基于有人/无人机系统的近距空战智能决策方法与流程
本发明属于有人/无人机协同技术领域,具体涉及一种基于有人/无人机系统的近距空战智能决策方法。
背景技术:
无人机作为新兴的空中作战力量,在现代局部战争中发挥着越来越多的作用,与有人机相比,无人机具有零伤亡、持续作战能力强、全寿命周期成本低,以及在尺寸和机动性等方面的特有优势。通过无人机与有人作战平台的协同作战运用,在一定程度上可以弥补当前无人机自主水平不够的不足,使无人机与有人作战平台优势互补,增强体系立体态势感知能力、提高战场生存力和任务成功率,进而提升体系作战的能力,该作战方式是潜在的第六代穿透型战机的发展方向之一。
在近距对空作战中,敌我机群的机动变化更为剧烈,战场态势更迭更为迅速,对决策的实时性和智能程度要求更高。目前机动决策的方法可大致分为两大类:一类是以微分对策和专家系统为代表的传统方法;另一类是以强化学习、遗传算法、影响图法、蚁群算法、人工免疫系统等为代表的智能方法。近年来,随着人工智能技术的普及,特别是深度强化学习理论的迅速发展,其凭借着不需要先验知识输入,仅依靠与环境交互“试错”实现自我学习的特点而具备了与近距空战决策进行结合的可能,同时该技术的运用可以极大地缓解有人机飞行员决策的压力,为其争取更多的时间去指挥调度整个有人/无人系统,从而最大限度地发挥系统的作战效力。
技术实现要素:
为体现有人机在全局指挥调度方面的特点,同时充分发挥无人机在空战中持续作战能力强、全寿命周期成本低的优势,本发明以有人/无人机系统为研究对象,提出一种基于有人/无人机系统的近距空战智能决策方法。
具体地,本发明的技术方案是:
一种基于有人/无人机系统的近距空战智能决策方法,包括以下步骤:
s1.确定有人/无人机系统的组成,其中有人机用于全局指挥调度,无人机用于实施空战;
s2.根据近距空战更加重视作战双方相对位置和相对速度的特点,确定系统内无人机的航迹控制模型;
s3.根据马尔科夫决策过程理论,建立有人/无人机系统近距空战智能决策模型,其中奖励函数根据有人机不同空战意图确定;
s4.利用强化学习算法对有人/无人机系统近距空战智能决策模型进行训练,得到满足预设成功率要求的各空战意图下的神经网络;
s5.有人机根据战场态势判断无人机应采取的空战意图,并以命令的形式下达给无人机;
s6.无人机加载空战意图所对应的神经网络,进行智能决策,并结合无人机的航迹控制模型,生成空战航迹。
进一步的,本发明的s1通过以下步骤方法实现:
由n架有人机和k架无人机构成有人/无人机系统,其中n≥1,k≥1,系统中,无人机表示为集合u,u={i∈n+|ui,i≤k},其中n+表示正整数,ui表示无人机个体,所配备的武器为近距离航炮;有人机记为m,m={j∈n+|cj,j≤n},其中cj表示有人机个体。
进一步的,本发明的s2通过以下步骤方法实现:
在研究无人机空战航迹时,重点是研究空战双方实时的位置信息和速度信息,因此可将无人机视为质点,研究其三自由度质点模型:
其中,(x,y,h)表示无人机在惯性坐标系下的三维坐标;(γ,χ,μ,α)表示无人机的航迹倾角、航向角、航迹滚转角和迎角;v指无人机飞行速度;m为无人机质量,g为重力加速度;t为发动机推力;d为空气阻力,l为升力,二者的计算公式为:
其中,su为无人机参考横截面积;cl和cd分别为升力和阻力系数;ρ为空气密度,当无人机在对流层高度飞行时,其随海拔高度h的变化为:
ρ=1.225*[(288.15-0.0065*h)/288.15]4.25588
无人机的发动机推力t的表达式如下:
t=δtmax
其中,tmax为发动机最大推力,δ为油门,取值为[0,1];设定u0=(δ,α,μ)为无人机航迹控制的输入,s=(x,y,h,v,χ,γ)为无人机航迹控制的状态量。
进一步的,本发明的s3通过以下步骤方法实现:
智能体与环境的交互都可以用马尔科夫决策过程来表示,其主要包含状态空间、动作空间、奖励函数、折扣系数以及状态转移概率等5个要素,而对于无模型强化学习,只需要讨论5个要素中的前4个要素;
其中近距空战智能决策模型的状态空间要素xo具体为:
xo=(d0,qr,qb,β0,δh,δv,v,h,f1,f2)
其中,其中d0、qr、qb、和β0的表达式为:
其中,下标r和b用以区分我方无人机与敌方无人机的状态量;d0表示敌我双方相对距离;q表示速度矢量与质心连线的夹角;β0、δh、δv分别表示敌我双方速度矢量的夹角、高度差和速度差;f1和f2分别是达成目标和超出限幅的预警标识;
近距空战智能决策模型的动作空间要素a=(a1,a2,a3),与无人机航迹控制量u0=(δ,α,μ)之间的联系为:
其中,sigmoid和tanh为神经网络的激活函数,输出范围分别为[0,1]和[-1,1],αv和αμ分别为α和μ的值域;
近距空战智能决策模型的奖励函数要素具体为:
当有人机的意图为攻击意图时,此时意图目标达成的条件为:qr∈qattack且d0<demit,其中qattack和demit表示允许攻击敌方的视线角区间和发射距离;当敌方构成相同的发射条件或d0>descape时,认为我方失败,其中descape为逃脱距离;另外,当无人机的状态量超出限幅时,亦认定失败,具体的优势函数设定如下:
其中,ra,d、rv、rh和rresult分别表示角度距离优势函数、速度优势函数、高度优势函数和结果优势函数;v0、δh0为最优空战速度和高度差;sr为我方无人机状态量值域;当达到意图目标状态或失败状态3s及以上时,rresult置为非零值,不足3s时通过预警标识进行标记和引导;
当有人机的意图为逃离意图时,此时意图目标达成的条件是:d0>descape且qb∈q0,具体的优势函数如下:
其中,qb∈q0表示我方攻击时应保证敌方的视线角在q0的区间内,通常q0表示一个钝角区间,q0_min为q0的最小值;
将各意图中的ra,d、rv、rh、rresult和预警标识f1,f2进行加权,得到两意图下的奖励函数r:
其中,ωa,d,ωv,ωh,ωresult,
近距空战智能决策模型的折扣系数要素γd的设定通常为经验常值,如γd=0.9。
进一步的,本发明的s4通过以下步骤方法实现:
根据强化学习中智能体利用环境反馈调整自身策略以实现最佳决策的特性,对近距空战智能决策模型进行训练,当达到每训练100回合有90回合达到空战意图目标时,停止训练,并保存此时的神经网络。
进一步的,本发明的s5通过以下步骤方法实现:
当有人/无人机系统以完成空战突袭任务为目标或敌方机体性能指标低于我方时,有人机向无人机下达强攻意图指令;当有人/无人机系统旨在完成空战中诱敌任务或敌方空战优势较大、我方机体出现故障时,有人机向无人机下达逃离意图指令。
进一步的,本发明的s6通过以下步骤方法实现:
无人机加载空战意图所对应的神经网络,并根据实时更新的状态空间xo进行智能决策,得出u0并将其输入到无人机航迹控制模型之中,结合决策时间间隔δt,利用龙格库塔法得到无人机在任意时刻的s,即实时生成了满足有人机空战意图的航迹。
本发明将强化学习理论与有人/无人智能空战决策模型相结合,创新地引入有人机的典型空战意图,即攻击意图和逃离意图,并分别建立了不同的奖励函数模型,通过嵌入智能决策系统,可有效发挥有人机在异构系统中的指挥引导作用,实现有人机与无人机的优势互补。
附图说明
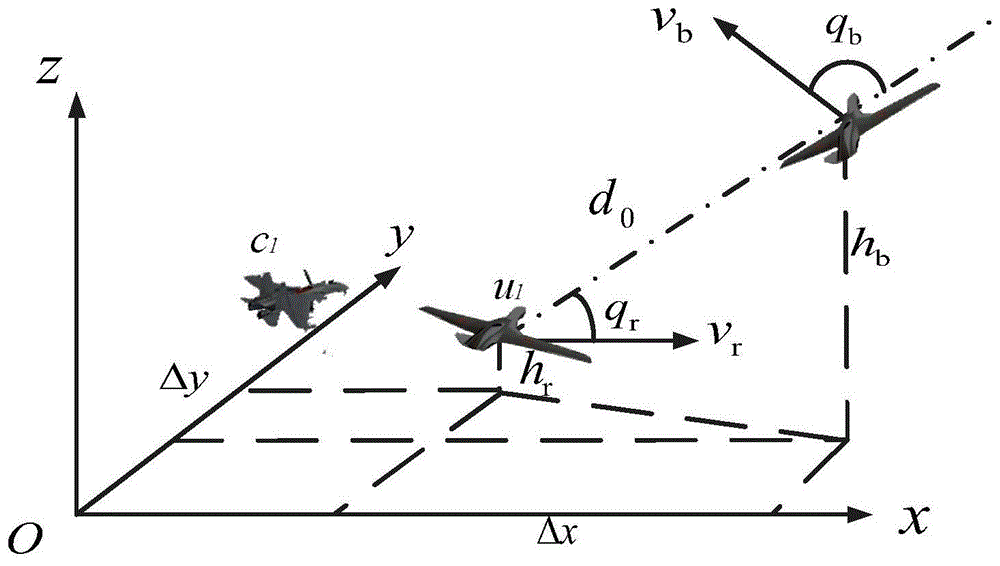
图1是有人/无人机系统空战示意图;
图2是ddpg算法原理图;
图3是本发明流程图。
具体实施方式
本发明中有人/无人机空战示意图如图1所示。图1中,我方有1架有人机c1带领1架无人机u1进行空战,即n=1,k=1,敌方配置1架无人机;其中,下标r和b用以区分我方无人机与敌方无人机的状态量;d0表示敌我双方相对距离;v指无人机飞行速度;q表示速度矢量与质心连线的夹角;δx、δy表示敌方与我方无人机在惯性坐标系下的x、y轴上的位置差;h为无人机飞行高度。
具体地,一种基于有人/无人机系统的近距空战智能决策方法,包括以下步骤:
s1.确定有人/无人机系统的组成,其中有人机用于全局指挥调度,无人机用于实施空战。
由1架有人机和1架无人机构成有人/无人机系统,系统中,无人机用u1表示,所配备的武器为近距离航炮;有人机用c1表示。
s2.根据近距空战更加重视作战双方相对位置和相对速度的特点,确定系统内无人机的航迹控制模型。
在研究无人机空战航迹时,重点是研究空战双方实时的位置信息和速度信息,因此可将无人机视为质点,研究其三自由度质点模型:
其中,(x,y,h)表示无人机在惯性坐标系下的三维坐标;(γ,χ,μ,α)表示无人机的航迹倾角、航向角、航迹滚转角和迎角;v指无人机飞行速度;m为无人机质量,g为重力加速度;t为发动机推力;d为空气阻力,l为升力,二者的计算公式为:
其中,su为无人机参考横截面积;cl和cd分别为升力和阻力系数;ρ为空气密度,当无人机在对流层高度飞行时,其随海拔高度h的变化为:
ρ=1.225*[(288.15-0.0065*h)/288.15]4.25588
无人机的发动机推力t的表达式如下:
t=δtmax
其中,tmax为发动机最大推力,δ为油门,取值为[0,1];设定u0=(δ,α,μ)为无人机航迹控制的输入,s=(x,y,h,v,χ,γ)为无人机航迹控制的状态量。
s3.根据马尔科夫决策过程理论,建立有人/无人机系统近距空战智能决策模型,其中奖励函数根据有人机不同空战意图确定。
智能体与环境的交互都可以用马尔科夫决策过程来表示,其主要包含状态空间、动作空间、奖励函数、折扣系数以及状态转移概率等5个要素,而对于无模型强化学习,只需要讨论5个要素中的前4个要素,本发明中有人/无人机系统近距空战智能决策模型即基于无模型强化学习建立。
其中近距空战智能决策模型的状态空间要素xo具体为:
xo=(d0,qr,qb,β0,δh,δv,v,h,f1,f2)
其中,其中d0、qr、qb、和β0的表达式为:
其中,下标r和b用以区分我方无人机与敌方无人机的状态量;d0表示敌我双方相对距离;q表示速度矢量与质心连线的夹角;β0、δh、δv分别表示敌我双方速度矢量的夹角、高度差和速度差;f1和f2分别是达成目标和超出限幅的预警标识;
近距空战智能决策模型的动作空间要素a=(a1,a2,a3),与无人机航迹控制量u0=(δ,α,μ)之间的联系为:
其中,sigmoid和tanh为神经网络的激活函数,输出范围分别为[0,1]和[-1,1],αv和αμ分别为α和μ的值域;
近距空战智能决策模型的奖励函数要素具体为:
当有人机的意图为攻击意图时,此时意图目标达成的条件为:qr∈qattack且d0<demit,其中qattack和demit表示允许攻击敌方的视线角区间和发射距离;当敌方构成相同的发射条件或d0>descape时,认为我方失败,其中descape为逃脱距离;另外,当无人机的状态量超出限幅时,亦认定失败,具体的优势函数设定如下:
其中,ra,d、rv、rh和rresult分别表示角度距离优势函数、速度优势函数、高度优势函数和结果优势函数;v0、δh0为最优空战速度和高度差;sr为我方无人机状态量值域;当达到意图目标状态或失败状态3s及以上时,rresult置为非零值,不足3s时通过预警标识进行标记和引导;
当有人机的意图为逃离意图时,此时意图目标达成的条件是:d0>descape且qb∈q0,具体的优势函数如下:
其中,qb∈q0表示我方攻击时应保证敌方的视线角在q0的区间内,通常q0表示一个钝角区间,q0_min为q0的最小值;
将各意图中的ra,d、rv、rh、rresult和预警标识f1,f2进行加权,得到两意图下的奖励函数r:
其中,ωa,d,ωv,ωh,ωresult,
近距空战智能决策模型的折扣系数要素γd的设定通常为经验常值,如γd=0.9。
s4.利用深度确定性策略梯度算法(deepdeterministicpolicygradient,ddpg)对有人/无人机系统近距空战智能决策模型进行训练,得到满足预设成功率要求的各空战意图下的神经网络。
ddpg算法融合了确定性策略梯度、演员—评论家(actor-critic)结构以及深度q网络的思想,是目前最为最流行的深度强化学习算法之一;借鉴深度q网络思想,ddpg算法也运用了经验回放和估计/目标网络,其原理图如图2所示,图中数字标号为算法运行的先后顺序,其中q(s,a|θq)和μ(s|θμ)分别表示critic和actor的估计网络,θq和θμ分别表示其参数;与之对应的,q'(s,aθq′)和μ'(s|θμ′)分别表示critic和actor的目标网络,对应参数为θq′和θμ';对于critic网络部分,其输入为动作a和当前状态s,输出为q(s,a);该网络的参数更新方式是向着最小化估计的q值和目标的q值的差的方向进行优化,其中估计的q值可以通过状态估计网络得到,目标的q值λi通过状态目标网络输出的q'值和即时奖励函数ri相加获得,具体如下式:
其中,下标i表示n个采样数据中第i个数据的标号,即0<i≤n;γd为近距空战智能决策模型的折扣系数要素;δq表示估计的q值和目标的q值的差的最小值方向;
对于actor网络,其输入为当前状态s,输出为动作a,而策略网络的参数是朝着值函数网络输出增大的方向进行更新,可表示为下式:
每循环一步,对目标网络的参数进行软更新,如下式:
θq′←τθq+(1-τ)θq′
θμ′←τθμ+(1-τ)θμ′
其中,τ为更新比例参数;
利用ddpg算法对近距空战智能决策模型进行训练,具体利用python3.0语言进行编程,以深度学习框架tensorflow为基础,actor和critic神经网络均采用简单的全连接网络架构,共设置2层神经网络,并分别选取600和300个神经元;每个意图训练的上限定为15000个回合,大约106步,当达到每训练100回合有90回合达到空战意图目标时,可随时停止训练,并保存此时的神经网络。
s5.有人机根据战场态势判断无人机应采取的空战意图,并以命令的形式下达给无人机。
当有人/无人机系统以完成空战突袭任务为目标或敌方机体性能指标低于我方时,有人机向无人机下达强攻意图指令;当有人/无人机系统旨在完成空战中诱敌任务或敌方空战优势较大、我方机体出现故障时,有人机向无人机下达逃离意图指令。
s6.无人机加载空战意图所对应的神经网络,进行智能决策,并结合无人机的航迹控制模型,生成空战航迹。
无人机加载空战意图所对应的神经网络,并根据实时更新的状态空间xo进行智能决策,得出u0并将其输入到无人机航迹控制模型之中,结合决策时间间隔δt,利用龙格库塔法得到无人机在任意时刻的s,即实时生成了满足有人机空战意图的航迹。
- 还没有人留言评论。精彩留言会获得点赞!