一种图像文档的文本抽取方法、装置及电子设备与流程
本发明涉及图像处理技术领域,尤其涉及一种图像文档的文本抽取方法、装置及电子设备。
背景技术:
文档抽取可以分为信息抽取和文档结构理解两个部分。以语言模型为基础的信息抽取技术已经发展到了较高水平,比较常用的框架有word2vec+bilstm+crf、bert、gpt、ernie等预训练模型。大规模预训练语言模型能够通过自监督任务在预训练阶段有效捕捉文本中蕴含的语义信息,经过下游任务微调后能有效地提升模型效果。然而,现有的预训练语言模型主要针对文本单一模态进行,而忽视了文档本身与文本天然对齐的视觉结构信息,而且均是利用识别好的ocr结果进行信息抽取的,不支持类似表格结构的信息抽取,造成结构信息的抽取混乱。
技术实现要素:
本发明提供了一种图像文档的文本抽取方法、装置及电子设备,能够有效解决现有的文档抽取方法造成的结构信息混乱的问题。
根据本发明的第一方面,提供了一种图像文档的文本抽取方法,包括:
通过光学字符识别模型对图像文档进行识别;
根据所识别的信息生成组合向量;
将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;
其中,根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
进一步地,所述通过光学字符识别模型对图像文档进行识别,包括:
对图像文档进行倾斜校正、文字检测、文字识别和表格识别,得到文字信息、图像信息、坐标信息和表格信息。
进一步地,根据所识别的信息生成组合向量包括:
根据文字信息得到词嵌入和位置嵌入,根据图像信息到字符图像嵌入,根据坐标信息得到坐标嵌入,根据表格信息得到表格信息嵌入,组合得到所述组合向量。
进一步地,按照下述方式计算所述联合损失函数
其中,
进一步地,所述对图像文档进行识别的损失包括文字识别的损失和表格识别的坐标损失。
根据本发明的第二方面,提供了一种图像文档的文本抽取装置,包括:
识别模块,用于通过光学字符识别模型对图像文档进行识别;
向量生成模块,用于根据所识别的信息生成组合向量;
抽取模块,用于将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;
训练模块,用于根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
进一步地,所述识别模块包括倾斜校正模块、文字检测模块、文字识别模块和表格识别模块,得到文字信息、图像信息、坐标信息和表格信息;
所述向量生成模块根据文字信息得到词嵌入和位置嵌入,根据图像信息到字符图像嵌入,根据坐标信息得到坐标嵌入,根据表格信息得到表格信息嵌入,组合得到所述组合向量。
进一步地,所述对图像文档进行识别的损失包括文字识别的损失和表格识别的坐标损失。
根据本发明的第三方面,提供了一种电子设备,包括处理器和存储器,所述存储器存储有多条指令,所述处理器用于读取所述多条指令并执行如第一方面所述的方法。
根据本发明的第四方面,提供了一种计算机可读存储介质,所述计算机存储介质存储有多条指令,所述多条指令可被处理器读取并执行如第一方面所述的方法。
本发明提供的图像文档的文本抽取方法、装置及电子设备,至少包括如下有益效果:
ocr的输出除了纯文本的文字特征外,还包括单个字符的图像特征、x、y坐标特征、表格特征等结构信息,在文本抽取模型中实现多种特征的嵌入,从而避免了结构信息的抽取混乱;对光学字符识别模型以及文本抽取模型进行联合优化,充分利用了文档的布局信息和文档的语义信息,不再单独优化光学字符识别模型以及文本抽取模型某一部分的结果,大大增加了光学字符识别模型的识别能力、语义分割能力和文档抽取结果的准确度;本申请的文档抽取方法不限于某种网络架构和语言模型、也不限于具体自然语言处理任务;光学字符识别模型也不限于识别的功能和模块结构,文档抽取方法不限于具体抽取和识别文档,适用任何图像文档和语言。
附图说明
图1为本发明提供的图像文档的文本抽取方法一种实施例的流程图。
图2为本发明提供的图像文档的文本抽取装置一种实施例的结构示意图。
图3为本发明提供的电子设备一种实施例的结构示意图。
具体实施方式
为了更好的理解上述技术方案,下面将结合说明书附图以及具体的实施方式对上述技术方案做详细的说明。
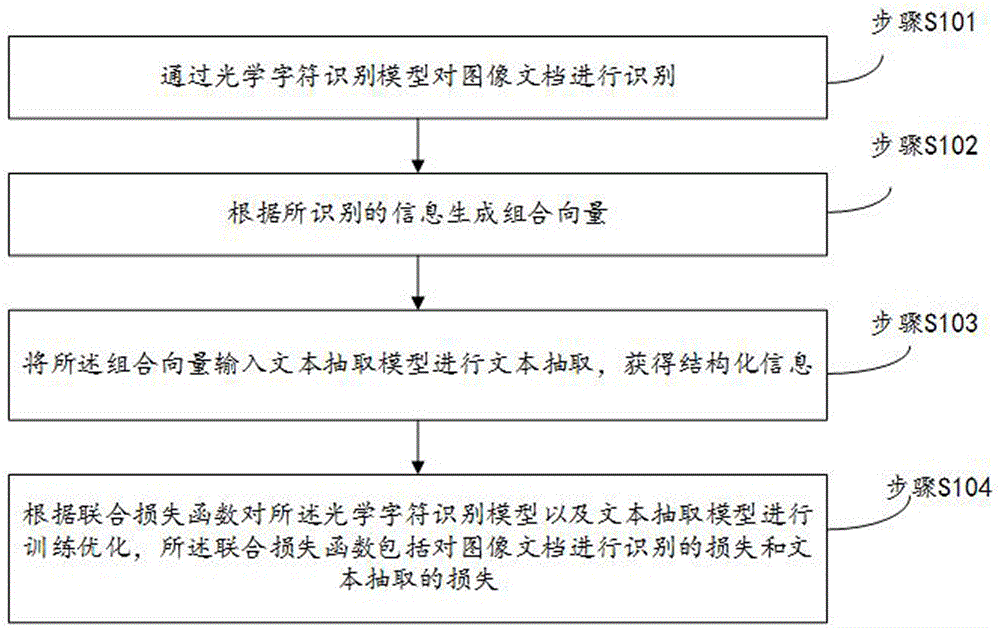
参考图1,在一些实施例中,提供一种图像文档的文本抽取方法,包括:
步骤s101,通过光学字符识别模型对图像文档进行识别;
步骤s102,根据所识别的信息生成组合向量;
步骤s103,将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;
步骤s104,根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
具体地,步骤s101中,所述通过光学字符识别模型对图像文档进行识别,包括:
对图像文档进行倾斜校正、文字检测、文字识别和表格识别,得到文字信息、图像信息、坐标信息和表格信息。
ocr,光学字符识别(opticalcharacterrecognition)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
光学字符识别模型(ocr)首先是对图像文档进行整体的倾斜校正,倾斜或者扭曲较大的图片会对文字识别和表格识别造成较大干扰,倾斜矫正采用east模型实现;由于在倾斜文档中各个文字的大小不一、位置不一致,而east模型除了抽取特征层外,还有一个特殊的特征融合层能够融合不用层次的特征,大小文字,分别利用底层和高层的语义信息。文字检测则是利用训练简单,结果易用,不需要进行太多后续复杂处理的dbnet模型。文字识别则是利用crnn模型,crnn由cnn+bilstm+ctc结构组成。表格识别则利用maskr-cnn实现。
单个字符的图像特征包含了丰富的文字字体、字号大小、颜色等特征,是一种重要的文本信息。在大多数商业票据或者图像文档中,存在大量的表格,若按照纯文本的方法处理表格信息,将造成大量的信息缺失和混乱。上述实施例提供的方法,利用ocr输出的表格结构信息,将描述同一事物的单行、多行信息约束在同一个单元格内。
进一步地,步骤s102中,根据所识别的信息生成组合向量包括:
根据文字信息得到词嵌入和位置嵌入,根据图像信息到字符图像嵌入,根据坐标信息得到坐标嵌入,根据表格信息得到表格信息嵌入,组合得到所述组合向量。
组合向量的形式如下:
y=
其中,
进一步地,步骤s103中,将所述组合向量y输入文本抽取模型进行文本抽取,获得结构化的信息,例如以json格式。
文档抽取利用的是transformers特征提取器。transformers主要由两大部分组成:编码器(encoder)和解码器(decoder),每个模块都包含6个block。所有的编码器在结构上都是相同的,负责把自然语言序列映射成为隐藏层。
文档抽取框架利用的是bert框架。以保险单图像为例,将整个保险单ocr的结果作为一个sequence进行信息抽取。由于大部分文档的长度超过了512,所以利用窗口滑动或者多个bert预训练模型向量输入将输入的嵌入长度提升到2048,实现对整个文档的特征嵌入。文档特征通过抽取bert+crf,输出token的最后一层向量,利用softmax函数实现文本token的分类。
进一步地,步骤s104中,按照下述方式计算所述联合损失函数
其中,
进一步地,所述对图像文档进行识别的损失包括文字识别的损失和表格识别的坐标损失。
其中,
文字识别的损失、表格识别的坐标损失以及文本抽取损失可以采取各自领域常见损失计算方法,此处利用系数
参考图2,在一些实施例中,提供一种图像文档的文本抽取装置,包括:
识别模块201,用于通过光学字符识别模型对图像文档进行识别;
向量生成模块202,用于根据所识别的信息生成组合向量;
抽取模块203,用于将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;
训练模块204,用于根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
在一些实施例中,识别模块201包括倾斜校正模块、文字检测模块、文字识别模块和表格识别模块,用于分别获得文字信息、图像信息、坐标信息和表格信息。
向量生成模块202根据文字信息得到词嵌入和位置嵌入,根据图像信息到字符图像嵌入,根据坐标信息得到坐标嵌入,根据表格信息得到表格信息嵌入,组合得到所述组合向量。
组合向量的形式如下:
y=
其中,
在一些实施例中,抽取模块203利用的是transformers特征提取器进行文本抽取。
在一些实施例中,训练模块204按照下述方式计算所述联合损失函数
其中,
进一步地,所述对图像文档进行识别的损失包括文字识别的损失和表格识别的坐标损失。
其中,
参考图3,在一些实施例中,还提供一种电子设备,包括处理器301和存储器302,存储器302存储有多条指令,处理器301用于读取所述多条指令并执行上述的图像文档抽取与识别的优化方法,例如包括:通过光学字符识别模型对图像文档进行识别;根据所识别的信息生成组合向量;将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;其中,根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
在一些实施例中,还提供一种计算机可读存储介质,所述计算机存储介质存储有多条指令,所述多条指令可被处理器读取并执行上述的图像文档抽取与识别的优化方法,例如包括:通过光学字符识别模型对图像文档进行识别;根据所识别的信息生成组合向量;将所述组合向量输入文本抽取模型进行文本抽取,获得结构化信息;其中,根据联合损失函数对所述光学字符识别模型以及文本抽取模型进行训练优化,所述联合损失函数包括对图像文档进行识别的损失和文本抽取的损失。
综上,上述实施例提供的图像文档的文本抽取方法、装置及电子设备,至少包括如下有益效果:
(1)ocr的输出除了纯文本的文字特征外,还包括单个字符的图像特征、x、y坐标特征、表格特征等结构信息,将描述同一事物的单行、多行信息约束在同一个单元格内,在文本抽取模型中实现多种特征的嵌入,从而避免了结构信息的抽取混乱;
(2)对光学字符识别模型以及文本抽取模型进行联合优化,不再单独优化光学字符识别模型以及文本抽取模型某一部分的结果,大大增加了光学字符识别模型的识别能力、语义分割能力和文档抽取结果的准确度;
(3)与现有方法相比,文档抽取方法不限于某种网络架构和语言模型也不限于具体自然语言处理任务;光学字符识别模型也不限于识别的功能和模块结构,不限于具体抽取和识别文档,适用任何图像文档和语言。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!