一种基于深度学习的车底板异物击打故障检测方法与流程
1.本发明属于列车运行故障检测领域,具体涉及一种基于深度学习的车底板异物击打故障检测方法。
背景技术:
2.动车组列车在结构上具有结构复杂,零部件多,底板高度低等特点,列车运行过程中多为高站台,同时动车组列车在运行状态中具有一站直达,折返运行并且停站时间短的特点,并且它在中途无法对底板部件状态进行人工的检测和检修。对于运行过程中因为异物击打造成的底部部件损伤难以及时得到确认和检测,容易造成折返运行的动车组带病运行。尤其是行驶在有碎石轨道上的动车组,在高速运行的过程中更容易引起异物击打底部部件,存在行驶安全隐患。随着动车组的高强度使用,人工检修的方式无法达到高效率,高准确率,只依靠传统的人工检修方式已经无法满足动车组检修需求。
3.深度学习和人工智能技术不断成熟,因而采用深度学习进行动车组底部异物击打痕迹的检测,能够有效提高检测效率和检测准确率。
技术实现要素:
4.本发明是为了解决人工检修因动作车组底板异物击打造成的部件故障效率不高,且准确率不高的问题。现提供一种基于深度学习的车底板异物击打故障检测方法。
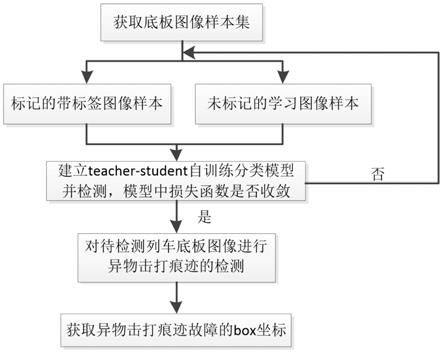
5.一种基于深度学习的车底板异物击打故障检测方法,包括:
6.步骤一、获取列车底板图像样本集,所述列车底板图像样本集包括标记的带标签图像样本和未标记的学习图像样本;
7.步骤二、对标记的带标签图像样本和未标记的学习图像样本通过teacher
‑
student模型进行样本扩增,建立自训练分类模型,利用所述扩增后得到的样本,以最小化ghm损失函数为目标对自训练分类模型进行迭代训练,直至ghm损失函数完全收敛时,停止迭代;
8.步骤三、停止迭代后,使训练后的自训练分类模型对待检测列车底板图像进行异物击打痕迹的检测,将检测得到的异物击打痕迹的box坐标投射为整个列车上的坐标,所述box坐标为异物击打痕迹在待检测列车底板图像上的具体位置。
9.有益效果
10.1、本发明利用图像自动识别的方式代替人工检测,既提高了检测效率又提高了准确率。
11.2、本发明采用teacher
‑
student模型方式增加数据标记样本,使异物击打列车底板痕迹特征数量相对列车底板图像中其他特征保持平衡,同时增加了数据集的标签数量,提高了故障识别的准确率和检测算法的泛化能力。
12.3、针对列车底板图像中异物击打痕迹的特殊形态,在模型中采用ghm损失函数,加快了在深度学习训练中模型的收敛速度。
13.4、利用ghm损失函数进行模型训练,对列车底板异物击打痕迹进行检测,能够区分与列车底板挂异物、漏油、水渍等困难特征,有效防止模型在训练中过于关注困难样本,更加准确地对底板异物击打痕迹进行分类。
附图说明
14.图1位本发明故障检测流程图;
15.图2为teacher
‑
student模型流程图。
具体实施方式
16.需要特别说明的是,在不冲突的情况下,本申请公开的各个实施方式之间可以相互组合。
17.具体实施方式一:参照图1来说明本实施方式,本实施方式一种基于深度学习的车底板异物击打故障检测方法,包括:
18.步骤一、获取列车底板图像样本集,列车底板图像样本集包括标记的带标签图像样本和未标记的学习图像样本;
19.步骤二、对标记的带标签图像样本和未标记的学习图像样本通过teacher
‑
student模型进行样本扩增,建立自训练分类模型,利用所述扩增后得到的样本,以最小化ghm损失函数为目标对自训练分类模型进行迭代训练,直至ghm损失函数完全收敛时,停止迭代;
20.步骤三、停止迭代后,使训练后的自训练分类模型对待检测列车底板图像进行异物击打痕迹的检测,将检测得到的异物击打痕迹的box坐标投射为整个列车上的坐标,所述box坐标为异物击打痕迹在待检测列车底板图像上的具体位置。
21.具体实施方式二:本实施方式与具体实施方式以不同的是,所述步骤一获取车底板图像样本集,所述列车底板图像样本集包括待训练的带标签图像样本和未标记的学习图像样本;具体过程为:
22.获取列车底板图像,即灰度图像;车底部在结构上具有复杂、零部件较多且底部高度低等特征,故采集到的底板灰度图像中的目标(图像中的前景目标,即包括底板异物击打痕迹、水渍、油渍、底板零部件等)比较复杂,同时考虑到车高频率的运返,将会采集到不同天气环境下的图像,不同探测站拍摄的图像也会存在一定差异;车底板异物击打痕迹相比各部件以及通风口等,面积小,样本少;所以在收集车底板异物击打痕迹过程中要保证样本点多样性,尽量少将各种条件下的车底板异物击打痕迹全部收集;按照车底板部件分布的特点,将列车底板图像按车厢节数分节,由于车底板较大,故将每节车厢底板图像按照主要部件特征点再分为若干个小图像,选择部分小图像进行样本标记,针对标记的带标签图像中易对底板异物击打痕迹检测造成影响的目标特征进行统一标记,目标可以包括部件、漏油以及水渍等,得到真实标签数据集,作为待训练的带标签图像样本,剩下未标记的不带标签小图像作为学习样本;每节车厢的底板图像特征均不同,根据列车的不同车节数,采集得到不同的底板图像,获取这些底板图像的特征。
23.其他步骤及参数与具体实施方式一相同。
24.具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤二对标
记的带标签图像和未标记的不带标签图像通过teacher
‑
student模型进行样本扩增,建立自训练分类模型,以最小化ghm损失函数为目标对自训练分类模型进行迭代训练,直至ghm损失函数完全收敛时,停止迭代;具体过程为:
25.步骤二一、将标记的带标签图像记为{(x1,y1),(x2,y2),...,(x
n
,y
n
)},未标记的不带标签图像记为对标注的带标签图像数据集{(x1,y1),(x2,y2),...,(x
n
,y
n
)}进行训练学习,最小化ghm(gradient harmonizing mechanism)损失函数,训练学习得到teacher modelθ
t
(通过已标记标签样本对未标记样本中的目标进行预测的半监督学习模型):
[0026][0027]
其中,n表示带标签图像样本数;f
noised
表示对x
i
加入噪声后进行teacher model训练的函数机制;x
i
表示第i个带标签样本;y
i
表示x
i
对应的标签;θ
t
表示teacher model;
[0028]
步骤二二、使用训练学习得到的teacher model为未标记的图像打上伪标签:
[0029][0030]
其中,表示未标记的样本通过学习得到的伪标签;m表示伪标签样本总数;表示未标记的样本;
[0031]
步骤二三、使用已标记带标签数据集和没有标记的数据集,通过学习训练使得ghm(gradient harmonizing mechanism)损失函数最小,来训练添加噪音的student model(通过已标记的样本,和样本对应的标签对未标记样本通过teacher模型引导,预测其真实的标签的训练模型),通过以下公式迭代训练teacher model,直至ghm损失函数的损失值l
ghm
最小,停止迭代:
[0032][0033]
其它步骤及参数与具体实施方式一或二相同。
[0034]
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述步骤二中损失函数l
ghm
为:
[0035][0036]
其中,p
i
表示图像标签y
i
出现异物击打痕迹故障的概率;p
i*
表示真实标签,p
i*
={0,1};g
i
表示第i个样本的梯度模长;gd(g
i
)表示梯度密度,是单位梯度模长g部分的样本个数;l
ce
表示交叉熵损失函数;使用l
ghm
损失函数,可使模型不会过多关注车底部图像中特别难分的样本,防止在模型已经收敛时,错误判断这些难以区分的样本离散点,使模型关注这些离散点,增加训练的成本,从而提高训练的效率,让模型能较好的收敛,提高检测识别的准确率。
[0037]
其它步骤及参数与具体实施方式一至三之一相同。
[0038]
具体实施方式五:本实施方式与具体实施方式一至四之一不同的是,所述交叉熵损失函数l
ce
为:
[0039][0040]
其它步骤及参数与具体实施方式一至四之一相同。
[0041]
具体实施方式六:本实施方式与具体实施方式一至五之一不同的是,所述梯度密度gd(g
i
)为:
[0042][0043]
其中,l
ε
为交叉损失函数;δ
ε
(g
k
,g
i
)表示样本1~n中,梯度模长在范围内的样本个数,l
ε
(g
i
)代表了区间的长度,其中,ε表示计算梯度时每个bin(区间)的宽度;g
k
表示第k个样本的梯度模长;g
i
为单位梯度模长。
[0044]
其他步骤及参数与具体实施方式一至五之一相同。
[0045]
具体实施方式七:本实施方式与具体实施方式一至六之一不同的是,所述单位梯度模长g
i
表示为:
[0046][0047]
其中,p表示teacher model预测出现异物击打痕迹故障的概率;p
*
表示真实标签,p
*
={0,1};g
i
正比于检测的难易程度,检测难度越大,g
i
越大。
[0048]
其他步骤及参数与具体实施方式一至六之一相同。
[0049]
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述步骤二三使用已标记带标签数据集和没有标记的数据集,通过学习训练使得ghm(gradient harmonizing mechanism)损失函数最小,来训练添加噪音的student model;所述噪音包括:data augmentation(数据增强,通过亮度、翻转等方式进行增强)、dropout(在训练的过程中,按照设定的阈值比例随机丢弃一些样本)和stochastic depth(在训练的过程中随机丢掉一些teacher
‑
student的训练层数);通过添加data augmentation输入性噪声,对车底部图像进行增强,保证变换后的图像依然具有正确的分类标签,达到让student model更加容易对困难样本的特征图像做出预测的目的;在训练student model的同时,对标记的带标签图像样本和打上伪标签的未标记学习图像样本添加dropout(随机丢弃)和stochastic depth(随机深度)噪声,让student model不单一,复杂度逐渐靠近teacher model集合的复杂度;让每类已经带标签的图像样本和未标记标签图像样本逐渐达到平衡。
[0050]
其他步骤及参数与具体实施方式一至七之一相同。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1