多功能业务板卡以及数据处理方法与流程
本公开涉及嵌入式系统技术领域,尤其涉及一种多功能业务板卡以及数据处理方法。
背景技术:
随着集成电路、计算机处理技术和软件技术的飞速发展,处理平台系统架构也随之快速发展演变。vpx是vita(vmeinternationaltradeassociation,vme国际贸易协会)组织于2007年在其vme总线基础上提出的新一代高速串行总线标准。在vpx平台或vpx系统中可以使用多种专用业务板卡,专用业务板卡为进行视频处理、雷达信号分析、数据加解密等的板卡,可用于雷达、通信、声纳、导航、电子对抗等多个领域。目前,对于多任务需求的应用场景,需要同时使用多种专用板卡。例如,在自动驾驶中,对于3d点云信号分析任务和3d场景图像生成任务,需要使用两个专用业务板卡,分别用于对3d点云信号进行分析、生成周边场景的3d场景图像。由于对于多任务需要同时使用多种专用板卡进行处理,使得系统的性能功耗较高、功耗较高,并且任务调度处理较复杂;因此,需要一种多功能业务板卡,能够满足处理多种任务的需求。
技术实现要素:
为了解决上述技术问题,提出了本公开。本公开的实施例提供了一种多功能业务板卡以及数据处理方法。
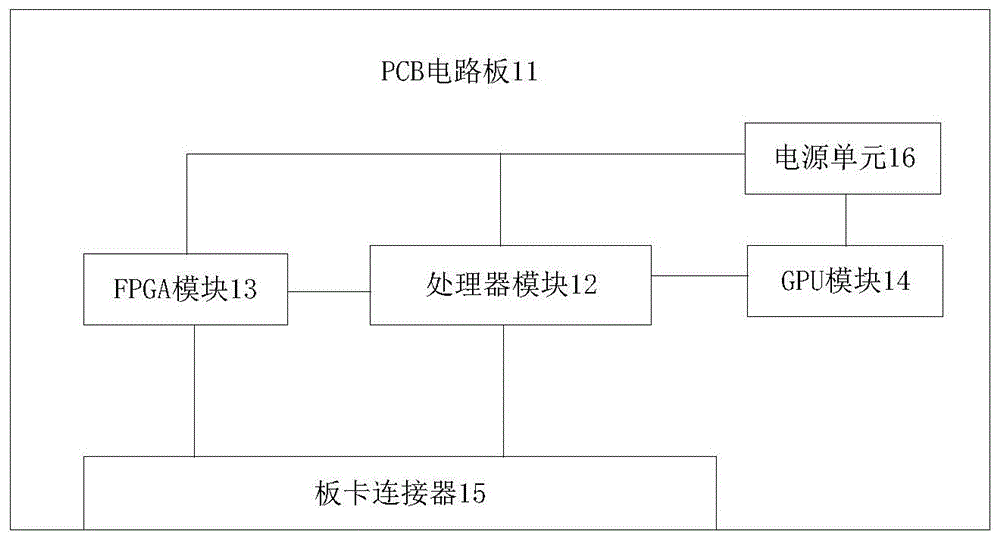
根据本公开实施例的一个方面,提供一种多功能业务板卡,包括:pcb电路板;在所述pcb电路板上设置有处理器模块、gpu模块和fpga模块;所述fpga模块通过第一pcie信号线与所述处理器模块连接,所述处理器模块通过第二pcie信号线与所述gpu模块连接;所述fpga模块,用于对接收到的第一数据进行处理,获得第二数据并发送给所述处理器模块或外部设备;所述gpu模块对接收到的第三数据进行处理,获得第四数据并将所述第四数据发送给所述处理器模块或外部设备;所述处理器模块用于根据所述第二数据生成所述第三数据并传输给所述gpu模块或外部设备;对所述第二数据和所述第四数据进行整合处理,将整合后的数据传输给外部设备;其中,所述第一数据、所述第二数据、所述第三数据和所述第四数据包括:图像数据。
可选地,所述处理器模块包括cpu芯片单元;所述cpu芯片单元与第一ddr内存单元连接;在所述pcb电路板上设置有xmc接口、usb接口、以太网接口、vga接口、音频接口、串行接口、pcie接口和光纤接口;所述cpu芯片单元与所述xmc接口、所述usb接口、所述以太网接口、所述vga接口、所述音频接口、所述串行接口、所述pcie接口和所述光纤接口中的至少一个接口连接。
可选地,所述fpga模块包括:符合ultrascale架构的fpga芯片和第二ddr内存模块,所述fpga芯片与所述第二ddr内存模块连接;在所述pcb电路板上设置有多个lvds接口和多个gth接口;所述fpga芯片分别与所述lvds接口和所述gth接口连接。
可选地,所述fpga芯片设置有多个高速扩展卡接口以及调试jtag接口,其中,所述fpga芯片通过所述调试jtag接口接收调试指令以及配置信息。
可选地,所述gpu模块包括多个cuda处理核、图形模块和第三ddr内存单元;所述gpu模块通过所述cuda处理核对所述第三数据进行处理,获得所述第四图像数据;通过所述第三ddr内存单元缓存所述第三数据和所述第四数据。
可选地,所述第三数据和所述第四数据为图像数据;其中,所述gpu模块还包括图像输出接口;所述gpu模块通过所述图像输出接口向外部设备发送所述第四数据。
可选地,多种状态指示灯和电源单元;所述多种状态指示灯和所述电源单元设置在所述pcb电路板上;所述处理器模块、所述gpu模块和所述fpga模块分别与对应的状态指示灯连接,所述处理器模块、所述gpu模块和所述fpga模块分别与所述电源单元连接;后插卡模块;所述后插卡模块包括sata扩展接口、sata盘、显示接口、usb接口。
根据本公开实施例的一个方面,提供一种基于如上所述的多功能业务板卡的数据处理方法,包括:处理器模块接收到外部设备发送的处理命令和待处理数据,生成第一数据任务和第二数据处理任务;所述处理器模块基于所述第一数据任务并基于所述处理命令和所述待处理数据生成第一数据,将所述第一数据通过第一pcie信号线发送给fpga模块;所述fpga模块对所述第一数据进行处理,获得第二数据并通过所述第一pcie信号线将所述第二数据发送给所述处理器模块;所述处理器模块基于所述第二数据任务并基于所述处理命令、所述待处理数据以及所述第二数据生成第三数据,将所述第三数据通过第二pcie信号线发送给gpu模块;所述gpu模块对所述第三数据进行处理,生成第四数据并通过第二pcie信号线将所述第四数据发送给所述处理器模块;所述cpu主机单元对进行所述第二数据和所述第四数据进行整合处理,将整合后的数据传输给外部设备。
可选地,所述fpga接收外部设备发送的数据,对外部设备发送的数据进行处理,获得所述第二数据并发给所述处理器模块或此外部设备。
可选地,在所述fpga芯片内设置有虚拟接口模块、虚拟任务分发模块、虚拟数据处理模块;所述虚拟接口模块接收所述第一数据或外部设备发送的数据,将所述第一数据或外部设备发送的数据发送给所述虚拟任务分发模块;所述虚拟任务分发模块将所述第一数据或外部设备发送给对应的虚拟数据处理模块;所述虚拟数据处理模块对所述第一数据或外部设备发送的数据进行处理,获得所述第二数据并发给所述处理器模块或外部设备。
可选地,所述处理器模块将所述第二数据发送给外部设备;所述gpu模块对接收到的第三数据进行处理,获得第四数据并将所述第四数据发送给外部设备。
可选地,所述第一数据处理任务包括:压缩或解压任务、信号分析任务、编码或解码任务;所述第二数据任务包括:图像处理任务、3d虚拟重构任务;所述fpga模块对所述第一数据进行的处理包括:压缩或解压处理、信号分析处理、编码或解码处理;所述gpu模块对所述第三数据进行的处理包括:图像处理、3d虚拟重构处理。
基于本公开上述实施例提供的一种多功能业务板卡以及数据处理方法,在pcb电路板上设置有处理器模块、gpu模块和fpga模块,fpga模块通过第一pcie信号线与处理器模块连接,处理器模块通过第二pcie信号线与gpu模块连接;处理器模块对数据处理进行控制,fpga模块和gpu模块分别执行不同的处理任务,可以发挥fpga模块和gpu模块的并行处理能力,并且fpga具有良好的性能功耗比;能够适用于多种应用场景,满足多任务处理需求,使系统的性能功耗较低,降低了任务调度处理的复杂度,提高了产品质量和可靠性。
下面通过附图和实施例,对本公开的技术方案做进一步的详细描述。
附图说明
通过结合附图对本公开实施例进行更详细的描述,本公开的上述以及其他目的、特征以及优势将变得更加明显。附图用来提供对本公开实施例的进一步的理解,并且构成说明书的一部分,与本公开实施例一起用于解释本公开,并不构成对本公开的限制。在附图中,相同的参考标号通常代表相同部件或步骤。
图1为本公开的多功能业务板卡的一个实施例的模块示意图;
图2为本公开的多功能业务板卡的另一个实施例的模块示意图;
图3为本公开的多功能业务板卡的实物示意图;
图4为本公开的多功能业务板卡的一个实施例中的fpga芯片内设置的模块示意图;
图5为本公开的多功能业务板卡的gpu模块的实物示意图;
图6为在cuda架构下的存储器层次结构示意图;
图7为本公开的多功能业务板卡的后插卡模块的模块示意图;
图8为本公开的数据处理方法的一个实施例的流程图。
具体实施方式
下面将参考附图详细地描述根据本公开的示例实施例。显然,所描述的实施例仅仅是本公开的一部分实施例,而不是本公开的全部实施例,应理解,本公开不受这里描述的示例实施例的限制。
应注意到:除非另外具体说明,否则在这些实施例中阐述的部件和步骤的相对布置、数字表达式和数值不限制本公开的范围。
本领域技术人员可以理解,本公开实施例中的“第一”、“第二”等术语仅用于区别不同步骤、设备或模块等,既不代表任何特定技术含义,也不表示它们之间的必然逻辑顺序。
还应理解,在本公开实施例中,“多个”可以指两个或者两个以上,“至少一个”可以指一个、两个或两个以上。
还应理解,对于本公开实施例中提及的任一部件、数据或结构,在没有明确限定或者在前后文给出相反启示的情况下,一般可以理解为一个或多个。
另外,本公开中术语“和/或”,仅是一种描述关联对象的关联关系,表示可以存在三种关系,如a和/或b,可以表示:单独存在a,同时存在a和b,单独存在b这三种情况。另外,本公开中字符“/”,一般表示前后关联对象是一种“或”的关系。
还应理解,本公开对各个实施例的描述着重强调各个实施例之间的不同之处,其相同或相似之处可以相互参考,为了简洁,不再一一赘述。
同时,应当明白,为了便于描述,附图中所示出的各个部分的尺寸并不是按照实际的比例关系绘制的。
以下对至少一个示例性实施例的描述实际上仅仅是说明性的,决不作为对本公开及其应用或使用的任何限制。
对于相关领域普通技术人员已知的技术、方法和设备可能不作详细讨论,但在适当情况下,所述技术、方法和设备应当被视为说明书的一部分。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步讨论。
本公开的实施例可以应用于终端设备、计算机系统、服务器等电子设备,其可与众多其它通用或者专用计算系统环境或配置一起操作。适于与终端设备、计算机系统或者服务器等电子设备一起使用的众所周知的终端设备、计算系统、环境和/或配置的例子包括但不限于:个人计算机系统、服务器计算机系统、瘦客户机、厚客户机、手持或膝上设备、基于微处理器的系统、机顶盒、可编程消费电子产品、网络个人电脑、小型计算机系统、大型计算机系统和包括上述任何系统的分布式云计算技术环境等。
如图1所示,本公开提供一种多功能业务板卡,包括pcb电路板11;在pcb电路板11上设置有处理器模块12、gpu(图形处理器,graphicsprocessingunit)模块14和fpga(现场可编程门阵列,fieldprogrammablegatearray)模块13。fpga模块13通过第一pcie(peripheralcomponentinterconnectexpress,高速串行计算机扩展总线标准)信号线与处理器模块12连接,处理器模块12通过第二pcie信号线与gpu模块14连接。
fpga模块13对接收到的第一数据进行处理,获得第二数据并发送给处理器模块12或外部设备;第一数据和第二数据可以为图像数据、雷达信号数据、需要进行加密解密的数据等多种数据。外部设备可以为位于多功能业务板卡外部的多种终端、板卡等。第一数据可以由处理器模块12或外部设备发送给fpga模块13。
gpu模块14对接收到的第三数据进行处理,获得第四数据并将第四数据发送给处理器模块12或外部设备。处理器模块12用于根据第二数据生成第三数据并传输给gpu模块14或外部设备。处理器模块12对第二数据和第四数据进行整合处理,将整合后的数据传输给外部设备。第三数据和第四数据可以包括图像数据等。第三数据可以由处理器模块12或外部设备输入gpu模块14。
在一个实施例中,处理器模块12包括cpu(中央处理器,centralprocessingunit)芯片单元,cpu芯片单元与第一ddr内存单元连接。在pcb电路板11上设置有xmc接口、usb接口、以太网接口、vga接口、音频接口、串行接口、pcie接口和光纤接口等多种接口,cpu芯片单元与xmc接口、usb接口、以太网接口、vga接口、音频接口、串行接口、pcie接口和光纤接口中的至少一个接口连接。
fpga模块13包括符合ultrascale架构的fpga芯片和第二ddr内存模块,fpga芯片与第二ddr内存模块连接。在pcb电路板11上设置有多个lvds接口和多个gth接口,fpga芯片分别与lvds接口和gth接口连接。fpga芯片设置有多个高速扩展卡接口以及调试jtag接口,fpga芯片通过调试jtag接口接收调试指令以及配置信息。
gpu模块14包括多个cuda处理核和第三ddr内存单元。gpu模块14通过cuda处理核并基于cuda架构下shiftandadd等算法对第三数据进行处理,获得第四图像数据,通过第三ddr内存单元缓存第三数据和第四数据。第三数据和第四数据为图像数据,gpu模块14能够进行加速处理等。gpu模块14还包括图像输出接口,gpu模块14可以通过图像输出接口向外部设备发送第四数据。
在一个实施例中,如图2所示,本公开的多功能业务板卡可以为6uvpx集成gpu板卡,板卡遵循vita65规范。多功能业务板卡集成符合xilinxultrascale架构的fpga芯片,集成intelxeond-1500系列服务器级cpu,可扩展1组gpu模块(为mxm,mobilepciexpressmodule模块)14,包括英伟达(nvidia)28nm工艺teslap6处理器模块和geforcegtx10系列(gtx1050ti/gtx1060/gtx1070)。
多功能业务板卡的实物如图3所示。多功能业务板卡为6uopenvpx规格的板卡,处理器模块12包括intelxeond-1500系列cpu芯片,第一ddr内存单元包括32gbddr4内存。gpu模块14包括1组teslap6图形处理器,teslap6图形处理器包括2048颗cudatm处理核;第三ddr内存单元包括16gbgddr5,支持ecc,内存宽度256-bit。
多功能业务板卡包括多种前面板接口,包括1个rj45千兆网口、2个usb2.0/3.0接口、1个显示接口、1xsfp+万兆网光口、复位按键等。多功能业务板卡包括vpx接口:1x8pciegen3@p2、1路千兆以太网(1000base-t)@p4、2xrs422@p4、8xgtx/gth@p5、16xlvds@p4。多功能业务板卡的其他参数包括:主供电:+12v;典型功耗:<100w;可提供常温(0-55℃);宽温(-40-70℃)版本;相对湿度0-95%;散热方式:风冷、导冷。
多功能业务板卡对外可以提供1组x8pcie接口,方便用户搭建高性能嵌入式计算系统(hpec),多功能业务板卡适用于雷达信号/图像处理,视频压缩/解压,图像增强,3d虚拟重构,360°情景识别,编码、解码和密码分析,情报监视和侦察等应用。
处理器模块12的cpu芯片采用intelxeond-1539处理器,intelxeond-1539处理器的参数包括:8核,1.6ghz主频,睿频2.1ghz;12mbcache;最大功耗35w;32gbddr4ecc内存;集成芯片组;1路sfp+万兆网口;24xpcie3.0,8xpcie2.0接口;2路usb2.0;2路sata3.0;支持windows7/8,linux等操作系统。intelxeond-1500处理器对外提供24组pcie3.0接口和8组pcie2.0接口,分别扩展xilinxfpga,nvme存储模块或gpu模块。
在一个实施例中,fpga芯片为xilinxfpga芯片。xilinxultrascale+fpga系列包括
在ultrascale系列的fpga芯片中,gc(globalclock)管脚取代了srcc和mrcc。ultrascale系列的fpga芯片的时钟区域共有6x6即36个,如果是7系列fpga,则是2x6即12个。ultrascale系列的fpga芯片不包含时钟缓冲器,其功能由新增的bufgce_div代替。
fpga模块13的fpga芯片采用基于xilinxultrascalekintex系列的fpga芯片,型号为xcku060-ffva1156-2-i,支持pciegen3x8,两组64-bitddr4,每组容量4gbyte,可稳定运行在2400mt/s,对外提供8xgth高速接口,以及16对lvds接口。板卡具有自控上电顺序,bpi模式快速程序加载,支持板内/板外两种系统时钟接入模式等特点。
fpga芯片xcku060的主要技术参数为:外挂两簇ddr4,数据位宽64-bit,每组容量4gbyte,可稳定运行在2400mt/s;外挂一片bpix16norflash,容量1gb,用于系统配置程序存储;外挂一片qspix4norflash,容量512mb,可用于参数存储;加载模式为bpi模式;外接两路qsfp+,支持40gbps传输速率;支持pciegen3x8模式,传输速率高可达5000mbyte/s;对外提供16对lvds接口;对外提供8xgth接口,传输速率可达13.6gbps等。
在一个实施例中,fpga芯片内部逻辑分为固定区和可重构区两部分,可重构区能够实现多种算法的重新配置,可以将不同的算法程序通过固定区下载到可重构区,实现不同的算法。如图4所示,fpga芯片内配置有虚拟接口模块131、虚拟任务分发模块132、虚拟数据处理模块133。虚拟接口模块131接收第一数据或外部设备发送的数据,将第一数据或外部设备发送的数据发送给虚拟任务分发模块132。虚拟任务分发模块132将第一数据或外部设备发送给对应的虚拟数据处理模块133。虚拟数据处理模块133对第一数据或外部设备发送的数据进行处理,获得第二数据并发给处理器模块12或外部设备。
在一个实施例中,gpu模块14包括具有特定宽温范围(-40℃至+85℃)的强固型mxm图形模块的6uvpxgpu板卡,gpu模块14同时提供可加强防尘、防潮、防腐蚀与抵抗化学物质溅入的敷形涂层服务,强化产品抵抗静电、防潮、防尘、抗腐蚀与各种环境污染的能力。
基于业界标准mxm(行动pciexpress模块)规范,6uvpxgpu板卡提供高速图形计算能力,其总线数据传输率符合pciexpress3.0,提供最高每秒8gigatransfers(gt/s)位传输率,适用于高性能需求与图像密集的嵌入式平台。如图5所示,相较于传统pciexpress显卡,6uvpxgpu板卡外型设计更为轻薄,能更紧密的嵌入于平台中,除节省系统空间外,于冲击或振动中仍保有稳定运作。
gpu模块的组成以及主要性能和参数为:6uopenvpxgpu处理板,符合vita46vpxvita65openvpx规范;2x8pcie2.0接口@vpxp2;2x8pcie2.0接口@vpxp5;预留4xdp/dvi-d接口@vpxp3;预留4xdp/dvi-d接口@vpxp6。
处理板包括1组nvidiateslap6mxm模块:gpu时钟为1012(最高1506)mhz;cudatm处理核为2048颗;浮点运算能力为6.16tflops(单精度);内存为16gbgddr5,支持ecc;内存宽度为256-bit;内存时钟为3003mhz;内存带宽为192.2gb/s。
处理板包括2组nvidiagtx1060mxm模块(可选):gpu时钟1404(最高1670)mhz;cuda处理核1280颗;浮点运算能力3.90tflops(单精度);内存6gbgddr5(6x256mx32);内存宽度192-bit;内存时钟4004mhz(8gbps);mxm3.1typeb外型。
处理板支持cuda9.0,directx12,opencl1.2;支持nvidiacuda技术;预留前出显示接口:2xdisplayport,2xvga;供电电压12v;最大功耗100w(2片);mtbf120000小时;工作温度范围-40-85℃,湿度10%到90%,无凝结;存储温度范围-45℃到85℃,湿度10%到90%,无凝结;操作系统支持windows,linux。
在一个实施例中,cuda(computeunifieddevicearchitecture,统一计算架构)是一种指令集架构(isa)以及并行计算引擎。cuda是建立在gpu基础之上的通用计算开发平台,是一个全新的软硬件架构,可以将gpu视为一个并行数据计算的设备,对所进行的计算进行分配和管理。利用cuda能够充分地将gpu的高计算能力开发出来,并使得gpu的计算能力获得更多的应用。
cuda的gpu编程语言基于标准的c语言,在cuda的架构下,一个程序分为两个部份:host端和device端。host端是指在cpu上执行的部份,而device端则是在显示芯片上执行的部份。device端的程序又称为"kernel"。通常host端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行device端程序,完成后再由host端程序将结果从显卡的内存中取回。
cuda允许定义称为内核(kernel)的c语言函数,从而扩展了c语言,在调用此类函数时,它将由n个不同的cuda线程并行执行n次,与普通的c语言函数只执行一次的方式不同。cuda的核心有三个重要抽象概念:线程层次结构、共享存储器、屏蔽同步,这些抽象提供了细粒度的数据并行化和线程并行化。在cuda架构下,显示芯片执行时的最小单位是thread。多个thread可以组成一个block。多个block可以组成一个grid。同一个grid中的block执行相同程序,不同的grid则可以执行不同的程序。线程层次结构如图6所示,block中的thread能存取同一块共享的内存,而且可以快速进行同步的动作。不同block中的thread无法存取同一个共享的内存,因此无法直接互通或进行同步。
cuda线程可在执行过程中访问多个存储器空间的数据,如图6所示,每个线程都有一个私有的本地存储器。每个block都有一个共享存储器,该存储器对于block内的所有线程都是可见的,并且与block具有相同的生命周期。同时,所有线程都可访问相同的全局存储器。在一个块内的某些线程访问共享或全局存储器中的相同地址时,部分访问操作可能存在写入后读取、读取后写入或写入后写入之类的风险。可通过在这些访问操作间同步线程来避免这些数据风险。很多应用领域需要强大的计算能力,gpu提供了一个可能性:在降低尺寸,重量和功耗的同时还能增加功能。在swap方面提供了一个数量级的改进,仅用10%swap就可以提供目前的功能或使用目前的swap可以增加目前功能的10倍。
在一个实施例中,多功能业务板卡设置有多种状态指示灯和电源单元,多种状态指示灯和电源单元16设置在pcb电路板11上,处理器模块12、gpu模块14和fpga模块13分别与对应的状态指示灯连接,处理器模块、gpu模块和fpga模块分别与电源单元16连接。
在一个实施例中,在提供6组led指示灯,led指示灯的位置功能表如下表1所示:
表1-led指示灯的位置功能表
在一个实施例中,后插卡模块,后插卡模块包括sata扩展接口、sata盘、显示接口、usb接口等。为了满足使用者对于多路接口接口的需求,为本公开的多功能业务板卡设计了配套的后插卡模块,例如为io插卡rtm-vpx6-g800。rtm-vpx6-g800是多功能业务板卡配套的后插卡模块,后插卡模块扩展可1个sata3.0接口,支持2.5inchsata盘,对外提供2路千兆以太网(1000base-t),提供1路hdmi显示接口和2路usb2.0/3.0接口。
在一个实施例中,如图7所示,后插卡模块的基本技术指标为:6uopenvpx规格(后出线);扩展2路1000base-t网口(rj45);扩展1路sata3.0接口,支持2.5inchsata盘扩展,存储容量1tb;提供1路hdmi显示接口;提供2路usb2.0/3.0接口;支持的操作系统:windows,linux,vxworks6.x;供电电压12v(+/-5%);功耗:10w;工作温度范围:-40-70℃;存储温度范围:-40℃~+85℃。
图8为本公开的数据处理方法的一个实施例的流程图,数据处理方法应用在如上实施例中的多功能业务板卡中,如图8所示:
s801,处理器模块接收到外部设备发送的处理命令和待处理数据,生成第一数据任务和第二数据处理任务。例如,待处理数据为3d点云信号以及周边图像数据等,处理命令包括信号分析命令、生成3d场景图像命令等。
s802,处理器模块基于第一数据任务并基于处理命令和待处理数据生成第一数据,将第一数据通过第一pcie信号线发送给fpga模块。例如,第一数据为3d点云信号。
s803,fpga模块对第一数据进行处理,获得第二数据并通过第一pcie信号线将第二数据发送给处理器模块。例如,第二数据为对3d点云信号的分析结果。
s804,处理器模块基于第二数据任务并基于处理命令、待处理数据以及第二数据生成第三数据,将第三数据通过第二pcie信号线发送给gpu模块。例如,第三数据为基于周边图像数据、3d点云信号的分析结果生成的3d场景图像数据。
s805,gpu模块对第三数据进行处理,生成第四数据并通过第二pcie信号线将第四数据发送给处理器模块。例如,第四数据为对3d场景图像数据的处理结果。
s806,cpu主机单元对进行第二数据和第四数据进行整合处理,将整合后的数据传输给外部设备。例如,整合后的数据为基于对3d点云信号的分析结果、对3d场景图像数据的处理结果生成的最终结果。
在一个实施例中,fpga接收外部设备发送的数据,对外部设备发送的数据进行处理,获得第二数据并发给处理器模块或此外部设备。在fpga芯片内设置有虚拟接口模块、虚拟任务分发模块、虚拟数据处理模块。虚拟接口模块接收第一数据或外部设备发送的数据,将第一数据或外部设备发送的数据发送给虚拟任务分发模块。虚拟任务分发模块将第一数据或外部设备发送给对应的虚拟数据处理模块。虚拟数据处理模块对第一数据或外部设备发送的数据进行处理,获得第二数据并发给处理器模块或外部设备。gpu模块对接收到的第三数据进行处理,获得第四数据并将第四数据发送给外部设备。
在一个实施例中,第一数据处理任务包括压缩或解压任务、信号分析任务、编码或解码任务等;第二数据任务包括图像处理任务、3d虚拟重构任务等;fpga模块对第一数据进行的处理包括压缩或解压处理、信号分析处理、编码或解码处理等;gpu模块对第三数据进行的处理包括图像处理、3d虚拟重构处理等。
处理器模块根据应用场景分配第一数据任务和第二数据处理任务,fpga模块和gpu模块分别执行不同的任务。处理器模块对数据处理进行控制,可以发挥fpga模块和gpu模块的并行处理能力,并且fpga具有良好的性能功耗比,能够适用于多种应用场景。
以上结合具体实施例描述了本公开的基本原理,但是,需要指出的是,在本公开中提及的优点、优势、效果等仅是示例而非限制,不能认为这些优点、优势以及效果等是本公开的各个实施例必须具备的。另外,上述公开的具体细节仅是为了示例的作用和便于理解的作用,而非限制,上述细节并不限制本公开为必须采用上述具体的细节来实现。
上述实施例中的多功能业务板卡以及数据处理方法,在pcb电路板上设置有处理器模块、gpu模块和fpga模块,fpga模块通过第一pcie信号线与处理器模块连接,处理器模块通过第二pcie信号线与gpu模块连接;处理器模块对数据处理进行控制,fpga模块和gpu模块分别执行不同的处理任务,可以发挥fpga模块和gpu模块的并行处理能力,并且fpga具有良好的性能功耗比;能够适用于多种应用场景,满足多任务处理需求,使系统的性能功耗较低,降低了任务调度处理的复杂度,提高了产品质量和可靠性。
可能以许多方式来实现本公开的方法和装置。例如,可通过软件、硬件、固件或者软件、硬件、固件的任何组合来实现本公开的方法和装置。用于所述方法的步骤的上述顺序仅是为了进行说明,本公开的方法的步骤不限于以上具体描述的顺序,除非以其它方式特别说明。此外,在一些实施例中,还可将本公开实施为记录在记录介质中的程序,这些程序包括用于实现根据本公开的方法的机器可读指令。因而,本公开还覆盖存储用于执行根据本公开的方法的程序的记录介质。
还需要指出的是,在本公开的装置、设备和方法中,各部件或各步骤是可以分解和/或重新组合的。这些分解和/或重新组合应视为本公开的等效方案。
提供所公开的方面的以上描述,以使本领域的任何技术人员能够做出或者使用本公开。对这些方面的各种修改等对于本领域技术人员而言,是非常显而易见的,并且在此定义的一般原理可以应用于其他方面,而不脱离本公开的范围。因此,本公开不意图被限制到在此示出的方面,而是按照与在此公开的原理和新颖的特征一致的最宽范围。
为了例示和描述的目的已经给出了以上描述。此外,此描述不意图将本公开的实施例限制到在此公开的形式中。尽管以上已经讨论了多个示例方面以及实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和子组合。
- 还没有人留言评论。精彩留言会获得点赞!