解异常,节省时间。
s105:获取处于非运行状态pod的日志信息,将非运行状态pod日志信息的后n行保存至一文本;
本实施例为进一步方便运维人员进行问题诊断,将异常pod的日志提取到一文本,运维人员在文本中查找故障原因。
具体通过调用kubelet错误排查命令(kubectldescribepo–nns)获取非运行状态pod的日志信息;通过调用kubelet保存命令(kubectllogs–f-nns)将获取的处于非运行状态pod相关信息保存至一文本。
需要说明的是,n的取值范围为10-30,即最少将异常pod日志后10行,最多将异常pod日志后30行提取出来保存。后10-30一般已包含全部故障信息。
s106,获取非运行状态pod对应kubelet的服务状态信息和etcd数据库内成员的状态信息,将所获取对应kubelet的服务状态和etcd数据库内成员的状态信息保存至另一文本;
为更全面地定位问题,本实施例还获取非运行状态pod对应kubelet的服务状态信息和etcd数据库内成员的状态信息。需要说明的是,ectd内成员与节点一一对应,若有节点异常,ectd内成员相应也会有异常。
获取非运行状态pod对应kubelet的服务状态信息的命令为systemctlstatuskubelet–l。
获取etcd数据库内成员的状态信息的命令为:
etcdurl=`dockerexecetcdps-oargs|grep-vps|grep-vcommand|awk'{print$7}'
`dockerexecetcdetcdctl--endpoints${etcdurl}cluster-health。
同样调用命令kubectllogs–f–nns>xx.log将所获取对应kubelet的服务状态和etcd数据库内成员的状态信息保存至另一文本。
实施例二
如图3所示,在实施例基础上,本实施例提供一种基于kubernetes平台的集群状态自动获取装置,包括以下功能模块。
节点状态监测模块101:监测集群所有节点状态;
集群状态判断模块102:判断在第一预设时长内所有节点是否恢复到正常状态,若是则集群状态正常,否则集群状态异常;
第一信息反馈模块103:反馈集群状态异常提醒;
pod运行状态获取模块104:获取集群内所有pod的运行状态;
pod运行状态检测模块105:检测集群内所有pod是否均处于运行状态;
第二信息反馈模块106:反馈集群已完全启动提醒;
pod统计模块107:统计非运行状态的pod并生成列表;
第三信息反馈模块108:反馈非运行状态pod列表。
进一步地,为定位问题,该装置还设置以下功能模块。
日志信息获取模块109:获取处于非运行状态pod的日志信息;
日志信息保存模块110:将非运行状态pod日志信息的后n行保存至一文本;其中n的取值范围为10-30。
kubelet服务状态信息获取模块111:获取非运行状态pod对应kubelet的服务状态信息;
etcd数据库内成员状态信息获取模块112:获取etcd数据库内成员的状态信息;
状态信息保存模块113:将所述获取对应kubelet的服务状态和etcd数据库内成员的状态信息保存至另一文本。
以上公开的仅为本发明的优选实施方式,但本发明并非局限于此,任何本领域的技术人员能思之的没有创造性的变化,以及在不脱离本发明原理前提下所作的若干改进和润饰,都应落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!