基于随机森林的铸坯裂纹智能预测方法
1.本发明涉及连铸生产过程控制领域,尤其涉及一种基于随机森林的铸坯裂纹智能预测方法。
背景技术:
2.裂纹是连铸坯主要质量问题之一,在各类缺陷中裂纹约占50%。连铸过程铸坯发生相转变、碳氮化物在晶界的析出行为、不同组织间的性能差异是裂纹形成的根本原因。轻微的裂纹经精整后对后续工序不会产生影响,严重的裂纹会导致铸坯判废,甚至漏钢。连铸生产技术暂时不能彻底消除裂纹缺陷,因此为了保证连续化生产,需要在铸坯流向下一工序之前,对存在裂纹的铸坯进行准确预测,进而及时将之分拣下线。
3.目前,有关铸坯裂纹的预测模型也出现了一些公开的专利文件,例如,名称为《连铸板坯表面纵裂纹在线预测的方法》(申请号:cn202010217692.0)文件中记载的方法:在结晶器壁面上设置多个温度检测点,且多个温度检测点呈矩形阵列形式排布,所述矩形阵列至少包括两行,每间隔设定时间对所述温度检测点的温度进行检测,根据温度检测点的温度对连铸板坯表面的纵裂纹进行在线预测。名称为《一种连铸坯裂纹风险预测的方法及其应用》(申请号:cn201911315780.8)文件中记载的方法:取拉应变作为中间裂纹萌生、表面裂纹扩展判定依据,以高温拉伸测定的临界裂纹准则和连铸从结晶器弯月面到空冷区结束的全流程热/力耦合模型为基础建立了裂纹风险预测模型。以上专利的局限在于:利用上述手段对铸坯裂纹进行预测时,都需要配备相应的检测设备,在实际应用中,这些设备不仅价格昂贵,而且日常维护工作也将增加生产成本。
4.名称为《一种板坯表面裂纹的预测方法及装置》(申请号:cn201910913079.x)文件中记载的方法:经过预处理之后的目标样本集使用皮尔逊系数,计算每个特征参数之间的线性关系,提取重要特征参数;结合冶金工艺规则,对每个特征参数进行线性组合,构造工艺特征参数,根据重要特征参数和工艺特征参数生成目标数据集;利用xgboost机器学习算法实现特征排序之后输出特征的重要性,保留重要性最高的n个特征;最后将其输入基于随机森林的裂纹预测模型。
5.本专利针对铸坯裂纹的预测问题,从钢厂实际生产数据中采集可能对铸坯裂纹有影响的变量因子,利用随机森林算法从上述变量中筛选出重要的影响变量,剔除冗余变量,实现对模型输入数据的降维,并在此基础上建立铸坯裂纹的预测模型。随机森林算法通过对评价每个变量在随机森林中的每棵树上所做的的贡献,然后取平均值作为每个变量的贡献,最后比较不同变量之间的贡献大小实现变量选择。它对异常值和噪声具有很好的容忍度,不容易出现过拟合,且在处理大规模数据时表现优异。
6.并且,随机森林对过拟合具有很强的鲁棒性,对于不平衡的数据集来说,它可以平衡误差,提高模型泛化能力。故而,针对这一特点,选用随机森林来构建铸坯裂纹的智能预测模型。
技术实现要素:
7.本发明的目的是提供一种铸坯裂纹智能预测方法,实现对铸坯裂纹更加精准的预测。
8.本发明的目的是通过以下技术方案实现的:
9.一种基于随机森林的铸坯裂纹智能预测方法,包括以下步骤:
10.步骤一、采集铸坯裂纹数据,并对数据进行预处理。
11.本专利收集对铸坯裂纹可能有影响的因素,并对上述采集到的数据进行必要的预处理:
12.1)剔除数据记录中的零值;
13.2)剔除数据记录中有缺失项数据的变量;
14.3)将剩余变量有空值的地方用该变量的均值填补;
15.4)按照炉号或者流号,对数据进行打标签处理。
16.步骤二、使用随机森林(random forest,英文简写是rf)算法对上述相关过程变量进行重要性排序。
17.(1)生成自生数据集dn:针对原始数据集,使用bootstrap重抽样方法进行有放回地随机数据抽取,形成与原始数据集大小相同的自生数据集dn。
18.(2)由dn生成分类树tn:设原始数据的自变量总个数为p,在每一颗树的每个节点处随机选取mtry个自变量(1≤mtry≤p)作为备选分枝变量,基于备选分枝变量选取最优分枝,采用cart算法生成一棵没有剪枝的分类树;
19.cart生成分类树算法如下:
20.在训练数据集的输入空间中,递归地将每个区域划分为两个子区域并决定每个子区域上的输出值,构建二叉决策树:
21.①
对每一个特征a,其可能取的每个值a,根据样本点对a=a的测试为“是”或“否”将d分割成d1和d2两部分,即:
22.d1={(x,y)|a(x)=a},d2=d-d1ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
23.则在特征a的条件下,集合d的基尼指数为:
[0024][0025][0026]
其中,ck是d中属于第k类的样本自己,k是类别个数。
[0027]
②
在所有可能的特征a以及其所有可能的切分点a中,选择基尼指数最小的特征及其对应的切分点作为最优特征与最优切分点。依此从现节点生成两个子节点,将训练数据集依特征分配到两个子节点中去。
[0028]
③
继续对两个子区域调用步骤
①②
,直到节点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值,或者没有更多特征。
[0029]
(3)利用基尼指数评价变量(参数)重要性
[0030]
将变量重要性评分(variable importance measures)用vim来表示,将基尼指数
用gi来表示,假设有c个特征x1,x2,
…
,xc,现在要计算出每个特征xj的基尼指数评分亦即第j个特征在rf所有决策树中节点分裂不纯度的平均改变量。具体过程如下:
[0031]
①
节点m的基尼指数,即从节点m中随机抽取两个样本,其类别标记不一致的概率为:
[0032][0033]
特征xj在节点m的重要性,即节点m分枝前后的基尼指数变化量为:
[0034][0035]
其中,gi
l
和gir分别表示分枝后两个新节点的基尼指数。
[0036]
②
如果特征xj在决策树i中出现的节点在集合m中,那么xj在第i颗树的重要性为:
[0037][0038]
假设rf中共有n颗树,那么:
[0039][0040]
③
把所有求得的重要性评分做一个归一化处理:
[0041][0042]
④
输出所有变量的重要性评分,然后按照重要性评分从大到小的顺序对所有变量进行排序。
[0043]
步骤三、构建随机森林分类模型。
[0044]
随机森林(random forest,rf)就是用随机的方式建立一个由众多决策树组成的森林,随机森林的每一棵决策树之间是没有关联的。rf的核心思想是组合众多决策树的预测结果,通过多数投票法(针对分类问题)得出最终的预测结果,如下图1所示。
[0045]
rf分类模型的输入为样本集d={(x1,y1),(x2,y2),...(xm,ym)},弱分类器迭代次数t;输出为最终的强分类器f(x),具体步骤如下:
[0046]
1)对于t=1,2...,t:
[0047]
a)对训练集进行第t次随机采样,共采集m次,得到包含m个样本的采样集d
t
[0048]
b)用采样集d
t
训练第t个决策树模型g
t
(x),在训练决策树模型的节点的时候,在节点上所有的样本特征中选择一部分样本特征,在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分
[0049]
2)对于分类算法预测,t个弱学习器投出最多票数的类别或者类别之一为最终类别。
[0050]
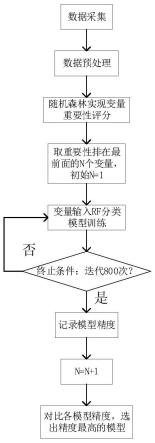
步骤四、逐步增加经随机森林筛选的重要性评分排在前面的相关变量,将这些变量输入到rf分类模型,筛选出使得rf分类模型精度最高的相关变量组合。
[0051]
例如重要性排序如:“var114”》“var113”》“var93”》
…
。那么先取“var114”这个重要性评分排在最前面的特征变量,将其输入到rf分类模型,并记录模型精度。接着增加“var114”、“var113”这两个重要性评分排在最前面的特征变量,将它们输入到rf分类模型,并记录模型精度。再接着增加重要性评分排在最前面的:3个特征变量、4个特征变量、
…
,并将其输入到rf分类模型,并记录模型精度。对比记录的模型精度,选出精度最高的模型,并将此模型的输入变量组合作为最终的输入变量组合。
[0052]
步骤五、模型在线应用
[0053]
利用正常工况下采集到的钢厂生产数据建立rf分类模型后,我们可以将其应用于铸坯裂纹智能预测。随机森林是一种由多个决策树组成的分类器,每一个非叶子节点是一个判断条件,每一个叶子节点是结论。从跟节点开始,经过多次判断得出结论,每一个决策树都是一个弱分类器。将采集的数据输入到rf分类模型后,可以实现对铸坯裂纹的智能预测。
[0054]
本发明的有益效果:
[0055]
针对连铸生产技术暂时不能彻底消除裂纹缺陷,为了保证连续化生产,需要在铸坯流向下一工序之前,对存在裂纹的铸坯进行准确预测的技术难题,提出了一种基于随机森林的铸坯裂纹智能预测方法。与现有的方法相比,本发明所提出的方法有效解决了变量过多而引入大量的噪声和冗余因子,影响模型精度的难题,并且能够对铸坯裂纹进行准确的预测。在对流号炉号都进行数据分析时,总分类精度可达到90.7%以上,在只对炉号进行分析时,总分类精度可达到59.4%以上。该方法主要围绕如何选取合适的过程变量,搭建rf分类模型来对铸坯裂纹数据智能预测,达到实现更加精准的预测的目的,有利于及时发现裂纹,避免更大的经济损失。具有较广泛的推广价值。
附图说明
[0056]
图1是随机森林算法原理图;
[0057]
图2是本发明中铸坯裂纹的智能预测方法的整体流程图;
[0058]
图3是按照流号打标签的数据处理图;
[0059]
图4是按照炉打标签的数据处理图。
具体实施方式
[0060]
下面以国内某大型钢厂的2637条连铸生产过程数据为例,结合附图和实施例对本发明作进一步的说明,铸坯裂纹的智能预测方法的整体流程如图2所示。
[0061]
实施例1
[0062]
具体步骤如下:
[0063]
1.对采集的数据进行数据预处理。
[0064]
在采集数据的时候,容易漏掉少许采集点上变量的值,统计每个变量的0值样本数,将0值样本数超过400的变量删除。接着统计每个变量的缺失值样本数,将缺失值样本数超过400的变量删除(标签变量除外)。如果不将这些数据剔除掉,那么这些数据将影响模型最终精度。所以,要将变量值为0以及缺失值的数据剔除掉,将剩余变量有空值的地方用该变量的均值填补。
[0065]
2.对流号炉号都进行数据分析,来对具体流号的铸坯裂纹数据进行异常检测。
[0066]
对于流号炉号都分析的情况,要将数据按照流号分成4类数据,针对1流数据,只看
var201,如果var201为0或null,则将该样本归为0标签类,表示该类样本没有角裂,其他的样本则归为1标签类,表示该类有角裂。针对2流数据,只看var202,处理方法与1流数据相同;针对3流数据,只看var203,处理方法与1流数据相同;针对4流数据,只看var204,处理方法与1流数据相同。处理完成后再将4个流的数据合并到一起组成数据集,如图3所示。
[0067]
3.基于实验数据集,使用随机森林计算各影响因素的重要性排序。
[0068]
设置基评估器的数量ntree=2000,使用随机森林模型获得相关变量的重要性排序如表1所示。
[0069]
表1铸坯裂纹相关变量的重要性评分
[0070][0071][0072]
4.逐步增加经随机森林筛选的重要性评分排在前面的相关变量,将变量组成新的训练集和测试集,重新训练rf分类模型和测试新的模型的精度,反复此过程,直至筛选出使
得rf分类模型精度最高的相关变量组合。具体过程如下:
[0073]
1)输入重要性评分排在最前面的m个变量,最开始令m=1,将变量组成的数据划分为训练集和测试集,按照训练集:测试集=7:3划分。
[0074]
2)将训练集放入rf分类模型训练,训练后用测试集测试模型精度,并保存模型精度,然后令m=m+1。
[0075]
3)重复步骤1)和2),若随着m的增加模型精度明显连续下降,则停止实验。
[0076]
4)比较所有模型的精度,筛选出精度最高的模型及其相关变量组合。
[0077]
输入重要性评分排在最前面的m个变量,随着m的变大,实验结果如下表2所示:
[0078]
表2 rf分类模型测试集精度变化
[0079][0080]
[0081]
针对相同的数据集,表3举了采用随机森林算法和xgboost方法进行特征筛选后的模型精度。可见,利用随机森林筛选变量后精度为0.907692,xgboost的为0.904895。
[0082]
表3分析流号时不同特征筛选方法结果对比
[0083][0084][0085]
实施例2:
[0086]
对炉号进行数据合并分析,来对某炉铸坯裂纹数据异常检测。
[0087]
这种情况下,按照炉号,将每个炉子的数据(炉号相同,流号不同)按照平均值合并成一条数据即可。然后将var205都为0的样本归为0标签类,表示该类样本没有角裂,其他的样本则归为1标签类,表示该类有角裂,如图4所示。
[0088]
模型结构与实施例1保持一致,在这种情况下,使用随机森林模型获得相关变量的重要性排序如表4所示。
[0089]
表4钢角裂相关变量的重要性评分
[0090]
[0091][0092]
rf分类模型测试集精度变化如表5所示。
[0093]
表5 rf分类模型测试集精度变化
[0094]
[0095][0096]
针对相同的数据集,表6举了采用随机森林算法和xg boost方法进行特征筛选后的模型精度。可见,利用随机森林筛选变量后精度为0.594595,xgboost的为0.583784。
[0097]
表6分析炉号时不同特征筛选方法结果对比
[0098][0099][0100]
本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明的目的,而并非用作对本发明的限定,只要在本发明的实质范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1