一种用于弹幕情感分析且基于表情和语气的情感词典构建方法与流程
本发明涉及文本情感分析技术领域,尤其涉及一种用于弹幕情感分析且基于表情和语气的情感词典构建方法。
背景技术:
近年来,随着网络视频行业的快速发展,网络视频用户规模的也在不断扩大,弹幕评论越来越受到欢迎。弹幕是一种新兴、实时更新的互动评论系统,它以滚动字幕的方式直接显示在视频界面上,有助于加深观众对视频内容的理解,也可促进观看相同类型视频的观众之间交流。随着弹幕功能在各大视频网站的流行,弹幕中的情感信息越来越具有普遍性和参考性,这些情感信息能准确地反应用户在观看视频时的情感和褒贬评价。
目前,国内外在文本情感分析方面做出了一定的研究成果,但主要集中在社交媒体和商品评论两大领域,因弹幕是近几年新兴的一种互动评论方式,故对弹幕的研究很少,现有对弹幕的研究是将其视为与视频内容紧密相关的时间同步的文本标签,主要应用于视频内容摘要、视频内容标记及视频关键帧推荐。由于弹幕本身的特点,比如文本内容较短,口语化,网络用语较多,用语不规范等,所以对弹幕的情感分析仍然存在很大的挑战。
现有针对弹幕的研究是将弹幕视为与视频内容紧密相关的时间同步的文本标签,越来越多的研究学者围绕弹幕评论进行视频数据分析:
sun,s.等人针对自动电影内容摘要,利用弹幕评论选择候选的视频高亮片段,再根据弹幕的数量与内容对候选片段进行评分,最后选择达到最高分的候选片段组成电影内容摘要;
zeng,z.等人针对视频内容标记,提出一种监督动态lda模型,该模型利用弹幕评论的变分主题提取类型标签和关键字作为标签;
chen,x.等人针对视频关键帧推荐,利用视频图像和弹幕评论设计一个新颖的关键帧推荐器,可针对用户进行个性化的关键帧推荐;
此外,研究人员还从弹幕的传播角度出发,zhao,c.等人利用弹幕内容评估锚的情感,并预测锚的后续行为,提出一种网络广播锚定行为评估系统,若直播内容是暴力或色情内容,平台管理人员可提前禁止,以避免造成更大影响;yonggang,z.等人探讨在大学英语视听课中使用弹幕的有效性,它可以有效地激发学生的兴趣,促进课堂互动,并促进教师监督教学。
现有基于情感词典的文本情感分析方法中,没有考虑颜文字表情对情感分析的影响,颜文字表情在文本预处理阶段经常易被过滤掉,这影响了情感分析的效果,无法尽量准确地还原文本的真实情感倾向。同时,现有的方法也忽视了语气词在情感表达中的作用,语气词通常被认为是没有意义可以被省略的停用词,在文本预处理阶段将被过滤掉,这忽视了语气词本身含有情感色彩,进而影响情感分析的准确率。
技术实现要素:
本发明所解决的技术问题在于提供一种用于弹幕情感分析且基于表情和语气的情感词典构建方法,以解决上述背景技术中的问题。
本发明所解决的技术问题采用以下技术方案来实现:
一种用于弹幕情感分析且基于表情和语气的情感词典构建方法,具体步骤如下:
(1)构建传统情感词典
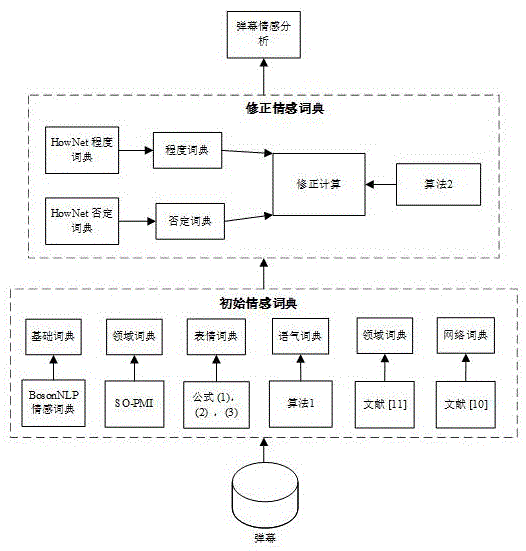
首先构建一本传统情感词典td,td包括基础情感词典、领域词典、字段词典、网络词典、程度词典及否定词典,即td={基础情感词典,领域词典,字段词典,网络词典,程度词典,否定词典},基础情感词典基于bosonnlp情感词典构建,领域词典基于so-pmi算法构建,字段词典基于字段分类器构建,网络词典基于搜狗输入法词典构建;
(2)构建表情词典
定义i:表情词典,表情词典由一组表情构成,使用e表示表情词典,e具有三个属性:符号、类别和情感值,令s为e中的符号集合,c为类别的集合,e.v为情感值的集合,
表情来自搜狗输入法的表情词典,包括23个类别的802个表情符号,目前,对表情的研究主要基于传播科学,很少有研究将表情应用于情感分析,因此,如何确定表情的情感值是一个挑战,故采用如下计算表情情感值的方法:
首先,
公式(1)中,ecd为表情相关度的缩写,b(e1,e2)表示两个表情e1和e2一起出现的弹幕数量,b(e1)和b(e2)表示两个表情单独出现的弹幕数量;
公式(1)的计算将得到三个结果,①当ecd(e1,e2)>>0时,e1与e2具有相关性,若e1和e2之间存在相关性,则b(e1,e2)>b(e1)与b(e2),同时,ecd(e1,e2)越大,相关性越强,②ecd(e1,e2)<<0时,e1与e2互斥,同时ecd(e1,e2)的较大值显示两个表情更加互斥;③当ecd(e1,e2)≈0时,e1与e2独立,即e1与e2不相关或互斥;
其次,设置一组正向表情pe和一组负向表情ne,且
最后,定义低阈值
公式(3)中,①当e.v>0时,e是积极表情;②当e.v=0时,e是中性表情;③当e.v<0时,e是消极表情;
(3)构建语气词典
定义ii:语气词典,语气词典由一组语气词构成,采用t表示一个语气词典,t具有“语气词”和“情感值”两个属性,令w为t中的语气词集合,t.v为情感值的集合,
同时发现,bosonnlp情感词典中部分语气词的情感倾向与弹幕的实际情感倾向不符,故未将bosonnlp中的任何语气词添加到t中,采用bdict表示bosonnlp中的所有单词名称;
首先根据jieba分词工具,将弹幕b分为一组单词j,
而后将语气词集w作为输入参数输入so-pmi算法中,获得一组so-pmi值sw,最后,根据sw计算出一组语气词情感值;
在传统情感词典td上添加构建表情词典e与语气词典t,得到新词典bset;
(4)构建程度词典和否定词典
为区分具有相同情感词的不同弹幕,在新词典bset中构建程度词典dd和否定词典nd;
(5)对所有情感词典进行修正
对基于步骤(4)构建的所有情感词典进行修正,并将获得修正后的情感值用于弹幕情感分析,采用v表示所有情感值,
定义iii:弹幕句型,不同句型对应于不同的情感强度,定义句型影响系数x,x的计算规则如下:
规则1:若弹幕类型是感叹句,即“!”出现在弹幕中,x=2;
规则2:若弹幕类型是疑问句,即“?”出现在弹幕中,弹幕中没有任何反问标志词(例如“难道”),x=0.9;
规则3:若弹幕类型是反问句,即“?”出现在弹幕中,弹幕中有一个反问标志词(例如“难道”),x=-1.5;
规则4:若不满足上述三个规则,则x=1;
根据句型影响系数x的定义,计算v的修正情感值vm如公式(4)所示:
vm=v×x#(4)
定义iv:程度修正,当情感词由一组k个程度词di∈dd修正时,i∈[1,k],相应的校正系数为dm-i,v的修正情感值vm的计算方法如公式(5)所示:
定义v:否定修正,当一组否定词为修正情感词开头时,计算方法如公式(8)所示:
vm=v×x×(-1)n#(6)
其中,n是否定词的数量;
否定词和程度词同时出现在弹幕中的情况有两种:一种是“否定词+程度词+情感词”,它对情感强度的影响较小,另一个是“程度词+否定词+情感词”,它对情感强度的影响更大,因此,相关定义如下:
定义ⅵ:程度词+否定词,当情感词由一组程度词+一组否定词修饰后,
定义ⅶ:否定词+程度词,当用一组否定词+一组程度词修饰情感词时,v的修正情感值vm的计算方法如公式(8)所示:
基于以上定义,计算情感词修正,以弹幕b、一组程度问题qw、程度词典dd、否定词典nd和b中情感词的初始情感值v为输入,同时,将修正后的情感值vm作为输出,并将获得修正后的情感值vm用于分析弹幕评论的情感倾向,计算情感倾向人数为视频评分,将弹幕分为三个类别,首先,设置情感阈值范围δ=[δmin,δmax],然后,
有益效果:本发明在传统情感词典基础上构建有表情词典与语气词典,从而提高了弹幕情感分析的准确性,同时注重语气词的作用,有效增强弹幕情感分析的效果;而后对基于程度词典和否定词典构建的所有情感词典进行修正,同时采用修正后的情感值用于弹幕情感分析,实验结果表明本发明比现有的方法在弹幕情感分析领域具有更好的性能。
附图说明
图1是本发明的较佳实施例的bset情感词典示意图;
图2是本发明的较佳实施例中的语气情感值计算流程示意图;
图3是本发明的较佳实施例中的td+t准确率对比图;
图4是本发明的较佳实施例中的td+t召回率对比图;
图5是本发明的较佳实施例中的td+tf值对比图;
图6是本发明的较佳实施例中的td+e准确率对比图;
图7是本发明的较佳实施例中的td+e召回率对比图;
图8是本发明的较佳实施例中的td+ef值对比图;
图9是本发明的较佳实施例中的bset准确率对比图;
图10是本发明的较佳实施例中的bset召回率对比图;
图11是本发明的较佳实施例中的bsetf值对比图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本发明。
一种用于弹幕情感分析且基于表情和语气的情感词典构建方法,也称为bset(anewbarragesentimentanalysisschemebasedonexpressionandtone,bset)算法,具体步骤如下:
所涉及的重要符号定义如下:
(1)构建传统情感词典
首先构建一本传统情感词典(缩写为td),td包括基础情感词典、领域词典、字段词典、网络词典、程度词典及否定词典,即td={基础情感词典,领域词典,字段词典,网络词典,程度词典,否定词典},基础情感词典基于bosonnlp情感词典构建,领域词典基于so-pmi算法构建,字段词典基于字段分类器构建,网络词典基于搜狗输入法词典构建;在研究弹幕的情感倾向时,构建高质量的情感词典对弹幕情感分析有着至关重要的影响,为此构建表情词典和语气词典,以获得新词典bset;
(2)构建表情词典
定义i:表情词典,表情词典由一组表情构成,使用e表示表情词典,e具有三个属性:符号、类别和情感值,令s为e中的符号集合,c为类别的集合,e.v为情感值的集合,
本实施例使用的表情来自搜狗输入法的表情词典,包括23个类别的802个表情符号,目前,对表情的研究主要基于传播科学,很少有研究将表情应用于情感分析,因此,如何确定表情的情感值是一个挑战,为此本实施例采用一种计算表情情感值的方法:
首先,
公式(1)中,ecd为表情相关度的缩写,b(e1,e2)表示两个表情e1和e2一起出现的弹幕数量,b(e1)和b(e2)表示两个表情单独出现的弹幕数量;
公式(1)的计算将得到三个结果,①当ecd(e1,e2)>>0时,e1与e2具有相关性,若e1和e2之间存在相关性,则b(e1,e2)>b(e1)与b(e2),同时,ecd(e1,e2)越大,相关性越强,②ecd(e1,e2)<<0时,e1与e2互斥,同时ecd(e1,e2)的较大值显示两个表情更加互斥;③当ecd(e1,e2)≈0时,e1与e2独立,即e1与e2不相关或互斥;
其次,设置一组正向表情pe和一组负向表情ne,且
最后,定义低阈值
公式(3)中,①当e.v>0时,e是积极的表情;②当e.v=0时,e是中性的表情;③当e.v<0时,e是消极的表情,表情词典在23个类别中有802个表情符号;为简化说明,本实施例仅提供每种类别的一个表情示例,如表1所示,在表1中,设置
表1表情词典中每种类别表情示例表
(3)构建语气词典
由于口语化和语气词的简化等影响,存在许多完全由语气词组成的弹幕,例如“(ha-ha)”弹幕,由于有趣的视频情节,弹幕能够表达观众的笑声,还能够传达观众积极乐观的感觉,若将“ha-ha”这个语气词作为停用词过滤掉,则将降低情感分析的效果和准确性,为消除上述问题,构建一个新的弹幕语气词典,语气词典定义如下:
定义ii:语气词典,语气词典由一组语气词构成,采用t表示一个语气词典,t具有“语气词”和“情感值”两个属性,令w为t中的语气词集合,t.v为情感值的集合,
同时发现,bosonnlp情感词典中部分语气词的情感倾向与弹幕的实际情感倾向不符,故未将bosonnlp中的任何语气词添加到t中,为便于描述,采用bdict表示bosonnlp中的所有单词名称;
在图2中,首先根据jieba分词工具,将弹幕b分为一组单词j,
而后将语气词集w作为输入参数输入so-pmi算法中,获得一组so-pmi值sw,最后,根据sw计算出一组语气词情感值,具体计算过程如表2所示,将弹幕b与bdict作为输入,同时,以一组语气词集w与一组语气词情感值t.v作为输出,首先,找到一组语气词w(步骤2~7),其次,计算语气词情感值t.v集合(步骤8~24):
图2语气词情感值t.v集合计算表
为便于理解,表3中给出一个示例用以说明语气词情感值t.v集合计算的执行结果:
表3语气词情感值t.v集合计算执行结果表
在上述表3中,因id=2的弹幕不包含任何语气词,故不运行表2的步骤9~21,即无情感值(步骤23);运行步骤2~7后,id=1弹幕的语气词为“mama”,即得到它的so-pmi值6.7(第9步),而后得到它的情感值1(步骤10~21);
(4)构建程度词典和否定词典
如,一个观众说“好看”,另一个说“非常好看”,另一个说“不好看”,若这三个弹幕的情感值相同,显然是不合理的;同样,观众发出一束鲜花,若在鲜花后添加感叹号,则显然两个情感值应该不同,因此,有必要修改情感值以区分具有相同情感词的不同弹幕,为此,构建程度词典和否定词典,采用dd表示程度词典,采用nd表示否定词典,修正的计算不仅针对某种词典,而且针对所有情感词典,因此,根据上述定义,采用v表示所有情感值,
定义iii:弹幕句型,不同句型对应于不同的情感强度,定义句型影响系数x,x的计算规则如下:
规则1:若弹幕类型是感叹句,即“!”出现在弹幕中,x=2;
规则2:若弹幕类型是疑问句,即“?”出现在弹幕中,弹幕中没有任何反问标志词(例如“难道”),x=0.9;
规则3:若弹幕类型是反问句,即“?”出现在弹幕中,弹幕中有一个范文标志词(例如“难道”),x=-1.5;
规则4:若不满足上述三个规则,则x=1;
根据句型影响系数x的定义,计算v的修正情感值vm如公式(4)所示:
vm=v×x#(4)
定义iv:程度修正,当情感词由一组k个程度词di∈dd修正时,i∈[1,k],相应的校正系数为dm-i,v的修正情感值vm的计算方法如公式(5)所示:
定义v:否定修正,当一组否定词为修正情感词开头时,计算方法如公式(8)所示:
vm=v×x×(-1)n#(6)
其中,n是否定词的数量;
否定词和程度词同时出现在弹幕中的情况有两种:一种是“否定词+程度词+情感词”,它对情感强度的影响较小,另一个是“程度词+否定词+情感词”,它对情感强度的影响更大,例如,“看起来不太好”和“看起来太不好”,第一句话的情感强度明显弱于第二句话的情感强度,因此,相关定义如下:
定义ⅵ:程度词+否定词,当情感词由一组程度词+一组否定词修饰后,
定义ⅶ:否定词+程度词,当用一组否定词+一组程度词修饰情感词时,v的修正情感值vm的计算方法如公式(8)所示:
基于以上定义,表4中详细介绍情感词经过修正的计算过程,该算法以弹幕b、一组程度问题qw、程度词典dd、否定词典nd和b中情感词的初始情感值v为输入,同时,将修正后的情感值vm作为输出:
图4情感词修正计算表
在获得修正后的情感值vm后,可以以多种方式使用这种数据,它可用于分析弹幕评论的情感倾向,计算情感倾向人数为视频评分等,例如,将弹幕分为三个类别,首先,设置情感阈值范围δ=[δmin,δmax],然后,
假设设置δ=[-0.8,0.8],并以表5为例,说明情感词修正计算的执行过程,在id=1的范围内,“so”的程度校正系数为2.678,即dm=2.678且x=1,因此,vm=v×x×dm=(-2×1×2.678=-5.356<-0.8,故id=1的弹幕为消极弹幕;id=2的弹幕具有与“so”相同的度数校正系数,但有一个感叹号“!”,因此x=2,即vm=v×x×dm=1×2×2.678=5.356>0.8,故id=2的弹幕为积极弹幕,为简化描述,此处省略其他弹幕的分析过程:
表5情感词修正计算的执行结果表
(5)验证bset方法的有效性和实用性
将bset与sacm方法、ctsa方法进行对比,这两种方法与本实施例的技术方案最为相似,同时,sacm方法和ctsa方法也是应用场景中最经典的方法,在所有实验中,设置
本实施例采用在自然语言处理领域被广泛认可和使用的准确率、召回率以及f值作为实验性能的评估指标,以测试弹幕情感分析的三种方法(bset,sacm和ctsa)的性能,准确率的定义如公式(9)所示,召回率的定义如公式(10)所示,f值的定义如公式(11)所示,在这三个公式中,nc代表分类中正确的弹幕分析数量,na代表分类中实际的弹幕分析数量,ns代表应作为分类分析的弹幕数量:
首先,构建传统情感词典(缩写为td),td包括基础情感词典、领域词典、字段词典、网络词典、程度词典及否定词典,即td={基础情感词典,领域词典,字段词典,网络词典,程度词典,否定词典},此外,还向td添加一些新的情感词,此处td指的是现有的词典,包括最新的情感词典;而后将两个新词典添加到td中:表情词典e和语气词典t,同时将此新词典命名为bset,bset={td,e,t};
为清楚呈现添加t和e后的效果,设计三组实验:在第一组中,将语气词典t添加至td中以获得新的词典td+t,而后将td+t的性能与现有的两种方法(sacm和ctsa)进行比较;在第二组中,将表情词典e添加至td中以获得新的词典td+e,依次将td+e与现有的两种方法进行比较;在第三组中,将表情词典e和语气词典t添加至td中以获得新的词典bset,与现有方法进行比较,最后在各种弹幕上对比三种方法的性能,如表6所示:
表6弹幕性能对比表
为验证语气词典t对弹幕情感分析的影响,第一组的实验结果如图4所示,其中三个横坐标均代表弹幕分类,图3的纵坐标代表准确率,图4的纵坐标代表召回率,图5的纵坐标代表f值;
在图3中,td+t在td的基础上增加有语气词典t,因此,可以识别出不包含在td中的语气词,故td+t在所有情感趋势中的准确率均高于sacm和ctsa,这证明语气对弹幕情感分析的明显影响,即语气词典t的构建有助于提高情感分析的准确性;
另外,例如,“很难说我是否喜欢”出现在情感词“喜欢”上,但实际上,这种弹幕是中立,因此,使用阈值范围而不是阈值,这使得bset在中性弹幕的准确率方面明显优于ctsa和sacm;
在图4中,添加语气词后,被误分类为中性弹幕的某些弹幕被正确分类为积极或消极弹幕,因此,td+t的召回率比ctsa和sacm的召回率高;ctsa增加一些字段词和多义词,因此ctsa的平均召回率高于sacm;
在图5中,每种分类中td+t的f值均高于sacm和ctsa,sacm专注于微博,但微博中的语气词不如弹幕中的重要,另一方面,ctsa添加有一些带有强烈情感色彩的情感词,因此,多义弹幕的f值略高于sacm;
为验证表情词典e对弹幕情感分析的影响,第二组实验结果如图5所示,其中三个横坐标均代表弹幕分类,图6的纵坐标代表准确率,图7的纵坐标代表召回率,图8的纵坐标代表f值;
在图6中,td+e在td的基础上添加表情词典e,可以识别传统词典中不包括的表情符号,因此有效地增加正确识别的弹幕数量,这也使得情感分析准确率高于现有的sacm和ctsa方法,证明表情对情感分析的明显影响,构建表情词典e有助于提高情感分析的效果;同时,td+e的准确率明显高于td+t,因此,表情的添加比语气词的添加更有助于情感分析;
在图7中,添加表情词典e后,可以正确地分类一些错误分类的弹幕,因此,各种分类的召回率高于现有的sacm和ctsa,sacm没有多义词、字段词或表情,因此sacm的召回率低于td+e和ctsa;
在图8中,td+e可将错误分类的一些中性弹幕正确分类为消极弹幕和积极弹幕,显着提高积极弹幕和消极弹幕的f值,故具有比sacm和ctsa高的f值,ctsa增加有一些经典情感词,因此比sacm更好地找到正确的情感词分类,因此,ctsa的f值高于sacm;
为验证bset的有效性和实用性,第三组实验结果如图9~图11所示,其中三个横坐标均代表弹幕分类,图9的纵坐标代表准确率,图10的纵坐标代表召回率,图11的纵坐标代表f值;
在图9中,由于添加语气词典t和表情词典e,因此bset在所有分类中的准确率均显着高于sacm和ctsa,但由于ctsa添加有具有强烈情感色彩和明显情感倾向的多义情感词,因此在精确度分析方面,ctsa优于sacm;
在图10中,ctsa添加有一些多义情感词,因此可更好地识别积极弹幕和消极弹幕,sacm添加有程度词典、网络词典和否定词典,因此可以修改情感值,但sacm没有考虑表情词典和语气词典,从而导致许多有效情感词被忽略,故召回率低于bset;
在图11中,sacm针对微博,弹幕与网络文化密切相关,因此,弹幕具有许多微博无法提供的功能,在处理弹幕的情感分析时,将一组积极弹幕和消极弹幕分为中立弹幕,因此,sacm的f值低于ctsa和bset的f值,ctsa未考虑表情在弹幕中的影响,因此情感分析的f值低于bset。
综上,本实施例构建的情感词典分析可用于许多场景,如云计算、发布/订阅、电影评论及数据查询等。
- 还没有人留言评论。精彩留言会获得点赞!