用于测量语义分割网络的边界性能的方法与流程
本发明涉及一种用于测量语义分割网络的边界性能的方法和装置、一种计算机程序以及一种计算机可读存储介质和一种控制方法。
背景技术:
在图像识别中,语义分割起到重要作用。为了识别图像中的不同对象,有必要检测图像中的不同类型的对象并且对其分类。例如,利用图像识别,计算机能够将天空与建筑物、与道路和/或与植被区分开。这通过语义分割、进行预测、读取运行的不同对象的边界来实现。
为了测量语义分割的性能,特别地,需要测量语义分割的边界性能。通常,为此,边界本身必须被确定。通常,距离变换用于获得边界,然后像素距离用于对边界进行阈值处理,这是非常低效的。
因此,需要一种用于测量边界性能的改进的方法。
技术实现要素:
就边界度量(boundarymetric)的计算而言,已知的方法效率低下。此外,它们仅将其视为分析评估度量,这意味着其不能用于训练神经网络。
因此,提供一种测量语义分割网络的边界性能的改进的快速且灵活的方式。此外,引入边界损失项,该边界损失项是可区分的,因此可以在语义分割网络的训练中使用,以优化边界性能。
因此,可以以更可靠且更有效的方式来测量边界性能。此外,可以直接优化用于语义分割的神经网络的边界性能。实施例
根据一方面,一种用于测量语义分割网络的边界性能的方法包括以下步骤:确定限定图像的分割对象之间的边界的原始边界掩模;使用形态学运算根据原始边界掩模确定加粗边界掩模;根据原始边界掩模和/或加粗边界掩模确定真正率、假正率和假负率;根据确定的真正率、确定的假正率和确定的假负率来确定指示边界性能的最终边界度量。
优选地,所述方法是计算机实施的方法。
如本文中所使用的,术语“加粗边界掩模”涉及一种与原始边界掩模相比被扩大的边界掩模。因此,原始边界掩膜限定图像的不同类别之间的更细的边界。
如本文中所使用的,术语“类别”涉及图像中包含的不同类型的对象,所述不同类型的对象被卷积神经网络的语义分割网络分割。优选地,在包含被语义分割网络分割的对象的图像上,从背景分割待检测的对象。在图像的二进制图像图中,待检测的对象、也被称为前景优选地通过值“1”来标记,背景通过值“0”来标记。例如,如果通过语义分割网络在图像中对狗进行分割,则图像的与狗相关的每个像素获得值“1”并且图像的与背景相关的每个像素获得值“0”。因此,图像的二进制图像图被创建。在图像中分割的不同类别的示例包括风景、汽车、人、天空、树木和/或植被。
如本文中所使用的,术语“形态学运算”是基于形状来处理图像的图像处理运算的广泛集合。在形态学运算中,图像中的每个像素基于其邻域中的其他像素的值来调整。通过选择邻域的尺寸和形状,可以构造对输入图像中的特定形状敏感的形态学运算。两个基本的形态学运算符为腐蚀和膨胀,腐蚀使前景缩小,而膨胀使前景对象扩大。
原始边界掩模和/或加粗边界掩模优选地被配置为二进制边界掩模。
优选地,确定原始边界掩模的步骤包括对图像图进行阈值处理。
优选地,真正与被正确分类为前景的像素的数量相关。因此,真正率与被正确分类为前景的像素的数量和前景的正确标注(groundtruth)的像素的总数量相比相关。
优选地,假正与被错误地分类为前景的像素的数量相关。因此,假正率与被错误地分类为前景的像素的数量和前景的正确标注的像素的总数量相比相关。
优选地,假负与被错误地分类为背景的像素的数量相关。因此,假负率与被错误地分类为背景的像素的数量和前景的正确标注的像素的总数量相比相关。
通过使用形态学运算获得原始边界掩膜和加粗边界掩膜,允许改进的对边界性能的分析评估。
因此,可以改进对边界性能的测量。
在一个优选实施例中,确定原始边界掩模的步骤包括:确定原始正确标注边界掩模和确定预测原始边界,确定加粗边界掩模的步骤包括:根据原始正确标注边界掩模确定加粗正确标注边界掩模,根据原始预测的边界掩膜确定加粗预测边界掩模。
为了允许将预测中的更多像素视为边界像素,优选地使正确标注的边界加粗。当使用加粗正确标注边界掩膜和预测的边界的卷积之和来计算真正时,与使用正确标注边界掩膜和预测的边界掩膜之和相比,真正率会更高。对于假正率和假负率类似,分数将更低。
因此,可以改进对边界性能的测量。
在一个优选实施例中,所述方法包括确定边界损失函数的步骤,所述边界损失函数被确定为第一损失项lce和第二损失项lb的加权和,其中,第一损失项表示语义分割的交叉熵损失,其中,第二损失项包括可微分的边界损失项。α是可以被调整的用于加权的超参数。
边界损失项是可微分的,因此可以在语义分割网络的训练中使用,以优化边界性能。
以下函数描述了所述关系。
边界损失函数=αlce+(1-α)lb
在一个优选实施例中,可微分的边界损失项根据正确标注边界掩膜和预测的边界掩膜确定。
优选地,对于一个类别,正确标注和预测被确定。
可微分的边界损失项通过以下项来确定:
或
lb=交叉熵(正确标注*正确标注边界掩膜,预测*正确标注边界掩膜)
其确定边界掩膜的像素的交叉熵。
边界损失项lb可以描述为损失项,其可以被计算为对边界像素赋予更多加权的交叉熵损失或dice损失,其中,边界的粗细可以使用与边界分析评估度量相同的思想来限定。
因此,当与加权参数的调整一起共同优化正常像素的交叉熵损失和边界损失项时,可以改进卷积神经网络关于边界像素的性能。
因此,可以改进对边界性能的测量。
在一个优选实施例中,确定原始边界掩模的步骤包括使用形态学运算。
腐蚀(erosion)是计算机视觉中的一种形态学运算,其使用结构元滤波器缩小区域边界。例如,结构元滤波器为3×3的正方形。
优选地,原始边界掩模通过从二进制图像图减去腐蚀的二进制图像图来确定。
以下函数描述了所述关系。
原始边界掩膜=二进制图像图-腐蚀(二进制图像图)
因此,可以改进对边界性能的测量。
在一个优选实施例中,确定原始边界掩模的步骤包括使用具有二阶拉普拉斯算子的卷积。
优选地,对卷积的使用包括根据原始边界图来确定原始边界掩模。原始边界图通过二进制图像图和边缘核的二维卷积来确定,同时使用填充。以下函数描述了所述关系。
原始边界图=二维卷积(二进制图像图,边缘核,填充=′same′
如本文中所使用的,术语“填充=′same′”意味着零填充将被执行,以使卷积的输出与输入图像具有相同的形状。
优选地,边缘核具有3×3的尺寸。例如,边缘核被限定为
基于确定的原始边界图来确定原始边界掩模。优选地,原始边界掩模通过边界图的具有小于零的值的像素来确定。以下函数描述了该关系。
原始边界掩膜=原始边界图<0
因此,可以改进对边界性能的测量。
在一个优选实施例中,确定加粗边界掩模的步骤包括原始边界掩模的膨胀,其中,原始边界掩模的膨胀使原始边界掩模的内部边界和原始边界掩模的外部边界加粗。
由于在边界二进制图中其本身很细,因此当直接对其计算边界分数时,最终分数将趋于非常小。在实践中,将总是允许一定的公差,这意味着,如果预测的边界像素是少数图片中的,则是允许的。为了为公差设置阈值,提出的边界度量使用形态学运算来计算加粗边界掩膜。
膨胀(dilation)是与腐蚀相反的形态学运算,其使用结构元滤波器扩大区域边界。然后,边界的粗细可以通过结构元滤波器尺寸的尺寸来控制。然后,公差的阈值通过过滤器尺寸控制。优选地,过滤器尺寸是3×3。
因此,原始边界掩模的内部边界被扩大。
以下函数描述了所述关系。
加粗边界掩膜=膨胀(原始边界掩膜)
在一个优选实施例中,根据原始边界掩模确定加粗边界的步骤包括腐蚀,其中,腐蚀仅使原始边界掩模的内部边界加粗。
以下函数描述了所述关系。
加粗边界掩膜=二进制图像图-腐蚀(二进制图像图,较大的核)
较大的核优选地具有比边缘核高的尺寸。
因此,原始边界的内部边界和原始边界的外部边界被扩大。
因此,可以改进对边界性能的测量。
在一个优选实施例中,真正率根据加粗正确标注边界掩膜和原始预测边界掩膜来确定,其中,假正率根据加粗正确标注边界掩膜和原始预测边界掩膜来确定,和/或,其中,假负率根据原始正确标注边界掩膜和加粗预测边界掩膜来确定。
优选地,真正通过加粗正确标注边界掩模与原始预测边界掩模的乘积之和来确定。然后,真正率根据确定的真正和正确标注来确定。换句话说,真正限定在两个掩膜上具有值1(前景)的像素的总数量。
优选地,假正通过加粗正确标注边界掩模与原始预测边界掩模的乘积之和来确定。然后,假正率根据确定的假正和正确标注来确定。
优选地,假负通过正确标注边界掩模与加粗预测边界掩模的乘积之和来确定。然后,假负率根据确定的假负和正确标注来确定。
在一个优选实施例中,最终边界度量包括交并比分数、iou(intersectionoverunion)分数。
优选地,交并比分数、iou分数根据真正率、假正率和假负率来确定。更优选地,交并比分数通过真正率除以真正率、假正率和假负率之和来确定。
以下函数描述了所述关系。
优选地,iou分数在0和1之间的范围内,其中,较高的值与较好的分数相关。
因此,可以改进对边界性能的测量。
在一个优选实施例中,最终边界度量包括f1分数,其中,确定最终边界度量的步骤包括确定精确度因子和确定召回率因子,其中,f1分数根据确定的精确度和确定的召回率来确定。
优选地,精确度因子根据真正率和假正率来确定。更优选地,精确度因子通过真正率除以真正率和假正率之和来确定。
以下函数描述了所述关系。
优选地,召回率因子根据真正率和假负率来确定。更优选地,召回率因子通过真正率除以真正率和假负率之和来确定。
以下函数描述了所述关系。
优选地,f1分数根据精确度因子和召回率因子来确定。更优选地,f1分数通过将精确度因子乘以因子2和召回率因子,并且将其除以精确度因子和召回率因子之和来确定。
以下函数描述了所述关系。
优选地,f1分数在0和1之间的范围内,其中,较高的值与较好的分数相关。
根据一方面,一种被配置为能够执行如本文中所述的用于测量边界性能的方法的装置。
根据一方面,提供一种包括指令的计算机程序,当程序通过计算机执行时,所述指令使计算机执行如本文中所述的用于测量边界性能的方法。
根据一方面,提供一种计算机可读数据载体,所述计算机可读数据载体上存储有如本文中所述的计算机程序。
根据一方面,一种至少部分自主的机器人的控制方法包括以下步骤:接收至少部分自主的机器人的环境图像数据;对接收的环境图像数据执行图像识别,其包括执行如本文中所述的用于测量边界性能的方法;根据执行的图像识别来控制至少部分自主的机器人。
优选地,至少部分自主的机器人包括至少部分自主的车辆。替代地,至少部分自主的机器人可以是任何其他移动机器人、例如通过飞行、游泳、潜水或步行而移动的移动机器人。在一个示例中,至少部分自主的机器人可以是至少部分自主的割草机或至少部分清洁机器人。
优选地,控制至少部分自主的机器人的步骤包括使用驾驶员辅助功能用于至少部分自主的机器人的车道保持支持和车道偏离警告。
附图说明
在下文中将参考优选的示例性实施例更详细地解释本发明的主题,所述优选的示例性实施例在附图中示出,在附图中:
图1示出了使用腐蚀确定原始边界掩模;
图2示出了不同的边界图;
图3示出了边界的膨胀的示意示图;
图4示出了基于对边界的相对差的预测的在原始边界与加粗边界之间的真正、假正和假负的比较;
图5示出了基于对边界的相对好的预测的在原始边界与加粗边界之间的真正、假正和假负的比较;
图6示出了用于测量语义分割网络的边界性能的方法的示意图。
附图中使用的附图标记及其含义在附图标记的列表中以总结的形式列出。原则上,相同的部分在图中具有相同的附图标记。
具体实施方式
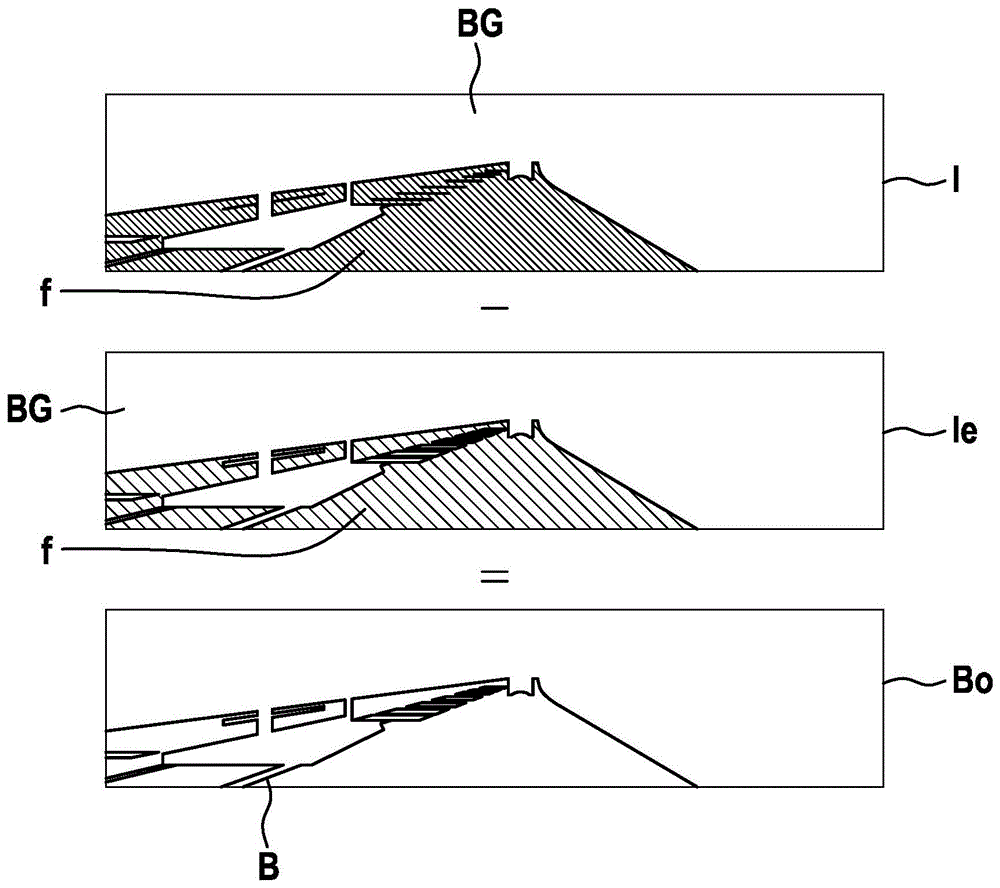
图1示出了图像图i。图像图i是将图像图i划分为前景f和背景bg的二进制图像图i。为了计算前景f与背景bg之间的二进制边界b,原始边界掩模(boundarymask)bo被确定。
因此,使用形态学运算,所述形态学运算在这种情况下为腐蚀。使用腐蚀,边界b的面积使用结构元滤波器被缩小。在所示的情况下,结构元滤波器为3×正方形。将腐蚀施加到图像图i,确定腐蚀的图像图ie。将图像图i与腐蚀的图像图ie进行比较,可以看出,腐蚀的图像图ie的腐蚀的前景fe小于图像图i的前景f。因此,腐蚀的图像图ie的腐蚀的背景bge大于图像图i的背景bg。
从图像图i中减去腐蚀的图像图ie以对它们进行比较,得到原始边界掩模bo。因此,施加到图像图i的腐蚀确定原始边界图bo的边界b。
图2示出了具有边界b的原始边界图bo。如可见的,边界b本身相对细。直接对相对细的边界b计算与确定的边界b的质量相关的边界分数通常导致小的边界分数。通常,在实际的用例中,需要容忍边界上的一些偏差、例如在周长中的10像素。那么进行加粗边界计算非常有用,这是因为在这种情况下可以具有一些容忍度,从而不会获得太低的分数并且同时仍然正确地反映性能。因此,边界b需要被加粗。确定的加粗边界图bt在图2中示出,其包括加粗边界bth。当将边界b与加粗边界bth进行比较时,可以看出,与边界b相比,加粗边界bth被扩大。这将得到与边界b相比的加粗边界bth的更好边界分数。
为了确定加粗边界掩模bt,优选地使用形态学运算。在图3的情况下,原始边界掩模bo的膨胀被示出为用于扩大图像图i的内部边界in和外部边界out。如图3中所示,图像图i包括通过边界b分割的前景f和背景bg。使用膨胀,内部边界in被确定在边界b的前景侧,并且外部边界out被确定在边界b的背景侧。因此,加粗边界bt可以被确定。
图4示出了基于边界的相对差的预测的在原始边界与加粗边界之间的真正(truepositive)、假正(falsepositive)和假负(falsenegative)的比较。
首先,示出正确标注边界bgt的正确标注gt,其与如原始图像中所示的前景和背景之间的边界相关。在基于卷积神经网络的图像识别期间,当执行语义分割时,需要预测前景和背景之间的边界,并且必须确定预测边界bp。通常,由于卷积神经网络的语义分割中的不同的不确定性,预测边界bp与正确标注边界bgt不相同。
图4证明了如本文中所述的加粗边界掩模的与原始边界掩模相比的优点。如可见的,预测边界bp与正确标注边界gt的不同相对较大。
示出第一原始真正tpo1,其基于原始边界掩模bo与被正确地分类为前景的边界的像素的数量相关。与此相比,示出第一加粗真正tpth1,其基于加粗边界掩模bt与被正确地分类为前景的边界的像素的数量相关。与第一原始真正tpo1相比,第一加粗真正tpth1获得可接受的分数,同时仍然正确反映边界的性能。
示出第一原始假正fpo1,其基于原始边界掩膜bo与被错误地分类为前景的边界的像素的数量相关。与此相比,示出第一加粗假正fpth1,其基于加粗边界掩模bt与被错误地分类为前景的边界的像素的数量相关。第一加粗假正fpth1具有比第一原始假正fpo1更少数量的错误分类的像素,与第一原始假正fpo1相比,第一加粗假正fpth1获得可接受的分数,同时仍然正确地反映边界的性能。
示出第一原始假负fno1,其基于原始边界掩模bo与错误地未被分类为前景的边界的像素的数量相关。与此相比,示出第一加粗假负fnth1,其基于加粗边界掩模bt与错误地未被分类为前景的边界的像素的数量相关。与第一原始假负fno1相比,第一加粗假负fnth1获得可接受的分数,同时仍然正确反映边界的性能。
如所述的,与正确标注边界掩模bgt相比,预测边界掩模bp看起来不精确。然而,在这种情况下,预测仍具有0.97的非常高的iou分数。提出的边界分数在0.74的合理值处。例如,没有加粗的相对差的边界将获得在约0.3的范围中的iou分数。
如本文中所述,图5证明了加粗边界掩模的与原始边界掩模相比的优点。如可见的,预测边界bp与正确标注边界gt仅略有不同(与图4相比)。
示出第二原始真正tpo2,其基于原始边界掩模bo与被正确分类为前景的边界的像素的数量相关。与此相比,示出第二加粗真正tpth2,其基于加粗边界掩模bt与被正确分类为前景的边界的像素的数量相关。第二加粗真正tpth2具有比第二原始真正tpo2更大数量的正确分类的像素,并且因此比第二原始真正tpo2更精确。
示出第二原始假正fpo2,其基于原始边界掩膜bo与被错误地分类为前景的边界的像素的数量相关。与此相比,示出第二加粗假正fpth2,其基于加粗边界掩模bt与被错误地分类为前景的边界的像素的数量相关。第二加粗假正fpth2具有比第二原始假正fpo2更少数量的错误分类的像素,并且因此比第二原始假正fpo2更精确。第二加粗假正fpth2包括相对少量的错误分类的像素。
示出第二原始假负fno2,其基于原始边界掩模bo与错误地未被分类为前景的边界的像素的数量相关。与此相比,示出第二加粗假负fnth2,其基于加粗边界掩模bt与错误地未被分类为前景的边界的像素的数量相关。第二加粗假负fnth2具有比第二原始假负fno2更少数量的错误地未被分类的像素,并且因此比第二原始假负fno2更精确。第二加粗假负fnth2包括相对少量的错误分类的像素。
如所述的,与正确标注边界掩模bgt相比,预测边界掩模bp看起来较精确。在这种情况下,预测具有0.99的非常高的iou分数。提出的边界分数在0.95的高值处。例如,没有加粗的相对好的边界将获得在约0.5的范围中的iou分数。
图6示出了用于测量语义分割网络的边界性能的方法的示意示图。在步骤s1中,确定限定图像的不同类别之间的边界的原始边界掩模bo。在步骤s2中,使用形态学运算根据原始边界掩模bo,确定加粗边界掩模bt。在步骤s3中,根据原始边界掩模bo和/或加粗边界掩模bt,确定真正率、假正率和假负率。在步骤s4中,根据确定的真正率、确定的假正率和确定的假负率来确定最终边界度量。
- 还没有人留言评论。精彩留言会获得点赞!