一种分布式文件系统控制数据恢复速度的方法及装置与流程
[0001]
本发明涉及分布式存储系统领域,特别是涉及一种分布式文件系统控制数据恢复速度的方法及装置。
背景技术:
[0002]
分布式文件系统以分布式存储系统为基础,将文件转化为存储对象随机存储在集群底层的磁盘中。每个磁盘通过一个守护进程osd来管理,osd实现了数据读写、复制、平衡、恢复等功能。系统通过多副本或者纠删码产生的数据冗余来实现数据保护机制。当一个磁盘发生故障时,通过其他磁盘上的冗余数据将故障磁盘上的数据恢复到满足故障域要求的非故障磁盘上。这是数据恢复(或称数据重构,recovery/backfill)的一个基本场景,recovery是数据恢复的意思,在某些语境下专指通过日志来恢复不一致对象;backfill是指pg通过扫描和全量拷贝恢复缺失对象。除了磁盘故障,其他类型的集群拓扑结构变化,如集群扩容/缩容,也要通过对象的灵活迁移实现数据的平衡分布。
[0003]
为了减少数据恢复对前端性能的影响,现有方案实现了对数据恢复速度的控制功能。该方案通过限定一个恢复周期可恢复的最大数据量和最大对象数来限制恢复速度。具体方法是根据集群规模计算出数据恢复速度的上限,即最大带宽,再根据最大带宽计算每个osd的恢复速度。计算数据恢复速度上限的方法考虑到了集群规模等因素,使恢复速度上限和参与数据恢复的主osd个数成正比,这样,集群规模越大,恢复速度越大。
[0004]
然而,对于换盘或者扩容等场景,只有少量磁盘参与数据恢复的数据写入。在这些场景下,虽然参与数据恢复的osd很多,但是只有新增磁盘在写入数据,这样计算出的数据恢复速度较大,使得写入磁盘压力过大。
技术实现要素:
[0005]
本发明主要解决的技术问题是提供一种分布式文件系统控制数据恢复速度的方法,按照数据恢复过程中写入的osd数量来调整数据恢复速度上限,解决当前分布式文件系统在换盘等写入osd很少的场景下磁盘压力过大影响前端业务的问题。
[0006]
为解决上述技术问题,本发明采用的一个技术方案是:提供一种分布式文件系统控制数据恢复速度的方法,包括:
[0007]
s100,遍历放置组,查找并记录每个放置组内缺失数据的对象存储守护进程;
[0008]
s200,统计当前正在数据恢复的放置组所要写入数据的对象存储守护进程个数;
[0009]
s300,计算数据恢复速度上限;
[0010]
s400,计算对象存储设备当前单位时间内可以恢复的基础数据量,当对象存储设备在一个恢复周期内恢复的数据量大于基础数据量,则改对象存储设备的所有放置组都不再新增数据恢复对象,直至下一个周期。
[0011]
进一步,所述步骤s100具体包括以下步骤:
[0012]
s101,在放置组根据日志检查各副本版本是否一致的过程中,查找缺失数据的对
象存储守护进程;
[0013]
s102,通过查找到的缺失数据的对象存储守护进程判断磁盘是否需要在数据恢复中写入数据;
[0014]
s103,放置组将缺失数据的对象存储守护进程上报到监视器守护进程。
[0015]
进一步,所述步骤s200具体包括以下步骤:所述监视器守护进程统计当前正在数据恢复的所有放置组上报的对象存储守护进程,获得正在写入的磁盘数量。
[0016]
进一步,所述步骤s300具体包括以下步骤:
[0017]
s301,根据步骤s100和s200获得需要恢复的主对象存储守护进程数量m和需要写入的对象存储守护进程数量n;
[0018]
s302,配置单个对象存储守护进程的数据恢复速度s和系数r,根据以下公式计算s1和s2:
[0019]
s1=s*m,s2=s*n*r;
[0020]
s303,比较s1和s2,取较小值作为数据恢复速度上限s。
[0021]
进一步,所述步骤s400中的基础数据量的计算方法为:基础数据量等于对象存储设备需要恢复的存储对象数除以集群需要恢复的存储对象数再乘以数据恢复速度上限s。
[0022]
进一步,所述放置组为pg,所述对象存储守护进程为osd,所述放置组根据日志检查各副本版本是否一致的过程为peering。
[0023]
进一步,在peering过后,pg查看peering结果,peering把该pg主osd缺失的对象信息放到pg log的map中;判断该map不为空,则将该pg的主osd计入该pg需要写入的osd中;
[0024]
peering把从osd缺失的对象信息放到peer_missing结构中,检查每个osd的missing map是否为空,如果不为空,将该osd计入该pg需要写入的osd中;
[0025]
在osd层上报统计的信息,将每个pg需要写入的osd信息加入到pginfo中,osd每隔一段时间上报一次该osd上所有pg的pginfo给监视器守护进程。
[0026]
进一步,所述监视器守护进程收到上报的pginfo后将其保存起来;所述监视器守护进程每隔一段时间遍历保存的pginfo,若遍历到的pg处于recover或backfill状态,将其主osd计入需要数据恢复的osd,将该pg的pginfo中保存的该pg需要写入的osd计入集群需要写入的osd;遍历结束后得到需要恢复的主osd数量和需要写入的osd数量。
[0027]
一种分布式文件系统控制数据恢复速度的装置,包括处理器和存储器,所述存储器用于存储执行前述方法的程序;所述处理器被配置为用于执行所述存储器中存储的程序。
[0028]
本发明的有益效果是:本发明优化了根据集群规模动态调整数据恢复速度上限的方法,可以使分布式文件系统集群的恢复速度和需要写入的磁盘数量正相关,避免实际写入磁盘很少时造成磁盘压力过大影响前端业务。
附图说明
[0029]
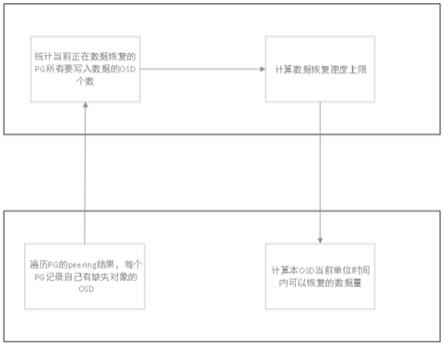
图1是本发明一种分布式文件系统控制数据恢复速度的方法一较佳实施例的架构图。
具体实施方式
[0030]
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
[0031]
请参阅图1,本发明实施例包括:
[0032]
一种分布式文件系统控制数据恢复速度的方法,使用peering过程中发现的缺失数据的osd来判断磁盘是否需要在数据恢复中写入数据。pg将缺失数据的osd上报到mon,mon统计当前正在数据恢复的所有pg上报的osd,来得到正在写入的磁盘数量。得到写入的磁盘数量后,计算数据恢复速度上限,和现有方案计算出的数据恢复速度上限相比较,取较小的值作为最终结果。这样计算出的结果可以避免写入的磁盘较少时这些磁盘写入压力过大而影响到前端业务。其中osd全称object-based storage device,意思是对象存储设备;pg全称placement group,意思是放置组,是用于放置对象的一个载体;mon是monitor集群的监视器守护进程;peering指的是pg根据日志来检查各副本版本是否一致的过程。
[0033]
具体实施过程如下:
[0034]
1、在pg层统计需要写入数据恢复数据的osd;在peering过后,pg查看peering结果;peering把该pg主osd缺失的对象信息放到pglog的map中,检查该map不为空,则将该pg的主osd计入该pg需要写入的osd中;peering把从osd缺失的对象信息放到peer_missing结构中,检查每个osd的missing map是否为空,如果不为空,将该osd计入该pg需要写入的osd中;
[0035]
2、在osd层上报统计的信息;在现有方案中,osd每5秒会上报一次该osd上所有pg的pginfo;我们将步骤1中统计的每个pg需要写入的osd信息加入到pginfo中上报给mon;
[0036]
3、mon收到上报的pginfo后将其保存起来,并执行议案;
[0037]
4、mon每隔一段时间遍历一下保存的所有pg的pginfo,如果遍历到的pg处于recover或backfill状态,将其主osd计入需要数据恢复的osd,将该pg的pginfo中保存的该pg需要写入的osd计入集群需要写入的osd;统计时重复的osd不予统计;遍历结束后得到需要恢复的主osd数量m和需要写入的osd数量n;
[0038]
5、计算数据恢复速度上限;配置单个osd的数据恢复速度s和系数r,分别计算数据恢复速度上限s1=s
×
m,s2=s
×
n
×
r,比较s1和s2,取较小的那个作为数据恢复速度上限s;
[0039]
6、将数据恢复速度上限下发给osd;osd通过以下方法计算自己在单位时间内数据恢复的数据量s0:
[0040]
s0=osd需要恢复的对象数/集群需要恢复的对象数
×
s;
[0041]
7、当osd在一个恢复周期内恢复的数据量大于s0,则该osd的所有pg都不再新增数据恢复对象,直到下一个周期。
[0042]
另一方面,基于与前述实施例中控制数据恢复速度方法同样的发明构思,本说明书实施例还提供一种分布式文件系统控制数据恢复速度的装置,包括处理器和存储器,所述存储器用于存储执行前述方法的程序;所述处理器被配置为用于执行所述存储器中存储的程序。
[0043]
以上所述仅为本发明的实施例,并非因此限制本发明的专利范围,凡是利用本发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技
术领域,均同理包括在本发明的专利保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1