一种恶意代码分类结果的精确度验证方法及装置与流程
[0001]
本发明涉及信息安全技术领域,尤其涉及一种恶意代码分类结果的精确度验证方法及装置。
背景技术:
[0002]
随着互联网的快速发展,计算机软件的安全问题已经提高到国家安全的战略角度。建立安全可信的计算机软件系统成为维护计算机信息安全的一种有效手段,对于恶意代码的检测成为软件可信性分析的一个核心研究方向。
[0003]
目前,针对恶意代码的分类,传统机器学习模型在特征提取阶段往往需要人工设计和参与,这需要完备的先验知识,并且不能从数据本质出发提取恶意代码区分度较大的特征,在一定程度上影响了恶意代码的分类精确率;另外,该方法需要较为复杂、耗费时间且浪费资源。因此,在当下海量恶意代码背景下,传统的恶意代码分类方法已经不能满足恶意代码分类高效性要求了。
技术实现要素:
[0004]
鉴于上述的分析,本发明实施例旨在提供一种恶意代码分类结果的精确度验证方法及装置,用以解决现有的恶意代码分类方法耗费时间和资源且效率较低的问题。
[0005]
一方面,本发明实施例提供了一种恶意代码分类结果的精确度验证方法,包括下述步骤:
[0006]
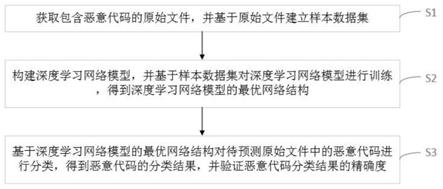
获取包含恶意代码的原始文件,并基于所述原始文件建立样本数据集;
[0007]
构建深度学习网络模型,并基于所述样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构;
[0008]
基于所述深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,得到恶意代码的分类结果,并验证所述恶意代码分类结果的精确度。
[0009]
进一步,获取包含恶意代码的原始文件,并基于所述原始文件建立样本数据集,包括下述步骤:
[0010]
基于所述包含恶意代码的原始文件,得到指定序列长度的二进制代码;
[0011]
对所述指定序列长度的二进制代码进行预处理,得到二进制文件列表;
[0012]
为所述二进制文件列表中的每个恶意代码添加标签,得到样本数据集。
[0013]
进一步,所述恶意代码的标签包括ramnit、lollipop、kelihos_ver3、vundo、simda、tracur、kelihos_ver1、obfuscator.acy和gatak。
[0014]
进一步,所述深度学习网络模型包括卷积神经网络和长短期记忆网络,其中,所述卷积神经网络包括依次连接的卷积层、池化层、全连接层、归一化层和第一输出层;
[0015]
所述长短期记忆网络包括正向lstm层、反向lstm层和第二输出层,其中,所述第二输出层用于将所述正向lstm层的输出特征与反向lstm层的输出特征进行拼接并输出。
[0016]
进一步,基于所述样本数据集对深度学习网络模型进行训练,得到深度学习网络
模型的最优网络结构,包括下述步骤:
[0017]
将所述样本数据集划分为训练数据集和验证数据集;
[0018]
将所述训练数据集输入深度学习网络模型进行训练,得到训练好的深度学习网络;
[0019]
基于所述验证数据集对训练好的深度学习网络进行验证,得到深度学习网络模型的最优网络结构。
[0020]
进一步,基于所述深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,得到恶意代码的分类结果,并验证所述恶意代码分类结果的精确度,包括下述步骤:
[0021]
将所述包含恶意代码的待预测原始文件输入深度学习网络模型的最优网络结构,得到恶意代码的分类结果和预测结果;
[0022]
基于所述预测结果计算精确率和召回率;
[0023]
基于所述精确率和召回率得到分类结果对应的f1分数,其中,所述f1分数越大,则恶意代码分类结果的精确度越高。
[0024]
另一方面,本发明实施例提供了一种恶意代码分类结果的精确度验证装置,包括:
[0025]
样本数据集构建模块,用于获取包含恶意代码的原始文件,并基于所述原始文件建立样本数据集;
[0026]
模型训练模块,用于构建深度学习网络模型,并基于所述样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构;
[0027]
分类结果的精确度验证模块,用于根据所述深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,得到恶意代码的分类结果,并验证所述恶意代码分类结果的精确度。
[0028]
进一步,所述样本数据集构建模块用于:
[0029]
基于所述包含恶意代码的原始文件,得到指定序列长度的二进制代码;
[0030]
对所述指定序列长度的二进制代码进行预处理,得到二进制代码文件列表;
[0031]
为所述二进制代码文件列表中的每个恶意代码添加标签,得到样本数据集。
[0032]
进一步,所述恶意代码的标签包括ramnit、lollipop、kelihos_ver3、vundo、simda、tracur、kelihos_ver1、obfuscator.acy和gatak。
[0033]
进一步,所述深度学习网络模型包括卷积神经网络和长短期记忆网络,其中,所述卷积神经网络包括依次连接的卷积层、池化层、全连接层、归一化层和第一输出层;
[0034]
所述长短期记忆网络包括正向lstm层、反向lstm层和第二输出层,其中,所述第二输出层用于将所述正向lstm层的输出特征与反向lstm层的输出特征进行拼接并输出。
[0035]
与现有技术相比,本发明至少可实现如下有益效果之一:
[0036]
1、一种恶意代码分类结果的精确度验证方法,通过建立样本数据集,并利用样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构,最后将包含恶意代码的待预测原始文件输入最优网络结构进行分类,得到恶意代码的分类结果,并通过计算f1分数验证恶意代码分类结果的精确度,简单易行、易于实施,提高了恶意代码的分类效率和可靠性,具有较高的实用价值。
[0037]
2、采用类别均衡采样法对指定序列长度的二进制代码进行预处理,得到二进制文
件列表,并为二进制文件列表中的每个恶意代码添加标签,恶意代码与其对应的标签构成了样本数据集,为后期深度学习网络模型的训练提供了数据支撑和依据。
[0038]
3、通过构建深度学习网络模型,并利用训练数据集对深度学习网络模型进行训练,得到训练好的深度学习网络,并利用验证数据集对训练好的深度学习网络进行训练,得到深度学习网络模型的最优网络结构,为后期对待预测原始文件中的恶意代码分类提供了基础,且能够提高恶意代码分类的精度。
[0039]
4、基于深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,同时得到恶意代码的分类结果和预测结果,并基于预测结果计算精确率和召回率,最终得到f1分数,基于f1分数验证恶意代码分类结果的精确度,具有较高的实用性。
[0040]
本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
附图说明
[0041]
附图仅用于示出具体实施例的目的,而并不认为是对本发明的限制,在整个附图中,相同的参考符号表示相同的部件。
[0042]
图1为一个实施例中恶意代码分类结果的精确度验证方法流程图;
[0043]
图2为一个实施例中深度学习网络模型结构示意图;
[0044]
图3为另一个实施例中恶意代码分类结果的精确度验证装置结构图;
[0045]
附图标记:
[0046]
100-样本数据集构建模块,200-模型训练模块,300-分类结果的精确度验证模块。
具体实施方式
[0047]
下面结合附图来具体描述本发明的优选实施例,其中,附图构成本申请一部分,并与本发明的实施例一起用于阐释本发明的原理,并非用于限定本发明的范围。
[0048]
目前,针对恶意代码的分类,传统机器学习模型在特征提取阶段往往需要人工设计和参与,这需要完备的先验知识,并且不能从数据本质出发提取恶意代码区分度较大的特征,在一定程度上影响了恶意代码的分类精确率;另外,该方法需要较为复杂、耗费时间且浪费资源。因此,在当下海量恶意代码背景下,传统的恶意代码分类方法已经不能满足恶意代码分类高效性要求了。为此,本申请提出了一种恶意代码分类结果的精确度验证方法及装置,通过建立样本数据集,并利用样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构,最后将包含恶意代码的待预测原始文件输入最优网络结构进行分类,得到恶意代码的分类结果,并通过计算f1分数验证恶意代码分类结果的精确度,简单易行、易于实施,提高了恶意代码的分类效率,具有较高的实用价值。
[0049]
本发明的一个具体实施例,公开了一种恶意代码分类结果的精确度验证方法,如图1所示,包括下述步骤s1~s3。
[0050]
步骤s1、获取包含恶意代码的原始文件,并基于原始文件建立样本数据集,包括下述步骤s101~s103。
[0051]
步骤s101、基于包含恶意代码的原始文件,得到指定序列长度的二进制代码。其中,采用opencv计算机视觉库对包含恶意代码的原始文件进行压缩,得到指定序列长度为sequence_length的二进制代码。
[0052]
步骤s102、对指定序列长度的二进制代码进行预处理,得到二进制文件列表。具体来说,采用类别均衡采样法对得到的指定序列长度的二进制代码进行预处理的步骤包括:首先按照恶意代码的类别顺序对指定序列长度的二进制代码进行排序,统计每个类别的二进制代码数目并记录二进制代码的最大值;根据该最大值对每类二进制代码产生一个随机排列的列表,然后用此列表中的随机数对各自类别的二进制代码取余,得到对应的索引值。根据索引从该类的二进制代码中随机提取相应数值的二进制代码,生成该类二进制代码的随机列表。最后将所有类别二进制代码的随机列表连在一起并随机打乱次序,即可得到最终的二进制文件列表,可以发现最终的二进制文件列表中每类二进制代码数目均等。
[0053]
步骤s103、为二进制文件列表中的每个恶意代码添加标签,得到样本数据集。其中,恶意代码的标签包括ramnit、lollipop、kelihos_ver3、vundo、simda、tracur、kelihos_ver1、obfuscator.acy和gatak。
[0054]
采用类别均衡采样法对指定序列长度的二进制代码进行预处理,得到二进制文件列表,并为二进制文件列表中的每个恶意代码添加标签,恶意代码与其对应的标签构成了样本数据集,为后期深度学习网络模型的训练提供了数据支撑和依据。
[0055]
步骤s2、构建深度学习网络模型,并基于样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构。如图2所示,深度学习网络模型包括卷积神经网络和长短期记忆网络,其中,卷积神经网络包括依次连接的卷积层、池化层、全连接层、归一化层和第一输出层;长短期记忆网络包括正向lstm层、反向lstm层和第二输出层。其中,卷积神经网络中第一输出层的输出特征同时作为正向lstm层和反向lstm层的输入,第二输出层用于将正向lstm层的输出特征与反向lstm层的输出特征进行拼接并输出。
[0056]
构建得到深度学习网络模型后,可利用样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构,包括下述步骤:
[0057]
将样本数据集划分为训练数据集和验证数据集。示例性的,本申请中可将样本数据集按照9:1的比例划分为训练数据集和验证数据集,其中,训练数据集用于对深度学习网络模型进行训练,以得到训练好的深度学习网络;验证数据集用于对训练好的深度学习网络进行验证,以得到深度学习网络的最优网络结构。
[0058]
将训练数据集输入深度学习网络模型进行训练,得到训练好的深度学习网络,具体包括下述步骤:
[0059]
首先对参数初始化:令v
dw
=0,s
dw
=0,v
db
=0,s
db
=0,且设置迭代次数epochs为100,其中,w为权重;b为偏移量;dw和db为w和b的微分,v
dw
为dw的平均数,s
dw
为dw的指数加权平均数;v
db
为db的平均数,s
db
为db的指数加权平均数。
[0060]
在第t次迭代中,利用梯度下降法计算得到dw和db。同时设dw的指数加权平均数β1为0.9,计算v
dw
和v
db
:
[0061]
v
dw
=β1v
dw
+(1-β1)dw
[0062]
v
db
=β1v
db
+(1-β1)db
[0063]
设超参数β2为0.999,用rmsprop更新s
dw
和s
db
:
[0064]
s
dw
=β2s
dw
+(1-β2)(dw)2[0065]
s
db
=β2s
db
+(1-β2)(db)2;
[0066]
计算v
dw
、v
db
、s
dw
和s
db
分别对应的修正误差和
[0067][0068][0069][0070][0071]
设阈值门槛ε为10-8
,学习率α为0.001,对深度学习模型卷积层的权重进行修正,令训练收敛到更好的性能,修正后的权重w
′
和修正后的偏移量b
′
分别为:
[0072][0073][0074]
基于修正后的权重和偏移量计算得到网络对应的损失函数,当损失函数小于预设损失函数门槛时,得到对应的训练好的深度学习网络;若损失函数不小于预设损失函数门槛,继续调整参数,直至满足条件,得到对应的训练好的深度学习网络。同时,可利用验证数据集对训练好的深度学习网络进行验证,得到深度学习网络模型的最优网络结构。
[0075]
通过构建深度学习网络模型,并利用训练数据集对深度学习网络模型进行训练,得到训练好的深度学习网络,并利用验证数据集对训练好的深度学习网络进行训练,得到深度学习网络模型的最优网络结构,为后期对待预测原始文件中的恶意代码分类提供了基础,且能够提高恶意代码分类的精度。
[0076]
步骤s3、基于深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,得到恶意代码的分类结果,并验证恶意代码分类结果的精确度,包括下述步骤s301~s303:
[0077]
步骤s301、将包含恶意代码的待预测原始文件输入深度学习网络模型的最优网络结构,得到恶意代码的分类结果和预测结果。详细地,将包含恶意代码的待预测原始文件输入深度学习网络模型的最优网络结构后,同时得到的恶意代码的分类结果和预测结果。其中,预测结果包括tp(将正确的判断正确)、fp(将正确的判断错误)、fn(将错误的判断错误)和tn(将错误的判断正确)四种,可统计得到这四种预测结果的数量。
[0078]
步骤s302、基于预测结果计算精确率precision和召回率recall:
[0079][0080]
[0081]
步骤s303、基于精确率和召回率得到分类结果对应的f1分数,f1分数为精确率和召回率的调和平均值,其中,f1分数越大,则恶意代码分类结果的精确度越高,f1分数的计算公式为:
[0082][0083]
基于深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,同时得到了恶意代码的分类结果和预测结果,并基于预测结果计算精确率和召回率,最终得到f1分数,利用f1分数验证恶意代码分类结果的精确度,具有较高的实用性。
[0084]
与现有技术相比,本实施例提供的一种恶意代码分类结果的精确度验证方法,通过建立样本数据集,并利用样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构,最后将包含恶意代码的待预测原始文件输入最优网络结构进行分类,得到恶意代码的分类结果,并通过计算f1分数验证恶意代码分类结果的精确度,简单易行、易于实施,提高了恶意代码的分类效率。
[0085]
本发明的另一个具体实施例,公开了一种恶意代码分类结果的精确度验证装置,如图3所示,包括样本数据集构建模块100,用于获取包含恶意代码的原始文件,并基于原始文件建立样本数据集;模型训练模块200,用于构建深度学习网络模型,并基于样本数据集对深度学习网络模型进行训练,得到深度学习网络模型的最优网络结构;分类结果的精确度验证模块300,用于根据深度学习网络模型的最优网络结构对待预测原始文件中的恶意代码进行分类,得到恶意代码的分类结果,并验证恶意代码分类结果的精确度。
[0086]
由于恶意代码分类结果的精确度验证装置与前述恶意代码分类结果的精确度验证的实现原理相同,故这里不再赘述。
[0087]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1