实体识别方法和系统与流程
[0001]
本申请涉及机器学习模型训练的技术,更具体地讲,涉及一种实体识别 方法和系统。
背景技术:
[0002]
命名实体识别(named entity recognition,ner)是一项基础而又重要 的自然语言处理(natural language processing,nlp)中的词法分析任务,也 往往作为信息抽取、问答系统、机器翻译等方向或显式或隐式的基础任务。
[0003]
针对目标领域的实体识别任务,需要基于该目标领域的训练语料训练特 定的实体识别模型。当目标领域的训练语料较少时,训练出的实体识别模型 的精确度难以达到预期;从无到有地训练出针对目标领域的实体识别模型需 要耗费大量的成本,实施过程比较困难,而且训练出的实体识别模型的识别 效果无法预估,若识别效果无法满足期望,会导致成本的浪费。
技术实现要素:
[0004]
本公开的示例性实施例可至少解决上述问题,也可不解决上述问题。
[0005]
在一个方面,提供了一种实体识别方法,包括:获取第一实体识别模型, 其中,第一实体识别模型是基于目标领域之外的领域的实体识别训练数据预 先训练好的、且第一实体识别模型包括语义理解层、映射层、序列标注层, 映射层包括至少一个子映射层;对第一实体识别模型的映射层进行重构,得 到第二实体识别模型;基于目标领域的实体识别训练数据训练第二实体识别 模型;利用训练好的第二实体识别模型对目标领域的文本进行实体识别,输 出实体识别结果。
[0006]
可选地,对第一实体识别模型的映射层进行重构的步骤包括:调整映射 层中每个子映射层的权重和结构。
[0007]
可选地,调整映射层中每个子映射层的权重和结构的步骤包括:将映射 层中每个子映射层的权重进行初始化。
[0008]
可选地,对第一实体识别模型的映射层进行重构的步骤还包括:调整映 射层中每个子映射层的隐藏单元的数量。
[0009]
可选地,对第一实体识别模型的映射层进行重构的步骤还包括:在映射 层中,在原有子映射层的基础上新增至少一个子映射层。
[0010]
可选地,目标领域之外的领域的实体识别训练数据,是通过将目标领域 之外的至少一个领域的实体识别训练数据融合后得到的;该方法还包括:当 同一种实体的类型在不同领域的表述方式不一致时,将同一种实体的类型进 行归一处理。
[0011]
可选地,训练第一实体识别模型所使用的实体识别训练数据的数量,大 于训练第二实体识别模型所使用的实体识别训练数据的数量。
[0012]
在另一个方面,提供了一种实体识别系统,实体识别系统包括第一模型 获取模
块、第二模型获取模块、模型训练模块和实体识别模块;
[0013]
第一模型获取模块被配置为:获取第一实体识别模型,其中,第一实体 识别模型是基于目标领域之外的领域的实体识别训练数据预先训练好的、且 第一实体识别模型包括语义理解层、映射层、序列标注层,映射层包括至少 一个子映射层;第二模型获取模块被配置为:对第一实体识别模型的映射层 进行重构,得到第二实体识别模型;模型训练模块被配置为:基于目标领域 的实体识别训练数据训练第二实体识别模型;实体识别模块被配置为:利用 训练好的第二实体识别模型对目标领域的文本进行实体识别,输出实体识别 结果。
[0014]
可选地,第二模型获取模块被配置为:调整映射层中每个子映射层的权 重和结构。
[0015]
可选地,第二模型获取模块被配置为:将映射层中每个子映射层的权重 进行初始化。
[0016]
可选地,第二模型获取模块被配置为:调整映射层中每个子映射层的隐 藏单元的数量。
[0017]
可选地,第二模型获取模块被配置为:在映射层中,在原有子映射层的 基础上新增至少一个子映射层。
[0018]
可选地,目标领域之外的领域的实体识别训练数据,是通过将目标领域 之外的至少一个领域的实体识别训练数据融合后得到的;第一模型获取模块 被配置为:当同一种实体的类型在不同领域的表述方式不一致时,将同一种 实体的类型进行归一处理。
[0019]
可选地,训练第一实体识别模型所使用的实体识别训练数据的数量,大 于训练第二实体识别模型所使用的实体识别训练数据的数量。
[0020]
在另一个方面,提供了一种存储指令的计算机可读存储介质,其中,当 指令被至少一个计算装置运行时,促使至少一个计算装置执行上述的实体识 别方法。
[0021]
在另一个方面,提供了一种包括至少一个计算装置和存储有至少一个存 储指令的存储装置的系统,其中,指令在被至少一个计算装置运行时,促使 至少一个计算装置执行上述的实体识别方法。
[0022]
根据本发明示例性实施例提供的实体识别方法和系统,对于基于目标领 域之外的领域的实体识别数据预先训练好的第一实体识别模型的映射层重构, 得到初始的第二实体识别模型,以目标领域少量的训练数据来初始的第二实 体识别模型,训练后的第二实体识别模型即可应用于目标领域的实体识别业 务,且能够达到较高的精确度。上述针对目标领域的模型训练过程,可以基 于较少的训练语料,较快的得到具有期望精确度的实体识别模型,可以显著 地简化训练过程,降低成本。
附图说明
[0023]
通过结合附图,从实施例的下面描述中,本发明这些和/或其它方面及优 点将会变得清楚,并且更易于理解,其中:
[0024]
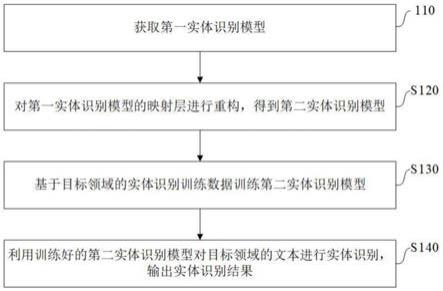
图1示出了本发明示例性实施例提供的实体识别方法的流程图。
[0025]
图2示出了本发明示例性实施例提供的实体识别系统的框图。
具体实施方式
[0026]
提供参照附图的以下描述以帮助对由权利要求及其等同物限定的本发明 的实施例的全面理解。包括各种特定细节以帮助理解,但这些细节仅被视为 是示例性的。因此,本领域的普通技术人员将认识到在不脱离本发明的范围 和精神的情况下,可对描述于此的实施例进行各种改变和修改。此外,为了 清楚和简洁,省略对公知的功能和结构的描述。
[0027]
在此需要说明的是,在本公开中出现的“若干项之中的至少一项”均表示 包含“该若干项中的任意一项”、“该若干项中的任意多项的组合”、“该若干项 的全体”这三类并列的情况。例如“包括a和b之中的至少一个”即包括如下 三种并列的情况:(1)包括a;(2)包括b;(3)包括a和b。又例如“执行 步骤一和步骤二之中的至少一个”,即表示如下三种并列的情况:(1)执行步 骤一;(2)执行步骤二;(3)执行步骤一和步骤二。
[0028]
本发明示例性实施例提供的第一实体识别模型和第二实体识别模型均为 机器学习模型。这里,机器学习是人工智能研究发展到一定阶段的必然产物, 其致力于通过计算的手段,利用经验来改善系统自身的性能。在计算机系统 中,“经验”通常以“数据”形式存在,通过机器学习算法,可从数据中产生“模 型”,也就是说,将经验数据提供给机器学习算法,就能基于这些经验数据产 生模型,在面对新的情况时,模型会提供相应的判断,即,预测结果。不论 是训练机器学习模型,还是利用训练好的机器学习模型进行预测,数据都需 要转换为包括各种特征的机器学习样本。机器学习可被实现为“有监督学习”、
ꢀ“
无监督学习”或“半监督学习”的形式,应注意,本发明的示例性实施例对具 体的机器学习算法并不进行特定限制。此外,还应注意,在训练和应用模型 的过程中,还可结合统计算法等其他手段。
[0029]
在本发明的示例性实施例中,第一实体识别模型可以对目标领域以外的 领域的文本进行实体识别,第二实体识别模型可以对目标领域的文本进行实 体识别,其中,第二实体识别模型是基于预先训练好的第一实体识别模型经 过重构和重新训练后得到的。下面介绍本发明示例性实施例提供的实体识别 方法的流程,该流程包括获得第二实体识别模型的过程、以及利用训练好的 第二实体识别模型对目标领域的文本进行实体识别的过程。
[0030]
图1示出了本发明示例性实施例提供的实体识别方法的流程图。
[0031]
参见图1,在步骤s110,获取第一实体识别模型。
[0032]
这里,第一实体识别模型是基于目标领域之外的领域的实体识别训练数 据预先训练好的、且第一实体识别模型包括语义理解层、映射层、序列标注 层,映射层包括至少一个子映射层。
[0033]
可选地,第一实体识别模型可以是基于目标领域之外的一个领域的实体 识别训练数据预先训练好的,也可以是基于目标领域之外的多个领域的实体 识别训练数据预先训练好的。第一实体识别模型具体的训练过程将在后续内 容中做示例性的介绍,应当理解,该第一实体识别模型能够对其实体识别训 练数据所属领域的文本进行实体识别,且可以达到期望的准确率。
[0034]
作为示例,目标领域为科技领域,第一实体识别模型可以是基于影视领 域的实体识别训练数据预先训练好的,并且该第一实体识别模型能够对影视 领域的文本进行实体识别,且可以达到期望的准确率。
[0035]
可选地,语义理解层的类型可以包括bert(bidirectional encoderrepresentations from transformers)模型、mass(masked sequence to sequencepre-training)模型、mt-dnn(multi-task deep neural networks)模型和 unilm(unified pre-trained language model)模型等,但不限于此,第一实 体识别模型中所应用的语义理解层的类型可以根据实际的需要而定。
[0036]
可选地,映射层可以包括一个子映射层,也可以包括多个子映射层。子 映射层的类型可以包括linear层、lstm(long short-term memory)层、rnn (recurrent neural network)层和transform层。映射层所包括的子映射层的 数量和类型可以根据实际的需要而定。
[0037]
可选地,序列标注层的类型可以包括crf(conditional random field) 模型、hmm(hidden markov model)和memm(maximum entropy markovmodel)等,但不限于此,第一实体识别模型中所应用的序列标注层的类型可 以根据实际的需要而定。
[0038]
应当理解,第一实体识别模型可以是上述任一类型的语义理解层、映射 层和序列标注层的组合。例如,第一实体识别模型的结构可以包括以下的形 式:bert+linear+crf、mass+linear+crf、bert+linear+hmm、 bert+linear+linear+crf、bert+linear+lstm+crf、mass+linear+lstm+crf、 bert+linear+lstm+memm。当然,第一实体识别模型的结构形式不限于此。
[0039]
在步骤s120,对第一实体识别模型的映射层进行重构,得到第二实体识 别模型。
[0040]
可选地,对映射层进行重构可以包括对映射层的子映射层的某个参数进 行调整、对映射层中的子映射层的数量进行调整,但重构的方式不限于此。
[0041]
在此需要说明的是,执行步骤s120是,第一实体识别模型中的语义理解 层和序列标注层的是不变的,例如,语义理解层和序列标注层的权重不变。
[0042]
在步骤s130,基于目标领域的实体识别训练数据训练第二实体识别模型。
[0043]
可以理解,第二实体识别模型的训练过程与第一实体识别模型的训练过 程基本一致,第二实体识别模型具体的训练过程可以参考后续内容中介绍的 第一实体识别模型的训练过程。
[0044]
在此需要说明的是,训练第一实体识别模型所使用的实体识别训练数据 的数量,大于训练第二实体识别模型所使用的实体识别训练数据的数量。具 体来说,在能够达到相近或相同的准确率的情况下,训练第二实体识别模型 所使用的目标领域的实体识别训练数据的数量,可以小于训练第一实体识别 模型所使用的目标领域之外的领域的实体识别训练数据的数量。
[0045]
在步骤s140,利用训练好的第二实体识别模型对目标领域的文本进行实 体识别,输出实体识别结果。
[0046]
在第二实体识别模型训练完成之后,可以将目标领域的文本输入到第二 实体识别模型,第二实体识别模型可以对目标领域的文本进行实体识别并输 出实体识别结果。可选地,实体识别结果可以包括文本中至少一个实体在文 本中的位置、该实体的类型和该实体的内容之中的至少一项。
[0047]
根据本发明示例性实施例提供的实体识别方法,对于基于目标领域之外 的领域的实体识别数据预先训练好的第一实体识别模型的映射层重构,得到 初始的第二实体识
别模型,以目标领域少量的训练数据来初始的第二实体识 别模型,训练后的第二实体识别模型即可应用于目标领域的实体识别业务, 且能够达到较高的精确度。上述针对目标领域的模型训练过程,可以基于较 少的训练语料,较快的得到具有期望精确度的实体识别模型,可以显著地简 化训练过程,降低成本。
[0048]
可选地,步骤s120的对第一实体识别模型的映射层进行重构的步骤包括: 调整映射层中每个子映射层的权重和结构。
[0049]
作为示例,可以对映射层中各个子映射层的权重按照相同的方式进行调 整。例如,调整映射层中每个子映射层的权重的步骤包括:将映射层中每个 子映射层的权重进行初始化、或者将映射层中每个子映射层的权重按照预设 的比例进行缩放,但不限于此。
[0050]
作为示例,可以对映射层中各个子映射层的权重分别按照不同的方式进 行调整。例如,调整映射层中每个子映射层的权重的步骤包括:将映射层中 一部分子映射层的权重进行初始化,将映射层中另一部分子映射层的权重按 照预设的比例进行缩放,但不限于此。
[0051]
可选地,子映射层包括至少一个隐藏单元。作为示例,可以通过调整子 映射层中隐藏单元的数量的方式来调整子映射层的结构,其中,子映射层中 隐藏单元的数量可以根据训练第二实体识别模型所使用的实体识别训练数据 的数量而定。
[0052]
可选地,步骤s120的对第一实体识别模型的映射层进行重构的步骤还可 以包括:在映射层中,在原有子映射层的基础上新增至少一个子映射层。
[0053]
应当理解,新增的子映射层是权重调整后的子映射层。新增的子映射层 的数量可以根据实际需要而定,可以在原有子映射层的基础上新增一个子映 射层,也可以在原有子映射层的基础上新增多个子映射层。
[0054]
可选地,原有子映射层包括一个类型的子映射层,新增的子映射层的类 型与原有子映射层的类型相同。
[0055]
例如,原有子映射层仅包括linear,每个新增的子映射层的为权重调整后 的linear。
[0056]
作为示例,第一实体识别模型的结构形式为bert+linear+crf,将linear 的权重初始化之后,新增加一个权重初始化后的linear,第二实体识别模型的 结构形式bert+linear+linear+crf。
[0057]
可选地,原有子映射层包括两个以上的不同类型的子映射层,每个新增 的子映射层类型属于原有子映射层的类型集合。可以理解,每个新增的子映 射层类型可以是原有子映射层的类型中的任意一种。
[0058]
例如,原有子映射层包括linear和lstm,新增的子映射层的类型可以包 括权重调整后的linear和权重调整后的lstm之中至少一个。
[0059]
作为示例,第一实体识别模型的结构形式为bert+linear+lstm+crf,将 linear和lstm重初始化之后,新增加一个权重初始化后的linear,第二实体识 别模型的结构形式bert+linear+linear+lstm+crf,或者新增加一个权重初始化 后的linear和一个权重初始化后的lstm,第二实体识别模型的结构形式为 bert+linear+linear+lstm+lstm+crf。
[0060]
下面对第一实体识别模型具体的训练过程做示例性的介绍。
[0061]
为了便于表述,将目标领域之外的领域称为参照领域。训练第一实体识 别模型所
使用的目标领域之外的领域的实体识别训练数据,为了获得训练第 一实体识别模型的实体识别训练数据,首先对参照领域的每条语料中的内容 进行数字化转换。
[0062]
以参照领域为影视领域的为例,该影视领域的一条语料包括:{"text":" 如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困 潦倒之中的独门秘笈","entity_list":[{"entity_index":{"begin":21,"end":25}, "entity_type":"影视作品","entity":"喜剧之王"},{"entity_index":{"begin":26, "end":29},"entity_type":"人物","entity":"周星驰"}]}。
[0063]
在上述语料中,text为文本内容,entity_list为一个列表,该列表用以保 存文本中所有标注的实体的信息。一个实体的信息包括实体在文本中的位置 (entity_index)、实体类型(entity_type)和实体内容(entity)。
[0064]
如前文所示,第一实体识别模型是基于目标领域之外的领域的实体识别 训练数据预先训练好的,因此,目标领域之外的领域的实体识别训练数据, 可以是通过将目标领域之外的至少一个领域的实体识别训练数据融合后得到 的。当同一种实体的类型在不同领域的表述方式不一致时,将同一种实体的 类型进行归一处理。例如,对于文本中的人名,在不同领域的类型可以分别 被表述为“人物”、“人名”和“person name”,可以将文本中的人名的类型统 一规定为“person name”。
[0065]
实体识别训练数据包括文本输入和标签输入,其中文本为语料中的文本 内容,标签为语料中的实体。
[0066]
对语料中的文本内容进行数字化转换得到文本输入。具体地,在文本的 开始位置加上[cls],在文本的结尾位置加上[sep],文本内容变为变成“[cls] 如何演好自己的角色,请读《演员自我修养》《喜剧之王》周星驰崛起于穷困 潦倒之中的独门秘笈[sep]”。然后基于词表,将文本内容转换数字,例如“如
”ꢀ
这个字在词表中的第1064行,那么就会把“如”这个字映射成1064。上述 文本内容可以基于词表转换成为[101,1964,863,4029,1963,5633,2347,4639, 6236,5683,8025,6436,6439,518,4029,1448,5633,2770,935,1076,519,518, 1600,1197,723,4375,519,1454,3216,7721,2308,6630,755,4957,1738,4058, 949,723,705,4639,4325,7306,4909,5008,102]。
[0067]
对语料中的实体进行数字化转换得到标签输入。标签输入采用b(begin) e(end)i(inter)o(other)格式进行处理,具体地,将“喜剧之王”这一实体转换 为序列[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,2,2,3,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],将“周星驰”这一实体转换为序列[0,0, 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,2,3,0,0,0,0,0,0,0, 0,0,0,0,0,0,0,0,0,0]。
[0068]
在上述序列中,1代表begin,表示实体内容的开始部分;3代表end, 表示实体的结束部分;2代表inter,表示实体的开始和结束之间的部分;0 代表other,表示文本中除了当前实体内容之外的其它内容。例如,上述的第 一个序列中的“1”,“2”,“2”,“3”,分别代表“喜”,“剧”,“之”,“王”。 第一个序列中的“0”代表文本中除了“喜剧之王”之外的其它内容。
[0069]
可以将上述得到的文本输入和标签输入作为第一实体识别模型的实体识 别训练数据。在进行模型训练时,训练程序可以将所有的实体识别训练数据 按照预设比例(如9:1)切分为训练集和测试集,利用训练集对第一实体识别 模型进行训练,利用测试集测试第一实体识别模型的准确率。另外,可以根 据需要设置相关的训练参数,例如,将文本中句子
最大长度设置为128,学 习率设置为0.00001。
[0070]
在得到训练好的第一实体识别模型,对第一实体识别模型的映射层进行 重构。作为示例,第一实体识别模型的结构形式为bert+linear+crf,在得到 训练好的第一实体识别模型之后,将第一实体识别模型中的linear替换为 linear+linear,linear+linear中的每个linear的权重和结构均已做调整,第二实 体识别模型的结构形式为bert+linear+linear+crf。
[0071]
在得到结构形式为bert+linear+linear+crf的第二实体识别模型之后,再 基于目标领域的实体识别训练数据训练第二实体识别模型。
[0072]
可以理解,第二实体识别模型的训练过程与第一实体识别模型的训练过 程基本一致,此处不再赘述。两个模型训练过程的区别在于,训练第一实体 识别模型所使用的实体识别训练数据的数量,大于训练第二实体识别模型所 使用的实体识别训练数据的数量。作为示例,使用10000条语料的实体识别 训练数据来训练第一实体识别模型,使用几十条语料(例如20条)的实体识 别训练数据来训练第二实体识别模型。
[0073]
在第二实体识别模型训练完成之后,利用训练好的第二实体识别模型对 目标领域的文本进行实体识别,输出实体识别结果。
[0074]
具体地,将目标领域的文本输入到训练好的第二实体识别模型,第二实 体识别模型可以对目标领域的文本进行实体识别并输出实体识别结果。以目 标领域为科技领域为例,输入的科技领域的文本如下:{"text":“chomp创建 于2010年,最初仅针对苹果app store商店开展业务,2011年又将其服务范 围延伸至谷歌android平台。techcrunch称,chomp此前已获得250万美 元资金援助,其天使投资人包括罗恩
·
康维(ron conway)等。美国社交新闻网 站digg创始人凯文
·
罗斯(kevin rose)、美国演员阿什顿
·
库彻(ashton kutcher) 等人为chomp顾问。chomp目前员工量为20名左右,这些员工都将加盟苹 果。对于苹果已收购chomp的报道,chomp拒加置评,苹果亦尚未就此发表 评论。(来源:腾讯科技文:中涛)”}。
[0075]
输出的实体识别结果如下:{"text":"chomp创建于2010年,最初仅针对 苹果app store商店开展业务,2011年又将其服务范围延伸至谷歌android 平台。techcrunch称,chomp此前已获得250万美元资金援助,其天使投资 人包括罗恩
·
康维(ron conway)等。美国社交新闻网站digg创始人凯文
·
罗斯 (kevin rose)、美国演员阿什顿
·
库彻(ashton kutcher)等人为chomp顾问。 chomp目前员工量为20名左右,这些员工都将加盟苹果。对于苹果已收购 chomp的报道,chomp拒加置评,苹果亦尚未就此发表评论。(来源:腾讯 科技文:中涛)\n","entity_list":[{"entity_index":{"begin":0,"end":5}, "entity_type":"company_name","entity":"chomp"},{"entity_index":{"begin": 8,"end":13},"entity_type":"time","entity":"2010年"},{"entity_index": {"begin":19,"end":30},"entity_type":"product_name","entity":"苹果appstore"},{"entity_index":{"begin":37,"end":42},"entity_type":"time","entity": "2011年"},{"entity_index":{"begin":53,"end":63},"entity_type": "product_name","entity":"谷歌android"},{"entity_index":{"begin":66,"end": 76},"entity_type":"person_name","entity":"techcrunch"},{"entity_index": {"begin":78,"end":83},"entity_type":"product_name","entity":"chomp"}, {"entity_index":{"begin":107,"end":
112},"entity_type":"person_name", "entity":"罗恩
·
康维"},{"entity_index":{"begin":113,"end":123}, "entity_type":"person_name","entity":"ron conway"},{"entity_index": {"begin":126,"end":128},"entity_type":"location","entity":"美国"}, {"entity_index":{"begin":134,"end":138},"entity_type":"product_name", "entity":"digg"},{"entity_index":{"begin":141,"end":146},"entity_type": "person_name","entity":"凯文
·
罗斯"},{"entity_index":{"begin":147,"end": 157},"entity_type":"person_name","entity":"kevin rose"},{"entity_index": {"begin":159,"end":161},"entity_type":"location","entity":"美国"}, {"entity_index":{"begin":163,"end":169},"entity_type":"person_name", "entity":"阿什顿
·
库彻"},{"entity_index":{"begin":170,"end":184}, "entity_type":"person_name","entity":"ashton kutcher"},{"entity_index": {"begin":188,"end":193},"entity_type":"company_name","entity":"chomp"}, {"entity_index":{"begin":196,"end":201},"entity_type":"company_name", "entity":"chomp"},{"entity_index":{"begin":221,"end":223},"entity_type": "company_name","entity":"苹果"},{"entity_index":{"begin":226,"end":228}, "entity_type":"company_name","entity":"苹果"},{"entity_index":{"begin": 231,"end":236},"entity_type":"company_name","entity":"chomp"}, {"entity_index":{"begin":240,"end":245},"entity_type":"company_name", "entity":"chomp"},{"entity_index":{"begin":250,"end":252},"entity_type": "company_name","entity":"苹果"},{"entity_index":{"begin":266,"end":270}, "entity_type":"product_name","entity":"腾讯科技"},{"entity_index":{"begin": 273,"end":275},"entity_type":"person_name","entity":"中涛"}]}。
[0076]
在上述输出结果中,text为文本内容,entity_list为一个列表,该列表用 以保存文本中所有标注的实体的信息。一个实体的信息包括实体在文本中的 位置(entity_index)、实体类型(entity_type)和实体内容(entity)。
[0077]
以{"entity_index":{"begin":19,"end":30},"entity_type":"product_name", "entity":"苹果app store"}这一实体信息为例,该实体在文本中的位置为第19 至第30个字节,该实体的类型为product_name(产品名称),该实体的内容 为“苹果app store”。
[0078]
为了测试本发明提供的第二实体识别模型的性能,本申请的发明人对第 二实体识别模型和第三实体识别模型进行了对比试验,其中,第二实体识别 模型是基于第一识别模型得到的(即,对第一实体识别模型的映射层进行重 构后得到第二实体识别模型),第三实体识别模型为基于常规的模型构造方法 得到的。
[0079][0080][0081]
表1
[0082]
利用相同来源的相同数量(如20条)的实体识别训练数据对第二实体识 别模型和第三实体识别模型进行训练,计算两个模型的f1分数(f1-score), 两个模型的f1分数情况参照表1。需要说明的是,f1分数是分类问题的一个 衡量指标,它是精确率和召回率的调和平均数,f1分数最大为1,f1分数最 小为0。f1分数越大,说明机器学习模型的精确率和召回率越高。
[0083]
在表1中可以看出,在使用20条实体识别训练数据对第二识别模型和第 三识别模型进行训练的情况下,第二识别模型在每个领域都能够获得较高的 f1分数,并且,在同一领域下第二识别模型的f1分数均高于第三识别模型 的f1分数。
[0084]
图2示出了本发明示例性实施例提供的实体识别系统的框图。
[0085]
参照图2,实体识别系统包括第一模型获取模块、第二模型获取模块、 模型训练模块和实体识别模块。
[0086]
第一模型获取模块被配置为:获取第一实体识别模型,其中,第一实体 识别模型是基于目标领域之外的领域的实体识别训练数据预先训练好的、且 第一实体识别模型包括语义理解层、映射层、序列标注层,映射层包括至少 一个子映射层。
[0087]
第二模型获取模块被配置为:对第一实体识别模型的映射层进行重构, 得到第二实体识别模型。
[0088]
模型训练模块被配置为:基于目标领域的实体识别训练数据训练第二实 体识别模型。
[0089]
实体识别模块被配置为:利用训练好的第二实体识别模型对目标领域的 文本进行实体识别,输出实体识别结果。
[0090]
可选地,第二模型获取模块被配置为:调整映射层中每个子映射层的权 重和结构。
[0091]
可选地,第二模型获取模块被配置为:将映射层中每个子映射层的权重 进行初始化。
[0092]
可选地,第二模型获取模块被配置为:调整映射层中每个子映射层的隐 藏单元的
数量。
[0093]
可选地,第二模型获取模块被配置为:在映射层中,在原有子映射层的 基础上新增至少一个子映射层。
[0094]
可选地,原有子映射层包括两个以上的不同类型的子映射层;每个新增 的子映射层类型属于原有子映射层的类型集合。
[0095]
可选地,目标领域之外的领域的实体识别训练数据,是通过将目标领域 之外的至少一个领域的实体识别训练数据融合后得到的;第一模型获取模块 被配置为:当同一种实体的类型在不同领域的表述方式不一致时,将同一种 实体的类型进行归一处理。
[0096]
可选地,训练第一实体识别模型所使用的实体识别训练数据的数量,大 于训练第二实体识别模型所使用的实体识别训练数据的数量。
[0097]
以上已参照图1至图2描述了根据本公开示例性实施例的实体识别方法 和系统。
[0098]
根据本发明示例性实施例提供的实体识别方法和系统,对于基于目标领 域之外的领域的实体识别数据预先训练好的第一实体识别模型的映射层重构, 得到初始的第二实体识别模型,以目标领域少量的训练数据来初始的第二实 体识别模型,训练后的第二实体识别模型即可应用于目标领域的实体识别业 务,且能够达到较高的精确度。上述针对目标领域的模型训练过程,可以基 于较少的训练语料,较快的得到具有期望精确度的实体识别模型,可以显著 地简化训练过程,降低成本。
[0099]
图2所示出的实体识别系统中的各个单元可被配置为执行特定功能的软 件、硬件、固件或上述项的任意组合。例如,各个单元可对应于专用的集成 电路,也可对应于纯粹的软件代码,还可对应于软件与硬件相结合的模块。 此外,各个单元所实现的一个或多个功能也可由物理实体设备(例如,处理 器、客户端或服务器等)中的组件来统一执行。
[0100]
此外,参照图1所描述的实体识别方法可通过记录在计算机可读存储介 质上的程序(或指令)来实现。例如,根据本公开的示例性实施例,可提供 存储指令的计算机可读存储介质,其中,当所述指令被至少一个计算装置运 行时,促使所述至少一个计算装置执行根据本公开的实体识别方法。
[0101]
上述计算机可读存储介质中的计算机程序可在诸如客户端、主机、代理 装置、服务器等计算机设备中部署的环境中运行,应注意,计算机程序还可 用于执行除了上述步骤以外的附加步骤或者在执行上述步骤时执行更为具体 的处理,这些附加步骤和进一步处理的内容已经在参照图1进行相关方法的 描述过程中提及,因此这里为了避免重复将不再进行赘述。
[0102]
应注意,根据本公开示例性实施例的实体识别系统中的各个单元可完全 依赖计算机程序的运行来实现相应的功能,即,各个单元在计算机程序的功 能架构中与各步骤相应,使得整个系统通过专门的软件包(例如,lib库)而 被调用,以实现相应的功能。
[0103]
另一方面,图2所示的各个单元也可以通过硬件、软件、固件、中间件、 微代码或其任意组合来实现。当以软件、固件、中间件或微代码实现时,用 于执行相应操作的程序代码或者代码段可以存储在诸如存储介质的计算机可 读介质中,使得处理器可通过读取并运行相应的程序代码或者代码段来执行 相应的操作。
[0104]
例如,本公开的示例性实施例还可以实现为计算装置,该计算装置包括 存储部件和处理器,存储部件中存储有计算机可执行指令集合,当计算机可 执行指令集合被处理器
执行时,执行根据本公开的示例性实施例的实体识别 方法。
[0105]
具体说来,计算装置可以部署在服务器或客户端中,也可以部署在分布 式网络环境中的节点装置上。此外,计算装置可以是pc计算机、平板装置、 个人数字助理、智能手机、web应用或其他能够执行上述指令集合的装置。
[0106]
这里,计算装置并非必须是单个的计算装置,还可以是任何能够单独或 联合执行上述指令(或指令集)的装置或电路的集合体。计算装置还可以是 集成控制系统或系统管理器的一部分,或者可被配置为与本地或远程(例如, 经由无线传输)以接口互联的便携式电子装置。
[0107]
在计算装置中,处理器可包括中央处理器(cpu)、图形处理器(gpu)、 可编程逻辑装置、专用处理器系统、微控制器或微处理器。作为示例而非限 制,处理器还可包括模拟处理器、数字处理器、微处理器、多核处理器、处 理器阵列、网络处理器等。
[0108]
根据本公开示例性实施例的实体识别方法中所描述的某些操作可通过软 件方式来实现,某些操作可通过硬件方式来实现,此外,还可通过软硬件结 合的方式来实现这些操作。
[0109]
处理器可运行存储在存储部件之一中的指令或代码,其中,存储部件还 可以存储数据。指令和数据还可经由网络接口装置而通过网络被发送和接收, 其中,网络接口装置可采用任何已知的传输协议。
[0110]
存储部件可与处理器集成为一体,例如,将ram或闪存布置在集成电 路微处理器等之内。此外,存储部件可包括独立的装置,诸如,外部盘驱动、 存储阵列或任何数据库系统可使用的其他存储装置。存储部件和处理器可在 操作上进行耦合,或者可例如通过i/o端口、网络连接等互相通信,使得处 理器能够读取存储在存储部件中的文件。
[0111]
此外,计算装置还可包括视频显示器(诸如,液晶显示器)和用户交互 接口(诸如,键盘、鼠标、触摸输入装置等)。计算装置的所有组件可经由总 线和/或网络而彼此连接。
[0112]
根据本公开示例性实施例的实体识别方法可被描述为各种互联或耦合的 功能块或功能示图。然而,这些功能块或功能示图可被均等地集成为单个的 逻辑装置或按照非确切的边界进行操作。
[0113]
因此,参照图1所描述的实体识别方法可通过包括至少一个计算装置和 至少一个存储指令的存储装置的系统来实现。
[0114]
根据本公开的示例性实施例,至少一个计算装置是根据本公开示例性实 施例的用于执行实体识别方法的计算装置,存储装置中存储有计算机可执行 指令集合,当计算机可执行指令集合被至少一个计算装置执行时,执行参照 图1所描述的实体识别方法。
[0115]
以上描述了本公开的各示例性实施例,应理解,上述描述仅是示例性的, 并非穷尽性的,本公开不限于所披露的各示例性实施例。在不偏离本公开的 范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更 都是显而易见的。因此,本公开的保护范围应该以权利要求的范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1