一种基于自适应候选视差预测网络的实时双目立体匹配方法与流程
[0001]
本发明属于计算机视觉技术领域,具体涉及一种基于自适应候选视差预测网络的实时双目立体匹配方法。
背景技术:
[0002]
双目立体视觉系统在机器人导航、智能监控、自动驾驶等应用领域有着广泛的应用。因此,准确,快速的双目立体匹配对于立体视觉系统在移动设备的实时部署具有重要意义。近年来,基于深度学习技术的双目立体匹配得益于神经网络模型的不断创新,其算法的处理精度显著提升。但是,当前的高精度立体匹配网络通常需要占用大量的内存和计算资源,这使得已有方法难以在资源受限的移动平台上应用。
[0003]
端到端双目立体匹配网络主要包括特征提取、聚合代价量构建、匹配代价聚合以及视差回归/优化等步骤。其中,匹配代价聚合步骤对模型的计算速度和资源耗费起着决定性作用,因此对该步骤的合理优化成为网络轻量化设计的关键。当前,已有方法主要采用由粗到精(coarse-to-fine)的视差估计策略来大幅降低代价聚合步骤的计算复杂度。具体地,该方法首先在小分辨率下进行全视差范围搜索得到粗视差估计结果,然后逐级上采样,并在大分辨率下用极少数的视差偏移量对粗估计视差进行精细化修正,因此计算速度显著提高。然而,已有方法均采用固定偏移量的方式为精细估计阶段提供候选视差,该方式将候选值限制在粗视差估计结果的局部小范围内,从而导致视差修正难以满足不同场景中不同目标的实际需求,因此已有方法的视差图质量相对较差。此外,为了一定程度提高估计结果,已有由粗到精方法通常采用多阶段(一般≥3级)处理来得到更准确的视差。但是,随着操作级数的增加,计算速度会显著降低。综上所述,已有采用由粗到精策略的轻量化双目立体匹配网络在计算精度和速度等方面仍难以满足移动设备对立体视觉的实时性要求。
技术实现要素:
[0004]
本发明的目的在于提出一种基于自适应候选视差预测网络的实时双目立体匹配方法,以克服现有技术的缺点。本发明利用粗视差估计结果和原始图像信息为每一像素动态预测精细估计阶段所需的视差偏移量,从而适应不同目标物体对视差校正范围的差异化需求。并且,由于该方法的有效性,本发明设计了一种两级处理结构以提升双目立体匹配网络的计算精度和速度。
[0005]
为达到上述目的,本发明采用如下技术方案来实现:
[0006]
一种基于自适应候选视差预测网络的实时双目立体匹配方法,该方法包括:
[0007]
首先利用二维卷积对校正后的立体图像对进行多尺度特征提取,得到高、低分辨率的特征图;然后,在第一阶段中,在低分辨率特征图下进行视差粗估计;随后利用粗估计视差图和左图进行动态偏移量预测,该偏移量与粗估计结果相加生成自适应候选视差;第二阶段视差估计利用自适应候选视差和高分辨率特征图构建紧凑匹配代价量,该代价量通过正则化之后进行视差回归得到精细估计视差;最后,视差精修模块对精细视差图进行层
次化上采样,得到全尺寸视差图。
[0008]
本发明进一步的改进在于,特征提取时,首先用一系列二维卷积将输入原图逐级下采样到1/2、1/4、1/8和1/16,然后对1/4和1/16特征进行更深层次的特征提取。
[0009]
本发明进一步的改进在于,第一阶段视差估计,利用特征提取的1/16特征图进行错位拼接,得到完整匹配代价量;通过堆叠的三维卷积对代价量进行正则化处理,得到聚合后的匹配代价量,对该代价量进行回归得到粗估计视差图。
[0010]
本发明进一步的改进在于,动态偏移量预测dop根据粗估计视差图和左图信息预测动态候选视差偏移量,将其与粗估计视差图相加生成自适应候选视差。
[0011]
本发明进一步的改进在于,dop利用视差粗估计结果和左图信息预测动态偏移量,进而得到自适应候选视差,表示如下:
[0012][0013]
其中,表示像素点p的第n个视差偏移量i
1p
表示左图像素点p的值,表示像素点p的第一阶段视差粗估计结果;使用一系列二维卷积实现dop,具体过程为:首先将粗估计视差图和左图双线性插值到1/4分辨率,再沿通道方向级联,接着将该张量通过一个卷积得到c
dop
维表示,然后该张量通过4个步长为1的残差块得到尺寸为(n-1)
×
h/4
×
w/4的偏移量,其中,n为偏移量总数,h和w为输入图像的高和宽;将该偏移量和零张量加到粗估计视差图上,便可得到自适应的候选视差dc
p
:
[0014][0015]
本发明进一步的改进在于,第二阶段视差估计,利用自适应候选视差对1/4右特征图进行扭曲操作,即根据自适应候选视差对右特征图的每一像素进行不同程度的位移,然后与左特征图级联得到紧凑匹配代价量,对该代价量正则化处理后,进行视差回归得到1/4分辨率的精细视差估计。
[0016]
本发明进一步的改进在于,视差精修时,通过级联残差块,利用精细视差估计结果和左图信息层次化预测视差残差,将残差与视差相加得到精修视差图,并上采样得到全尺寸视差;
[0017]
得到视差图后,采用adam优化方法优化smoothl1loss目标函数,具体公式如下:
[0018][0019][0020]
其中,为像素点i的视差预测值,d
i
为像素点i的视差真值;得到优化模型后,便可进行线上推理。
[0021]
与现有技术相比,本发明至少具有如下有益的技术效果:
[0022]
本发明提出的一种基于自适应候选视差预测网络的实时双目立体匹配方法,该方法提出的dop可以预测动态偏移量来代替已有方法的恒定偏移量,该偏移量与粗估计视差结果相加生成自适应候选视差,可以适应不同图像位置的不同视差校正范围需求,并且能够恢复粗估计阶段丢失的细小结构信息,显著提升视差图质量。
[0023]
进一步,由于dop的有效性,本发明无需采用与已有方法类似的多级处理操作。因此,本发明设计了两级由粗到精的处理结构,能够大幅提升精度的同时,速度也提高至原有方法的两倍。
附图说明
[0024]
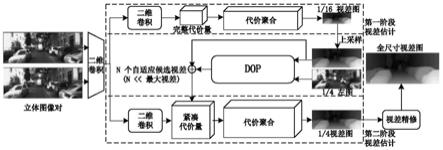
图1为本发明基于自适应候选视差预测网络的实时双目立体匹配方法的整体框架;
[0025]
图2为本发明的特征提取网络示意图;
[0026]
图3为本发明的动态偏移量预测以及自适应候选视差生成示意图;
[0027]
图4为dop的动态偏移量可视化示意图,图4(a)为动态候选视差偏移量,图4(b)为偏移量直方图;
[0028]
图5为本发明的视差精修模块示意图。
具体实施方式
[0029]
以下结合附图和实施例对本发明作进一步的详细说明。
[0030]
如图1-5所示,在对原始输入图像进行打乱、裁剪、归一化等常规数据预处理操作后,本发明提供了一种基于自适应候选视差网络的实时双目立体匹配方法,该方法包括特征提取、第一阶段视差估计、动态偏移量预测dop(dynamic offset prediction,dop)、第二阶段视差估计和视差精修等5个步骤:
[0031]
1)图1是本发明的整体框架示意图。完成双目立体匹配任务的神经网络模型输入是匹配图像对i1和i2,输出是目标图像i1的稠密视差图d。该网络将学习一个函数(模型)f满足下列关系:
[0032]
f(i1,i2)=d
[0033]
具体地,网络首先从经过校正的原始输入图像i1和i2中提取用于匹配代价计算的高维特征信息f1和f2,然后利用f1和f2构建三维匹配代价量并进行代价聚合,最终回归出稠密视差图d。如图1所示,本发明的整体模型主要包括特征提取f1、第一阶段视差估计f2、dopf3、第二阶段视差估计f4和视差精修f5等5个模块。
[0034]
2)特征提取f1:f1采用一系列二维卷积操作学习i1和i2的1/4和1/16分辨率特征表示示以及该过程可表示为:
[0035][0036][0037]
首先,本发明采用三个下采样率分别为2、1、2的卷积、一个残差块和一个卷积操作将原始输入图像i1变换为2c
×
h/4
×
w/4的高维特征图其中,h、w分别表示输入图像的高和宽,c为控制特征提取通道数的常数。然后用两次2倍下采样卷积+残差块的操作组合、一个残差块和一个卷积操作提取到尺寸为8c
×
h/16
×
w/16的特征i1和i2的特征提取网络权值共享,且i2的特征提取过程与上述一致。
[0038]
3)第一阶段视差估计f2:该模块主要包含构建完整匹配代价量、代价聚合和视差计算三部分。完整匹配代价量的构建过程具体为:在每一个视差下,沿宽度方向向左进
行相应视差值个单位的平移,然后与目标特征图(左)在通道方向进行拼接。通过上述错位拼接,即可构建尺寸为16c
×
d/16
×
h/16
×
w/16的初始匹配代价量其中d表示最大视差值。通过6个级联的标准三维卷积对进行正则化得到尺寸为1
×
d/16
×
h/16
×
w/16的匹配代价量最后用soft argmin对该代价量进行回归,得到粗估计视差值:
[0039][0040]
其中,c
d
表示相应视差d下的匹配代价,d
max
表示该分辨率下的最大视差。
[0041]
4)dop f3:dop根据f2粗视差结果和左图信息动态预测每个像素的视差偏移量。具体可表示如下:
[0042][0043]
其中,表示像素点p的第n个视差偏移量i
1p
表示左图像素点p的值,表示像素点p的第一阶段视差粗估计结果。本发明使用一系列二维卷积来实现dop函数。具体运算过程如图3所示,首先将粗估计视差图和左图双线性插值到1/4分辨率,再沿通道方向级联,接着将该张量通过一个卷积得到c
dop
维表示,然后该张量通过4个步长为1的残差块得到尺寸为(n-1)
×
h/4
×
w/4的偏移量,其中,n为偏移量总数,动态偏移量及其统计直方图如图4所示。将该偏移量和零张量加到粗估计视差图,便可得到自适应的候选视差dc
p
:
[0044][0045]
5)第二阶段视差估计f4:该模块与f2类似,主要包含构建紧凑匹配代价量、代价聚合和视差计算三部分。本发明利用f3得到的dc
p
对右图1/4分辨率特征图进行扭曲操作,即根据候选视差对右特征图的每一个像素进行不同程度的位移,然后与左图1/4分辨率特征图沿通道方向级联,形成尺寸为4c
×
d/4
×
h/4
×
w/4的初始匹配代价量接下来对进行正则化得到代价量最后用soft argmin对该代价量进行回归:
[0046][0047]
其中,表示相应视差下的匹配代价。
[0048]
由于dop可以预测更准确的候选视差,本发明设计为两级由粗到精结构以进行准确且快速的视差估计。
[0049]
6)视差精修f5:如图5所示,在得到1/4分辨率视差以后,本发明对其进行两级精修和上采样。具体地,首先本发明将和1/4左图级联,经过卷积后形成尺寸为32
×
h/4
×
w/4的张量,之后该张量经过膨胀率分别为1、2、4、8、1、1的残差块和一个二维卷积,得到尺寸为1
×
h/4
×
w/4的视差残差r1,将其与相加后,便可得到1/4分辨率下的视差精修结果,将该结果上采样到1/2分辨率后重复上述过程得到1/2分辨率下的视差精修结果r2,最后将1/2精修视差图上采样到全分辨率便得到最终视差结果。
[0050]
为了使反向传播的梯度随误差的变化更加平滑,对离群点更加鲁棒,本发明使用smoothl1loss函数作为优化目标,其具体公式如下:
[0051][0052][0053]
其中,为像素点i的视差预测值,d
i
为像素点i的视差真值。
[0054]
在训练阶段,本发明在第一、二阶段的第一个卷积后增加输出视差图进行更有效的监督,损失函数计算如下:
[0055][0056]
为了提升学习收敛速度,防止陷入局部最优点,本发明选择adam优化器对模型参数进行更新。本发明在flyingthings3d、driving和monkaa数据集按上述过程做预训练,之后利用预训练得到的模型在kitti 2012或kitti 2015做迁移训练。至此,模型优化完成,可进行线上推理任务。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1