一种自适应特征及数据分布的目标检测方法与流程
本发明涉及计算机视觉技术领域,特别是自适应特征及数据分布的目标检测方法denseattentionnetwork。
背景技术:
在计算机视觉领域,卷积神经网络被广泛使用。尤其是2012年alexnet在imagenet竞赛中以超过第二名10.9个百分点的优势夺得冠军之后,卷积神经网络在计算机视觉领域的应用更加广泛,alexnet同时也奠定了深度学习里程碑式的基础。
来自于牛津大学的karensimonyan和andrewzisserman于2014年提出了vgg-nets,在2014年imagenet竞赛中取得了定位任务的第一名和分类任务第二名的优秀结果。vgg-nets展示了可以在先前网络架构的基础上通过增加网络层数和深度来提高网络的性能。vgg-nets包含16-19层权重网络,比先前的网络架构更深层数更多。当然除了更深的层数之外,卷积层使用更小的filter尺寸和间隔,这样做不但减少了参数量,而且增加了网络的非线性表达能力。
googlenet在2014年击败所有对手,成为imagenet分类任务的冠军。它跟alexnet,vgg-nets这种单纯依靠加深网络结构进而改进网络性能的思路不一样,在加深网络的同时(22层),也在网络结构上做了创新,引入inception结构代替了单纯的卷积激活的传统操作(这思路最早由networkinnetwork提出)。googlenet进一步把对卷积神经网络的研究推上新的高度。
从alexnet、vgg-nets、googlenet的发展可以看到,随着网络深度的增加,网络的准确度也应该逐步增加。但是网络深度增加的一个问题在于这些增加的层是参数更新的信号,因为梯度信息是从后向前传播的,增加网络深度后,比较靠前层的梯度就会很小,也就意味着这些层的学习基本上停滞了,也就是所谓的梯度消失。另一方面更深的网络意味着更大的参数空间,优化问题变得更难,一味的增加网络深度可能会造成更高的训练误差,网络出现退化。针对这些问题,何恺明团队在2015年推出了残差网络resnet,并在当年的islvrc和coco上横扫所有选手,获得冠军。resnet的优点是更加容易优化,并能从网络层数的增加带来显著的精度提升,此网络也因152层的网络结构创造了新的模型记录。
gaohuang,zhuangliu,kilianq.weinberger和laurensvandermaaten于2016年提出了密集卷积神经网络densenet的概念,它吸收了resnet的最精华的部分,并且做了更加创新的工作,使用密集链接,缓解梯度消失问题,加强特征传播,更加有效的利用特征,极大的减少了参数量。使得网络更深,参数量反而更少,在cifar指标上全面超越resnet。
2017年momenta胡杰团队(wmw)提出的新的网络结构提出了squeeze-and-excitationnetworks(简称senet)。作者在文中将senetblock插入到现有的多种分类网络中,都取得了不错的效果。作者的动机是显式地建模特征通道之间的相互依赖关系。另外,作者并未引入新的空间维度来进行特征通道间的融合,而是采用了一种全新的「特征重标定」策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
上述现有技术,依然存在的缺陷有:
1、参数冗余
虽然现有的网络结构越来越深,越来越宽,在一些公开数据集上也达到了一个不错的效果,但是这也带来了更多的参数。由于无法确定哪一层或者哪一些参数起到了关键作用,也无法确定某一层或某些参数是否真的被用到,这一定程度上造成了参数的冗余。
2、针对实际任务的优化难度大
现有网络的设计都是针对于比较复杂的数据集,这些数据集的类别比较多,但是在实际任务中可能并没有那么多的类别,数据也不一定特别复杂,目标的大小分布也相对比较集中。在保证网络精度的同时,为了减少网络的计算资源,通常的做法是减少一些层,但是无法确定减少哪些层才足够有效。必须通过大量的实验比较,此时会消耗掉大量的时间和精力。
3、网络训练阶段无法自适应数据的分布
现有网络大多设计有多个特征金字塔fpn,但是每个fpn的训练损失权重是相同的。实际任务中目标的大小分布往往是比较集中的,检出结果可能大多出自一个fpn,那么每个fpn的损失权重完全相同显然是不科学的。
技术实现要素:
为了解决上述现有技术中存在的缺陷,本发明的目的是提供一种自适应特征及数据分布的目标检测方法。它可以自动选择某些层的某些参数作为特征图进行目标检测,有效减少冗余的参数,节省对网络进行优化的时间。
为了达到上述发明目的,本发明的技术方案以如下方式实现:
一种自适应特征及数据分布的目标检测方法,其方法步骤为:
1)输入图像采用宽度w为416像素、高度h为416像素、通道数c为3。
2)减小尺寸增加通道数模块运算dropriseblock:
对输入图像进行降采样并增加通道数。
3)2路密集连接模块运算2-waysdenseblock:
对图像分2路捕获不同尺寸的感受野信息,输出得到3x3和5x5的感受野。
4)生成特征图featuremap:
对输入图像先经过1个dropriseblock运算,然后再进行1个2-waysdenseblock运算,再经过1个卷积并激活convolution&relu和最大池化maxpooling运算,再经过2个2-waysdenseblock运算,再经过1个convolution&relu和maxpooling运算,再经过4个2-waysdenseblock运算,再经过1个convolution&relu和maxpooling运算,最后经过8个2-waysdenseblock运算,最终生成13x13x1024的featuremap。
5)对各个通道权重的学习、计算和重新筛选:
给每个通道分配一个0~1的权重,每个通道的输入系数分别乘上对应权重得到对应输入。然后,根据各个通道权重的大小,将权重较小的通道丢弃,实现对通道的筛选。
6)目标位置及类别的回归:
使用多个特征金字塔fpn回归目标的位置、置信度和类别。
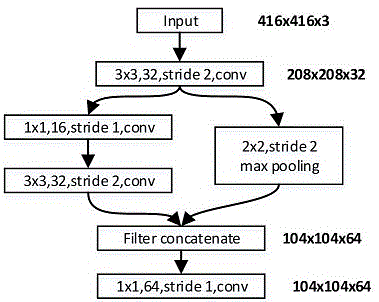
在上述目标检测方法中,所述对输入图像进行降采样并增加通道数,此操作将输入宽度w变为104,高度h变为104,通道数c增加到32。
在上述目标检测方法中,所述对图像分2路捕获不同尺寸的感受野信息的方法为,一路经过卷积核大小为1x1的卷积之后,再进行一层卷积核大小为3x3的卷积运算,另外一路则经过卷积核大小为1x1的卷积计算之后,再进行两层卷积核大小为3x3的卷积运算,两个大小为3步长为1的卷积核其感受野等于一个5x5卷积核的感受野。
在上述目标检测方法中,所述生成特征图步骤中的convolution&relu模块卷积核的大小为1x1,通道数与前一层输出的通道数相同,其目的是保持宽、高、通道数都不变的前提下,对前面的特征进行融合;maxpooling运算采用的核大小为2x2,将特征的尺寸降为原来的一半。
在上述目标检测方法中,所述使用多个特征金字塔为3个。
本发明由于采用了上述方法步骤,同现有技术相比具有如下优点:
1、本发明使用的网络结构为轻量级架构,网络参数更少,参数利用率更高。针对不同的目标检测及分类任务能保持主干网络结构不变。
2、针对一些特定的目标检测任务,本发明能自动选择比较适宜层的不同深度、更易目标识别的特征进行计算,自动舍弃不重要的不易于目标识别的特征以提高网络的质量并减少网络计算量,且无需手动调节网络结果。
3、能够根据样本的分布自动调整每个fpn训练损失权重,使训练收敛速度更快、更准确。
下面结合附图和具体实施方式对本发明做进一步说明。
附图说明
图1为本发明中减小尺寸增加通道数模块示意图;
图2为本发明中原始密集连接模块示意图;
图3为本发明中2路密集连接模块示意图;
图4为本发明中生成特征图示意图;
图5为本发明中se-block模块示意图;
图6为本发明中se-block模块之后添加通道筛选层示意图;
图7为本发明实施例中实施方案示意图。
具体实施方式
本发明自适应特征及数据分布的目标检测方法用densenet的对特征复用的特性,densenet最后的特征层包含了前面所有宽高相同通道的特征。本发明利用了inception结构思想对densenet进行了修改,对最后特征层的每个通道学习一个权重,每个通道参数乘以权重,之后把权重较低的通道直接丢弃,最后送入多fpn的目标检测模块,以达到自动选择最优的深度特征进行目标检测的效果。具体方法步骤为:
1)输入图像采用宽度w为416像素、高度h为416像素、通道数c为3。需要先将图像的尺寸变换为416x416,如果输入图像尺寸不为416x416,后续步骤中的输入输出也会发生改变。
2)dropriseblock运算:
参看图1,对输入图像进行降采样并增加通道数,此操作将输入宽度w变为104,高度h变为104,通道数c增加到32。
3)dropriseblock运算:
参看图2、图3,此处的目标通道数k取值为32。借鉴inception分多路捕获不同尺度感受野信息的思想,对图像分2路捕获不同尺寸的感受野信息,输出得到3x3和5x5的感受野。具体方法为,一路经过卷积核大小为1x1的卷积之后,再进行一层卷积核大小为3x3的卷积运算,另外一路则经过卷积核大小为1x1的卷积计算之后,再进行两层卷积核大小为3x3的卷积运算,两个大小为3步长为1的卷积核其感受野等于一个5x5卷积核的感受野。
4)生成featuremap:
参看图4,对输入图像先经过1个dropriseblock运算,然后再进行1个2-waysdenseblock运算,再经过1个convolution&relu和maxpooling运算,再经过2个2-waysdenseblock运算,再经过1个convolution&relu和maxpooling运算,再经过4个2-waysdenseblock运算,再经过1个convolution&relu和maxpooling运算,最后经过8个2-waysdenseblock运算,最终生成13x13x1024的featuremap。convolution&relu模块卷积核的大小为1x1,通道数与前一层输出的通道数相同,其目的是保持宽、高、通道数都不变的前提下,对前面的特征进行融合。maxpooling运算采用的核大小为2x2,将特征的尺寸降为原来的一半。
5)对各个通道权重的学习、计算和重新筛选:
权重的学习和计算采用2017imagenet分类比赛冠军模型senet中的se-block,此处只给出其操作流程,不做详细介绍。给每个通道分配一个0~1的权重,每个通道的输入系数分别乘上对应权重得到对应输入。
参看图5、图6,本发明提出一种新的层,通道筛选层channelscreenlayer,根据各个通道权重的大小,将权重较小的通道直接丢弃,不参与后面模块的计算,放在se-block的后面,对通道进行筛选。
令i表示输入通道的序号,通道的总数为i,n表示要保留的通道的数量,对输入通道的权重按大小进行排序,此处只取前n个序号,得到包含序列号的序列l。对于所有的通道,如果i属于l,则保留此通道,否则直接丢弃。在反向传播时,得到保留的通道的梯度保持不变,丢弃的通道的梯度赋值为0。
本发明将n设置为512(使用此值,但不仅限于此值),直接丢弃了512个通道,也即是从1024个通道中选择了最优的512个通道,参与后面的计算,由于denseblock的特性,这512个通道可能来自不同的层,从而达到自动选择特征的效果。
6)目标位置及类别的回归:
使用3个特征金字塔回归目标的位置、置信度和类别。
在实际任务中,待检出目标大小的分布往往是比较集中的,所以每个fpn层的训练权重不应是相同的,而是应该与样本的分布有关,所以本发明提出了一种根据样本分布自动对训练损失进行加权的方法。
记每个fpn层分别为fi,i表示每个fpn层的序号,其每一层的损失为li。初始化每个fpn层的训练损失权重λi都为1/3,总是损失函数
对si执行归一化指数函数运算(softmax),此操作将进一步调整每个fpn层训练损失权重,即λi=softmax(si)。经过此调整之后,输出目标更多的层的损失权重更大一些,在训练过程中也更加容易收敛。
参看图7,本发明目标检测方法实施时主要分为2个阶段,网络预训练学习阶段和目标检测阶段,网络预训练学习阶段用来训练网络模型,目标检测阶段使用训练好的模型检测目标。
在训练学习阶段,需要先收集项目中的实际图像,然后对我们需要检出的目标进行标注,标注的内容是目标点左上角坐标、右下角坐标、以及类别。然后设置统计样本分布需要迭代的次数以及迭代的总次数。然后使用标注结果训练我们的denseattentionnetwork参数,迭代次数到达设置的次数之后,保存denseattentionnetwork网络训练结果模型。
在目标检测阶段,我们需要先加载已经训练好的denseattentionnetwork网络模型,并且设置目标检出阈值。然后将待检测的图片进行尺寸变换之后送入网络模型进行前向传播,最后使用非极大值抑制的方法对检出结果进行合并过滤,即可得出目标检测结果。
在本发明技术方案基础上使用的如下替换,均应属于本发明保护范围:
1、本发明的输入图像尺寸可根据需要替换为其他尺寸。
2、本发明的channelscreenlayer的输出通道数可替换为其他值,但是必须小于或等于1024个通道,为1024时即为保留所有通道。
3、针对目标分类任务,可以将channelscreenlayer之后的层替换为全局平均池化层+softmax层。
- 还没有人留言评论。精彩留言会获得点赞!