一种基于深度强化学习的水下滑翔机姿态控制方法与流程
本发明涉及一种水下机器人的控制技术,具体说是一种基于深度强化学习的水下滑翔机姿态控制方法。
背景技术:
水下滑翔机是一种将浮标、潜标技术与水下机器人技术相结合而研制出的一种无外挂、依靠自身重力驱动的新型水下航行器。其主要特点是:运动控制不依靠螺旋桨推进系统,而是通过调节滑翔机净浮力,实现上下沉浮运动,利用附于机身的水平机翼产生斜向上、或斜向下的升力,操纵滑翔机向前滑翔。水下滑翔机克服了水下航行器功率大、航行时间短的缺点,大大降低了运行成本和制造成本,提高了续航时间,在军事上和海洋探索研究上非常有实用价值。
水下滑翔机的运动姿态容易受海流与波浪的影响,同时水下滑翔机机体结构复杂,动力方式单一,动力学模型表现为强非线性,准确的模型参数不易得到而且在不同的水域环境下构建的模型也缺乏普适性。虽然许多传统的控制方法可以实现水下滑翔机的姿态控制且能达到一定的控制精度,但仍然不能满足高精度的要求,而且控制过程较为复杂。
技术实现要素:
要解决的技术问题
本发明的目的是克服现有技术的缺点和不足,提供一种基于深度强化学习的水下滑翔机姿态控制方法,建立深度强化学习神经网络模型,通过对仿真模型数据或者人工实验数据进行学习,可以实现水下滑翔机姿态的精确控制。
技术方案
本发明提出的基于深度强化学习的水下滑翔机姿态控制方法包括学习阶段和应用阶段,在学习阶段通过仿真模拟水下滑翔机的运动过程同时记录运动的实时数据,根据运动数据更新当前决策神经网络、当前评价神经网络、目标决策神经网络和目标评价神经网络的参数,具体步骤如下:
步骤1:建立4个bp神经网络,分别为当前决策神经网络、当前评价神经网络、目标决策神经网络和目标评价神经网络。当前决策神经网络与目标决策神经网络称为决策神经网络,当前评价神经网络和目标评价神经网络称为评价神经网络。决策神经网络采用水下滑翔机的状态值作为输入量,而采用水下滑翔机的控制量a作为输出动作。评价神经网络有以水下滑翔机的状态值和控制量为输入,以评价值为输出;
构建神经网络之后,初始化4个神经网络的参数,初始化记忆库以及数据缓冲区的大小。
步骤2:获得当前时刻下水下滑翔机的状态值st,将状态值输入当前决策神经网络计算出在当前时刻姿态控制器的输出动作at,将输出的动作at施加给水下滑翔机仿真器,得到下一时刻水下滑翔机的状态值st+1。根据当前时刻的状态st、当前时刻的动作at、目标俯仰角θd和下一时刻的状态st+1计算出当前时刻的奖励值rt。
优选rt取值为:
rt=r1+r2+r3
其中,r1=-λ1(dt-dt-1),r1代表当前俯仰角远离或靠近期望角度获得的回报值,r2=-λ2(wt-wt-1),r2代表角速度发生变化获得的回报值,r3根据当前俯仰角的大小取值,如果:|dt-dt-1|<0.1°,r3为一个正的“奖励”,如果θ<-90°或θ>90°时,r3为一个负数,表示惩罚,dt为在t时刻时,当前的俯仰角θ与目标俯仰角θd的差值,wt为在t时刻时俯仰角速率的大小,λ1和λ2为设定系数。
步骤3:将步骤2中获得的状态(st,at,rt,st+1)作为一组经验数据单元储存在记忆库中,将t自增1;判断t与设定的记忆库大小n之间关系,如果t<n,则利用更新后的st返回步骤2,直至记忆库中存储的经验数据单元数量满足n的要求后,进入步骤4。
步骤4:从记忆库中采样指定数目为n的经验数据单元存放到缓冲区中。
优选通过基于优先级的经验回放机制对缓冲区中的n个经验数据单元进行优先级排序,并存储在sumtree数据结构中;sumtree数据结构中的头结点的值为所有节点所代表的经验数据单元的优先级之和,记为ptotal。
步骤5:对步骤4得到的存储在sumtree数据结构中的n个经验数据单元,然后在n个经验数据单元中采样m个经验数据单元,本实施例中为了能够保证各种经验都有可能被选到,通过以下过程采样m个经验数据单元;
将[0,ptotal]等分为数目为m的小区间,在各个小区间中进行随机均匀采样,得到采样所得优先级对应的经验数据单元,共得到m个经验数据单元。
对采样得到的m个经验数据单元按照以下过程进行逐一处理,得出当前评价神经网络的梯度值
对于某个经验数据单元(st,at,rt,st+1),将状态st和动作信号at输入到当前评价神经网络中得到当前评价神经网络的评价值q;将下一时刻状态st+1输入目标决策神经网络中,得到目标决策神经网络输出的执行机构的动作信号μ';将下一时刻状态st+1和目标决策神经网络输出的动作值μ'输入到目标评价神经网络中得到目标评价神经网络的评价值q';
利用当前评价神经网络的评价值q和目标评价神经网络的评价值q'以及评价神经网络的损失函数l计算出当前评价神经网络的梯度值
具体而言,当前评价神经网络的损失函数l为:
其中,ωi为第i个经验数据单元的重要性采样权重,δi为:
δi=ri+γq'(si+1,μ'(si+1|σμ')σq')-q(si,ai|σq)
ri是第i个经验数据单元中的奖励值,si+1是第i个经验数据单元中的下一时刻状态,σμ'是目标决策神经网络的参数,μ'(si+1|σμ')是si+1通过目标决策神经网络输出的执行机构的动作信号。σq'是目标评价神经网络的参数,q'(si+1,μ'(si+1|σμ')σq')是将μ'(si+1|σμ')和si+1通过目标评价神经网络得到的评价值大小。si是第i个经验数据单元中的当前时刻状态,ai是第i个经验数据单元中的当前时刻状态下的动作信号,σq为当前评价神经网络的参数,q(si,ai|σq)是当前评价神经网络的评价值大小。γ是折扣系数,γ取值为0.99。
当前评价神经网络的损失函数l的梯度为:
步骤6:当前评价神经网络更新:根据当前评价神经网络的梯度
步骤7:计算当前决策神经网络的梯度
其中
步骤8:当前决策神经网络更新:
根据当前决策神经网络的梯度
步骤9:目标评价神经网络与目标决策神经网络更新:根据更新后的当前评价神经网络参数对目标评价神经网络参数进行更新,根据更新后的当前决策神经网络参数对目标决策神经网络参数进行更新,更新公式为
其中,σt+1q表示更新后的当前评价神经网络参数,σtq'表示待更新的目标评价神经网络参数,σt+1q'表示更新后的目标评价神经网络参数;σt+1μ表示更新后的当前决策神经网络参数,σtμ'表示待更新的目标决策神经网络参数,σt+1μ'表示更新后的目标决策神经网络参数;τ1为目标评价神经网络的更新率取值为0.001,τ2为目标决策神经网络的更新率取值为0.0001。
步骤10:判断训练次数是否超过设定训练次数,如果超过设定训练次数,则停止训练,保存4个神经网络的参数值,如果没有超过设定的训练次数,则返回步骤4,重新在记忆库中采样指定数目为n的经验数据单元存放到缓冲区中。
步骤11:得到训练完成的深度强化学习神经网络模型后,应用到实际水下滑翔机在纵平面滑翔运动中,给定目标俯仰角θd,采集水下滑翔机的状态值输入到深度强化学习神经网络模型得到控制量实现水下滑翔机姿态控制。
有益效果
与现有技术相比,本发明的技术方案所带来的有益效果是:
1、基于仿真模型数据或者人工实验数据进行学习,实现水下滑翔机姿态的控制,学习方式简单。
2、无需得到水下滑翔机的精确数学模型,同时在复杂环境下同样适用。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
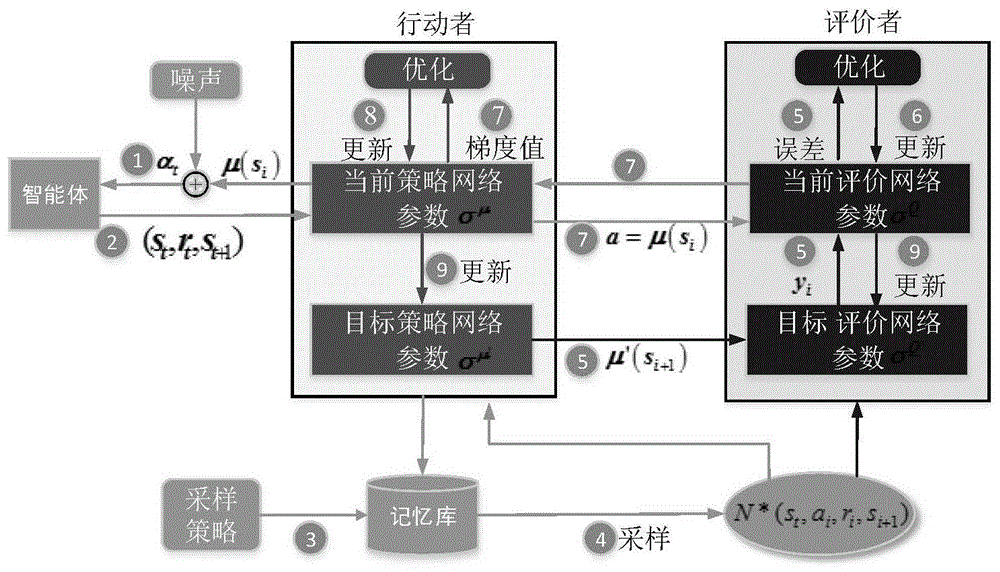
图1:深度强化学习算法框架示意图;
图2:水下滑翔机纵向滑翔运动控制图;
图3:sumtree结构示意图;
图4:水下滑翔机姿态控制训练过程回合奖励值大小示意图;
图5:应用阶段设定下滑期望俯仰角为-25°时在姿态调节单元作用下当前俯仰角的变化过程。
具体实施方式
下面详细描述本发明的实例,在本实例中,以一个实际水下滑翔机垂直平面内的俯仰角控制为例,首先确定水下滑翔机基本特征参数,得到水下滑翔机在纵平面滑翔运动时的数学模型,其中输入控制量为移动质量块在x轴上的速度指令at,滑翔机变化的状态为s:{v1,v3,ω2,θ},v1,v3,ω2,θ分别是水下滑翔机x,z轴方向速度(x轴为机体坐标系前向轴,z轴为垂直于机体平面的坐标轴)、俯仰角速度、以及俯仰角。以滑块速度为输入的纵向滑翔运动控制框图如图2所示。
本实例方法的原理是:使用基于优先采样的深度强化学习方法实现水下滑翔机在垂直平面内的俯仰角的控制,具体步骤如下:
步骤1:建立4个bp神经网络,分别为当前决策神经网络、当前评价神经网络、目标决策神经网络和目标评价神经网络。当前决策神经网络与目标决策神经网络称为决策神经网络,当前评价神经网络和目标评价神经网络称为评价神经网络。决策神经网络有4个输入量,即当前时刻下水下滑翔机的状态值v1,v3,ω2,θ,有1个输出量,即动作值a。评价神经网络有5个输入量v1,v3,ω2,θ,a,有1个输出量为评价值。本实施例中,4个bp神经网络均有2层隐含层,第一个隐含层有400个节点,第二个隐含层有300个节点,4个bp神经网络均有一个输出节点。
bp神经网络的映射过程如下:
输入层信息——隐含层激活函数——第1层隐含层输出:
其中,xi为第i个输入量,ε为输入量的总个数。vki表示输入层到第1层隐含层的权值,bk为偏置阈值,z1k为第一个隐含层的第k个节点,h1取为400,f1(s)为隐含层激活函数,选取为relu函数。
第1层隐含层输出——隐含层激活函数——第2层隐含层输出:
其中,wjk表示第1层隐含层到第2层隐含层之间的权值,bj为偏置阈值,z2j为第2层隐含层第j个输出,h2取为300,f2(s)为输出层的激活函数,选取为relu函数。
第2层隐含层输出——输出层激活函数——输出层输出:
其中,y为输出,这里输出都为一个值,wj表示第2层隐含层到输出层之间的权值,bl为偏置阈值,f3(s)为输出层的激活函数,决策神经网络的输出层激活函数为tanh函数,评价神经网络的输出层激活函数为relu函数。
初始化4个神经网络的参数,初始化记忆库大小为n=10000,数据缓冲区的大小为n为64。
步骤2:获得当前时刻下水下滑翔机的状态值st:{v1,v3,ω2,θ},将状态值输入当前决策神经网络计算出在当前时刻姿态控制器的输出动作at,将输出的动作at施加给基于水下滑翔机在纵平面滑翔运动时的数学模型而构建的仿真器,得到下一时刻水下滑翔机的状态值st+1。根据当前时刻的状态st、当前时刻的动作at、目标俯仰角θd和下一时刻的状态st+1计算出当前时刻的奖励值rt。本实施例中rt取值为:
rt=r1+r2+r3
其中,r1=-λ1(dt-dt-1),r1代表当前俯仰角远离或靠近期望角度获得的回报值,r2=-λ2(wt-wt-1),r2代表角速度发生变化获得的回报值,r3根据当前俯仰角的大小取值,如果:|dt-dt-1|<0.1°,r3为一个正的“奖励”,如果θ<-90°或θ>90°时,r3为一个负数,表示惩罚,dt为在t时刻时,当前的俯仰角θ与目标俯仰角θd的差值,wt为在t时刻时俯仰角速率的大小,λ1和λ2为设定系数。
步骤3:将步骤2中获得的状态(st,at,rt,st+1)作为一组经验数据单元储存在记忆库中,将t自增1;判断t与设定的记忆库大小n之间关系,如果t<n,则利用更新后的st返回步骤2,直至记忆库中存储的经验数据单元数量满足n的要求后,进入步骤4。
步骤4:从记忆库中采样指定数目为n的经验数据单元存放到缓冲区中;通过基于优先级的经验回放机制对缓冲区中的n个经验数据单元进行优先级排序,并存储在sumtree数据结构中;sumtree数据结构中的头结点的值为所有节点所代表的经验数据单元的优先级之和,记为ptotal。
基于优先级的经验回放具体如下:定义p(i)为第i次经验的采样概率,p(i)的计算为:
其中,
步骤5:对步骤4得到的存储在sumtree数据结构中的n个经验数据单元,然后在n个经验数据单元中采样m个经验数据单元,本实施例中为了能够保证各种经验都有可能被选到,通过以下过程采样m个经验数据单元;
将[0,ptotal]等分为数目为m的小区间,在各个小区间中进行随机均匀采样,得到采样所得优先级对应的经验数据单元,共得到m个经验数据单元。
对采样得到的m个经验数据单元按照以下过程进行逐一处理,得出当前评价神经网络的梯度值
对于某个经验数据单元(st,at,rt,st+1),将状态st和动作信号at输入到当前评价神经网络中得到当前评价神经网络的评价值q;将下一时刻状态st+1输入目标决策神经网络中,得到目标决策神经网络输出的执行机构的动作信号μ';将下一时刻状态st+1和目标决策神经网络输出的动作值μ'输入到目标评价神经网络中得到目标评价神经网络的评价值q';
利用当前评价神经网络的评价值q和目标评价神经网络的评价值q'以及评价神经网络的损失函数l计算出当前评价神经网络的梯度值
当前评价神经网络的损失函数l为:
其中,ωi为第i个经验数据单元的重要性采样权重,δi为:
δi=ri+γq'(si+1,μ'(si+1|σμ')σq')-q(si,ai|σq)
ri是第i个经验数据单元中的奖励值,si+1是第i个经验数据单元中的下一时刻状态,σμ'是目标决策神经网络的参数,μ'(si+1|σμ')是si+1通过目标决策神经网络输出的执行机构的动作信号。σq'是目标评价神经网络的参数,q'(si+1,μ'(si+1|σμ')σq')是将μ'(si+1|σμ')和si+1通过目标评价神经网络得到的评价值大小。si是第i个经验数据单元中的当前时刻状态,ai是第i个经验数据单元中的当前时刻状态下的动作信号,σq为当前评价神经网络的参数,q(si,ai|σq)是当前评价神经网络的评价值大小。γ是折扣系数,γ取值为0.99。
当前评价神经网络的损失函数l的梯度为:
步骤6:当前评价神经网络更新:根据当前评价神经网络的梯度
步骤7:计算当前决策神经网络的梯度,梯度大小计算公式为:
其中
步骤8:当前决策神经网络更新:
根据当前决策神经网络的梯度
步骤9:目标评价神经网络与目标决策神经网络更新:根据更新后的当前评价神经网络参数对目标评价神经网络参数进行更新,根据更新后的当前决策神经网络参数对目标决策神经网络参数进行更新,更新公式为
其中,σt+1q表示更新后的当前评价神经网络参数,σtq'表示待更新的目标评价神经网络参数,σt+1q'表示更新后的目标评价神经网络参数;σt+1μ表示更新后的当前决策神经网络参数,σtμ'表示待更新的目标决策神经网络参数,σt+1μ'表示更新后的目标决策神经网络参数;τ1为目标评价神经网络的更新率取值为0.001,τ2为目标决策神经网络的更新率取值为0.0001。
步骤10:判断训练次数是否超过设定训练次数,如果超过设定训练次数,则停止训练,保存4个神经网络的参数值,如果没有超过设定的训练次数,则返回步骤4,重新在记忆库中采样指定数目为n的经验数据单元存放到缓冲区中。
步骤11:得到训练完成的深度强化学习神经网络模型后,应用到实际水下滑翔机在纵平面滑翔运动中,给定目标俯仰角θd,采集水下滑翔机的状态值{v1,v3,ω2,θ}输入到深度强化学习神经网络模型得到控制量(移动质量块在x轴上的速度指令at)实现水下滑翔机姿态控制。
图4为本实例姿态控制器的训练过程的回合奖励值(episodereward),训练效果的评价主要通过回合奖励值来衡量,训练一定周期后,平均回报值越大,表明训练的效果越好,如图4所示,回合奖励持续上升,经过900个回合训练,回合奖励值基本稳定在850左右,表明控制器学习到了良好的策略。
图5为应用阶段的一个实例,表示下滑过程中俯仰角的大小变化过程。设置初始俯仰角为0°开始下滑,期望俯仰角为-25°。经过16s俯仰角度达到期望值大小,稳定下滑时稳态误差为0.06°,可以看出,稳定滑翔时俯仰角与期望角度的误差较小,可以认为滑翔机能够按照期望的轨迹连续滑翔。
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在不脱离本发明的原理和宗旨的情况下在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
- 还没有人留言评论。精彩留言会获得点赞!