一种深度Transformer级联神经网络模型压缩算法的制作方法
一种深度transformer级联神经网络模型压缩算法
技术领域
[0001]
本发明涉及自然语言处理领域领域,具体涉及一种深度transformer级联神经网络模型压缩算法。
背景技术:
[0002]
近年来,随着深度学习在图像领域获得了较大成功,其在自然语言处理领域也取得了突破性进展。基于深度transformer的级联神经网络在自然语言处理新范式,即自监督预训练加有监督微调中得到了不错的性能并不断刷新glue榜单记录,成为了自然语言处理领域新的研究热点之一。bert作为经典模型之一在基于文本的用户画像、情感分析和舆情分析中都有着广泛的应用前景。但是,此类模型往往体积较大,参数量多达数百万甚至数十亿导致在推理阶段内存占用和延时都较高,同时增加了生产环境的硬件部署和能耗成本。这些问题都极大地限制了此类模型的广泛使用,尤其是在智能移动端设备上。因此,如何高效地压缩深度transformer级联神经网络成为了当下面临的一个问题。
[0003]
为了精炼模型,科研人员针对此问题展开了研究,sanh v等[1]提出distilbert算法。该算法在预训练阶段对bert模型进行压缩,将bert模型中的12层编码器压缩至6层。jiao等[2]提出了tinybert算法,将模型压缩过程分别运用在预训练和微调阶段,在减少编码器层级数的同时对编码器维度进行压缩。然而,上述压缩算法的实现要涉及模型预训练阶段,这会导致算法运行的时间成本较高、结果难以复现等问题。之后,canwen xu等[3]提出bert-of-theseus算法,该算法仅在微调阶段采用逐步替换bert编码器层模块的方法对bert模型进行压缩,有效地降低计算复杂度。但是,从压缩模型体积角度出发,bert-of-theseus算法仍有进一步提升空间。
技术实现要素:
[0004]
鉴于此,本发明的目的在于克服现有技术的不足,提供一种深度transformer级联神经网络模型压缩算法,进一步提升模型压缩效率。
[0005]
为实现以上目的,本发明采用如下技术方案:
[0006]
一种深度transformer级联神经网络模型压缩算法,包括以下步骤:
[0007]
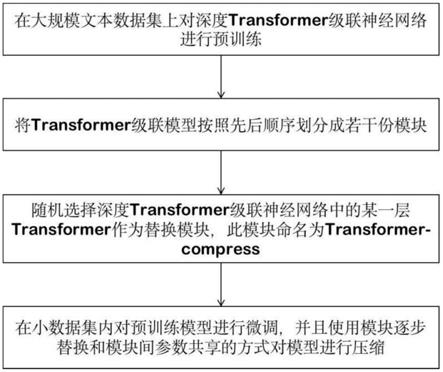
步骤a:在文本数据集上对深度transformer级联神经网络进行预训练;
[0008]
步骤b:将transformer级联模型按照先后顺序划分成若干份模块;
[0009]
步骤c:随机选择预训练完成的深度transformer级联神经网络中的某一层transformer作为替换模块,此模块命名为transformer-compress;
[0010]
步骤d:在小数据集内对预训练模型进行微调,并且使用模块逐步替换和模块间参数共享的方式对模型进行压缩。
[0011]
在上述的一种深度transformer级联神经网络模型压缩算法中,在步骤a中的预训练具体为在无标签文本数据集上对深度transformer级联神经网络模型进行自监督预训练,训练任务为遮掩词预测和前后文本预测,通过反向传播算法和梯度下降算法对所述模
型进行参数更新,并得到预训练模型。
[0012]
在上述的一种深度transformer级联神经网络模型压缩算法中,在步骤b中,按照模块间均等划分的原则对transformer级联神经网络进行划分。
[0013]
在上述的一种深度transformer级联神经网络模型压缩算法中,在步骤d中,在微调前半阶段,原先网络模型划分完成的模块分别以一定概率被替换成transformer-compress模块,在微调后半阶段,原先网络模型划分完成的模块全部被替换成transformer-compress模块。
[0014]
在上述的一种深度transformer级联神经网络模型压缩算法中,在步骤d中,不同位置的transformer-compress模块之间参数共享。
[0015]
本发明与现有技术方案相比具有下述优点:模型压缩计算执行过程仅出现在微调阶段,计算量较低;压缩后模型采用模块间参数共享方式减小了模型体积;仅需要通过调整模块划分结果就可以实现对模型压缩比的控制。
附图说明
[0016]
附图1为本发明实施例的深度transformer级联神经网络模型压缩流程示意图;
[0017]
附图2为本发明实施例的深度transformer级联神经网络模块划分结果;
[0018]
附图3为本发明实施例的深度transformer级联神经网络模块替换示意图;
[0019]
附图4为本发明实施例的深度transformer级联神经网络模型压缩结果示意图。
具体实施方式
[0020]
以下采用本发明的优选实施例并结合附图,对本发明的技术方案作进一步的描述,但本发明并不限于这些实施例。
[0021]
参见附图1,本发明一实施例提供的一种深度transformer级联神经网络模型压缩算法,包括:
[0022]
步骤a:在文本数据集上对深度transformer级联神经网络进行预训练,该预训练具体为在无标签文本数据集上对深度transformer级联神经网络模型进行自监督预训练,训练任务为遮掩词预测和前后文本预测,通过反向传播算法和梯度下降算法对所述模型进行参数更新,并得到预训练模型。
[0023]
步骤b:将transformer级联模型按照先后顺序划分成若干份模块。
[0024]
作为优选地,按照模块间均等划分的原则对transformer级联神经网络进行划分,划分结果如图2所示。
[0025]
步骤c:随机选择预训练完成的深度transformer级联神经网络中的某一层transformer作为替换模块,此模块命名为transformer-compress;
[0026]
步骤d:在小数据集内对预训练模型进行微调,并且使用模块逐步替换和模块间参数共享的方式对模型进行压缩。模块替换示意图如图3所示。在步骤d中,在微调前半阶段,原先网络模型划分完成的模块分别以一定概率被替换成transformer-compress模块,在微调后半阶段,原先网络模型划分完成的模块全部被替换成transformer-compress模块,在步骤d中,不同位置的transformer-compress模块之间参数共享。
[0027]
在所述步骤a中,所述对深度transformer级联神经网络模型进行预训练具体为:
在大规模无标签文本数据集上对深度transformer级联神经网络模型进行自监督预训练,训练任务为遮掩词预测和前后文本预测。通过反向传播算法和梯度下降算法对所述模型进行参数更新,并得到预训练模型。由于预训练阶段所需计算量较大,一般实验室硬件条件无法在短期内完成,因此,我们通常选用开源的预训练模型文件。
[0028]
进一步地,在所述步骤b中,所述对transformer级联模型按照先后顺序划分成若干份模块具体为:一般是按照模块间均等划分的原则对级联神经网络进行划分。
[0029]
作为优选地,在所述步骤d中,所述以模块逐步替换和模块间参数共享的方式进行模型压缩具体包括:在微调前半阶段,原先网络模型划分完成的模块分别以一定概率被替换成transformer-compress模块,且不同位置的transformer-compress模块之间参数共享;在微调后半阶段,原先网络模型划分完成的模块全部被替换成transformer-compress模块,且不同位置的transformer-compress模块之间参数共享,以此完成模型压缩.
[0030]
在步骤d中,对使用模块逐步替换和模块间参数共享的方式对模型进行压缩具体为:在微调前半阶段,原先网络模型划分完成的模块分别按照50%的概率被替换成transformer-compress模块。在微调后半阶段,则原先网络模型划分完成的模块全部被替换成transformer-compress模块。并且,不同位置的transformer-compress模块之间参数共享,以此实现从模型结构和参数数量两个角度对模型进行压缩。模型压缩后网络结构如图4所示。
[0031]
为了证明本发明的可行性,我们利用收集得到的文本数据集进行验证。该数据集为社交电商公开文本数据集,并根据社交电商售卖商品属性的不同将其分为20类,共计38975条。此外,选用bert、bert-of-theseus模型进行比较。结果如下表所示。
[0032][0033][0034]
结果表明在准确率方面,本文算法相比于bert下降2.0%,相比于bert-of-theseus下降1.6%。准确率损失在可接受范围内。模型压缩比方面,本文算法将原先bert大小从409.2mb压缩至97.3mb,模型压缩比为23.8%,相比于bert-of-theseus压缩比提高34.6%。
[0035]
由此可见,本文压缩算法在准确率和压缩比方面都具有很大优势,在准确率仅降低2.0%的前提下模型大小从原先409.2mb压缩至100mb以内。这不仅提可以升了bert在服务器端的运行效率,也使得bert部署在智能移动端成为可能。
[0036]
以上所述,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以所述权利要求的保护范围为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1