基于图神经网络的科学文献关键内容潜在关联挖掘方法与流程
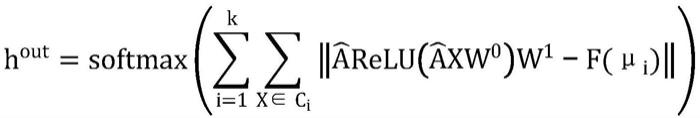
[0001]
本发明涉及文献分析技术领域,尤其涉及基于图神经网络的科学文献关键内容潜在关联挖掘方法。
背景技术:
[0002]
图神经网络目前被逐步应用于自然语言处理领域,如文本分类、信息检索、机器翻译等任务中,科学文献数据作为自然语言中常见的数据集,是指由论文信息及其作者信息构成的数据集,基于科学文献数据提供的论文参考文献以及作者信息,可以建立由科学家、论文构成的二分网,科学家合作网络,科学引文网络以及杂志-论文耦合网络,科研单位-论文耦合网络等。
[0003]
近年来,随着复杂网络研究的发展,为科学文献的系统分析提供了有效的方法和工具,开发了citespace、sci2等相关分析软件,可以对上述网络的拓扑结构及演化模式和演化机制等进行分析,除科学文献基本信息外,科学文献自身的文章内容也蕴含了丰富的信息,但现有的文献分析方法并未对其进行充分的利用。
技术实现要素:
[0004]
本发明的目的在于提供基于图神经网络的科学文献关键内容潜在关联挖掘方法,通过对文章内容抽取出的关键词关系进行建模,利用图卷积神经网络技术,对文献主要关键词的潜在关联进行挖掘,满足对科学文献内容进行分析需求,实现对不同领域科学文献的相关性进行分析。
[0005]
为了实现上述目的,本发明采用了如下技术方案:基于图神经网络的科学文献关键内容潜在关联挖掘方法,包括以下步骤:
[0006]
s1:获取某一特定事件相关的科学文献数据,并进行数据清洗和预处理;
[0007]
s2:利用tf-idf方法抽取文献内容关键词;
[0008]
s3:以句子为单位,对抽取出的关键词和关键词所属参考文献构建词共现网络;
[0009]
s4:利用图卷积神经网络学习关键词的向量表示;
[0010]
s5:利用相似度计算函数得到不同关键词之间的相关度,挖掘其潜在的关联关系。
[0011]
作为上述技术方案的进一步描述:
[0012]
所述步骤s1获取某一特定事件相关的科学文献数据,并进行数据清洗和预处理具体步骤为:
[0013]
s1.1:文本挖掘,如果要对某一感兴趣的事件相关文献进行分析时,可以在相关数据库中下载包含该事件关键词的相关文献,或者直接使用已存在的公开数据集。
[0014]
s1.2:文本清洗,得到原始数据后,抽取出文献的摘要和正文内容,如果是中文文本,需要对文本进行分词,然后去除标点、数字、乱码和停止词,减少文本噪声。
[0015]
作为上述技术方案的进一步描述:
[0016]
所述步骤s2利用tf-idf方法抽取文献内容关键词具体方法为:利用tf-idf方法评
估一个词汇对于它所在文本的重要程度,考虑到不同的词汇关键词对辅助决策的帮助不同,对不同词性的关键词赋予了不同的权重,并进行了排序。
[0017]
作为上述技术方案的进一步描述:
[0018]
所述步骤s3以句子为单位,对抽取出的关键词和关键词所属参考文献构建词共现网络的具体方法为:抽取文献内容n个关键词后,利用这n个关键词和其在参考文献中的共现情况,构建一个无向有权图。
[0019]
作为上述技术方案的进一步描述:
[0020]
所述无向有权图无向有权图表示为g=(v,e),其中v={v
i
|i=1,2,
…
,n}为节点集,为边集,n为节点数目,其中,g可以用邻接矩阵a表示,a∈r
n
×
n
,其中a
ij
=w
ij
如果(v
i
,v
j
)∈e,否则a
ij
=0,w
ij
为边(v
i
,v
j
)的权重;
[0021]
所述节点为从文章内容中提取的关键词,边为两个关键词是否时出现在一篇参考文献中,边的权重为两个关键词同时出现在同一篇参考文献中的次数。
[0022]
作为上述技术方案的进一步描述:
[0023]
所述步骤s4利用图卷积神经网络学习关键词的向量表示具体为利用word2vec的cbow模型在的语料库进行训练,所述图结构节点的输入特征矩阵,将图神经网络基本模型和k-means算法进行联合训练,得到关键词共现网络的节点表示。
[0024]
作为上述技术方案的进一步描述:
[0025]
所述步骤s5利用相似度计算函数得到不同关键词之间的相关度,挖掘其潜在的关联关系具体方法为,得到每个关键词的向量表示和新的类别,可以通过相似度计算函数来计算两个关键词之间的相关性,或直接可视化网络节点的空间分布以直观地展示所有关键词之间的亲疏关系。
[0026]
本发明提供了基于图神经网络的科学文献关键内容潜在关联挖掘方法。具备以下有益效果:
[0027]
该基于图神经网络的科学文献关键内容潜在关联挖掘方法通过对文章内容抽取出的关键词关系进行建模,利用图卷积神经网络技术,对文献主要关键词的潜在关联进行挖掘,满足对科学文献内容进行分析需求,实现对不同领域科学文献的相关性进行分析,为科学文献的系统分析提供了有效的方法,结合文献自身内容,首先对科学文献内容进行相关处理,然后对文献内容的关键词构建浅层关联网络,运用改进的图卷积神经网络算法,挖掘了不同领域文献的关键词之间的潜在关联,充分利用了文献内容的丰富信息,补充了科学文献分析中仅利用文献标题、作者、参考文献等非文献内容分析的不足。
附图说明
[0028]
图1为本发明提出的基于图神经网络的科学文献关键内容潜在关联挖掘方法的关系发现模型原理示意图;
[0029]
图2为本发明中文本挖掘和文本清洗模型应用流程图;
[0030]
图3为本发明中网络构件和关联性挖掘模型应用流程图。
具体实施方式
[0031]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完
整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0032]
参照图1-3,基于图神经网络的科学文献关键内容潜在关联挖掘方法,包括以下步骤:
[0033]
s1:获取某一特定事件相关的科学文献数据,并进行数据清洗和预处理;
[0034]
s2:利用tf-idf方法抽取文献内容关键词;
[0035]
s3:以句子为单位,对抽取出的关键词和关键词所属参考文献构建词共现网络;
[0036]
s4:利用图卷积神经网络学习关键词的向量表示;
[0037]
s5:利用相似度计算函数得到不同关键词之间的相关度,挖掘其潜在的关联关系。
[0038]
步骤s1获取某一特定事件相关的科学文献数据,并进行数据清洗和预处理具体步骤为:
[0039]
s1.1:文本挖掘,如果要对某一感兴趣的事件相关文献进行分析时,可以在相关数据库中下载包含该事件关键词的相关文献,或者直接使用已存在的公开数据集。
[0040]
s1.2:文本清洗,得到原始数据后,抽取出文献的摘要和正文内容,如果是中文文本,需要对文本进行分词,然后去除标点、数字、乱码和停止词,减少文本噪声。
[0041]
步骤s2利用tf-idf方法抽取文献内容关键词具体方法为:利用tf-idf方法评估一个词汇对于它所在文本的重要程度,考虑到不同的词汇关键词对辅助决策的帮助不同,对不同词性的关键词赋予了不同的权重,并进行了排序。
[0042]
进一步的,与形容词性关键词相比,名词性关键词更能表达文章内容的主题,每篇文献抽取权重值较大的前50个关键词,最终汇总,统计词频,按词频降序提取前n个所需要的重要关键词。
[0043]
步骤s3以句子为单位,对抽取出的关键词和关键词所属参考文献构建词共现网络的具体方法为:抽取文献内容n个关键词后,利用这n个关键词和其在参考文献中的共现情况,构建一个无向有权图。
[0044]
无向有权图无向有权图表示为g=(v,e),其中v={v
i
|i=1,2,
…
,n}为节点集,为边集,n为节点数目,其中,g可以用邻接矩阵a表示,a∈r
n
×
n
,其中a
ij
=w
ij
如果(v
i
,v
j
)∈e,否则a
ij
=0,w
ij
为边(v
i
,v
j
)的权重;
[0045]
所述节点为从文章内容中提取的关键词,边为两个关键词是否时出现在一篇参考文献中,边的权重为两个关键词同时出现在同一篇参考文献中的次数。
[0046]
步骤s4利用图卷积神经网络学习关键词的向量表示具体为利用word2vec的cbow模型在的语料库进行训练,所述图结构节点的输入特征矩阵,将图神经网络基本模型和k-means算法进行联合训练,得到关键词共现网络的节点表示。
[0047]
对于模型的输入特征,利用word2vec的cbow模型在比较全面的语料库(如维基百科)进行训练,模型窗口大小设为5,词向量维度为100,其他参数均设置为默认参数,经过训练,可以得到一个大小为n
×
100的输入矩阵x。
[0048]
进一步的,虽然有些关键词由于某些划分属于同一类别,但它们在空间上的位置/关联性并不强,因此挖掘这些关键词之间的潜在关系,即发现属于不同类别但关联度高的关键词,或者区分同一类别中关联度较低的关键词。
[0049]
图卷积神经网络可以直接作用于图,实现结构化数据的端到端学习,其原理可以理解可区分的消息传递框架的特例:
[0050][0051]
其中为神经网络结构中第l层中节点v
i
的隐藏状态,d
l
为本层节点向量表示的维度,g
m
(
·
,
·
)形式的传入消息被累积起来,并通过一个激活函数σ(
·
)进行转换,m
i
为节点v
i
的传入消息集合,通常为与v
i
相连的边的集合,g
m
(
·
,
·
)通常为类似神经网络的函数,或者是一个线性变换g
m
(h
i
,h
j
)=wh
j
,w为参数矩阵。
[0052]
基于这种思想,定义了如下的两层传播模型来计算无向有权图中节点的前向传播更新:
[0053][0054]
其中其中为图g增加了自连接的邻接矩阵,i
n
为单位矩阵,w0是从输入层到隐藏层的参数矩阵,w1是从隐藏层到输出层的参数矩阵,relu(
·
)=max(0,
·
)为激活函数。k为节点类别,是可以预先定义的超参数,x为输入节点的特征矩阵,为属于簇c
i
的平均向量,由于μ
i
由原始输入计算得到,与经过积累了两跳相邻节点特征的节点输出矩阵可能存在量纲上的偏差,因此利用函数f(
·
)来调整μ
i
值的范围,函数f(
·
)可以根据需要自行定义。
[0055]
步骤s5利用相似度计算函数得到不同关键词之间的相关度,挖掘其潜在的关联关系具体方法为,得到每个关键词的向量表示和新的类别,可以通过相似度计算函数来计算两个关键词之间的相关性,或直接可视化网络节点的空间分布以直观地展示所有关键词之间的亲疏关系。
[0056]
其中,相似度计算函数采用的是余弦相似度,且相似度计算函数可以根据需要自行定义。
[0057]
进一步的,提取的关键词时,如果它所在的句子有参考文献,则可以暂且假设该关键词的标签是参考文献的类别,否则,该关键词的标签就是它所在文章的类别,基于此种假设,通过最小化交叉熵损失函数对模型进行训练:
[0058][0059]
其中y
k
是类别为k的节点集合,为第i个标签节点的k组输出,y
ik
是数据的原始类别,w
k
为类别k的权重,在模型训练过程中,采用梯度下降技术对参数进行优化。
[0060]
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料过着特点包含于本发明的至少一个实施
例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0061]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1