想法提案支持系统、想法提案支持装置和方法以及存储介质与流程
[0001]
本发明涉及想法提案支持系统、想法提案支持装置、想法提案支持方法以及存储介质。
背景技术:
[0002]
作为与电子计算机有关的技术,已知有从大量的数据提取与期望的信息有关的数据的技术。此外,存在一种人工智能技术(ai),其基于大量的数据提取规律性来学习对应关系,并基于学习结果来进行模式识别、最优解的选择。
[0003]
相对于此,要求人类发挥更大的创新作用。然而,经常发生如下情况:难以评估新想法(主意)的价值,从而有价值的发明经常没有被实施而被埋没,或者为实施低价值的发明而浪费精力。专利文献1公开了一种用于评估新想法的价值的技术。
[0004]
现有技术文献
[0005]
专利文献
[0006]
专利文献1:(日本)特开2002-92229号公报
技术实现要素:
[0007]
发明所要解决的课题
[0008]
但是,在一般的组织内,为了将新业务和产品的想法推进到执行阶段,有必要对想法的有用性、可实现性、收益性等制作有说服力的资料。在通常的业务中,收集针对新想法的恰当的资料并制作演讲资料时需要很多精力,经常成为有用的想法被埋没的原因。
[0009]
本发明的目的是,提供一种能够有效地降低与想法提案有关的资料的收集以及生成所消耗的精力的想法提案支持系统、想法提案支持装置、想法提案支持处理方法以及存储介质。
[0010]
用于解决课题的手段
[0011]
为了达到上述目的,技术方案1所记载的发明为,一种想法提案支持系统,其特征在于,具备:
[0012]
获取部,获取概念词;
[0013]
检索部,将所述概念词和表示针对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索;以及
[0014]
输出部,基于所述检索的结果,输出表示与所述概念词对应的所述特性的数据。
[0015]
技术方案2所述的发明为,在技术方案1所述的想法提案支持系统中,其特征在于,
[0016]
在所述辅助用语包含有与时间有关的第一类用语。
[0017]
技术方案3所述的发明为,在技术方案2所述的想法提案支持系统中,其特征在于,
[0018]
在所述第一类用语包含有时事、原委、历史、趋势、年代、年表中的至少一部分。
[0019]
技术方案4所述的发明为,在根据技术方案2或3所述的想法提案支持系统中,其特征在于,
[0020]
在与所述第一类用语有关的检索结果中获得了不同的多个时机的数据的,所述输出部将在时序内进行了合并的合并数据与所述概念词进行关联并输出。
[0021]
技术方案5所述的发明为,在根据技术方案4所述的想法提案支持系统中,其特征在于,
[0022]
具备制作基于与所述第一类用语有关的检索结果的图表数据的图表制作部,
[0023]
所述输出部输出所制作的所述图表数据。
[0024]
技术方案6所述的发明为,在根据技术方案1至5中任一项所述的想法提案支持系统中,其特征在于,
[0025]
在所述辅助用语包含有与数值规模有关的第二类用语。
[0026]
技术方案7所述的发明为,在根据技术方案6所述的想法提案支持系统中,其特征在于,
[0027]
在所述第二类用语包含有份额、销售额、利润、人数中的至少一部分。
[0028]
技术方案8所述的发明为,在根据技术方案6或者7所述的想法提案支持系统中,其特征在于,
[0029]
在与所述第二类用语有关的检索结果中获得了与相同的特性有关的不同的多个分类中的数据的情况下,所述输出部输出对该特性进行了合并的合并数据。
[0030]
技术方案9所述的发明为,在根据技术方案6至8中任一项所述的想法提案支持系统中,其特征在于,
[0031]
所述输出部将与所述第二类用语有关的多个检索结果进行组合,生成与所述特性有关的结合数据而输出。
[0032]
技术方案10所述的发明为,在根据技术方案6至9中任一项所述的想法提案支持系统中,其特征在于,
[0033]
具备制作基于与所述数值规模有关的检索结果的曲线的曲线制作部,
[0034]
所述输出部输出所制作的所述曲线。
[0035]
技术方案11所述的发明为,在根据技术方案1至10中任一项所述的想法提案支持系统中,其特征在于,
[0036]
所述检索部基于过去的检索历史信息,决定与所述概念词组合的所述辅助用语的优先顺序。
[0037]
技术方案12所述的发明为,在根据技术方案11所述的想法提案支持系统中,其特征在于,
[0038]
所述检索部从所述检索用语排除包含于所述检索历史信息的概念词。
[0039]
技术方案13所述的发明为,在根据技术方案1至12中任一项所述的想法提案支持系统中,其特征在于,
[0040]
所述检索部基于所述概念词和所述辅助用语之间的关联性,决定与所述概念词组合的所述辅助用语的优先顺序。
[0041]
技术方案14所述的发明为,在根据技术方案1至13中任一项所述的想法提案支持系统中,其特征在于,
[0042]
具备判定包含于所述检索的结果的用语和所述概念词之间的关联性的判定部,
[0043]
所述检索部将由所述判定部判定为关联性高的用语,添加至所述检索用语并重新
检索。
[0044]
技术方案15所述的发明为,在根据技术方案1至14中任一项所述的想法提案支持系统中,其特征在于,
[0045]
所述检索部将在包含于所述检索的结果的用语中的满足与出现频率有关的条件的用语,添加至检索条件并重新检索。
[0046]
技术方案16所述的发明为,在根据技术方案1至15中任一项所述的想法提案支持系统中,其特征在于,
[0047]
具备操作受理部,
[0048]
所述检索部,将由所述操作受理部受理的用语,添加至所述检索用语并进行检索。
[0049]
技术方案17所述的发明为,在根据技术方案1至16中任一项所述的想法提案支持系统中,其特征在于,
[0050]
对所述获取部能够输入包括图像数据以及语音数据中的至少一个的非文本数据以及文本数据,
[0051]
所述获取部识别所述非文本数据的内容并转换至文本数据,并从所述文本数据获取所述概念词。
[0052]
技术方案18所述的发明为,在根据技术方案17所述的想法提案支持系统中,其特征在于,
[0053]
在所述非文本数据包含有图像数据,
[0054]
所述获取部具有对所述图像数据的输入进行该图像数据的识别处理,并输出表示所述图像数据的内容的文本数据的已训练模型。
[0055]
技术方案19所述的发明为,在根据技术方案17或者18所述的想法提案支持系统中,其特征在于,
[0056]
所述获取部从所输入的文本数据提取独立词,并根据该独立词的出现频率确定并获取所述概念词。
[0057]
技术方案20所述的发明为,在根据技术方案17至19中任一项所述的想法提案支持系统中,其特征在于,
[0058]
所述获取部具有针对所述文本数据的输入,输出该文本数据的所述概念词的已训练模型。
[0059]
技术方案21所述的发明为,在根据技术方案1至20中任一项所述的想法提案支持系统中,其特征在于,
[0060]
所述获取部确定所获取的所述概念词的关联用语,并将所确定的所述关联用语添加至所述检索用语。
[0061]
技术方案22所述的发明为,在根据技术方案21所述的想法提案支持系统中,其特征在于,
[0062]
所述获取部生成具有与目标的语义相应的方向的语义向量,并将通过相对于与所述概念词对应的语义向量具有满足规定的基准的方向的语义向量来确定的文本目标,设为所述关联用语。
[0063]
技术方案23所述的发明为,在根据技术方案1至22中任一项所述的想法提案支持系统中,其特征在于,
[0064]
具备用于存储所述辅助用语的列表的存储部。
[0065]
技术方案24所述的发明为,一种想法提案支持装置,其特征在于,具备:
[0066]
获取部,获取概念词;
[0067]
检索部,将所述概念词和表示针对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索;以及
[0068]
输出部,基于所述检索的结果,输出表示与所述概念词对应的所述特性的数据。
[0069]
技术方案25所述的发明为,一种想法提案支持方法,其特征在于,包括:
[0070]
获取步骤,获取概念词;
[0071]
检索步骤,将所述概念词和表示针对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索;以及
[0072]
输出步骤,基于所述检索的结果,输出表示与所述概念词对应的所述特性的数据。
[0073]
技术方案26所述的发明为,在根据技术方案25所述的想法提案支持方法中,其特征在于,
[0074]
在所述辅助用语包含有与时间有关的第一类用语。
[0075]
技术方案27所述的发明为,在根据技术方案26所述的想法提案支持方法中,其特征在于,
[0076]
在所述第一类用语包含有时事、原委、历史、趋势、年代、年表中的至少一部分。
[0077]
技术方案28所述的发明为,在根据技术方案26或27所述的想法提案支持方法中,其特征在于,
[0078]
在与所述第一类用语有关的检索结果中获得了不同的多个时机的数据的情况下,在所述输出步,将在时序内进行了合并的合并数据与所述概念词进行关联并输出。
[0079]
技术方案29所述的发明为,在根据技术方案28所述的想法提案支持方法中,其特征在于,
[0080]
包括制作基于与所述第一类用语有关的检索结果的图表数据的图表制作步骤,
[0081]
在所述输出步骤,输出所制作的所述图表数据。
[0082]
技术方案30所述的发明为,在根据技术方案25至29中任一项所述的想法提案支持方法中,其特征在于,
[0083]
在所述辅助用语包含有与数值规模有关的第二类用语。
[0084]
技术方案31所述的发明为,在根据技术方案30所述的想法提案支持方法中,其特征在于,
[0085]
在所述第二类用语包含有份额、销售额、利润、人数中的至少一部分。
[0086]
技术方案32所述的发明为,在根据技术方案30或者31所述的想法提案支持方法中,其特征在于,
[0087]
在与所述第二类用语有关的检索结果中获得了与相同的特性有关的不同的多个分类中的数据的情况下,在所述输出步骤输出对该特性进行了合并的合并数据。
[0088]
技术方案33所述的发明为,在根据技术方案30至32中任一项所述的想法提案支持方法中,其特征在于,
[0089]
在所述输出步骤,将与所述第二类用语有关的多个检索结果进行组合,生成与所述特性有关的结合数据而输出。
[0090]
技术方案34所述的发明为,在根据技术方案30至33中任一项所述的想法提案支持方法中,其特征在于,
[0091]
包括制作基于与所述数值规模有关的检索结果的曲线的曲线制作步骤,
[0092]
在所述输出步骤,输出所制作的所述曲线。
[0093]
技术方案35所述的发明为,在根据技术方案25至34中任一项所述的想法提案支持方法中,其特征在于,
[0094]
在所述检索步骤,基于过去的检索历史信息,决定与所述概念词组合的所述辅助用语的优先顺序。
[0095]
技术方案36所述的发明为,在根据技术方案35所述的想法提案支持方法中,其特征在于,
[0096]
在所述检索步骤,从所述检索用语排除包含于所述检索历史信息的概念词。
[0097]
技术方案37所述的发明为,在根据技术方案25至36中任一项所述的想法提案支持方法中,其特征在于,
[0098]
在所述检索步骤,基于所述概念词和所述辅助用语之间的关联性,决定与所述概念词组合的所述辅助用语的优先顺序。
[0099]
技术方案38所述的发明为,在根据技术方案25至37中任一项所述的想法提案支持方法中,其特征在于,
[0100]
包括判定包含于所述检索的结果的用语和所述概念词之间的关联性的判定步骤,
[0101]
在所述检索步骤,将在所述判定步骤判定为关联性高的用语,添加至所述检索用语并重新检索。
[0102]
技术方案39所述的发明为,在根据技术方案25至38中任一项所述的想法提案支持方法中,其特征在于,
[0103]
在所述检索步骤,将在包含于所述检索的结果的用语中的满足与出现频率有关的条件的用语,添加至检索条件并重新检索。
[0104]
技术方案40所述的发明为,在根据技术方案25至39中任一项所述的想法提案支持方法中,其特征在于,
[0105]
在所述检索步骤,将通过输入操作受理的用语,添加至所述检索用语并进行检索。
[0106]
技术方案41所述的发明为,在根据技术方案25至40中任一项所述的想法提案支持方法中,其特征在于,
[0107]
在所述获取步骤,能够获取包括图像数据以及语音数据中的至少一个的非文本数据以及文本数据,并且识别所述非文本数据的内容并转换至文本数据,并从所述文本数据获取所述概念词。
[0108]
技术方案42所述的发明为,在根据技术方案41所述的想法提案支持方法中,其特征在于,
[0109]
在所述非文本数据包含有图像数据,
[0110]
在所述获取步骤,使用对所述图像数据的输入进行该图像数据的识别处理,并输出表示所述图像数据的内容的文本数据的已训练模型。
[0111]
技术方案43所述的发明为,在根据技术方案41或者42所述的想法提案支持方法中,其特征在于,
[0112]
在所述获取步骤,从所输入的文本数据提取独立词,并根据该独立词的出现频率确定并获取所述概念词。
[0113]
技术方案44所述的发明为,在根据技术方案41至43中任一项所述的想法提案支持方法中,其特征在于,
[0114]
在所述获取步骤,使用针对所述文本数据的输入,输出该文本数据的所述概念词的已训练模型。
[0115]
技术方案45所述的发明为,在根据技术方案25至44中任一项所述的想法提案支持方法中,其特征在于,
[0116]
在所述获取步骤,确定所获取的所述概念词的关联用语,并将所确定的所述关联用语添加至所述检索用语。
[0117]
技术方案46所述的发明为,在根据技术方案45所述的想法提案支持方法中,其特征在于,
[0118]
在所述获取步骤,生成具有与目标的语义相应的方向的语义向量,并将通过相对于与所述概念词对应的语义向量具有满足规定的基准的方向的语义向量来确定的文本目标,设为所述关联用语。
[0119]
技术方案47所述的发明为,在根据技术方案25至46中任一项所述的想法提案支持方法,其特征在于,
[0120]
在所述检索步骤,参照存储了所述辅助用语的列表的存储部的所述列表。
[0121]
技术方案48所述的发明为,一种存储介质,其特征在于,
[0122]
使计算机作为获取单元、检索单元以及输出单元发挥功能,
[0123]
所述获取单元获取概念词,
[0124]
所述检索单元将所述概念词和表示针对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索,
[0125]
所述输出单元基于所述检索的结果,输出表示与所述概念词对应的所述特性的数据。
[0126]
技术方案49所述的发明为,在根据技术方案48所述的存储介质中,其特征在于,
[0127]
在所述辅助用语包含有与时间有关的第一类用语。
[0128]
技术方案50所述的发明为,在根据技术方案49所述的存储介质中,其特征在于,
[0129]
在所述第一类用语包含有时事、原委、历史、趋势、年代、年表中的至少一部分。
[0130]
技术方案51所述的发明为,在根据技术方案49或50所述的存储介质中,其特征在于,
[0131]
在与所述第一类用语有关的检索结果中获得了不同的多个时机的数据的情况下,所述输出单元将在时序内进行了合并的合并数据与所述概念词进行关联并输出。
[0132]
技术方案52所述的发明为,在根据技术方案51所述的存储介质中,其特征在于,
[0133]
所述程序使所述计算机进一步作为制作基于与所述第一类用语有关的检索结果的图表数据的图表制作单元发挥功能,
[0134]
所述输出单元输出所制作的所述图表数据。
[0135]
技术方案53所述的发明为,在根据技术方案48至52中任一项所述的存储介质中,其特征在于,
[0136]
在所述辅助用语包含有与数值规模有关的第二类用语。
[0137]
技术方案54所述的发明为,在根据技术方案53所述的存储介质中,其特征在于,
[0138]
在所述第二类用语包含有份额、销售额、利润、人数中的至少一部分。
[0139]
技术方案55所述的发明为,在根据技术方案53或者54所述的存储介质中,其特征在于,
[0140]
在与所述第二类用语有关的检索结果中获得了与相同的特性有关的不同的多个分类中的数据的情况下,所述输出单元输出对该特性进行了合并的合并数据。
[0141]
技术方案56所述的发明为,在根据技术方案53至55中任一项所述的存储介质中,其特征在于,
[0142]
所述输出单元将与所述第二类用语有关的多个检索结果进行组合,生成与所述特性有关的结合数据而输出。
[0143]
技术方案57所述的发明为,在根据技术方案53至56中任一项所述的存储介质中,其特征在于,
[0144]
所述程序使所述计算机进一步作为制作基于与所述数值规模有关的检索结果的曲线的曲线制作单元发挥功能,
[0145]
所述输出单元输出所制作的所述曲线。
[0146]
技术方案58所述的发明为,在根据技术方案48至57中任一项所述的存储介质中,其特征在于,
[0147]
所述检索单元基于过去的检索历史信息,决定与所述概念词组合的所述辅助用语的优先顺序。
[0148]
技术方案59所述的发明为,在根据技术方案58所述的存储介质中,其特征在于,
[0149]
所述检索单元从所述检索用语排除包含于所述检索历史信息的概念词。
[0150]
技术方案60所述的发明为,在根据技术方案48至59中任一项所述的存储介质中,其特征在于,
[0151]
所述检索单元基于所述概念词和所述辅助用语之间的关联性,决定与所述概念词组合的所述辅助用语的优先顺序。
[0152]
技术方案61所述的发明为,在根据技术方案48至60中任一项所述的存储介质中,其特征在于,
[0153]
所述程序使所述计算机进一步作为判定包含于所述检索的结果的用语和所述概念词之间的关联性的判定单元发挥功能,
[0154]
所述检索单元将由所述判定单元判定为关联性高的用语,添加至所述检索用语并重新检索。
[0155]
技术方案62所述的发明为,在根据技术方案48至61中任一项所述的存储介质中,其特征在于,
[0156]
所述检索单元将在包含于所述检索的结果的用语中的满足与出现频率有关的条件的用语,添加至检索条件并重新检索。
[0157]
技术方案63所述的发明为,在根据技术方案48至62中任一项所述的存储介质中,其特征在于,
[0158]
所述计算机具备操作受理部,
[0159]
所述检索单元,将由所述操作受理部受理的用语,添加至所述检索用语并进行检索。
[0160]
技术方案64所述的发明为,在根据技术方案48至63中任一项所述的存储介质中,其特征在于,
[0161]
所述获取单元能够获取包括图像数据以及语音数据中的至少一个的非文本数据以及文本数据,并且识别所述非文本数据的内容并转换至文本数据,并从所述文本数据获取所述概念词。
[0162]
技术方案65所述的发明为,在根据技术方案64所述的存储介质中,其特征在于,
[0163]
在所述非文本数据包含有图像数据,
[0164]
所述获取单元具有对所述图像数据的输入进行该图像数据的识别处理,并输出表示所述图像数据的内容的文本数据的已训练模型。
[0165]
技术方案66所述的发明为,在根据技术方案64或者65所述的存储介质中,其特征在于,
[0166]
所述获取单元从所输入的文本数据提取独立词,并根据该独立词的出现频率确定并获取所述概念词。
[0167]
技术方案67所述的发明为,在根据技术方案64至66中任一项所述的存储介质中,其特征在于,
[0168]
所述获取单元具有针对所述文本数据的输入,输出该文本数据的所述概念词的已训练模型。
[0169]
技术方案68所述的发明为,在根据技术方案48至67中任一项所述的存储介质中,其特征在于,
[0170]
所述获取单元确定所获取的所述概念词的关联用语,并将所确定的所述关联用语添加至所述检索用语。
[0171]
技术方案69所述的发明为,在根据技术方案68所述的存储介质中,其特征在于,
[0172]
所述获取单元生成具有与目标的语义相应的方向的语义向量,并将通过相对于与所述概念词对应的语义向量具有满足规定的基准的方向的语义向量来确定的文本目标,设为所述关联用语。
[0173]
技术方案70所述的发明为,在根据技术方案48至69中任一项所述的存储介质中,其特征在于,
[0174]
所述计算机具备用于存储所述辅助用语的列表的存储部。
[0175]
发明效果
[0176]
根据本发明,可以有效地降低与想法提案有关的资料的收集以及生成的精力。
附图说明
[0177]
图1是表示本实施方式的想法提案支持系统的功能结构的框图。
[0178]
图2是说明想法提案支持的流程的图。
[0179]
图3是表示类似词的获取过程的例子的图。
[0180]
图4是表示基于图像数据的检索用语的设定的例子的图。
[0181]
图5是表示数字数据的结合例的图。
[0182]
图6是表示数字数据的合并例的图。
[0183]
图7是表示所制作的时间表的例子的图表。
[0184]
图8表示想法提案支持处理的控制过程的流程图。
[0185]
标号说明
[0186]
1 想法提案支持系统
[0187]
10 服务器装置
[0188]
11 控制部
[0189]
12 存储部
[0190]
121 程序
[0191]
1211 已训练模型
[0192]
122 辅助用语列表
[0193]
13 通信部
[0194]
20 数据库装置
[0195]
21 存储部
[0196]
211 用语数据
[0197]
212 历史数据
[0198]
30 终端装置
[0199]
31 控制部
[0200]
32 存储部
[0201]
33 显示部
[0202]
34 操作受理部
[0203]
35 通信部
具体实施方式
[0204]
以下,基于附图来说明本发明的实施方式。
[0205]
图1是表示本实施方式的想法提案支持系统1的功能结构的框图。
[0206]
该想法提案支持系统1包括服务器装置10(想法提案支持装置)、数据库装置20、以及终端装置30。
[0207]
服务器装置10具备控制部11(获取部、检索部、输出部、图表制作部、曲线制作部、判定部)、存储部12、以及通信部13等。控制部11是处理器,具有cpu(中央处理单元,central processing unit)以及ram(随机存储存储器,random access memory)等,并且进行各种运算处理,来统筹控制服务器装置10的动作。
[0208]
存储部12存储由控制部11所执行的程序121以及设定数据。此外,存储部12临时存储从终端装置30输入的各种数据及其处理数据。存储部12具有hdd(硬盘驱动器,hard disk drive)和/或闪存等非易失性存储器。此外,存储部12也可以具有用于临时存储大数据而高速处理的ram等。在程序121中包含有与文章分析、图像识别、语音识别以及后述的想法提案支持处理有关的程序。在与图像识别、关键词(想法的概念词)的提取等有关的各处理中,能使用分别被恰当地设计、训练的已训练模型1211。此外,在设定数据中包含有存储了多个后述的辅助用语的辅助用语列表122(列表)。
[0209]
通信部13根据tcp/ip(传输控制协议/网际协议,transmission control protocol/internet protocol)这种规定的通信标准,来控制与外部设备之间的数据的发送接收。通信部13经由网络连接于外部设备。在网络中包含有互联网,并且通过http(超文本传输协议,hypertext transfer protocol)等能够访问民用的检索服务器等。通信部13也可以具有经由usb(通用串行总线,universal serial bus)等与外部设备(外围设备等)能够直接通信的端子。
[0210]
数据库装置20具有存储部21。存储部21存储并保存用语数据211和历史数据212(过去的检索历史信息),所述用语数据211是将由文本、图像、语音等表达的多个各目标和其识别数据(包括后述的语义向量的值)进行关联的数据,所述历史数据212是在过去由服务器装置10检索的检索结果以及想法提案。此外,数据库装置20可以具有控制存储部21的读写的控制部以及控制与外部设备之间的通信的通信部。
[0211]
终端装置30受理来自用户的输入并且向用户输出。终端装置30具备控制部31、存储部32、显示部33、操作受理部34以及通信部35等。控制部31是处理器,具有cpu以及ram等,并且统筹控制终端装置30的动作。存储部32具有非易失性存储器等,并存储各种程序以及数据。通信部35根据规定的通信标准来控制外部设备之间的数据的收发。
[0212]
操作受理部34受理来自外部(用户等)的输入操作,并作为输入信号输出到控制部31。操作受理部34没有特别限定,例如具有键盘、鼠标、在显示部33的显示画面重叠而设置的触摸传感器等。显示部33具有显示画面,并且在该显示画面显示与控制部31的控制命令对应的内容。作为显示画面,没有特别限定,例如是液晶显示画面(lcd)。此外,在显示部33中也可以包括示出特定的状态的led灯(light emitting diode)等。
[0213]
接着,对本实施方式的想法提案支持系统1中的想法提案支持的动作内容进行说明。在服务器装置10中,根据基于所输入的想法的内容(想法数据)的概念词,使用各种数据库、检索网站来检索当前和过去的关联信息。检索对象没有特别限定,是数值数据、特别是时序数据、地域比较数据等。通过检索结果而获得的数值数据在可能的范围被进行统筹,从而被曲线化和/或被图表化。
[0214]
图2是说明想法提案支持的流程的图。
[0215]
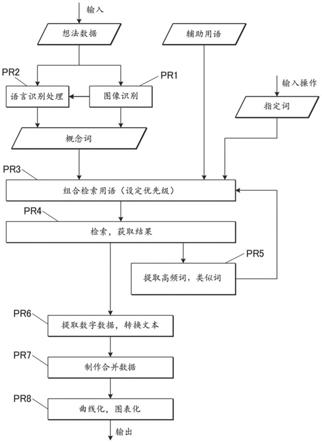
表示想法内容的输入数据可以是概念词(concept word)的罗列、流行语(catch copy)、摘要句、图像或是语音,或者是他们的组合(能够输入)。如图像数据、语音数据那样的非文本数据首先被转换为文本数据。当为图像(语音)的情况下,利用公知的图像识别技术(语音识别技术),将该图像(语音)转换为与内容对应的用语、说明文(文本数据)(pr1)。作为公知的图像识别技术,例如能够利用通过卷积神经网络(cnn)等而设计的机器学习模型的已训练模型1211。在被输入或者转换的文本数据为说明文等,且为多个单词的组合的情况下,利用公知的语言处理技术来确定并提取概念词(pr2)。在语言处理技术中,也可以使用与规定的算法的机器学习模型有关的已训练模型1211。机器学习模型的算法可根据语言来使用不同的算法。作为被确定并提取的概念词,可以优先提取名词,也可以从包含有形容词、动词的独立词(自立語)整体中提取。在从头开始输入有概念词(单词、短词组等)的情况下,可以直接使用这些概念词。pr1、pr2的处理包含于获取步骤(获取步骤、获取单元)。
[0216]
所获得的概念词没有必要是一个,但是在获取有多个概念词的情况下,在检索时一部分一部分选择(主要是逐词)而执行多次检索。此外,此时不仅是利用概念词,还可以利
用与从辅助用语列表122中提取的辅助用语进行组合的检索用语(检索条件)来执行检索(pr3)。辅助用语表示针对概念词的特性的项目,特别是用于获取与能够用数值表示的特性有关的数据(检索结果)的用语。辅助用语,即,作为特性的项目,可例举,主要表达时间(时刻、日期时间、时期、时序)的用语(第一类用语),例如表达时事、原委、历史、来历(history)、年代、年表、趋势等以及与事业等的规模有关的数值(数值规模)的用语(第二类用语),例如份额、销售额、利润、收益、人数、利用者数、购买者数、入场者数、参加者数、店铺数、匹(头、只)数、个(张、台、册)数、件(次、条、度)数等。另外,除此之外,辅助用语中也可以包含与数值规模的分类、属性相关的用语,例如,世代(可以附加“之间”、“按照”等,以下相同)、男女、性别、年龄、地域等。这些中,根据与概念词的种类(生物、物品、服务、商业性等)的关联性,组合妥当的用语优先被选择,并决定与每个该概念词的组合以及其顺序。即,与“数量”等的一般用语组合的量词,例如,针对小动物的宠物等的“匹”,针对鸟、兔子等的“只”,针对马、牛这种大型动物等的“头”等,也可以预先存储并保存,从而在检索前被参照并被选择。
[0217]
此外,不仅是如此自动被选择的概念词以及辅助用语,由用户等通过操作受理部34受理而发送至服务器装置10的用语(指定词)也可以并入至检索用语。
[0218]
用被决定的组合的顺序的检索用语,进行检索(pr4)。在检索时,可以利用公司内部等的封闭的数据库,即,数据库装置20的历史数据212、互联网上的免费检索服务器、基于民用调查公司等的付费数据库等。他们之中,公司内部数据库等的检索也可以先于其他检索。关于在用公司内部数据库进行检索的结果(在过去检索的结果)中检测出数字数据的情况等,可以将如下决策反映于优先顺序的决定:用相同的检索用语优先进行外部的检索,或者相反地,当存在用相同检索用语进行检索的检索结果时,作为不是新想法而从互联网上的检索(检索用语)中排除。针对优先进行还是排除的判断,例如也可以根据数字数据的更新日期等进行。
[0219]
被检索的对象不仅包括文本数据,还可包括图像数据、语音数据。如上所述,图像数据、语音数据可利用公知的识别技术来文本化。此外,在文本数据中包含有结构化文档。例如,若通过基于在各组合的检索用语中的、在优先顺序上到规定数目为止或者优先级别在规定的基准以上的检索用语的检索结果,获得大致结果,则从全部检索结果、或者针对各检索用语获得的检索结果中,用排列顺序进一步每次分析规定数(在重复的情况下也可以排除)的内容,进行所包含的词的检索,并提取常见的词、概念词以及与该高频词类似的用语(pr5)。在检索结果不够的情况、过多而无法明确提取恰当的结果的情况等,也可以在检索用语中追加关联的高频词(类似词)(在结果不够的情况下可以选择设定逻辑或,当结果过多的情况下选择设定逻辑与等)。高频词选定为,例如满足如下条件(与出现频率有关的条件)的词:出现次数降序的顺序到规定的顺序为止,或者,如与字符数进行比较从而成为规定的比例以上的字符数那样的频率等。此外,当包含有与设定的概念词相比明显出入的高频词(例如,不同语义的省略词、小说作品的专有名词、各种作品标题等)时,也可以作为排除词而在检索用语追加设定(检索条件的设定),以使排除包含有该高频词的内容。由此,重新设定检索用语并再次检索(当仅为检索模式的追加时,仅再次进行与追加的概念词有关的检索即可)。包括类似词的检索用语的优先顺序可根据对于该类似词的概念词的类似度、关联性等,再次决定。另外,当以一次检索获得足够的结果时,无需重新检索。pr3~pr5
的处理包含于检索步骤(检索部、检索单元)。
[0220]
另一方面,从检索的结果中提取表示与辅助用语对应的特性的数据,特别是包含有数字(数值)的数据(pr6)。当多个检索结果中各自包含的数字所表示的内容是,与相同的特性有关的不同的分类、分类(例如,与辅助用语(第二类用语)所表示的一个特性对应的不同的西洋历年、年龄分类、地域分类,与其他特性的对应条件等)的情况下,也可将在时序内等的时机、条件、分类等不同的多个检索结果的数据,合并为一个数据集(pr7)。被合并的数值数据,被进行适当曲线化(制作曲线数据)或者图表化(制作图表数据)(pr8;曲线制作部、曲线制作步骤、曲线制作单元/图表制作部、图表制作步骤、图表制作单元)之后,作为表示与概念词对应的特性的数据而输出。pr6、pr7的处理包含于输出步骤(输出部、输出单元)。
[0221]
与用于在检索等中利用的概念词类似的词(关联用语。以下记为类似词)的提取,基于数值的基准来客观地进行。作为这种类似词的提取,在此利用语义向量。语义向量是针对用语(目标)以多维向量来表示基于每个语义的方向的技术,多个用语之间的语义的类似度(关联度)与分别表示该多个用语的多维向量之间的角度差(距离)对应。维度数可以任意选定,例如可以是100~1000维度等。各用语的语义向量使用机器学习模型来决定,各维度的轴向的特性无需用语言表达。
[0222]
作为使用了机器学习的语义向量的决定技术,已知有word2vec。与机器学习有关的训练算法例举有,例如,word2vec中经常使用的continuous skip-gram(连续跳字)模型或者cbow(连续词袋,continuous bag-of-words)模型等,但是不限于此。此外,所使用的神经网络的层级不限于两个阶段,进一步地,也可以使用神经网络以外的训练算法。由使用了多个文章数据等的机器学习来获得的多个单词和语义向量之间的对应关系数据,作为用语数据211而保存于数据库装置20的存储部21。机器学习可以由服务器装置10预先准备足够的训练数据来进行,也可以将通过用外部的设备进行的训练而生成的已训练模型,复制到数据库装置20。另外,类似词的提取,不限于基于上一次(第一次)的检索的结果来进行的情况。也可以基于最初从想法数据获取的概念词,在第一次的检索之前另行选择。如上所述,与被提取的类似词的检索有关的优先顺序,可以根据与概念词的类似度(关联度)等(特别是优先关联度较高的类似词并添加到检索用语)来选定。
[0223]
图3是表示类似词的获取过程的例子的图。
[0224]
在图3(a)所示的第一例中,首先,在获取到概念词时,将该概念词发送至数据库装置20(pr21),并获取对应的语义向量(pr22)。接着,将该语义向量和针对该语义向量的设定角度(基准角度)发送至数据库装置20(pr23),将具有相对于语义向量在基准角度内(满足规定的基准的方向)的语义向量的用语(文本目标)作为类似词(关联用语)来获取(pr24)。将被获取的类似词追加设定至检索用语的列表,并且与其他的概念词同样地决定与辅助用语的组合有关优先顺序(pr25)。
[0225]
在图3(b)所示的第二例中,将从检索结果获得的高频词和概念词发送至数据库装置20(pr31),并且计算分别对应的语义向量(pr32)。使用被获得的语义向量的内积(用两个语义向量的长度的积除以内积的值)等,来求出与两个语义向量之间的角度差对应的值(pr33)。判定所求出的角度差是否在基准角度以内(关联性),将基准角度内的高频词作为类似词而追加设定至检索用语的列表,并且与其他的概念词同样地,决定与辅助用语的组合有关的优先顺序(pr34)。pr31~pr33(也可以包括pr34)的处理包含于本实施方式的判定
步骤(判定部、判定单元)。
[0226]
图4是表示基于图像数据的检索用语的设定的例子的图。
[0227]
在该图像数据中,作为目标,包含有自行车p1(公路自行车),例如,作为概念,启示有骑行那样的活动。对图像数据进行图像识别,从而提取自行车或者公路自行车等(根据背景等,也可以包括骑行、骑行公路、公路比赛等)作为概念词。
[0228]
对于这些概念词,作为辅助用语,例如可以选择历史、年表、趋势、销售台数、利用者数、价格、份额等。此外,基于语义向量,例如,也可以获取与山地自行车或越野自行车等其他车型、公路比赛、旅行、骑行、自行车长途旅行、用公共交通工具携带自行车(輪行)、捆绑踏板等关联的用语。也可以进一步选择针对关联用语的辅助用语。基于这些,能够选择公路自行车和销售台数的组合、公路比赛和参加者数的组合等可能的组合,为这些组合赋予优先顺序并作为检索用语来执行检索。
[0229]
作为基于这种组合的检索用语的检索的结果,可以更优先地获取与特别易作为客观的资料而起作用的数值数据、年代对应的变化、趋势等。
[0230]
但是,特别是公开于互联网上的数值数据,并不全是以适合演讲的形式网罗并公开的。例如,仅以自行车的销售台数的数据,无法得知何种车型的自行车受欢迎等。
[0231]
图5是表示数字数据的结合例的图。
[0232]
例如,如图5(a)所示,当通过检索,获取到包括车型a~c(多个分类)的所有自行车的销售台数的统计数据,而且获取到包括车型a~c的各车型的自行车的销售份额的统计数据时,可通过组合这些多个检索结果,在此是进行相乘,来粗略地计算车型a的自行车的销售台数,并生成与期望的结果有关的数据(结合数据)。基于该车型a的数值生成图5(b)的曲线,从而明确地示出车型a的销售台数的增长。
[0233]
另外,通常难以自动地判断这种结合的需要与否。因此,例如也可以预先在存储部12存储保存参数(特性值)的优先顺序、针对各参数能够设想到的组合模式等,并基于根据所获取的数据能够进行的组合模式等,判断可否结合。此外,也可以是,用于选定优先顺序的补充信息能够与概念词一并获取。
[0234]
统计数据除了明确表示有数值数据的情况之外,还有作为图像数据示出数字表,或者仅显示曲线的情况。在这类情况下,可以进行针对图像的字符识别处理、曲线图像的判别、数值化处理等。此外,对全部图像数据进行高精度的字符识别处理需费时费力,因此也可以进行简单的图像识别处理,判别出是否为曲线、图表之后,仅对曲线、图表的图像数据进行高精度的处理。
[0235]
图6是表示数字数据的合并例的图。
[0236]
如图6(a)所示,在除了商品p的稍旧的销售额的统计数据以外,还获取有了如图6(b)所示的表示近年的状况的报导的情况下,能够合并这些数值。在此,对从图6(a)中获得的2002~2010年的数据,从新闻的报导中追加了2000年、2012年、2018年(不同时机)的信息。如图6(c)所示,所合并的数据可以被曲线化。另外,此时可以看出新闻的报导的值是估算,即在合并数据中混入有精度不同的值,但是作为与公司内部等的封闭且非正式的演讲有关的资料,也可以无需特别考虑精度的差异。或者是,也可以一并显示数值的排列表。此外,根据每个获取源的数据的获取条件的差异、数据的可靠性的差异,有时还混入有本质上语义不同的值、可疑的值,因此当存在对信息的出处、条件的记载时,也可以赋予注释、脚注
等。
[0237]
另一方面,针对年表数据,并不总是定量的内容,但是也有产生有用性的时候,因此也可以作为表数据罗列生成。
[0238]
图7是表示所制作的年表的例子的图表。
[0239]
在此,将从各种新闻等中所获取的与公路自行车关联的事件,按照顺序排列并制作年表。如此,对事件的举行等,不单可以追踪数量的变化,还可以追踪历史,由此容易追踪现在的情况和今后的道路。
[0240]
图8表示由本实施方式的服务器装置10的控制部执行的、通过想法提案支持处理的控制部11进行的控制过程的流程图。该想法提案支持处理根据自终端装置30输入的请求而开始。
[0241]
若想法提案支持处理被开始,则控制部11(cpu)自终端装置30获取想法数据(步骤s101)。控制部11判别所获取的想法数据是否是图像数据(步骤s102)。当判别为是图像数据的情况下(在步骤s102中为“是”),控制部11,对该图像数据,应用使用了已训练模型1211等的图像识别处理,将图像内的目标文本化,或者生成内容的说明文(步骤s103)。然后,控制部11的处理转移至步骤s104。当判别为不是图像数据的情况下(在步骤s102中为“否”),控制部11的处理转移至步骤s104。
[0242]
若转移至步骤s104的处理,则控制部11进行文本处理,并提取概念词(步骤s104)。步骤s101~s104的处理构成本实施方式的想法提案支持处理中的获取步骤(程序中的获取单元)。
[0243]
控制部11参照辅助用语列表122来提取能够与概念词分别对应的辅助用语。控制部11对组合了各概念词和辅助用语的检索用语的模式给予优先顺位从而决定检索的优先级顺序(步骤s105)。控制部11以被决定的优先级的顺序来利用检索用语进行检索(步骤s106)。如上所述,当并用内部数据库和外部检索的检索时,也可以先进行内部数据库的检索,并基于其结果来改检索用语的优先顺位等。
[0244]
控制部11判别是否已获取了所需的数据(步骤s107)。当判别为尚未获取到时(在步骤s107中为“否”)、控制部11从作为检索结果而获得的数据的文本(可以包含自图像数据文本化的文本。此外,就结构化文档而言,可别进行结构分析)中,提取词(独立词),并计算频率,提取基准以上的高频词。此外,如上所述,控制部11例如使用语义向量,从高频词之中获取概念词的类似词(步骤s108;判定步骤、判定单元)。控制部11将类似词追加至检索用语(步骤s109)。控制部11也可以将检索中的上述排除词追加至检索条件。
[0245]
控制部11将当前的检索用语列表发送至终端装置30,并使其显示于显示部33(步骤s110)。控制部11等待来自终端装置30的回复,若接收到回复,则判别是否存在通过操作受理部34等进行的检索用语的追加指示(步骤s111)。当判别为存在的情况下(在步骤s111中为“是”),将存在追加指示的指定词追加至检索用语(步骤s112)。然后,控制部11的处理返回至步骤s105。当判别为不存在追加指示的情况下(在步骤s111中为“否”),控制部11的处理返回至步骤s105。
[0246]
步骤s105~s112的处理构成本实施方式的想法提案支持处理中的检索步骤(程序中的检索单元)。
[0247]
在步骤s107,当判别为已获取了需要的数据的情况下(在步骤s107中为“是”),控
制部11从检索结果提取数值数据,根据需要,将图像数据等转换为文本数据(步骤s121)。控制部11判别数值数据的内容,并对一致的内容的数据或者能够联系起来的关联的数据进行合并(步骤s122)。控制部11根据与规模等有关的数值数据制作曲线,而且根据需要来制作年表等的图表(步骤s123;曲线制作步骤、曲线制作单元/图表制作步骤、图表制作单元)。控制部11将所生成的数据输出至终端装置30(步骤s124)。控制部11可以将数值数据以及所生成的各种数据输出至数据库装置20,并追加至历史数据212。然后,控制部11结束想法提案支持处理。
[0248]
步骤s121、s122、s124的处理构成本实施方式的想法提案支持处理中的输出步骤(程序中的输出单元)。
[0249]
如上所述,本实施方式的想法提案支持系统1具备控制部11,控制部11作为获取部,获取概念词,作为检索部,将概念词和表示针对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索,作为输出部,基于检索的结果,输出表示与概念词对应的特性的数据。
[0250]
如此,在想法提案支持系统1,获取与概念词的特性有关的数据并概括输出,因此可以降低收集并生成在用户提案(演讲)主意时所需的文件的制作中起作用的资料的精力,可获得帮助。
[0251]
此外,在辅助用语中包含有与时间有关的第一类用语。在客观性信息的提示中,掌握至今为止的时序的关联信息的流程是重要的,因此可以选择对应的检索用语,由此更切实地收集提示中所需的信息。
[0252]
此外,在第一类用语包含有时事、原委、历史、趋势、年代、年表中的至少一部分。特别是利用作为与这些时间有关的用语而常见的用语,从而可以提高所需要的信息的收集概率。
[0253]
此外,控制部11作为输出部(输出步骤、输出单元),在与第一类用语有关的检索结果中获得了不同的多个时机的数据时,将在时序内进行合并的合并数据与概念词进行关联并输出。即,当获得了在时序上处于前后的多个检索结果时,可以合并这些检索结果并输出,因此大大降低用户比较、排列多个分析结果的精力。
[0254]
此外,控制部11作为图表制作部(图表制作步骤、图表制作单元),制作基于与第一类用语有关的检索结果的图表数据,作为输出部(输出步骤、输出单元),输出所制作的所述图表数据。如此,不仅可以输出与检索结果的格式相应的数据,还可以概括输出图表数据,因此可以降低用户制作图表的精力,还可以容易进行主意的提案内容的视觉上有效的提示。
[0255]
此外,在辅助用语包含有与数值规模有关的第二类用语。作为客观的资料,数值数据是有效的,因此可以将这种能够更切实地获取数值数据的用语选择性地添加至检索用语。由此,进一步地,可以更切实地获取演讲上有效的资料并输出。
[0256]
此外,份额、销售额、利润、人数中的至少一部分包含于第二类用语。特别是利用作为与这些数值有关的用语而常见的用语,从而提高定量的数据的收集概率,可以更有效地提高基于所输出的信息的演讲的说服力。
[0257]
此外,控制部11作为输出部(输出步骤、输出单元),在与第二类用语有关的检索结果中获得了与相同的特性有关的不同的多个分类中的数据时,针对该特性进行合并并输出
合并数据。即,基于多个检索结果,在获取了相同参数的不同时机、条件等(分类)的多个数值的情况下,合并这些数值并一览输出,由此用户无需比较对照多个检索结果,可以容易地整理有效的数据并进行确认、提示。
[0258]
此外,控制部11作为输出部(输出步骤、输出单元),组合与第二类用语有关的多个检索结果并生成与期望的特性有关的结合数据而输出。即使是使用了第二类用语的检索结果,也不一定是直接有助于提高主意提案的说服力的数据。即使在这种情况下,有时通过组合多个参数也可以得出所需的信息,因此通过组合该多个参数(检索结果)来生成结合数据,能够容易获得更有效的输出。由此,可以在不花费精力的情况下使主意提案的说服力提高。
[0259]
此外,控制部11作为曲线制作部(曲线制作步骤、曲线制作单元),制作基于与数值规模有关的检索结果的曲线,作为输出部(输出步骤、输出单元),输出所制作的曲线。在数值数据的排列的情况下,以曲线进行可视化,使第三者在短时间理解提案的方面非常有效。因此,在获得了能够曲线化的数据排列时,通过生成曲线进行输出,可以节省由用户进行的曲线制作的精力,同时容易制作有效的主意提案的资料。
[0260]
此外,控制部11作为检索部(检索步骤、检索单元),基于过去的历史数据212,决定与概念词进行组合的辅助用语的优先顺序。在将检索结果保存在内部服务器的情况下,通过重新利用该数据,能够容易降低与外部服务器的连接的精力和时间。此外,在预先得知了没有对主意提案起作用的数据的情况下,通过不再进行向该网站的访问,可以降低不必要的精力和时间。
[0261]
此外,控制部11作为检索部(检索步骤、检索单元),从检索用语排除包含于历史数据212的概念词。即,对于通过公司内部的历史知道已经用于检索的内容,已经被某人探索过而进行排除,由此还可以使检索的效率提高。但是,多个概念词的组合有时不同,因此在这种情况下,如上所述,也可以获取所对应的历史数据来利用。
[0262]
此外,控制部11作为检索部(检索步骤、检索单元),基于概念词和辅助用语的关联性,决定与概念词进行组合的辅助用语的优先顺序。在检索时,有没有向检索用语附加关联用语通常较重要,因此通过追加选择关联性高的用语的处理,能够容易更有效地获取必要性高的数据。
[0263]
此外,控制部11作为判定部(判定步骤、判定单元),判定包含于检索的结果的用语和概念词之间的关联性,作为检索部(检索步骤、检索单元),将判定为关联性高的用语添加至检索用语并重新检索。
[0264]
如此,可从检索过一次的结果中提取关联性高的用语并添加至检索用语,因此根据实际的检索来集中到更有效的检索结果,然后再次分析各检索结果,因此无需在不必要的内容的分析上花费精力,能够得出所需的信息。
[0265]
此外,控制部11作为检索部(检索步骤、检索单元),将包含于检索的结果的用语中的满足与出现频率有关的条件的用语,添加至检索条件并重新检索。即,将检索中的命中件数高的用语,添加至重新检索的检索用语,或者作为排除词,由此可有效地分析检索内容。
[0266]
此外,想法提案支持系统1中,终端装置30具备操作受理部34。服务器装置10的控制部11作为检索部(检索步骤、检索单元),将通过操作受理部34受理的用语添加至检索用语并进行检索。在完全的自动处理中,根据概念词的内容和类型之间的关联性等,并不一定
是反映了想法的基础和背景的最佳的检索用语,因此通过能够实现由用户向检索用语的追加,从而能够通过由用户花费少许精力进行追加,实现有效的检索和输出数据的生成,整体上可以降低用户制作主意提案资料的精力。
[0267]
此外,作为用于获取概念词的数据,可以输入包含图像数据以及语音数据中的至少一个的非文本数据、以及文本数据,控制部11作为获取部(获取步骤、获取单元),识别非文本数据的内容并转换至文本数据,从文本数据获取概念词。即,在想法提案支持系统1中,即使是用非文本数据表示的概念,也可以暂且恰当地转换成文本数据,与自始为文本数据的概念同样地,能够恰当地获取概念词。由此,可自各种形式的想法数据恰当地接连至主意提案资料,降低了用户的精力。特别是,通过从信息量多的图像数据等获取恰当的概念词的组合,也能够节省由用户进行的文本化的精力。
[0268]
此外,在非文本数据包含有图像数据,控制部11作为获取部(获取步骤、获取单元),具有对图像数据的输入进行该图像数据的识别处理,并输出表示该图像数据的内容的文本数据的已训练模型。即,在从图像数据获取概念词等时,通过使用机器学习模型进行图像识别,特别是通过今年来所使用的算法的发展,因此用通常的pc等也能够准确地识别并文本化。因此,在不花费大量金钱在硬件结构等上的情况下,也能够有效地进行概念词的获取,据此,可以输出对想法提案资料有用的信息。
[0269]
此外,控制部11作为获取部(获取步骤、获取单元),从输入的文本数据提取独立词,并根据该独立词的出现频率来确定并获取概念词。即,作为概念词,可以直接决定文本中的名词等的独立词。恰当地进行与自然语言分析有关的处理从而提取独立词,通过基于上下文分析来选择成为关键的独立词,由此无需创建就能够合理地获取新的概念词。
[0270]
此外,控制部11作为获取部(获取步骤、获取单元),具有对文本数据的输入来输出该文本数据的概念词的已训练模型。针对文本数据的自然语言分析,通过利用恰当地进行了训练的机器学习模型,也能够对少许的记载不完善等可以灵活地应对从而获得恰当的概念词,因此根据该概念词能够准确地进行检索。
[0271]
此外,控制部11作为获取部(获取步骤、获取单元),确定所获取的概念词的关联用语(类似词),将所确定的关联用语添加至检索用语。如上所述,不仅是从输入数据获取的概念词,与该概念词类似的等关联的用语也被设为检索用语,因此在不显著改变检索的方向性的范围内,能够扩大检索的幅度,能够有效地降低漏检的可能性。
[0272]
此外,控制部11作为获取部(获取步骤、获取单元),生成具有与目标的语义相应的方向的语义向量,将由相对于与概念词对应的语义向量具有满足规定的基准的方向的语义向量来确定的文本目标,设为关联用语(类似词)。如此,通过利用语义向量,能够客观地定量评估类似程度来决定类似词,因此能够实现稳定而偏差少的类似词的设定,相应地,能够使检索的方向性的偏移变小。
[0273]
此外,想法提案支持系统1具备在服务器装置10存储辅助用语列表122的存储部12。如此,预先将辅助用语进行列表化并预先保存,因此参照该辅助用语列表122,能够机械地将多个概念词和辅助用语的组合依次作为检索用语进行检索。
[0274]
而且,服务器装置10具备上述控制部11,并进行各处理。因此,服务器装置10基于所获取的概念词,能够有效地输出对主意提案资料有用的数据,可以降低由用户用于准备提案的精力。
[0275]
此外,本实施方式的想法提案支持方法包括:获取步骤,获取概念词;检索步骤,将概念词、和表示对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索;以及输出步骤,基于检索的结果,输出表示与概念词对应的特性的数据。如此,通过执行各处理,用户在公司内部等可容易提案出所想到的想法,能够降低由用户进行的准备的时间,同时容易制作更有说服力的资料。
[0276]
此外,本实施方式的程序121使服务器装置10的计算机作为获取单元、检索单元以及输出单元发挥功能,所述获取单元获取概念词,所述检索单元将概念词、和表示对该概念词的特性的项目的辅助用语的组合作为检索用语进行检索,所述输出单元基于检索的结果,输出表示与概念词对应的特性的数据。将这种程序安装到计算机并以软件方式处理,由此无需准备特殊的硬件结构也可以容易执行各处理,从而输出对主意提案资料有用的数据。
[0277]
另外,本发明不限于上述实施方式,并且能够进行各种改变。
[0278]
例如,在上述实施方式中,说明了概念词以独立词等的单词单位被设定的情况,但是在以单词单位进行划分不合适的情况下等,也可以是短词组。此时,可以决定如与短词组完全一致的检索条件。
[0279]
此外,输出数据的内容无需限于曲线或图表,只要是能够表示特性的内容,作为检索结果而获得的文本数据或图像数据的一部分也可以包含在输出数据。
[0280]
此外,在上述实施方式中,说明了将与时间以及数值相关的辅助用语进行组合,但是例如,针对用字母或符号等进行等级划分的多阶段评估的检索结果等,也可以设定辅助用语以使成为检索的对象,或者添加至输出数据。
[0281]
此外,曲线显示不限于曲线图,也可以根据内容(绝对值、比例、多个类型的比较等)从柱状图或条状图、圆形图等各种图中进行选择。此外,并非全部数值数据进行曲线化或图表化。根据成为表示对象的点的数量等,也可以不进行曲线化,此外,在仅获得了一个曲线的图像数据的情况下,也可以原样输出该图像数据。此外,在获得了多个检索结果的情况下,当加工时遇到问题或者难以加工时,也可以并列输出多个结果。
[0282]
此外,在上述实施方式中,保存历史数据212来用于检索用语的设定或优先顺序的设定等,但是也可以不作这种处理。此外,在历史数据212也可以仅保存进行了检索时的检索用语的列表,不保存检索结果的数据。
[0283]
此外,在上述实施方式中,说明了自动地合并、结合多个检索结果的数值或时序上的事件等,但是考虑到各数据的可靠性的偏差,也可以在进行合并、结合之前需要用户的批准,或者,以能够容易解除合并、结合中的一部分的方式制作合并/结合数据。
[0284]
此外,在上述实施方式中,使用语义向量来进行类似词(关联用语)的判定,但是不限于此。也可以仅输出基于辞典数据等而规定为同义词的词,或者利用检索结果所包含的相关性等进行判定。
[0285]
此外,在上述实施方式中,说明了能够将图像数据和/或语音数据的输入转换为概念词,但是,并不需要总是具备这种功能。也可以设为必须以文本输入。此时,使用其他程序等,能够将图像数据和/或语音数据转换成文本数据。
[0286]
此外,在上述实施方式中,说明了利用在网络上能够检索出的所有的数据,但是也可以根据检索结果的信息发送源等来设定可靠度,在判定时不利用一部分数据,也可以设
定为虽利用但是在上述数据的结合/合并时不会使用。
[0287]
此外,在上述实施方式中,说明了用户通过操作受理部34能够在中途指定检索用语,但是也可以限定为在不包括用户的处理而执行所有处理的情况。
[0288]
此外,在上述实施方式中,说明了具有单独的服务器装置10、数据库装置20以及终端装置30的想法提案支持系统1,但是也可以是所有结构被包括在单个装置内来执行。此外,各装置不限于位于相同lan内的情况,也可以从终端装置30经由互联网远程访问,从而服务器装置10进行动作等。
[0289]
此外,在上述实施方式中,所有处理通过控制部11以软件方式执行,但是控制部11的处理也可以分散至多个cpu、不同装置的控制部等。此外,处理的一部分也可以由专用的硬件电路等执行。
[0290]
此外,在上述实施方式中,作为与想法提案支持处理有关的程序121的计算机可读介质,以由hdd或者闪存等构成的存储部12为例进行了说明,但是不限于此。作为其他计算机可读介质,可应用其他非易失性存储器、以及cd-rom和dvd盘等的可移动记录介质。此外,作为将与本发明有关的程序的数据经由通信线路提供的介质,载波(carrier wave)也能应用在本发明。
[0291]
此外,在不脱离本发明的宗旨的范围内,在上述实施方式中所示的结构、处理内容以及过程等的具体细节,可以适当改变。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1