基于深度学习的文本分类方法与流程
本发明涉及一种基于深度学习的文本分类方法。
背景技术:
文本分类在信息处理中占据着重要的地位,随着互联网的发展海量的文本数据不断产生,这些文本数据中存在着大量的信息,利用有效的方法对这些信息进行有效的管理和提取对企业和社会信息技术发展有着重大作用。
目前,深度学习技术被广泛的应用在文本分类任务上。具体来说,kim等人将cnn应用在文本分类任务上,利用卷积层获取局部的文本信息。但卷积网络无法很好的利用文本的序列信息。之后人们将rnn以及在rnn基础上改进的lstm网络应用在文本分类任务上取得了更好的分类效果。但是,由于循环神经网络顺序处理词序列的特点,使得基于rnn的模型并行计算困难。
技术实现要素:
本发明的目的在于提供一种基于深度学习的文本分类方法。
为解决上述问题,本发明提供一种基于深度学习的文本分类方法,包括:
步骤1:对带文本标签的文本数据进行清洗,然后将清洗后的带标签的文本数据划分为训练数据集和验证集;
步骤2:将训练数据集合和验证集的文本中的单词替换成单词编号,以分别形成训练数据集合对应的单词索引序列和验证集对应的单词索引序列;
步骤3:构建词向量矩阵;
步骤4:基于所述词向量矩阵,将分别将训练数据集和验证集对应的单词索引序列映射为训练数据集和验证集对应的词向量序列s;
步骤5:将训练数据集对应的词向量序列s输入多注意力神经网络模型,以获取输出的文本向量sw;
步骤6:将所述文本向量sw输入到前馈神经网络中,以获取输出的文本类别概率向量;
步骤7:基于所述文本数据的文本标签得到文本标签向量,根据所述文本类别概率向量和文本标签向量,计算损失函数,并使用批量梯度下降算法优化所述损失函数,基于优化后的损失函数对注意力神经网络和前馈神经网络的模型参数进行调整,以得到优化后的模型;
步骤8:将验证集对应的词向量序列s输入所述优化后的模型,基于所述优化后的模型的输出选取最优的模型作为最终的模型;
步骤9:基于所述最终的模型对待分类的文本进行分类。
进一步的,在上述方法中,对带文本标签的文本数据进行清洗,包括:
去除多余的符号,只保留标点符号、单词,并将文本标签用one-hot向量表示。
进一步的,在上述方法中,步骤2:将训练数据集合和验证集的文本中的单词替换成单词编号,包括:
按照训练数据集中单词出现的频率分别为训练数据集中的单词进行编号,将训练数据集的文本中的单词替换成单词编号,其中,对于训练数据集中的前num个频率最高的单词,单词编号为该单词出现的频率对应的编号;对于编号大于num的单词,单词编号为0,num为正整数;
按照验证集中单词出现的频率分别为验证集中的单词进行编号,将验证集的文本中的单词替换成单词编号,其中,对于验证集中的前num个频率最高的单词,单词编号为该单词出现的频率对应的编号;对于编号大于num的单词,单词编号为0。
进一步的,在上述方法中,构建词向量矩阵,包括:
使用glove预训练词向量或者word2vec工具,分别获取训练数据集和验证集中的单词对应的维度为dim的词向量,其中,dim为正整数;
基于训练数据集中的单词对应的维度为dim的词向量,构建训练数据集对应的维度为num*dim的词向量矩阵;
基于训练验证集中的单词对应的维度为dim的词向量,构建训练数据集对应的维度为num*dim的词向量矩阵。
进一步的,在上述方法中,步骤4:基于所述词向量矩阵,将分别将训练数据集和验证集对应的单词索引序列映射为训练数据集和验证集对应的词向量序列s,包括:
基于所述训练数据集对应的词向量矩阵,并使用词向量初始化模型embedding层,将训练数据集输入embedding层,以得到训练数据集对应的词向量序列s;
基于所述验证集对应的词向量矩阵,并使用词向量初始化模型embedding层,将验证集对应的单词索引序列输入embedding层,以得到验证集对应的词向量序列s。
进一步的,在上述方法中,步骤5:将训练数据集对应的词向量序列s输入多注意力神经网络模型,以获取输出的文本向量sw,
将训练数据集对应的词向量序列s输入多注意力神经网络中,利用词注意力网络学习单词间依赖关系得到文本向量s1;
利用局部注意力网络学习局部依赖关系得到向量s2;
最后将s1和s2输入到交叉注意力网络中学习局部与单词间的依赖关系得到文本向量sw。
进一步的,在上述方法中,步骤7中,所述损失函数计算公式为:
其中,批量大小batch-size=128,y为文本标签,
与现有技术相比,本发明首先对带标签的文本数据进行清洗、划分;然后将文本序列映射为词向量序列s;并将s输入到多注意力神经网络(mann)中得到文本向量sw。最后,将句子sw输入到前馈神经网络(fnn)分类器得到文本类别。模型按照预设的超参数训练模型,根据模型在验证集上的表现选取最优的模型。实验结果显示,该模型取得了较好的分类精度。发明考虑了词序列中单词、局部序列间的依赖关系,提高了文本分类的精度。
附图说明
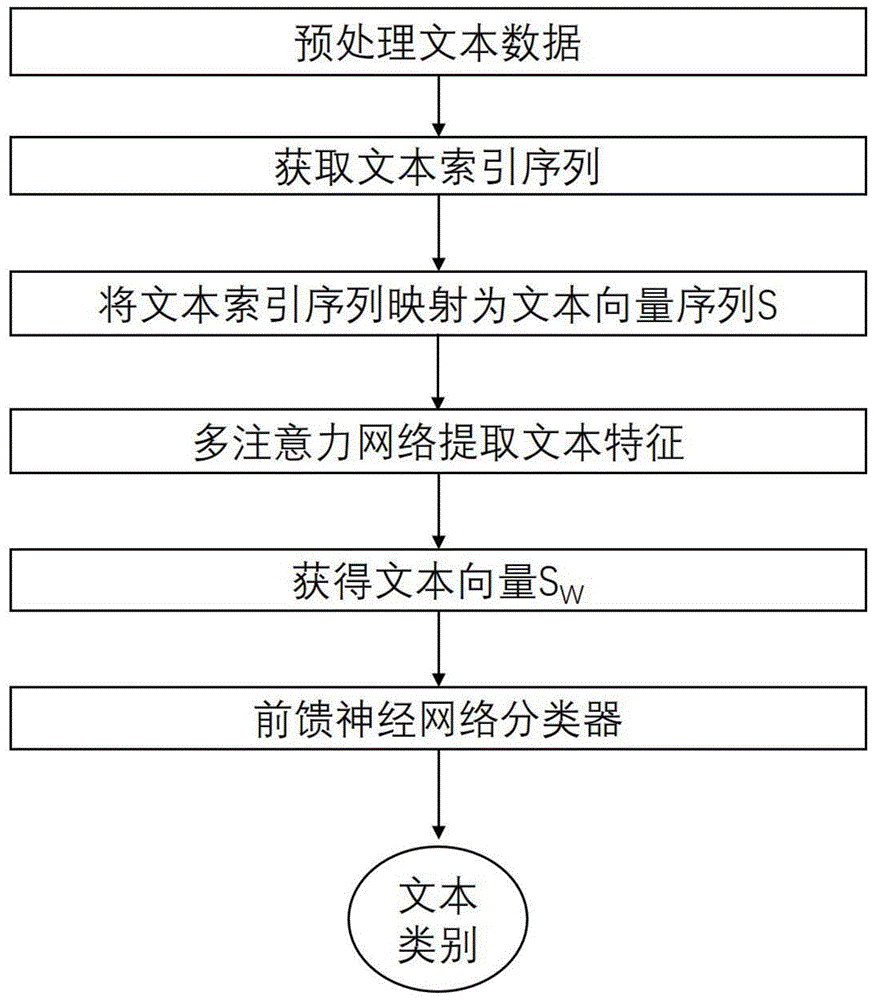
图1为本发明一实施例提供的文本分类模型流程图;
图2为本发明一实施例提供的词向量的获取方法的结构示意图;
图3为本发明一实施例提供的词注意力网络(wan)结构示意图;
图4为本发明一实施例提供的局部注意力网络(lan)结构示意图;
图5为本发明一实施例提供的交叉注意力网络(can)结构示意图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
如图1所示,本发明提供一种基于深度学习的文本分类方法,包括:
步骤1:对带文本标签的文本数据进行清洗,然后将清洗后的带标签的文本数据划分为训练数据集和验证集;
步骤2:将训练数据集合和验证集的文本中的单词替换成单词编号,以分别形成训练数据集合对应的单词索引序列和验证集对应的单词索引序列;
步骤3:构建词向量矩阵;
步骤4:基于所述词向量矩阵,将分别将训练数据集和验证集对应的单词索引序列映射为训练数据集和验证集对应的词向量序列s;
步骤5:将训练数据集对应的词向量序列s输入多注意力神经网络(mann)模型,以获取输出的文本向量sw;
步骤6:将所述文本向量sw输入到前馈神经网络(fnn)中,以获取输出的文本类别概率向量;
在此,将文本向量sw输入到前馈神经网络(fnn)分类器中,利用softmax层将输入映射为对应的类别概率向量
步骤7:基于所述文本数据的文本标签得到文本标签向量,根据所述文本类别概率向量和文本标签向量,计算损失函数,并使用批量梯度下降算法优化所述损失函数,基于优化后的损失函数对注意力神经网络和前馈神经网络的模型参数进行调整,以得到优化后的模型;
步骤8:将验证集对应的词向量序列s输入所述优化后的模型,基于所述优化后的模型的输出选取最优的模型作为最终的模型;
步骤9:基于所述最终的模型对待分类的文本进行分类。
在此,模型训练的迭代次数epochs=1000。每次更新参数后将在验证集上评估模型性能,选取最优的模型作为最终的模型。
本发明首先对带标签的文本数据进行清洗、划分;然后将文本序列映射为词向量序列s;并将s输入到多注意力神经网络(mann)中得到文本向量sw。最后,将句子sw输入到前馈神经网络(fnn)分类器得到文本类别。模型按照预设的超参数训练模型,根据模型在验证集上的表现选取最优的模型。实验结果显示,该模型取得了较好的分类精度。发明考虑了词序列中单词、局部序列间的依赖关系,提高了文本分类的精度。
本发明的基于深度学习的文本分类方法一实施例中,对带文本标签的文本数据进行清洗,包括:
去除多余的符号,只保留标点符号、单词,并将文本标签用one-hot向量表示。
在此,保留对带文本标签的文本数据中词语间的空格和必要的标点符号。
本发明的基于深度学习的文本分类方法一实施例中,步骤2:将训练数据集合和验证集的文本中的单词替换成单词编号,包括:
按照训练数据集中单词出现的频率分别为训练数据集中的单词进行编号,将训练数据集的文本中的单词替换成单词编号,其中,对于训练数据集中的前num个频率最高的单词,单词编号为该单词出现的频率对应的编号;对于编号大于num的单词,单词编号为0,num为正整数;
按照验证集中单词出现的频率分别为验证集中的单词进行编号,将验证集的文本中的单词替换成单词编号,其中,对于验证集中的前num个频率最高的单词,单词编号为该单词出现的频率对应的编号;对于编号大于num的单词,单词编号为0。
在此,根据频率分别将训练数据集和验证集中的文本数据中单词进行的编号,取前30000个频率最高的常用词,并用编号代替文本序列;将数据集中的单词截取或填充为相同长度l,该长度设置为平均长度,计算公式为:
其中,n表示数据集大小、si表示第i个句子、len(si)表示句子si的长度。
本发明的基于深度学习的文本分类方法一实施例中,步骤3:构建词向量矩阵,包括:
使用glove预训练词向量或者word2vec工具,分别获取训练数据集和验证集中的单词对应的维度为dim的词向量,其中,dim为正整数;
基于训练数据集中的单词对应的维度为dim的词向量,构建训练数据集对应的维度为num*dim的词向量矩阵;
基于训练验证集中的单词对应的维度为dim的词向量,构建训练数据集对应的维度为num*dim的词向量矩阵。
在此,可以加载glove维度为100的预训练词向量文件,得到数据集中单词对应的词向量。
本发明的基于深度学习的文本分类方法一实施例中,步骤4:基于所述词向量矩阵,将分别将训练数据集和验证集对应的单词索引序列映射为训练数据集和验证集对应的词向量序列s,包括:
基于所述训练数据集对应的词向量矩阵,并使用词向量初始化模型embedding层,将训练数据集输入embedding层,以得到训练数据集对应的词向量序列s;
基于所述验证集对应的词向量矩阵,并使用词向量初始化模型embedding层,将验证集对应的单词索引序列输入embedding层,以得到验证集对应的词向量序列s。
在此,可以构建维度为30000*100的embedding矩阵,使用步骤3获取的词向量初始化embedding矩阵,并在模型训练过程中微调embedding层参数。如图2所示,将词序列向量右乘embedding矩阵获取文本向量序列s。
本发明的基于深度学习的文本分类方法一实施例中,步骤5:将训练数据集对应的词向量序列s输入多注意力神经网络(mann)模型,以获取输出的文本向量sw,
将训练数据集对应的词向量序列s输入多注意力神经网络(mann)中,利用词注意力网络(wan)学习单词间依赖关系得到文本向量s1;
利用局部注意力网络(lan)学习局部依赖关系得到向量s2;
最后将s1和s2输入到交叉注意力网络(can)中学习局部与单词间的依赖关系得到文本向量sw。
在此,如图3所示,将文本向量s输入到词注意力神经网络(wan)中利用自注意力机制学习单词间依赖关系得到新的词向量序列s1;计算公式为:
其中,
如图4所示,将s1作为局部注意力网络(lan)的输入,该网络用于学习词序列局部间依赖关系得到句子向量序列s2。计算公式如下:
如图5所示,将s1、s2作为交叉注意力网络(can)的输入,该网络用于学习单词与局部词序列间的依赖关系得到句子向量sw。计算公式如下:
本发明的基于深度学习的文本分类方法一实施例中,步骤7中,所述损失函数计算公式为:
其中,批量大小batch-size=128,y为文本标签,
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。显然,本领域的技术人员可以对发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包括这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!