一种室内动态场景下的视觉定位方法与流程
本发明涉及图像处理
技术领域:
,具体涉及一种室内动态场景下的视觉定位方法。
背景技术:
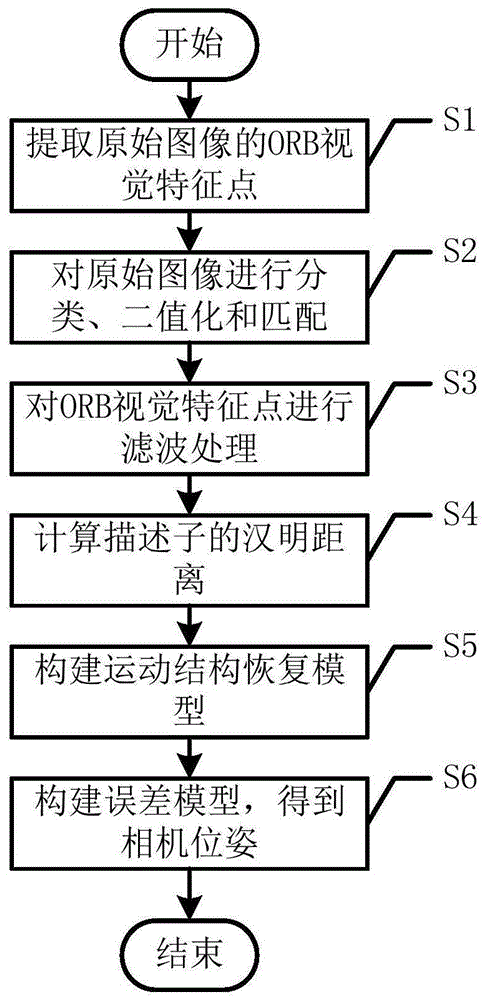
:利用视觉在室内进行定位的过程中,往往会出现移动的物体,大部分场景下移动的物体是活动的人,同时,目前所有的视觉定位建图系统的理论建立在静态场景假设上,现有技术中使用了结合光流与深度图平面假设的算法来进行前景物体的分割,此方法存在的问题是当物体与相机发生相对运动时,通常整个场景中的光流的一致性在不同的场景位置会不同,从而导致运动物体的光流难以判断,同时当场景复杂的情况下,静态场景的平面假设往往不成立导致前景判断的错误。另外一类方法是对运动物体的运动进行估计,并且将预测的运动物体的信息加入场景中进行定位建图。技术实现要素:针对现有技术中的上述不足,本发明提供的一种室内动态场景下的视觉定位方法,据物体检测得到的场景中物体分布的信息,同时结合人脸识别技术将场景中的人脸所在的图像块进行区分,通过将场景中可能发生位移的人剔除,从而进行精确的视觉定位。为了达到上述发明目的,本发明采用的技术方案为一种室内动态场景下的视觉定位方法,包括以下步骤:s1、采集室内动态场景下的原始图像,并提取其orb视觉特征点;s2、对原始图像分别进行物体和人脸分类、二值化和匹配,得到物体人脸二值掩膜图像;s3、采用物体人脸二值掩膜图像对orb视觉特征点进行滤波处理,得到静态场景特征点图像;s4、计算一幅静态场景特征点图像中的每一个特征点的描述子分别与另一幅静态场景特征点图像中所有特征点的描述子的汉明距离,得到多个特征点对;s5、根据特征点对,构建运动结构恢复模型,得到入射光线汇聚点;s6、将入射光线汇聚点投影至两幅静态场景特征点图像,构建误差模型,得到相机位姿,实现视觉定位。进一步地,步骤s2包括分步骤:s21、采用yolo神经网络对原始图像进行物体分类,得到物体像素框;s22、将物体像素框内的像素置1,物体像素框外的像素置0,得到物体二值掩膜图像;s23、采用mtcnn神经网络检测原始图像中的人脸像素框;s24、将人脸像素框内的像素值置1,人脸像素框外的像素值置0,得到人脸二值掩膜图像;s25、遍历人脸二值掩膜图像上的所有人脸像素框,通过每个人脸像素框对应的连通域中的每个像素检测对应物体二值掩膜图像的位置,判断其对应位置的掩膜值是否为1,若是,则保留对应位置的物体二值掩膜图像上的二值连通域,若否,将对应物体二值掩膜图像位置上的二值连通域置0,得到物体人脸二值掩膜图像。进一步地,步骤s3为:根据物体人脸二值掩膜图像,将orb视觉特征点的每一个特征点对应的物体人脸二值掩膜图像的值为1的位置剔除,得到静态场景特征点图像。进一步地,步骤s4包括以下分步骤:s41、计算一幅静态场景特征点图像中的每一个特征点的描述子分别与另一幅静态场景特征点图像中所有特征点的描述子的汉明距离;s42、寻找最小的汉明距离小于次小的汉明距离的60%以及最小的汉明距离小于汉明阈值的多对描述子;s43、将多对描述子各自在两幅静态场景特征点图像上的特征点作为特征点对。进一步地,步骤s5包括以下分步骤:s51、根据每一个特征点对,通过相机内参,得到特征点对的入射光线;s52、根据特征点对的入射光线,构建运动结构恢复模型,采用svd算法对运动结构恢复模型进行求解,得到入射光线汇聚点。进一步地,步骤s5中运动结构恢复模型为:x=k-1px′=k-1p′xt(t×r)x′=0p=[rt]x×px=0x=λx′其中,x为一幅静态场景特征点图像的入射光线的向量,x′为另一幅静态场景特征点图像的入射光线的向量,k为相机内参,p为一幅静态场景特征点图像上的特征点,p′为另一幅静态场景特征点图像上的特征点,t为两个相机之间的位移,r为相机之间的旋转角度矩阵,λ为入射因子,p为构建的相机旋转位移矩阵,x为入射光线汇聚点的坐标。进一步地,步骤s6中误差模型为:其中,p1为入射光线汇聚点在一幅静态场景特征点图像的位置,p2为入射光线汇聚点在另一幅静态场景特征点图像的位置,x为入射光线汇聚点的坐标,k为相机内参,x为一幅静态场景特征点图像的入射光线的向量,x′为另一幅静态场景特征点图像的入射光线的向量,err为误差值。综上,本发明的有益效果为:(1)、本发明主要提出一种基于物体检测与人脸识别融合信息的动态场景定位方法。本方法对空间中的语义信息进行提取与分类,相比传统视觉算法能适用更多的场景,在更复杂的室内环境中区分动态场景与静态场景,利用静态场景信息进行精确定位。(2)、本发明的语义信息更集中,基于室内环境中大多数的运动物体是人这一假设进行的深度学习算法设计,因此模型计算量更小,计算资源消耗更好,算法速度更快。附图说明图1为一种室内动态场景下的视觉定位方法的流程图。具体实施方式下面对本发明的具体实施方式进行描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。如图1所示,一种室内动态场景下的视觉定位方法,包括以下步骤:s1、采集室内动态场景下的原始图像,并提取其orb视觉特征点;s2、对原始图像分别进行物体和人脸分类、二值化和匹配,得到物体人脸二值掩膜图像;步骤s2包括分步骤:s21、采用yolo神经网络对原始图像进行物体分类,得到物体像素框;s22、将物体像素框内的像素置1,物体像素框外的像素置0,得到物体二值掩膜图像;s23、采用mtcnn神经网络检测原始图像中的人脸像素框;s24、将人脸像素框内的像素值置1,人脸像素框外的像素值置0,得到人脸二值掩膜图像;s25、遍历人脸二值掩膜图像上的所有人脸像素框,通过每个人脸像素框对应的连通域中的每个像素检测对应物体二值掩膜图像的位置,判断其对应位置的掩膜值是否为1,若是,则保留对应位置的物体二值掩膜图像上的二值连通域,若否,将对应物体二值掩膜图像位置上的二值连通域置0,得到物体人脸二值掩膜图像。s3、采用物体人脸二值掩膜图像对orb视觉特征点进行滤波处理,得到静态场景特征点图像;步骤s3为:根据物体人脸二值掩膜图像,将orb视觉特征点的每一个特征点对应的物体人脸二值掩膜图像的值为1的位置剔除,得到静态场景特征点图像。s4、计算一幅静态场景特征点图像中的每一个特征点的描述子分别与另一幅静态场景特征点图像中所有特征点的描述子的汉明距离,得到多个特征点对;步骤s4包括以下分步骤:s41、计算一幅静态场景特征点图像中的每一个特征点的描述子分别与另一幅静态场景特征点图像中所有特征点的描述子的汉明距离;s42、寻找最小的汉明距离小于次小的汉明距离的60%以及最小的汉明距离小于汉明阈值的多对描述子;在本实施例中,汉明阈值可设置是为45。s43、将多对描述子各自在两幅静态场景特征点图像上的特征点作为特征点对。s5、根据特征点对,构建运动结构恢复模型,得到入射光线汇聚点;步骤s5包括以下分步骤:s51、根据每一个特征点对,通过相机内参,得到特征点对的入射光线;s52、根据特征点对的入射光线,构建运动结构恢复模型,采用svd算法对运动结构恢复模型进行求解,得到入射光线汇聚点。步骤s5中运动结构恢复模型为:x=k-1px′=k-1p′xt(t×r)x′=0p=[rt]x×px=0x=λx′其中,x为一幅静态场景特征点图像的入射光线的向量,x′为另一幅静态场景特征点图像的入射光线的向量,k为相机内参,p为一幅静态场景特征点图像上的特征点,p′为另一幅静态场景特征点图像上的特征点,t为两个相机之间的位移,r为相机之间的旋转角度矩阵,λ为入射因子,p为构建的相机旋转位移矩阵,x为入射光线汇聚点的坐标。s6、将入射光线汇聚点投影至两幅静态场景特征点图像,构建误差模型,得到相机位姿,实现视觉定位。在本实施例中,可采用lm算法迭代求解误差模型。步骤s6中误差模型为:其中,p1为入射光线汇聚点在一幅静态场景特征点图像的位置,p2为入射光线汇聚点在另一幅静态场景特征点图像的位置,x为入射光线汇聚点的坐标,k为相机内参,x为一幅静态场景特征点图像的入射光线的向量,x′为另一幅静态场景特征点图像的入射光线的向量,err为误差值。实验效果:由于视觉定位需要实时的图像信息,同时保证物体识别与人脸识别的准确度,在具体方案实施过程中物体识别的主要技术参数为map和iou,而人脸识别的主要技术参数为人脸的识别率以及识别速度。而视觉定位模块的主要参数为均方根误差rmse,以及标准差std。物体识别与人脸识别模块以及室内定位模块部分的实验测试数据如下表:表1物体框的实验测试数据技术指标mapiou研究数据82.29%70%表2人脸像素框的实验测试数据表3动态场景视觉定位的实验测试数据根据表3可知,采用本方法对各图像集进行处理,其均方根误差rmse和标准差std均小于现有方法orbslam2,证明本方法的定位效果好。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1