一种用于广告投放的投放舆情监测方法与流程
[0001]
本发明涉及一种nlp领域的关于广告投放的舆情监控算法,具体地,涉及一种用于广告投放的投放舆情监测方法。
背景技术:
[0002]
当今社会媒体的发展导致了舆情评论的爆炸式增长,尤其是自媒体发展最为迅速,从而以自媒体为基础的kol广告投放和信息流广告投放愈发受到企业重视,其中kol渠道包括微信、b站等,信息流渠道包括抖音、快手等。而两种投放方式在广告投放后都会涉及到舆情评论,一方面舆情评论涉及到企业形象公关,另一方面根据企业内部数据分析,舆情评论好坏对该次广告投放成果大小有明显相关。所以实时的广告投放舆情监控对于企业而言至关重要。广告投放流程图参见图1所示。
[0003]
在人工智能和自然语言处理领域,近年来nlp(natural language processing,自然语言处理)领域发展迅速,理财教育行业人工智能在广告投放领域落地情况并不多。
[0004]
nlp领域文本分类发展迅速,但是广告投放评论的舆情监控面临负面语料少、难以识别负面评论、对kol号主的负面评价并非对公司的负面评价,二者难以很好地区分等问题,是难以落地的关键。
技术实现要素:
[0005]
本发明的目的是提供一种关于广告投放的舆情监控算法,通过基于多种方法的增强数据和语料生成的舆情数据增强模块,应用于基于bert系列多模型融合的舆情分类,并取得了较好的成绩。
[0006]
本发明提供了一种用于广告投放的投放舆情监测方法,其中,所述的方法是通过bert、albert、roberta三种深度学习模型,根据广告投放后用户评论数据,采用多个模型融合,训练或预训练模型,提取文本特征,增强数据,并生成相似语料,作为语料扩充,再应用于下游的舆情分类任务中解决标注数据少的问题。
[0007]
上述的用于广告投放的投放舆情监测方法,其中,所述的方法包含:步骤1、使用爬虫技术从投放广告渠道爬取投放广告发文下的评论,并存储评论到数据库;步骤2、使用舆情监控数据增强和语料生成模块对数据进行扩充和增强;步骤3、分别使用bert、albert、roberta算法构建模型;步骤4、采用多模型融合方案,融合bert、albert、roberta三个模型所得的结果;步骤5、完成线上环境部署和优化。
[0008]
上述的用于广告投放的投放舆情监测方法,其中,所述的步骤1中的渠道包含抖音、快手、b站。
[0009]
上述的用于广告投放的投放舆情监测方法,其中,所述的步骤2中的数据增强和语料生成模块是使用增删改换、基于词性和句法替换关键词、回译、深度学习生成相融合的方式进行数据增强,并生成语料。
[0010]
上述的用于广告投放的投放舆情监测方法,其中,所述的步骤3中的bert、albert、
roberta三个模型都是使用transformer结构的预训练模型。
[0011]
上述的用于广告投放的投放舆情监测方法,其中,所述的步骤3中的bert是开源预训练模型,albert是对bert模型的优化模型,roberta是对bert的另一种优化模型。
[0012]
上述的用于广告投放的投放舆情监测方法,其中,所述的步骤5中的线上环境部署是部署在两台rtx600024g的gpu服务器,线上环境优化服务性能解决高并发问题,响应速度控制在300ms以内。
[0013]
上述的用于广告投放的投放舆情监测方法,其中,所述的优化,其过程包含:模型计算图的gpu并行计算、bert预处理过程并行计算、多模型并行计算。
[0014]
本发明提供的用于广告投放的投放舆情监测方法具有以下优点:
[0015]
本发明主要应用于理财教育行业广告投放舆情分析领域,提供了一种基于少量标注数据和多种模型融合来解决语料不足问题和实现舆情分类的方法,通过albert、roberta、xlnet等当前前沿的深度学习模型,根据广告投放后用户评论数据,考虑语料扩充的多样性,采用多个模型融合,训练或预训练模型,提取文本feature,数据增强,并生成相似语料,作为语料扩充,并应用于下游的舆情分类任务中解决标注数据少的问题,实现精准的舆情分析,洞察用户反应,及时发现,快速调整,以减少广告投放对公司的负面影响。
[0016]
使用本发明提供的方法具有的优点还包括:
[0017]
1.多种数据增强模型来扩充语料,解决了舆情分类模型中的负面评价少的问题。
[0018]
2.使用了多模型融合的方案,在语料开发性非常强的情况下,既保证了模型的泛化能力,又提高了模型的准确率。
[0019]
3.在模型落地上考虑并发问题,针对模型的特性进行工程上的优化,使得响应时间控制在300以内。
附图说明
[0020]
图1为现有的广告投放流程图。
[0021]
图2为本发明的用于广告投放的投放舆情监测方法的示意图。
[0022]
图3为本发明的用于广告投放的投放舆情监测方法的transfomer结构示意图。
[0023]
图4为本发明的用于广告投放的投放舆情监测方法的bert示意图。
[0024]
图5为本发明的用于广告投放的投放舆情监测方法的多模型融合示意图。
[0025]
图6为本发明的用于广告投放的投放舆情监测方法的合并模型示意图。
[0026]
图7为本发明的用于广告投放的投放舆情监测方法的在线上环境部署和优化示意图。
[0027]
图8为本发明的用于广告投放的投放舆情监测方法的爬虫服务的爬取过程示意图。
具体实施方式
[0028]
以下结合附图对本发明的具体实施方式作进一步地说明。
[0029]
本发明提供了一种用于广告投放的投放舆情监测方法,该方法是通过bert、albert、roberta三种深度学习模型,根据广告投放后用户评论数据,采用多个模型融合,训练或预训练模型,提取文本特征,增强数据,并生成相似语料,作为语料扩充,再应用于下游
的舆情分类任务中解决标注数据少的问题。
[0030]
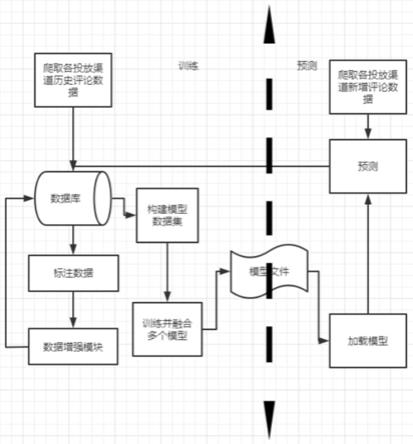
优选地,该方法包含:步骤1、使用爬虫技术从投放广告渠道爬取投放广告发文下的评论,并存储评论到数据库;步骤2、将数据库中的数据进行标注,例如通过人工标注,再使用舆情监控数据增强和语料生成模块对数据进行扩充和增强;步骤3、对数据库中扩充和增强后的数据,构建模型数据集,分别使用bert、albert、roberta算法构建模型;步骤4、训练并融合多个模型,采用多模型融合方案,融合bert、albert、roberta三个模型所得的结果;得到模型文件,然后加载模型;步骤5、完成线上环境部署和优化;最后爬取各投放渠道新增评论数据,用所得的模型进行预测,并存储评论到数据库。参见图2所示。
[0031]
步骤1中的渠道包含抖音、快手、b站等。
[0032]
步骤2中的数据增强和语料生成模块是使用“增删改换”、基于词性和句法替换关键词、回译、深度学习生成等方法相融合的方式进行数据增强,并生成语料,保证了语料生成的多样性。
[0033]
在构建数据集时,考虑对kol号主的差评并非对公司的差评,需要过滤掉,所以在样本构建过程中,将数据增强技术不仅应用于对公司的差评,对每一类数据都标注并使用,保证了对号主差、好、中评论和对公司好、差、中评等数据等数据的均衡,从而使模型取得了更好的效果。
[0034]
步骤3中的bert、albert、roberta三个模型都是使用transformer结构的预训练模型,在处理不同问题时候各有优势,所以在使用这些模型的时候,采用了多模型融合的方案。transformer结构参见图3所示。
[0035]
步骤3中的bert是2018年10月谷歌提出的开源预训练模型。参见图4所示。
[0036]
bert(bidirectional encoder representations from transformers)是一个预训练的模型,bert的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。在以后特定的nlp任务中,可以直接使用bert的特征表示作为该任务的词嵌入特征。所以bert提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。
[0037]
其中,为了训练双向特征,采用masked language model的预训练方法,随机mask句子中的部分token,然后训练模型来预测被去掉的token。
[0038]
albert是2019年9月份提出的对bert模型的优化模型,其主要是transformer参数共享参数共享,emebdding矩阵分解时使用了更少的维度,而在hidden上使用更大维度。
[0039]
roberta是对bert的另一种优化模型,取消了nsp,即预测下一个句子的步骤,同时用了更大的batch_size和更多的语料。
[0040]
步骤4、采用多模型融合方案,融合结果。
[0041]
在舆情分类模型开发中,使用前沿的bert系列算法,采用多模型融合的方案,取得了高于单模型的效果。
[0042]
优选地,步骤4是将基础数据通过多个算法分别得出预测结果,然后合并模型,首先进行数据处理,然后训练数据,再训练模型,接着评估模型,根据结果选择重复训练模型或进行模型输出。参见图5所示。
[0043]
合并模型是采用自助抽样法对原始数据进行若干次采样,再将不同的采样数据通
过模型训练,得到不同的模型结果,然后通过自动投票评估,最后融合模型。参见图6所示。
[0044]
步骤5中的线上环境部署是部署在两台rtx600024g的gpu服务器,线上环境,优化服务性能解决高并发问题,响应速度控制在300ms以内。参见图7所示。
[0045]
优化过程包含:模型计算图的gpu并行计算、bert预处理过程并行计算、多模型并行计算等。
[0046]
下面结合实施例对本发明提供的用于广告投放的投放舆情监测方法做更进一步描述。
[0047]
实施例1
[0048]
一种用于广告投放的投放舆情监测方法,其包含:
[0049]
s1、使用爬虫技术从投放广告的抖音、快手、b站等渠道,爬取投放广告发文下的评论,并存储评论到数据库。爬虫服务的爬取过程参见图8所示。
[0050]
具体包含:
[0051]
1.1爬虫服务通过scrapy-redis发布,爬虫服务监听redis,等待请求任务数据。每个任务通过azkaban调度,生成请求url到redis中,触发爬虫服务执行。
[0052]
1.2爬虫抓取数据后将结果写入到oss,同时将结果发布到kafka(topic=crawl_data);
[0053]
1.3清洗服务订阅kafka(topic=crawl_data),获取爬虫数据,将数据清洗后发布kafka(topic=etl_data);
[0054]
1.4模型服务订阅kafka(topic=etl_data),获取清洗后数据,将数据发布到celery,由celery调度对应的模型处理模块model_worker。model_worker处理结果发布到kafka(topic=model);
[0055]
1.5应用服务订阅kafka(topic=model),将模型结果写入数据库。
[0056]
1.6对模型数据结果在内部平台进行展示。同时对舆情分析结果实时发送到相关人员邮箱。
[0057]
s2、使用舆情监控数据增强、语料生成模块对数据进行扩充和增强。
[0058]
s3、分别使用bert、albert、roberta构建模型。
[0059]
s4、使用多模型融合方案,融合结果。
[0060]
s5、在线上环境部署,部署在两台rtx600024g的gpu服务器。线上环境,优化服务性能解决高并发问题,响应速度控制在300ms以内。优化过程包括:模型计算图的gpu并行计算,bert预处理过程并行计算,多模型并行计算等。
[0061]
本发明提供的用于广告投放的投放舆情监测方法,是对理财教育、保险行业等广告投放后的网络舆情评论,通过自然语言处理技术智能监控、分析、判断,洞察广告受众对该次广告投放行为的反应,为企业广告投放和企业公关实时提供数据支持。本发明采用的算法涉及自然语言理解与处理,使用深度学习的方法,深化语义理解,识别情感,尤其是将学术界最前沿技术使用到理财教育和保险行业广告投放的舆情分析领域,属于基于保险行业、理财教育行业的人工智能领域、自然语言理解与处理领域的舆情监控。
[0062]
尽管本发明的内容已经通过上述优选实施例作了详细介绍,但应当认识到上述的描述不应被认为是对本发明的限制。在本领域技术人员阅读了上述内容后,对于本发明的多种修改和替代都将是显而易见的。因此,本发明的保护范围应由所附的权利要求来限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1