一种对象存储系统中数据的聚合方法及系统与流程
本发明涉及服务器存储领域,具体涉及一种对象存储系统中数据的聚合方法及系统。
背景技术:
小文件在as13000上存储是按照一个对象进行存储的,即每个小文件会占一个对象,百亿文件会在集群中百亿的底层存储对象,而在磁盘故障等需要数据重构时是按照对象的粒度读取进行数据恢复的,磁盘故障的数据恢复就是一个灾难(瓶颈在磁盘io(输入输出)),在实际测试过程中,在有一亿小文件对象的存储场景中,一个osd(objectstoragedevice,对象存储设备)故障恢复需要耗时一两个小时,磁盘故障恢复耗时较长。
为此,本发明提供一种对象存储系统中数据的聚合方法及系统,用于解决上述问题。
技术实现要素:
针对现有技术的上述不足,本发明提供一种对象存储系统中数据的聚合方法及系统,用于减少对象存储系统在磁盘故障恢复的耗时。
本发明提供一种对象存储系统中数据的聚合方法,包括步骤:
s1:扫描对象存储系统存储池的热池中的小文件并加入小文件聚合队列;
s2:从小文件聚合队列中获取需要聚合的小文件;
s3:获取所述需要聚合的小文件的内容,加入大文件聚合缓存区形成一个聚合大文件;
s4:将所述聚合大文件的内容下刷到对象存储系统的存储池的冷池,将所述聚合大文件的元数据下刷到热池。
进一步地,该聚合方法在步骤s1之前,还包括步骤s0:
开启分级功能,上传文件时,判断文件是否是小文件:
若是,则将其存入到热池,并在index池索引表记录该文件的存储位置;
若否,则将其存入冷池,并在index池索引表记录该文件的存储位置。
进一步地,步骤s1包括:
遍历index池索引表,获取遍历到的存储位置在热池的文件为小文件,并将获取到的各小文件加入到小文件聚合队列。
进一步地,步骤s3包括:
申请聚合缓存数据区和聚合缓存元数据区,遍历聚合小文件队列,读取聚合小文件队列中的小文件的内容加入到聚合缓存数据区,并将读取到的小文件的元数据信息记录到聚合缓存元数据区。
进一步地,步骤s4包括:
每次在聚合缓存数据区写满时,停止读取聚合小文件队列中小文件的内容,将聚合缓存数据区内容下刷到冷池,将聚合缓存元数据区中存储的元数据信息下刷到热池,并修改当前次下刷内容到冷池的小文件在index池索引表中的标记为已聚合。
第二方面,本发明提供一种对象存储系统中数据的聚合系统,包括:
扫描线程,用于扫描对象存储系统存储池的热池中的小文件并加入小文件聚合队列;
第一聚合线程,用于从小文件聚合队列中获取需要聚合的小文件;
第二聚合线程,用于获取所述需要聚合的小文件的内容,加入大文件聚合缓存区形成一个聚合大文件;
第三聚合线程,用于将所述聚合大文件的内容下刷到对象存储系统的存储池的冷池,将所述聚合大文件的元数据下刷到热池。
进一步地,该聚合系统还包括:
对象写入线程,用于开启分级功能,用于在上传文件时,判断文件是否是小文件,并在判定为是时,将其存入到热池,在判定为否时,将其存入到冷池,并在index池索引表记录该文件的存储位置。
进一步地,扫描线程的实现方法为:
遍历index池索引表,获取遍历到的存储位置在热池的文件为小文件,并将获取到的各小文件加入到小文件聚合队列。
进一步地,第二聚合线程的实现方法为包括:
申请聚合缓存数据区和聚合缓存元数据区,遍历聚合小文件队列,读取聚合小文件队列中的小文件的内容加入到聚合缓存数据区,并将读取到的小文件的元数据信息记录到聚合缓存元数据区。
进一步地,第三聚合线程的实现方法为包括:
每次在聚合缓存数据区写满时,停止读取聚合小文件队列中小文件的内容,将聚合缓存数据区内容下刷到冷池,将聚合缓存元数据区中存储的元数据信息下刷到热池,并修改当前次下刷内容到冷池的小文件在index池索引表中的标记为已聚合。
本发明的有益效果在于,
本发明提供的对象存储系统中数据的聚合方法及系统,能够将很多个小文件聚合为聚合大文件,使得对象存储系统在存储总容量相同的前提下,存储对象的个数减少了,从而有助于减少对象存储系统在磁盘故障恢复的耗时,有助于提高对象存储系统故障时数据恢复的时间,从而有助于解决对象存储系统中磁盘osd恢复性能慢的问题,继而有助于提高分布式存储产品的市场竞争力。
此外,本发明设计原理可靠,结构简单,具有非常广泛的应用前景。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明一个实施例的方法的示意性流程图。
图2是本发明一个实施例的系统的示意性框图。
具体实施方式
为了使本技术领域的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
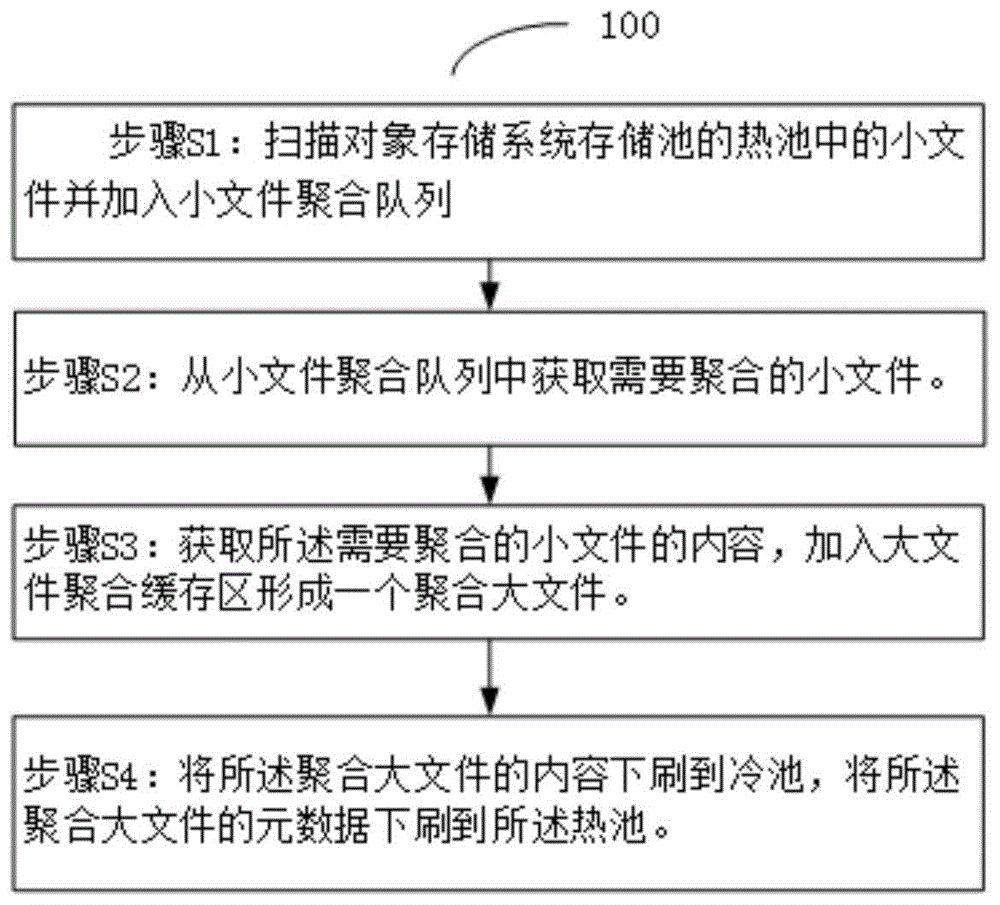
图1是本发明一实施例的对象存储系统中数据的聚合方法的示意性流程图。
在本实施例中,所述对象存储系统的存储池配设有热池和冷池,其中,热池为创建在ssd上的存储池,冷池为创建在hdd上的存储池。
本说明书中的小文件为小于512k的文件。
如图1所示,该聚合方法100包括:
步骤s1:扫描对象存储系统存储池的热池中的小文件并加入小文件聚合队列。
具体地,该聚合方法100在步骤s1之前,还可包括步骤s0:
开启分级功能,上传文件时,判断文件是否是小文件:
若是,则将其存入到热池,并在index池索引表记录该文件的存储位置;
若否,则将其存入冷池,并在index池索引表记录该文件的存储位置。
具体地,该步骤s1的实现方法为:
遍历index池索引表,获取遍历到的存储位置在热池的文件为小文件,并将获取到的各小文件加入到小文件聚合队列。
步骤s2:从小文件聚合队列中获取需要聚合的小文件。
步骤s3:获取所述需要聚合的小文件的内容,加入大文件聚合缓存区形成一个聚合大文件。
步骤s4:将所述聚合大文件的内容下刷到冷池,将所述聚合大文件的元数据下刷到所述热池。
可选地,作为本发明的一个实施例,步骤s3的实现方法为:申请聚合缓存数据区和聚合缓存元数据区,遍历聚合小文件队列,读取聚合小文件队列中的小文件的内容加入到聚合缓存数据区,并将读取到的小文件的元数据信息记录到聚合缓存元数据区。
可选地,作为本发明的一个实施例,步骤s4的实现方法为:每次在聚合缓存数据区写满时,停止读取聚合小文件队列中小文件的内容,将聚合缓存数据区内容下刷到冷池,将聚合缓存元数据区中存储的元数据信息下刷到热池,并修改当前次下刷内容到冷池的小文件在index池索引表中的标记为已聚合。
可见本方法100能够将很多个小文件聚合为聚合大文件,减少了存储系统中存储的对象个数,在故障恢复时直接恢复大文件,可以减少恢复的文件个数,可见在存储系统总容量不变的前提下,有助于提高了存储系统的数据恢复的速度。
图2为本发明提供的对象存储系统中数据的聚合系统的一个实施例。
参见图2,该聚合系统200包括:
扫描线程201,用于扫描对象存储系统存储池的热池中的小文件并加入小文件聚合队列;
第一聚合线程202,用于从小文件聚合队列中获取需要聚合的小文件;
第二聚合线程203,用于获取所述需要聚合的小文件的内容,加入大文件聚合缓存区形成一个聚合大文件;
第三聚合线程204,用于将所述聚合大文件的内容下刷到冷池,将所述聚合大文件的元数据下刷到热池。
可选地,作为本发明的一个实施例,该聚合系统还包括:
对象写入线程205,用于开启分级功能,用于在上传文件时,判断文件是否是小文件,并在判定为是时,将其存入到热池,在判定为否时,将其存入到冷池,并在index池索引表记录该文件的存储位置。
可选地,作为本发明的一个实施例,扫描线程201的实现方法为:遍历index池索引表,获取遍历到的存储位置在热池的文件为小文件,并将获取到的各小文件加入到小文件聚合队列。
可选地,作为本发明的一个实施例,第二聚合线程203的实现方法为包括:申请聚合缓存数据区和聚合缓存元数据区,遍历聚合小文件队列,读取聚合小文件队列中的小文件的内容加入到聚合缓存数据区,并将读取到的小文件的元数据信息记录到聚合缓存元数据区。
可选地,作为本发明的一个实施例,第三聚合线程204的实现方法为:每次在聚合缓存数据区写满时,停止读取聚合小文件队列中小文件的内容,将聚合缓存数据区内容下刷到冷池,将聚合缓存元数据区中存储的元数据信息下刷到热池,并修改当前次下刷内容到冷池的小文件在index池索引表中的标记为已聚合。
本说明书中各个实施例之间相同相似的部分互相参见即可。
尽管通过参考附图并结合优选实施例的方式对本发明进行了详细描述,但本发明并不限于此。在不脱离本发明的精神和实质的前提下,本领域普通技术人员可以对本发明的实施例进行各种等效的修改或替换,而这些修改或替换都应在本发明的涵盖范围内/任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应所述以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!