基于自组织图约束非负矩阵分解的未见图像特征迁移方法与流程
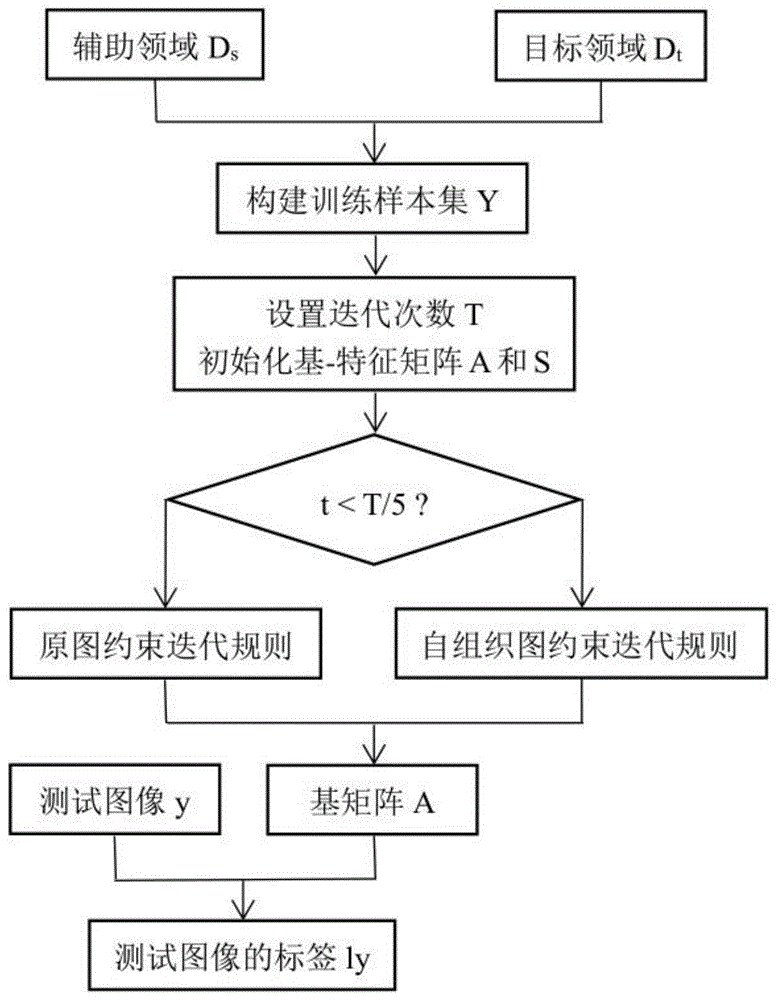
本发明属于图像处理
技术领域:
,涉及图像特征迁移学习方法,可用于图像非负特征提取与分析问题。
背景技术:
:非负矩阵分解是常见的图像特征提取方法,其通过将原始图像集矩阵分解为两个低秩的非负矩阵,得到图像集合的基矩阵和特征矩阵。由于非负矩阵分解能够描述图像的局部非负特征,其被广泛应用于各种数据特征提取与分析的任务中。随着数据规模的发展,不同领域的数据之间往往共享部分信息,提取跨领域的共享信息,用以提高目标领域的数据特征提取,是非负矩阵分解在跨领域特征迁移的研究重点。因此,基于非负矩阵分解的特征迁移是当前研究领域的一个热点研究问题。目前非负矩阵分解主要包括三种模型:无监督、有监督和半监督。其中,无监督模型不给定数据的标签信息,学习图像的表征;有监督则是引入标签信息,学习图像的判别特征;半监督则针对部分具有标签的数据进行特征学习。迁移非负矩阵分解方法由于辅助领域具有标签信息,属于半监督模型。通过将标记的辅助领域和无标记的目标领域进行结合,long等人提出了联合图正则化的矩阵分解方法进行迁移学习。该方法针对非负矩阵分解模型,同时引入特征的图约束和样例的图约束,解决迁移学习问题中的负迁移问题。但是该方法所使用的图结构来自对噪声敏感的图像原始空间,并非鲁棒性更强的特征空间,限制了特征迁移的性能。技术实现要素:本发明的目的在于针对上述已有技术在图像特征提取过程中存在的特征鲁棒性问题,提出一种基于自组织图约束直推式非负矩阵分解的未见图像特征迁移方法,一方面,特征空间自组织的图约束比原始空间计算得到的图结构鲁棒性更强,即特征学习和图学习同时进行;另一方面,分阶段的优化策略能加速迭代进程,降低次优结果的可能性。实现本发明的技术思路是:通过构建辅助领域和目标领域的图像样本集矩阵,其非负矩阵分解的结果应是具有结构化的特征表示和结构化的基矩阵。这种图约束的基矩阵和特征矩阵能够反映数据样本的本质特征。通过对特征之间的相似性关系约束基矩阵和特征矩阵,构建非负矩阵分解模型;迭代策略分为两个阶段:首先采用图像样本的图约束进行迭代;然后采用非负特征计算得到的图结构约束。最后,计算测试样本通过优化基矩阵的特征表示,得到该测试图像的标签。其具体步骤包括如下:(1)分别从辅助领域ds和目标领域dt选取若干图像样本构成训练样本集其中,d表示图像样本的维数,ns和nt分别表示从辅助领域和目标领域选取的训练样本个数;(2)根据辅助领域的图像样本ys和标注信息ls,初始化辅助领域和目标领域的基矩阵a和特征矩阵s,其中,c是辅助领域样本类别数,秩r=c;(3)初始化基矩阵图ga和特征矩阵图gs,用于循环迭代过程;(4)设置迭代次数t,使用迭代策略进行优化,得到优化的基矩阵a和特征矩阵s;(5)对于给定的测试图像通过基矩阵a,计算对应的标签ly。本发明相比现有技术具有以下优点:(1)本发明采用自组织图约束,提高了构建图的鲁棒性,实现了图学习和非负矩阵分解同时优化的目的,得到互优的结果;本发明在迭代过程中采用分阶段更新策略,构建了图像原始空间到特征空间的过渡过程,加快了迭代的进程,降低了次优结果的可能性。附图说明图1是本发明的总流程图图2是本发明仿真使用的extendedyaleb人脸图像数据集样例图图3是本发明仿真使用的coil20物体图像数据集样例图具体实施方式参照图1,本发明的具体实现步骤如下:步骤1,分别从辅助领域ds和目标领域dt选取若干图像样本构成训练样本集其中,d表示图像样本的维数,ns和nt分别表示从辅助领域和目标领域选取的训练样本个数。步骤2,根据辅助领域的图像样本ys和标注信息ls,初始化辅助领域和目标领域的基矩阵a和特征矩阵s,其中,c是辅助领域样本类别数,秩r=c。2a)基矩阵a采用随机的0-1之间的非负数进行初始化;2b)特征矩阵s的第1至n_s行用l_s初始化,第n_s至n_s+n_t行采用以下公式初始化:其中,max(0,*)表示取*和0之间较大的元素,(*)t表示矩阵的转置,(*)-1表示逆矩阵,i表示单位矩阵。步骤3,初始化基矩阵图ga和特征矩阵图gs,用于循环迭代过程,采用如下公式:其中,yi,:表示第i行,y:,i表示第i列,ω(*)表示*的k近邻,这里k∈{2,3,4,5}。步骤4,设置迭代次数t,使用迭代策略进行优化,得到优化的基矩阵a和特征矩阵s。4a)当迭代次数t<t5时,4b)当迭代次数t5≤t≤t时,其中,·表示矩阵点积操作,表示矩阵点除操作,ξ1,ξ2,ξ3∈(0,1)是设置的较小非负参数,对角矩阵wa和ws分别是ga和gs的度矩阵。步骤5,对于给定的测试图像通过基矩阵a,计算对应的标签ly:本发明的效果可以通过下面的仿真结果进一步说明:1.仿真条件本发明对2个图像数据集,extendedyaleb人脸数据集和coil20物体图像数据集进行测试,其中extendedyaleb有38个类别,coil20有20个类别。实验采用软件matlabr2019a作为仿真工具,计算机配置为intelcorei5-9600kf/3.7ghz/32g。2.仿真方法选择传统非负矩阵分解、正交非负矩阵分解、投影非负矩阵分解和图约束非负矩阵分解与本发明的结果进行比较,以验证本发明的有效性。四个代表性方法分别为:方法1,是lee等人提出的方法,具体参考文献“learningthepartsofobjectswithnonnegativematrixfactorization[j].nature,1999,401(6755):788-791.”。方法2,是kimura等人提出的方法,具体参考文献“afasthierarchicalalternatingleastsquaresalgorithmfororthogonalnonnegativematrixfactorization[j].journalofmachinelearningresearch,2014,39:129-141.”。方法3,是yang等人提出的方法,具体参考文献“linearandnonlinearprojectivenonnegativematrixfactorization[j].ieeetransactionsonneuralnetworks,2010,21(5):734-749.”。方法4,是cai等人提出的方法,具体参考文献“graphregularizednon-negativematrixfactorizationfordatarepresentation[j].ieeetransactionsonpatternanalysisandmachineintelligence,2011,33(8):1548-1560.”。3.仿真内容仿真1,从附图2所示的extendedyaleb图像集中,每个类别选择前50%作为辅助领域,即有标签的样本集,剩下50%的前50%作为目标领域,即无标签的训练样本集,后50%作为未参与训练的未见图像,使用方法1-4和本发明对未见图像进行测试,得到测试的未见图像标签。仿真2,从附图3所示的coil20图像集中,每个类别选择前50%样本作为辅助领域,即有标签的样本集,剩下50%样本的前50%作为目标领域,即无标签的训练样本集,后50%作为未参与训练的未见图像,使用方法1-4和本发明对未见图像进行测试,得到测试的未见图像标签。本发明采用的评价指标为标签的分类正确率,即测试图像正确分类数目与测试图像总数目的比值。分类正确率越高,则特征提取的性能越好。表1是2个图像数据集不同方法的分类正确率。表1不同方法在extendedyaleb和coil20图像数据集的分类正确率图像数据集方法1方法2方法3方法4本发明extendedyaleb33.39%34.87%35.20%34.21%37.83%coil2076.39%78.33%76.94%81.11%85.83%从表1可见,本发明在2个图像数据集上对未参与训练的图像分类正确率最高,比方法1分别高出4.5%和9.5%,比方法2高出3%和7.5%,比方法3高出2.5%和9%,比方法4高出3.5%和4.5%。综上,本发明相比于常见的非负矩阵分解方法,具有较好的特征提取能力,通过自组织图约束基矩阵和特征矩阵,得到更鲁棒的图结构,分阶段的迭代策略则加速了迭代进程,适合图像鲁棒特征迁移学习问题。虽然以上将实施例分开说明和阐述,但涉及部分共通之技术,在本领域普通技术人员看来,可以在实施例之间进行替换和整合,涉及其中一个实施例未明确记载的内容,则可参考有记载的另一个实施例。以上仅就本发明较佳的实施例作了说明,但不能理解为是对权利要求的限制。本发明不仅局限于以上实施例,其具体结构允许有变化。总之,凡在本发明独立权利要求的保护范围内所作的各种变化均在本发明的保护范围内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1