一种基于自组织特征的废气混合预测模型方法与流程
[0001]
本发明属于数值分析与深度学习技术领域,具体涉及一种基于自组织特征的废气混合预测模型方法。
背景技术:
[0002]
近几十年来,在各个领域,有许多的研究工作者对时间序列预测应用进行了大量的研究,使用的方法包括基于统计概率学、基于传统机器学习和基于深度学习等时序预测方法。20世纪40年代以来,人们提出了各种基于统计的时序预测方法,其中最为广泛使用是自回归模型(auto regressive,ar)、滑动平均模型(moving average,ma)和混合模型(arma)。ar、ma和arma都是平稳随机过程,不能用于非线性数据的分析。它们共同有着牢固的理论基础和完整建模方法,并且广泛应用于轨道交通、金融经济、环境监测等领域,但是却过分依赖平稳性、稳定性等假设,对数据要求较高,通用性弱,对短期预测效果较好,不太适合于中长期预测;使用传统机器学习方法模型进行实验,可以基本上解决以上非线性数据的预测。起初人工神经网络中使用最多的是bp神经网络,它具有较强的非线性映射能力,高度自学习和自适应的能力,将学习成果应用于新知识的能力和有一定的容错能力。但bp神经网络运用在5层以上神经网络在其收敛速度、预测能力和训练能力效果欠佳。目前,基于深度学习的时序数据预测方法得到了大量的关注和研究,广泛应用于食品、交通等领域。门限循环单元(gated recurrent unit,gru)具有更加简单的结构、更少的参数、更好的收敛性。应用于语音识别、自然语音处理和机器翻译等领域。在训练数据很大的情况下gru能节省很多时间。
[0003]
工业园区大气污染物浓度预测属于时间序列数据预测问题,具有明显的非线性特征,同时又受多种变量耦合影响,使预测建模变得更为复杂。神经网络模型在解决该问题上表现出一定的优势,但传统预测模型在具体应用时具有递推步数少、预测能力差等问题。针对大气污染物的预测中表现出的时序非线性、多变量耦合等特征,为克服目前单一的非平稳预测算法难以充分捕捉时序的复杂关联特性,同种预测模型对时序不同成份预测不准的难题,尝试结合分解算法与混合网络模型对非平稳时序进行预测。
技术实现要素:
[0004]
针对现有技术存在的缺陷,本发明提出改进时序分解的多模型融合方法,建立一种基于自组织模式特征的废气混合预测模型。首先,将复杂的原始数据进行经验模态分解(empirical mode decomposition,emd),根据各条imf的波动性、周期性等特征,分成3组,将各组内的imf相加,得到3条子模态时序数据;其次,将较为简单的子模态时序数据进行bp预测,较为复杂的两组子模态时序数据进行gru预测;最后,对3组子模态预测结果进行相加融合,得到原始数据的预测数据。
[0005]
本发明提出了一种混合的深度网络相结合的预测模型,该混合模型预测方法的具体技术方案如下:
[0006]
一种基于自组织特征的废气混合模型预测方法,其特征在于:所述方法的具体实现过程包括以下步骤:
[0007]
步骤1:经验模态分解与分类;
[0008]
步骤2:子模态时序数据预测;
[0009]
步骤3:多模型预测结果的融合及评估。
[0010]
进一步,所述的步骤1中,为了使数据的特征更加明显,使模型准确地挖掘数据特征并增强模型的可解释性,利用经验模态分解方法将原数据序列分解成三个不同类型的子模态数据,包括以下步骤:
[0011]
步骤1.1:对原数据序列进行emd分解,得到若干个imf分量;
[0012]
步骤1.2:计算每条imf分量的变化系数;
[0013]
步骤1.3:根据步骤1.2得到的变化系数对imf分量进行分类。
[0014]
进一步,所述步骤1.1中emd分解的具体分解过程包括以下步骤:
[0015]
步骤1.1.1:确定原数据序列x
t
所有的极大值点,并用三次样条插值函数拟合形成原数据序列的上包络线;
[0016]
步骤1.1.2:找出所有的极小值点,并将所有的极小值点通过三次样条插值函数拟合形成原数据序列的下包络线;
[0017]
步骤1.1.3:计算上包络线和下包络线的均值记作m
x
;
[0018]
步骤1.1.4:将原数据序列x
t
减去该序列上下包络的均值m
x
,得到一个新的数据序列n
t
;
[0019]
步骤1.1.5:判断n
t
是否满足imf分量的两个约束条件,若不满足,则把n
t
看作新的x
t
,重复步骤1.1.1至1.1.4,其约束条件为:
[0020]
(1)数据序列在整个时间序列范围内,极值点和过零点的数目相等或最多相差一个;
[0021]
(2)在任意时间点,极大值点的包络(上包络线)和极小值点的包络(下包络线)平均值为零,即上、下包络线相对于时间轴对称;
[0022]
步骤1.1.6:若n
t
满足imf分量的约束条件,则得到的n
t
就是一个模态分量 imf;
[0023]
步骤1.1.7:用原始数据序列x
t
减去步骤1.1.6中得到的imf分量n
t
,得到最新的序列r
t
=x
t-n
t
,把r
t
当作新的原数据序列x
t
重复步骤1.1.1至1.1.6,直到n
t
为常量或者单调函数,或者n
t
的最大值或最小值个数小于2时,emd迭代分解过程终止,得到所有imf分量与一个残差分量(res),emd的最终结果可表示为:
[0024]
x
t
=∑imf+res
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0025]
进一步,所述步骤1.2计算每条imf和res的变化系数r,其计算公式为:
[0026][0027]
其中,n是数据长度,d
i
是当前时刻的数据,d
i+1
是下一时刻的数据,i是观测点。
[0028]
进一步,所述步骤1.3根据步骤1.2得到的变化系数将imf分量分成三组:变化系数r>3.1和3.1>r>1的imf分别归为两组复杂的子模态数据,变化系数r<1 的imf归为一组简单的子模态数据。
[0029]
进一步,所述步骤2子模态时序数据预测过程具体包括以下步骤:
[0030]
步骤2.1所述两组复杂的子模态数据建立gru模型进行预测,gru模型在 t时刻的输出为h
t
,在t-1时刻的输出为h
t-1
,按如下过程得到模型输出:
[0031][0032]
其中,x
t
为t时刻该层隐藏层的输入,z
t
,r
t
,b
z
,b
r
分别为t时刻的更新门、重置门、当前候选激活和激活值,b
h
也是激活值,u
z
,u
r
,u
h
,w
z
,w
r
,w
h
为模型训练期间学习的权重矩阵,是输入x
t
和前一时刻输出h
t-1
的汇总,o是按元素进行的乘法运算符,σ和tanh是激活函数,分别用两个gru网络预测两组相对复杂的子模态数据;
[0033]
步骤2.2一组简单的子模态数据建立bp模型进行预测,bp模型的学习分解为正向和反向学习两个过程:在正向学习过程中,子模态数据进入输入层,由输入层的神经元再将其传递给中间层(隐层),子模态数据在中间层神经元激活函数的作用下进行变化处理后被传输至输出层,输出层将预测结果输出,随后将实际输出值和真实值进行比对,如若输出值和真实值存在误差,即转入反向传播;反向传播过程,将真实值作为期望输出,逐层递归地计算实际输出与期望输出之差,并依据此差值来调节各层权值,反复上述两个过程,直至误差调整至误差小于设定值时停止学习,具体的计算过程如下:
[0034]
在正向传播过程中,以一组子模态数据x
p
(共s个)作为输入信号,中间神经元的个数为k个,用j来表示第j个神经元,输出层的神经元个数用l表示。输入信号通过输入层传递给网络,信号正向传播过程如式(4)-(5)所示:
[0035][0036][0037]
y
l
=f(i
l
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(6)
[0038]
式中,x
p
是输入的子模态数据,ω
jp
为输入层与中间层之间的连接权值,ω
oj
为中间层与输出值之间的连接权值;
[0039]
输入的子模态数据经式(4)处理,得到中间层的输入net
j
,net
j
被传递到中间层后经过激活函数变换处理并通过式(5)得到输出i
l
,i
l
通过激活函数处理得到信号y
l
;
[0040]
将真实子模态数据d作为期望输出,当网络输出与期望输出不相等时,存在误差e:
[0041][0042]
若e<e时(e为设置的理想误差),计算结束,输出预测后的子模态数据;否则,进行反向传播;
[0043]
在反向传播过程中,使用神经网络的反馈调整来连续校正网络的权重,使得实际
输出接近期望值;已知误差e是权值ω
oj
、ω
jp
的函数,权值修正公式有:
[0044][0045][0046]
ω
oj
′
=ω
oj
+δω
oj
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0047]
ω
jp
′
=ω
jp
+δω
jp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0048]
式中,η是学习步长,是一个常数,0<η<1;
[0049]
通过式(8)-(11)得到更新后的权重ω
oj
′
和ω
jp
′
,进而调节输出值与期望之间的误差,把更新后的权重ω
oj
′
和ω
jp
′
当作最新的权重,然后继续转向式(4)开始正向传播。
[0050]
进一步,所述步骤3将各个网络的子输出相加以获得最终的预测结果,具体过程包括如下步骤:
[0051]
步骤3.1将步骤2中的两个gru网络和一个bp网络的输出结果进行相加运算,确保对应时间点的数据相加,可得到最终的预测结果;
[0052]
步骤3.2采用均方根误差(rmse)来预测模式预测能力的优劣,用来衡量预测值与真实值之间的误差,rmse的公式如式(12)所示,n是预测集的个数, x
t
(i)表示真实值,x
p
(i)表示预测值:
[0053][0054]
本发明与现有技术相比具有以下有益效果:
[0055]
采用gru和bp混合网络模型对时间序列数据进行预测,可充分捕捉时序的复杂关联特性,克服同种预测模型对时序不同成份预测不准的难题,进而有效地提取非平稳复杂数据的变化趋势,提高了预测模型的精度和鲁棒性,拓展了预测网络模型的应用范围
附图说明
[0056]
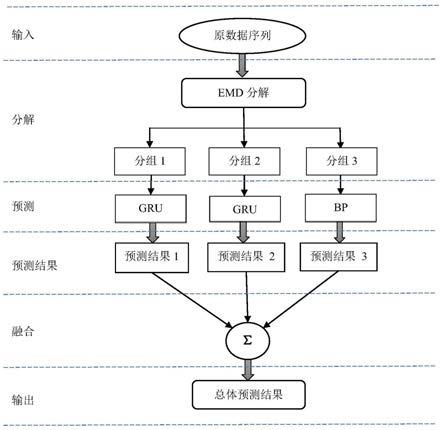
图1为基于模态分解的深度预测模型框架;
[0057]
图2为子模态时序数据分类流程;
[0058]
图3为emd分解结果;
[0059]
图4为工业园区so2数据预测结果;
[0060]
图5为工业园区so2数据预测绝对误差。
具体实施方式
[0061]
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
[0062]
本发明实施例给出一种基于自组织特征的废气混合模型预测方法,参考图 1,其为本发明实施例中提出的基于模态分解的深度预测模型框架,该方法具体包括:
[0063]
收集某市空气检测中心提供的四个月大气检测数据,对空气中的浓度进行分析预测。数据集共2900个数据,其中2000个作为训练集用于训练模型,900 个作为测试集用于测试模型。
[0064]
首先将so2浓度数据通过emd分解算法进行分解,分解成多个imf分量和一个res分量,其中imf分量需要满足两个约束条件:(1)数据序列在整个时间序列范围内,极值点和过零点的数目相等或最多相差一个;(2)在任意时间点,极大值的包络(上包络线)和极小值的包络(下包络线)平均值为零。emd分解的具体分解过程如下所示:
[0065]
(1)确定原数据序列x
t
所有的极大值点,并用三次样条插值函数拟合形成原数据序列的上包络线;
[0066]
(2)找出所有的极小值点,并将所有的极小值点通过三次样条插值函数拟合形成原数据序列的下包络线;
[0067]
(3)计算上包络线和下包络线的均值记作m
x
;
[0068]
(4)将原数据序列x
t
减去该序列上下包络的均值m
x
,得到一个新的数据序列n
t
;
[0069]
(5)判断n
t
是否满足imf分量的两个约束条件,若不满足,则把n
t
看作新的x
t
,重复步骤(1)-(4);
[0070]
(6)当n
t
满足imf分量的约束条件后,得到的n
t
就是一个模态分量imf;
[0071]
(7)用原始数据序列减去步骤(6)中得到的imf分量,得到最新的序列 r
t
=x
t-n
t
,把r
t
当作新的原数据序列x
t
重复步骤(1)-(6),直到n
t
为常量或者单调函数,或者n
t
的最大值或最小值个数小于2时,emd迭代分解过程终止,可得到其余imf分量与一个残差分量(res),emd的最终结果可表示为:
[0072]
x
t
=∑imf+res
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(13)
[0073]
通过emd分解后,得到10条imf分量和1条res分量,如附图3所示。
[0074]
参阅图2,其为子模态时序数据分类流程,然后对分解得到的10条imf分量和1条res分量进行分类,计算每条分量的变化系数r:
[0075][0076]
其中,n是数据长度,d
i
是当前时刻的数据,d
i+1
是下一时刻的数据,i是观测点。
[0077]
通过计算每条imf的变化系数,可以观察到,每条imf的变化系数相差过大,我们需要将imf分成三组,两组为相对复杂的,一组为相对简单的,将变化系数r>3.1的imf分为一组,这组定为相对复杂的一组,将变化系数3.1>r>1 的imf分为一组,这组也定为相对复杂的一组,将变化系数r<1的imf分为一组,这组定为相对简单的一组;然后通过变化系数将10条imf和1条res分成3组子模态数据,分组结果如表1所示:
[0078]
表1分组结果
[0079] 分量分组1(复杂)imf1,imf2分组2(复杂)imf3,imf4,imf5分组3(简单)imf6,imf7,imf8,imf9,imf10,res
[0080]
将三组子模态数据分别进行建模预测,将相对复杂的两组子模态数据用 gru模型预测,gru模型在t时刻的输出为h
t
,在t-1时刻的输出为h
t-1
,按如下过程得到模型输出:
[0081][0082]
其中,x
t
为t时刻该层隐藏层的输入,z
t
,r
t
,b
z
,b
r
分别为t时刻的更新门、重置门、当前候选激活和激活值,b
h
也是激活值,u
z
,u
r
,u
h
,w
z
,w
r
,w
h
为模型训练期间学习的权重矩阵,是输入x
t
和前一时刻输出h
t-1
的汇总,o是按元素进行的乘法运算符,σ和tanh是激活函数,分别用两个gru网络预测两组相对复杂的子模态数据;
[0083]
相对简单的一组子模态数据用bp模型预测,bp模型的学习分解为正向和反向学习两个过程:在正向学习过程,子模态数据进入输入层,由输入层的神经元再将其传递给中间层(隐层),子模态数据在中间层神经元激活函数的作用下进行变化处理后被传输至输出层,输出层将预测结果输出,随后将实际输出值和真实值进行比对,如若输出值和真实值存在误差,即转入反向传播;反向传播过程,将真实值作为期望输出,逐层递归地计算实际输出与期望输出之差,并依据此差值来调节各层权值,反复上述两个过程,直至误差调整至误差小于设定值时停止学习,具体的计算过程如下:
[0084]
在正向传播过程中,以一组子模态数据x
p
(共s个)作为输入信号,中间神经元的个数为k个,用j来表示第j个神经元,输出层的神经元个数用l表示,输入信号通过输入层传递给网络,信号正向传播过程如式(16)-(17)所示:
[0085][0086][0087]
y
l
=f(i
l
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(18)
[0088]
式中,x
p
是输入的子模态数据,ω
jp
为输入层与中间层之间的连接权值,ω
oj
为中间层与输出值之间的连接权值。
[0089]
输入的子模态数据经式(16)处理,得到中间层的输入net
j
,net
j
被传递到中间层后经过激活函数变换处理并通过式(17)得到输出i
l
,i
l
通过激活函数处理得到信号y
l
。
[0090]
将真实子模态数据d作为期望输出,当网络输出与期望输出不相等时,存在误差e:
[0091][0092]
若e<e时(e为设置的理想误差),计算结束,输出预测后的子模态数据;否则,进行反向传播;
[0093]
在反向传播过程中,使用神经网络的反馈调整来连续校正网络的权重,使得实际输出接近期望值;已知误差e是权值ω
oj
、ω
jp
的函数,权值修正公式有:
[0094][0095][0096]
ω
oj
′
=ω
oj
+δω
oj
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(22)
[0097]
ω
jp
′
=ω
jp
+δω
jp
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(23)
[0098]
式中,η是学习步长,是一个常数,0<η<1;
[0099]
通过式(20)-(23)得到更新后的权重ω
oj
′
和ω
jp
′
,进而调节输出值与期望之间的误差,把更新后的权重ω
oj
′
和ω
jp
′
当作最新的权重,然后继续转向式(16)开始正向传播。
[0100]
将各个网络的子输出相加以获得最终的预测结果。对整个网络进行不断训练,训练得到了相应的模型,最后将测试集输入到训练好的模型里进行测试。
[0101]
测试数据的部分预测结果如附图4所示,对应的绝对误差如附图5所示,通过均方根误差公式(24)计算出rmse为4.15。由此可见,在数据复杂的情况下,本发明可有效提取非平稳复杂数据的变化趋势,并可较为准确地预测时序变化值。
[0102][0103]
其中,n是预测集的个数,x
t
(i)表示真实值,x
p
(i)表示预测值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1