一种基于CNN的三级信息融合视觉目标跟踪方法与流程
一种基于cnn的三级信息融合视觉目标跟踪方法
技术领域
[0001]
本发明属于图像处理与模式识别领域,特别是一种深度学习和孪生网络的视觉目标跟踪方法。
背景技术:
[0002]
视觉目标跟踪作为图像处理与模式识别的重要分支,是人工智能中具有重要研究意义的课题。其任务是指定当前图像序列中的一个特定目标,在随后图像序列播放过程中,使用矩形边界框将该特定目标锁定,实现跟踪效果。当前该方向已经发展到基于深度学习解决非约束环境下的跟踪问题。随着5g技术的普及与计算机算力的加强,视觉目标技术受到了更多的重视,其应用场景也更为广阔。智能服务机器人通过摄像头采集视频信号,然后确定跟踪目标,最后自动地对目标进行跟踪并提供相应的服务。在汽车行驶过程中,判断车辆和周围事物的运动状态,对汽车的速度和行进轨迹进行调整。当前的医疗影响涵盖丰富的人体信息,诗句目标跟踪可以找到对应的目标信息,在整个医疗影像中进行跟踪,从而实现更精准的临床诊断。除此之外,视觉目标跟踪技术在人机交互、视觉导航、农业自动化生产等领域有着至关重要的地位。
技术实现要素:
[0003]
针对现有技术的不足,本发明提出了一种具有更高准确率、鲁棒性的视觉目标跟踪方法。
[0004]
为了实现上述目的,本发明采用的技术方案是,一种基于cnn的三级信息融合视觉目标跟踪方法,包括以下步骤:
[0005]
s1:对当前序列图像,提取模板图像和检测图像,进行图像预处理。
[0006]
s2:采用siamese孪生网络构建整体网络框架,将模板图像和检测图像分别输入两个相同的分支网络进行同步处理,分支网络采用改进后的vgg-11网络。 vgg-11相比siamese框架自带的alexnet能够带来更好的特征提取能力,提升系统的性能。
[0007]
s3:改进后的vgg-11网络采用三级网络融合策略,将整个网络分为浅层、中层、深层三个部分,通过cnn分别提取三个部分的各层卷积特征,对每个部分的各层卷积特征进行融合,得到特征图。
[0008]
s4:对两个分支网络中三个部分的特征图,按照浅层、中层、深层三个层次分别进行相关操作,构建三个层次的得分图。
[0009]
s5:对步骤s4中三个层次的得分图进行融合,构建出最终得分图。
[0010]
s6:使用最终得分图输出跟踪结果。
[0011]
本发明通过三级融合策略,浅层的外观特征将和深层的语义特征相融合,共同构建当前目标的特征图,能够在准确分类的情况下实现更精准的定位。步骤s5通过三级融合策略获得的融合特征图,将在得分图这一维度进行进一步融合,以达到充分利用各级别特征信息的目的。
[0012]
在测试数据集otb2015中,本方法获得了0.886的准确率和0.655的成功率,相比同样的siamese框架跟踪器分别提升9.52%和7.91%。;在测试数据集 vot2016中,本方法获得了0.3896的准确率和15.7913的鲁棒性,相比同框架跟踪器分别提升14.22%和21.56%。所以本发明具有更高准确率、鲁棒性。
附图说明
[0013]
图1为siamese网络框图;
[0014]
图2为vgg-11网络;
[0015]
图3为浅层到深层特征尺寸变化图;
[0016]
图4为三级信息融合流程图。
具体实施方式
[0017]
参见图1,一种基于cnn的三级信息融合视觉目标跟踪方法,其包括以下步骤:
[0018]
s1:对当前序列图像,选取第一帧为模板图像,后续帧为检测图像,进行图像预处理,以视觉目标为中心对图像进行裁剪,模板图像大小裁剪为127
×
127,检测图像大小裁剪为255
×
255,裁剪时超出的范围使用图像的rgb均值进行填充。
[0019]
s2:采用siamese孪生网络作为整体框架,即模板图像和检测图像将分别输入两个相同的分支进行同步处理,分支网络采用改进后的vgg-11网络;网络的两个分支共享权重,分别将两个输入送入两个分支,输出他们的相似度。从而将目标跟踪转换成相似性学习问题,这很好的匹配了目标跟踪的本质,即求取模板图像和检测图像的相似度。
[0020]
s3:对每个分支,采用三级信息融合策略,将整个vgg网络分为浅层、中层、深层三个部分,对每个部分的各层卷积特征进行融合。具体的,第三层卷积层conv3将通过3
×
1卷积和conv4构建浅层融合特征图,然后孪生网络的一对浅层融合特征图通过4
×
256卷积构建浅层得分图;同理,conv5、conv6、conv7 通过3
×
1卷积构建中层融合特征图,再通过2
×
256卷积构建中层得分图;conv8、conv9、conv11通过3
×
1卷积构建深层融合特征图,最后得到深层得分图。如图 3和图4所示。
[0021]
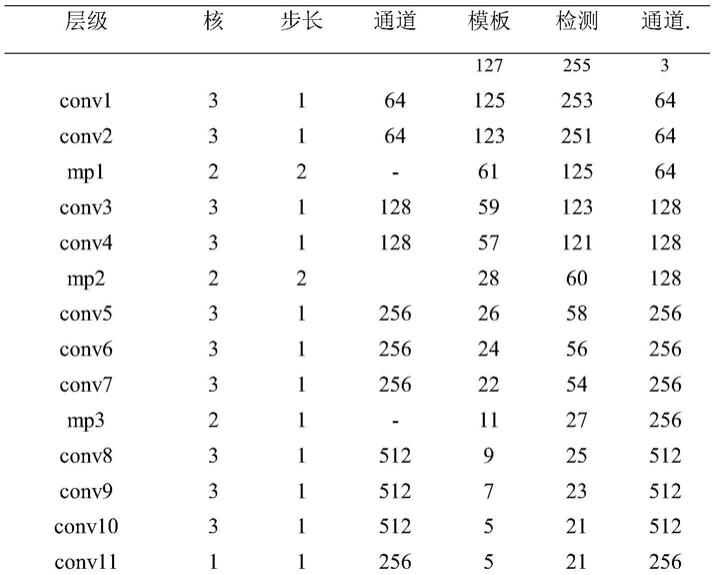
如图2和下表所示,vgg-11将网络层数从16层减少到11层,在2层和3 层,4层和5层,7层和8层之间设置最大池化层。将11层网络分为浅层、中层、深层三个级别,其中3、4层为浅层,5、6、7层为中层,8、9、11层为深层。浅层特征包含更多的外观信息,具有更好的定位属性;深层特征包含更多的语义信息,具有更好的分类属性;中层特征居中。
[0022][0023]
s4:根据siamese孪生框架,在三个层次,分别将对应的融合特征进行相关操作,构建出三个层次的得分图,公式为s(z,x)=f(φ(z),φ(x));其中z表示模板图像,x表示检测图像,φ(
·
)表示图像的特征表示,f(
·
)表示相关操作,s(z,x)表示模板图像和检测图像之间的相似性,网络的目标就是获取以上公式的最大值。
[0024]
s5:对三个层次的得分图进行融合,构建出最终得分图,公式为 s(z,x)=s1(z,x)+s2(z,x)+s3(z,x),其中s1(z,x),s2(z,x),s3(z,x)分别表示浅层、中层、深层的得分图。
[0025]
s6:使用最终得分图输出跟踪结果。
[0026]
s7:使用训练集对上述网络进行大数据训练,采用随机梯度下降法进行优化,公式为
[0027][0028]
其中l(y[u],v[u])表示损失函数,u是得分图上任一点,v[u]是该点模板-检测图像对的相似性得分,y[u]是该点的实际标签,d表示整张得分图范围,本发明通过随机梯度下降(sgd)优化损失函数来获得网络的权重参数θ。其中,根据得分图上u据目标中心点的距离定义y[u](k表示网络步长,c为目标中心点, r表示事先设定的阈值半径)
[0029][0030]
s8:使用验证集对训练后的模型进行验证,调整模型的超参数,包括迭代批次、批次大小和学习率。验证指标包括准确性和鲁棒性;准确性公式为
[0031][0032]
其中a表示实际边界框,b表示检测边界框。
[0033]
鲁棒性为
[0034][0035]
其中failure表示跟踪失败的帧数,sum表示视频总的帧数。
[0036]
s9:利用最终模型,当输入图像序列后,模型将自动提取第一帧作为模板图像,其余帧图像作为检测图像。两类图像将分别输入siamese孪生网络的两个分支,并进入vgg-11网络提取特征。在此过程中采用三级信息融合策略构建最终得分图,根据得分图中最高分值点的位置预测出视觉目标的位置。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1