一种简历批量归档方法与流程
本发明涉及简历批量处理技术领域,尤其涉及一种简历批量归档方法。
背景技术:
目前求职市场上简历投递者的的简历的命名格式不尽规范,各招聘平台生成的简历命名的格式不统一,导致用人企业的招聘人员要对收到的简历进行统一的规范化归档,需要按一定规则重新命名简历,但是招聘人员进行统一的规范化归档过程中,会出现各种各样的错误,例如出现手工输入的时候出现各种小错误,例如出现错别字、多加、漏加文字的情况,如果出现张冠李戴的情况,则可能会造成发出错误的招聘面试通知,给招聘工作带来严重的失误,而当前企业的招聘人员均依赖于招聘人员手动重命名文件,效率低下且易出错,目前软件市场上并未出现简历批量归档软件,而本发明提出的简历批量归档方法,能够大幅提高招聘人员管理简历的能力和效率,并且最大限度地减少了简历批量归档过程中可能产生的错误。
技术实现要素:
本发明的目的是针对上述问题,提供一种简历批量归档方法。
为了达到上述目的,本发明采用了以下技术方案:
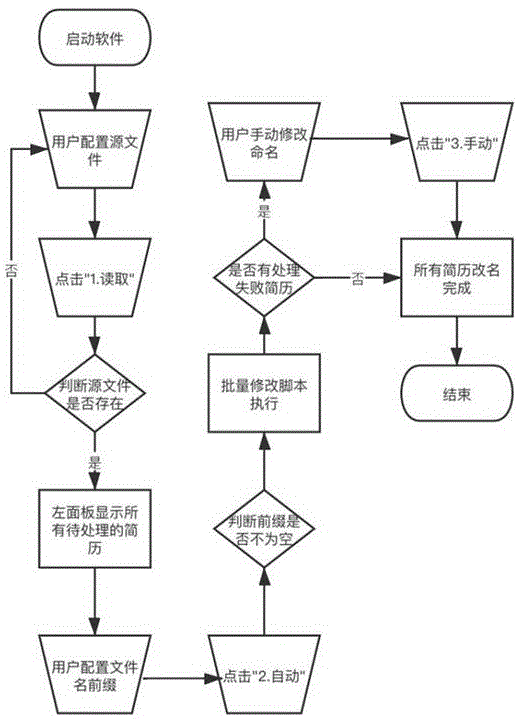
一种简历批量归档方法,包括配置简历、执行程序、异常状况处理、检查结果,软件启动后,配置简历完成后,开始执行程序,正式进行文件遍历和批量归档,批量归档简历的过程中,如果出现未能识别的人名或者重名的情况,则需要进行异常状况处理,异常状况处理完毕后,由人工检查是否所有简历均按照规定的命名格式归档完毕,当出现特殊人名时,则需要进行人名优化配置,使软件在完成配置后,下次运行遇到相同人名时,无需再进行手动更改。
在上述的简历批量归档方法中,所述配置简历包括用户配置需要批量归档的简历、加载初始资源和用户配置修改内容,用户将需要批量归档的简历粘贴到软件根目录下的“源文件目录”文件夹中,无文件数量和格式限制,支持粘贴复数和多层级文件夹。
在上述的简历批量归档方法中,所述加载初始资源是使用file.listfiles()获取文件夹下所有文件,根据file.isdirectory()判断文件是否为文件夹,是的话通过file.listfiles()进行递归读取,以取出源文件夹中所有的文件。
在上述的简历批量归档方法中,所述用户配置修改内容是配置处理后的文件的命名格式,将此命名文字赋值为静态变量,以便于后续高效处理文件。
在上述的简历批量归档方法中,所述执行程序开始后,执行处理程序,轮询并批量修改已配置完毕的所有简历,将所有源文件命名添加到list集合。
在上述的简历批量归档方法中,所述异常状况处理包括处理遍历到未能识别的人名和处理重名情况,未能识别的人名包括生僻姓氏、少数名族人名或外国人名,在软件根目录下的“人名词典.txt”文件中添加所述未能识别的人名,修改保存后下次运行软件处理到相同单词,无需再手动更改。
在上述的简历批量归档方法中,所述处理重名情况是遍历到所需批量处理的简历出现重名情况时,则输出到根目录下的“生成文件目录”中,,再次重名的文件名会以“-重名”结尾,多次重名则追加重复次数。
附图说明
图1是简历批量处理流程图示意图。
具体实施方式
如图1所示,一种简历批量归档方法,包括配置简历、执行程序、异常状况处理、检查结果,软件启动后,配置简历完成后,开始执行程序,正式进行文件遍历和批量归档,批量归档简历的过程中,如果出现未能识别的人名或者重名的情况,则需要进行异常状况处理,异常状况处理完毕后,由人工检查是否所有简历均按照规定的命名格式归档完毕,当出现特殊人名时,则需要进行人名优化配置,使软件在完成配置后,下次运行遇到相同人名时,无需再进行手动更改,从而大大减轻了简历批量归档过程的的工作量,提高了招聘工作的效率和准确性,避免了因人为因素导致了简历批量归档过程中产生的错误。
本发明涉及的简历批量归档方法,配置简历包括用户配置需要批量归档的简历、加载初始资源和用户配置修改内容。
用户配置需要批量处理的简历,用户将需要批量处理的简历粘贴到软件根目录下的“源文件目录”文件夹中,需要批量处理的简历没有文件数量和格式的要求,支持粘贴复制和多层级文件夹。
加载初始资源使用file.listfiles()获取文件夹下所有文件,根据file.isdirectory()判断文件是否为文件夹,是的话通过file.listfiles()进行递归读取,取出源文件夹中所有的文件。
用户配置修改内容:将统一的文件名前缀输入到软件面板的顶部输入框,代码中将此命名文字赋值为静态变量,以便于后续高效处理文件。
用户配置需要批量处理的简历后,开始正式进行文件遍历和处理,将所有源文件命名添加到list集合,使用hanlp框架list<term>seg=hanlp.newsegment().enablenamerecognize(true).segment.seg(prename)进行语义识别,获取到所有文件中的单词对象term;遍历判断term对象的词性"nr".equals(term.nature.tostring()),如果为名词nr,则取出此term对象的人名字符串stringname=term.word。最后通过字节流io操作完成源文件的重命名和剪切操作。
异常状况处理包括处理遍历到未能识别的人名和处理重名情况,当出现未识别的人名时,如“丹尼斯”“詹姆斯”等,可以在项目根目录下的“人名词典.txt”文件中添加一行配置,完成配置后下次运行软件处理到相同单词,无需再手动更改;如果存在重名情况,则输出文件中,再次重名的文件名会以”-重名“结尾,多次重名则追加重复次数,如“-重名2”。
以上步骤完成后,检查简历批量归档结果,打开软件根目录下的“生成文件目录”文件夹,所有文件已完成规范化命名且移动到此文件夹下,此步骤是人工进行的。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
技术特征:
1.一种简历批量归档方法,其特征在于,包括配置简历、执行程序、异常状况处理、检查结果,软件启动后,配置简历完成后,开始执行程序,正式进行文件遍历和批量归档,批量归档简历的过程中,如果出现未能识别的人名或者重名的情况,则需要进行异常状况处理,异常状况处理完毕后,由人工检查是否所有简历均按照规定的命名格式归档完毕,当出现特殊人名时,则需要进行人名优化配置,使软件在完成配置后,下次运行遇到相同人名时,无需再进行手动更改。
2.根据权利要求1所述的简历批量归档方法,其特征在于,所述配置简历包括用户配置需要批量归档的简历、加载初始资源和用户配置修改内容,用户将需要批量归档的简历粘贴到软件根目录下的“源文件目录”文件夹中,无文件数量和格式限制,支持粘贴复数和多层级文件夹。
3.根据权利要求2所述的简历批量归档方法,其特征在于,所述加载初始资源是使用file.listfiles()获取文件夹下所有文件,根据file.isdirectory()判断文件是否为文件夹,是的话通过file.listfiles()进行递归读取,以取出源文件夹中所有的文件。
4.根据权利要求2所述的简历批量归档方法,其特征在于,所述用户配置修改内容是配置处理后的文件的命名格式,将此命名文字赋值为静态变量,以便于后续高效处理文件。
5.根据权利要求1所述的简历批量归档方法,其特征在于,所述执行程序开始后,执行处理程序,轮询并批量修改已配置完毕的所有简历,将所有源文件命名添加到list集合。
6.根据权利要求1所述的简历批量归档方法,其特征在于,所述异常状况处理包括处理遍历到未能识别的人名和处理重名情况,未能识别的人名包括生僻姓氏、少数名族人名或外国人名,在软件根目录下的“人名词典.txt”文件中添加所述未能识别的人名,修改保存后下次运行软件处理到相同单词,无需再手动更改。
7.根据权利要求6所述的简历批量归档方法,其特征在于,所述处理重名情况是遍历到所需批量处理的简历出现重名情况时,则输出到根目录下的“生成文件目录”中,再次重名的文件名会以“-重名”结尾,多次重名则追加重复次数。
技术总结
本发明提供了一种简历批量归档方法,属于简历归档技术领域。本发明涉及的简历批量归档方法,包括配置简历、执行程序、异常状况处理、检查结果,软件启动后,配置简历完成后,开始执行程序,正式进行文件遍历和批量归档,批量归档简历的过程中,如果出现未能识别的人名或者重名的情况,则需要进行异常状况处理,异常状况处理完毕后,由人工检查是否所有简历均按照规定的命名格式归档完毕,当出现特殊人名时,则需要进行人名优化配置,使软件在完成配置后,下次运行遇到相同人名时,无需再进行手动更改。本发明涉及的简历批量归档方法,相比于传统的简历需要人工归档,具有效率大大提高,且不会出现错别字、多加或漏加文字等情况,稳定性高等优点。
技术研发人员:魏鹏
受保护的技术使用者:杭州冒险元素网络技术有限公司
技术研发日:2020.10.27
技术公布日:2021.01.15
- 还没有人留言评论。精彩留言会获得点赞!