一种知识图谱的构建方法及其系统和计算机设备与流程
[0001]
本发明涉及计算机软件技术领域,具体涉及一种企业知识图谱的构建方法及其系统和应用。
背景技术:
[0002]
知识图谱(knowledge graph)的研究最早可追溯到1977年,在第五届国际人工智能会议上,美国计算机科学家feigenbaum b.a.首次提出知识工程的概念。知识工程即针对用户提出的问题用知识库中已有的知识来求解的系统,其中最经典的是专家系统。2012年,谷歌(google)发布知识图谱项目,并宣布以此为基础构建下一代智能化搜索引擎。该项目通过对客观真实世界中各种实体及其关系的描绘,形成一张巨大的语义结构网络图,使各种庞杂无关的知识联系起来,从而达到便捷地获取知识的目的。
[0003]
知识图谱是将大量收集的数据整理成机器能处理的知识库,并实现可视化的展示。知识图谱本质上是一种大规模的语义网络,其主要目的是对真实世界里实体或概念之间的关联关系进行描述。知识图谱一般包含逻辑结构和技术(体系)构架。知识图谱构建的一般步骤包括数据采集、知识抽取、知识融合、知识加工以及知识更新等步骤。
[0004]
目前公开的指示图谱的构建方法中,对于数据源并没有相应的处理,使得抽取的知识单元包含了太多噪音或者具有歧义的实体,导致后期的实体消歧步骤不能完全消除实体的噪音和歧义,不能保证构建的知识图谱的质量。
技术实现要素:
[0005]
为了克服现有技术的不足,本发明的目的在于提供一种知识图谱的构建方法,通过在知识融合和实体消歧步骤中,去除重复具有歧义、多义等实体,构建高质量的知识图谱。
[0006]
为解决上述问题,本发明所采用的技术方案如下:
[0007]
一种知识图谱的构建方法,包括
[0008]
构建本体模型,根据预设应用场景所在的领域相关的数据源及业务特征构建本体模型;
[0009]
知识抽取,对当前数据源的实体进行命名实体识别,得到多个命名实体;对多个命名实体进行连接,得到多个实体关系;通过图数据库、关系型数据库以及文档数据库相结合的方式对抽取的知识单元进行存储;
[0010]
知识融合,通过实体链接标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,同时去掉重复的实体、属性以及关系;
[0011]
实体消歧,获取所有未被进行消歧处理的指代实体项的目标对象,利用数据库查询语句搜索到具有相同含义词语的链接页面,在未进行实体消歧的所在文本信息中与在备选实体所在的信息库中提取相同数量的关键词,针对所提取的关键词计算相似度,去除文
本信息中相似度低于第一预设阈值的实体;
[0012]
知识加工,对完成知识融合并实体消歧后的知识图谱进行加工,构建企业的知识图谱。
[0013]
作为进一步优选的方案,本发明在构建本体模型时,根据预设应用场景的特性选择采用采用自底向上、或者自顶向下、或自底向上与自顶向下两者相结合的构建方式。
[0014]
作为进一步优选的方案,本发明所述的知识抽取的数据源包括关系型数据以及非关系型数,知识抽取内容包括目标实体、实体属性和实体关系,根据不同的数据来源以及抽取方式标识置信度。
[0015]
作为进一步优选的方案,本发明所述的关系型数据来源于专业数据库或业务数据库,其中专业数据库的数据源视为完全信任,置信度c0=1,业务数据库的置信度根据信息完善度i和业务数据库的权威性进行计算;所述非关系型数据的数据源是通过爬虫集群由一个种开始在从网络、百科知识、媒体数据中抓取的数据,所述非关系型数据的置信度通过质量评估进行计算。
[0016]
作为进一步优选的方案,本发明所述的业务数据库的置信度c主要由信息完善程度i决定,数据库的权威性或公信力会影响信息的信任度,权威性或公信力的影响用影响参数γ表示,赋予影响参数权重α;
[0017]
其中,i在(0,1)之间取值,由完善度决定,即业务数据库信息完善度为100%时,i=1,若信息完善度为50%时,i=0.5;α的取值满足i+α=1;
[0018]
影响参数γ与数据库创建单位的公信力相关,当创建者具有完全公信力时,γ=1,
[0019]
引入一个校正因子ω,在具有完全公信力的情况下ω=0,当数据库创建者具有不完全公信力时,通过数据库的使用者的评价信息对ω赋值,ω为正面评价数量在总评价量中占比,即
[0020][0021]
根据上述设定,得到置信度的计算公式为:
[0022]
c=i*c0+(α-ω)*γ
[0023]
当计算得到的置信度低于50%,去除从对应数据库中获得的实体信息。
[0024]
作为进一步优选的方案,本发明所述的非关系型数据的置信度c通过对数据库的质量评估进行计算,根据数据的采集方式、数据库的使用程度以及使用效果的评价对非关系型数据的数据库进行质量评估,包括如下步骤:
[0025]
获取数据库采集数据的方式,根据每个数据库采集数据的方式获取数据来源的采集参数μ1,且
[0026]
获取数据库的所有历史浏览数据,计算所有历史数据每天浏览量的平均值n0,抽取历史数据中某一连续时间段t的浏览数据,计算该时间段浏览量的平均值n,获得使用程
度μ2,
[0027]
获取数据库的用户评价信息,根据所获取的评价信息,得到使用效果的评价指数,μ3,且
[0028]
根据采集方式、数据库的使用程度以及使用效果的评价建立评估指数p,
[0029]
其中
[0030]
当p=1时,视为完全置信度;当0.5≤p<1视为具有较高置信度,对应数据库中获得的实体信息作抽取后存入知识库;当p<0.5时,视为置信度低,去除从对应数据库中获得的实体信息。
[0031]
作为进一步优选的方案,本发明所述的实体消歧过程中,构建词向量模型计算词语的相似程度,将语义信息与预设应用场景所述领域信息进行必要的联系作用,取中心实体周围距离最近的n个实体构建实体关系图谱,如果待计算的两个实体都不在这个图谱中则将相似度设为0,反之,则用随机游走算法计算相似度:
[0032]
(1)给定初始化矩阵x,并令y=x;
[0033]
(2)根据实体间的转移概率,生成矩阵m;
[0034]
(3)计算c=σ
·
m
·
y+(1-σ)x;
[0035]
(4)令y=c;
[0036]
重复上述(3)和(4),直到c达到稳定状态或者迭代次数超过的第一预设阈值;
[0037]
其中σ为相似度权重,取值范围为(0-1),
[0038]
计算的目标关键词相似度可判断出值最大的是目标所选实体。
[0039]
作为进一步优选的方案,本发明所述的知识图谱的构建方法还包括
[0040]
多次实体消歧,在实体消歧去除的文本信息中与在备选实体所在的信息库中提取有限的相同数量的关键词,针对所提取的关键词计算相似度,抽取文本信息中相似度高于第二预设阈值的实体,其中第二预设阈值小于第一预设阈值,对抽取出来的这部分实体采用随机游走算法与三角函数余弦值结合的方式再次进行消歧或者与备选实体进行人工匹配,提取相似度高于第一预设阈值的实体对知识图谱进行更新。
[0041]
进一步的,本发明还提供了一种知识图谱的构建系统,包括
[0042]
数据源收集单元,用于收集预定场景的领域的相关数据源;
[0043]
实体建模单元,用于根据预定场景的领域的相关数据源建立实体模型;
[0044]
知识抽取单元,用于对数据源的实体进行命名实体识别,得到多个命名实体;对多个命名实体进行连接,得到多个实体关系;通过图数据库、关系型数据库以及文档数据库相结合的方式抽取的知识单元并进行存储;
[0045]
知识融合单元,用于标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,去掉重复的实体、属性以及关系;
[0046]
实体消歧单元,用于获取所有未被进行消歧处理的指代实体项的目标对象,利用
数据库查询语句搜索到具有相同含义词语的链接页面,在未进行实体消歧的所在文本信息中与在备选实体所在的信息库中提取相同数量的关键词,针对所提取的关键词计算相似度,去除文本信息中相似度低于第一预设阈值的实体;
[0047]
知识加工单元,通过知识推理、质量评价对知识图谱进行加工。
[0048]
进一步的,本发明还提供了一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现本发明所述方法的步骤。
[0049]
进一步的,本发明还提供了一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现本发明所述的方法的步骤。
[0050]
相比现有技术,本发明的有益效果在于:
[0051]
1.本发明所述的知识图谱的构建方法通过在知识融合和实体消歧步骤中,去除重复具有歧义、多义等实体,构建高质量的知识图谱。
[0052]
2.进一步的,本发明所述的知识图谱的构建方法还通过对数据源的置信度进行计算,根据不同的数据源设置不同的计算方式,提高了数据源的置信度,进一步达到提高知识图谱质量的目的,
[0053]
3.进一步的本发明所述的知识图谱的构建方法还设置了二次实体消歧,主要是对出去掉的实体进行筛选,避免筛除与目标实体存在关系的实体,保证了知识图谱的完整性。
[0054]
下面结合附图和具体实施方式对本发明作进一步详细说明。
附图说明
[0055]
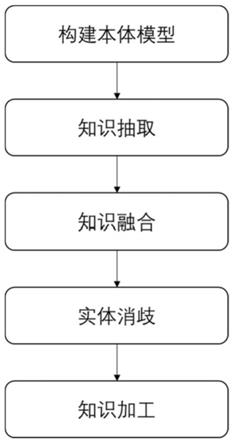
图1为本发明所述的知识图谱的构建的流程图。
[0056]
图2为本发明所述的知识图谱的构建系统结构图。
具体实施方式
[0057]
实施例1
[0058]
如图1所示,一种知识图谱的构建方法,应用场景是面向投资人的企业知识图谱,包括
[0059]
构建本体模型,根据企业所在的领域相关的数据源及业务特征构建本体模型;
[0060]
知识抽取,对当前数据源的实体进行命名实体识别,得到多个命名实体;对多个命名实体进行连接,得到多个实体关系;通过图数据库、关系型数据库以及文档数据库相结合的方式对抽取的知识单元进行存储;
[0061]
知识融合,通过实体链接标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,同时去掉重复的实体、属性以及关系;
[0062]
实体消歧,获取所有未被进行消歧处理的指代实体项的目标对象,利用数据库查询语句搜索到具有相同含义词语的链接页面,在未进行实体消歧的所在文本信息中与在备选实体所在的信息库中提取相同数量的关键词,针对所提取的关键词计算相似度,去除文本信息中相似度低于第一预设阈值的实体;
[0063]
对完成知识融合并实体消歧后的知识图谱进行加工,构建企业的知识图谱。
[0064]
具体的,由于企业的特性,实施例在本发明在构建本体模型时,根据采用自底向上的构建方式建模。
[0065]
具体的,实施例1所述的知识抽取的数据源包括关系型数据以及非关系型数,知识抽取内容包括目标实体、实体属性和实体关系,根据不同的数据来源以及抽取方式标识置信度。具体的,提取的知识单元包括该企业工商信息、上、下游企业、竞品企业、关联企业、投资信息、融资信息以及资产信息等。
[0066]
具体的,实施例所述的关系型数据来源于专业数据库或业务数据库,其中专业数据库包括工商登记信息,数据源视为完全信任,置信度c0=1;业务数据库包括企业名录、黄页等数据,这部分数据源的置信度根据信息完善度i和业务数据库的权威性进行计算;所述的业务数据库的置信度c主要由信息完善程度i决定,数据库的权威性或公信力会影响信息的信任度,权威性或公信力的影响用影响参数γ表示,赋予影响参数权重α;
[0067]
其中,i在(0,1)之间取值,由完善度决定,即业务数据库信息完善度为100%时,i=1,若信息完善度为50%时,i=0.5;α的取值满足i+α=1;
[0068]
影响参数γ与数据库创建单位的公信力相关,当创建者具有完全公信力时,γ=1,
[0069]
引入一个校正因子ω,在具有完全公信力的情况下ω=0,当数据库创建者具有不完全公信力时,通过数据库的使用者的评价信息对ω赋值,ω为正面评价数量在总评价量中占比,即
[0070][0071]
根据上述设定,得到置信度的计算公式为:
[0072]
c=i*c0+(α-ω)*γ
[0073]
当计算得到的置信度低于50%,去除从对应数据库中获得的实体信息。
[0074]
实施例1对于非关系型数据的置信度c通过对数据库的质量评估进行计算,根据数据的采集方式、数据库的使用程度以及使用效果的评价对非关系型数据的数据库进行质量评估,包括如下步骤:
[0075]
获取数据库采集数据的方式,根据每个数据库采集数据的方式获取数据来源的采集参数μ1,且
[0076]
获取数据库的所有历史浏览数据,计算所有历史数据每天浏览量的平均值n0,抽取历史数据中某一连续时间段t的浏览数据,计算该时间段浏览量的平均值n,获得使用程度μ2,
[0077]
获取数据库的用户评价信息,根据所获取的评价信息,得到使用效果的评价指数,
μ3,且
[0078]
根据采集方式、数据库的使用程度以及使用效果的评价建立评估指数p,
[0079]
其中
[0080]
当p=1时,视为完全置信度;当0.5≤p<1视为具有较高置信度,对应数据库中获得的实体信息作抽取后存入知识库;当p<0.5时,视为置信度低,去除从对应数据库中获得的实体信息。
[0081]
作为进一步优选的方案,本发明所述的实体消歧过程中,构建词向量模型计算词语的相似程度,将语义信息与预设应用场景所述领域信息进行必要的联系作用,取中心实体周围距离最近的n个实体构建实体关系图谱,如果待计算的两个实体都不在这个图谱中则将相似度设为0,反之,则用随机游走算法计算相似度:
[0082]
(1)给定初始化矩阵x,并令y=x;
[0083]
(2)根据实体间的转移概率,生成矩阵m;
[0084]
(3)计算c=σ
·
m
·
y+(1-σ)x;
[0085]
(4)令y=c;
[0086]
重复上述(3)和(4),直到c达到稳定状态或者迭代次数超过的第一预设阈值;
[0087]
其中σ为相似度权重,取值范围为(0-1),
[0088]
计算的目标关键词相似度可判断出值最大的是目标所选实体。
[0089]
进一步的,在上述实施例1的基础上,本发明所述的知识图谱的构建方法还包括
[0090]
多次实体消歧,在实体消歧去除的文本信息中与在备选实体所在的信息库中提取有限的相同数量的关键词,针对所提取的关键词计算相似度,抽取文本信息中相似度高于第二预设阈值的实体,其中第二预设阈值小于第一预设阈值,对抽取出来的这部分实体采用随机游走算法与三角函数余弦值结合的方式再次进行消歧或者与备选实体进行人工匹配,提取相似度高于第一预设阈值的实体对知识图谱进行更新。
[0091]
实施例2
[0092]
一种昆虫知识图谱的构建方法,包括
[0093]
构建本体模型,根据生物领域相关的数据源及昆虫特性构建本体模型;
[0094]
知识抽取,对当前数据源的实体进行命名实体识别,得到多个命名实体;对多个命名实体进行连接,得到多个实体关系;通过图数据库、关系型数据库以及文档数据库相结合的方式对抽取的知识单元进行存储;
[0095]
知识融合,通过实体链接标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,同时去掉重复的实体、属性以及关系;
[0096]
实体消歧,获取所有未被进行消歧处理的指代实体项的目标对象,利用数据库查询语句搜索到具有相同含义词语的链接页面,在未进行实体消歧的所在文本信息中与在备选实体所在的信息库中提取相同数量的关键词,针对所提取的关键词计算相似度,去除文本信息中相似度低于第一预设阈值的实体;
[0097]
对完成知识融合并实体消歧后的知识图谱进行加工,构建企业的知识图谱。
[0098]
具体的,由于企业的特性,实施例在本发明在构建本体模型时,根据采用自底向上的构建方式建模。
[0099]
具体的,实施例1所述的知识抽取的数据源包括关系型数据以及非关系型数,知识抽取内容包括目标实体、实体属性和实体关系,根据不同的数据来源以及抽取方式标识置信度。
[0100]
具体的,实施例所述的关系型数据来源于专业数据库或业务数据库,其中专业数据库包括农业部信息网数据库、各国的昆虫博物馆数据库,数据源视为完全信任,置信度c0=1;
[0101]
业务数据库包括昆虫百科全书、中国昆虫网等,这部分数据源的置信度根据信息完善度i和业务数据库的权威性进行计算;所述的业务数据库的置信度c主要由信息完善程度i决定,数据库的权威性或公信力会影响信息的信任度,权威性或公信力的影响用影响参数γ表示,赋予影响参数权重α;
[0102]
其中,i在(0,1)之间取值,由完善度决定,即业务数据库信息完善度为100%时,i=1,若信息完善度为50%时,i=0.5;α的取值满足i+α=1;
[0103]
影响参数γ与数据库创建单位的公信力相关,当创建者具有完全公信力时,γ=1,
[0104]
引入一个校正因子ω,在具有完全公信力的情况下ω=0,当数据库创建者具有不完全公信力时,通过数据库的使用者的评价信息对ω赋值,ω为正面评价数量在总评价量中占比,即
[0105][0106]
根据上述设定,得到置信度的计算公式为:
[0107]
c=i*c0+(α-ω)*γ
[0108]
当计算得到的置信度低于50%,去除从对应数据库中获得的实体信息。
[0109]
实施例2对于非关系型数据的置信度c通过对数据库的质量评估进行计算,根据数据的采集方式、数据库的使用程度以及使用效果的评价对非关系型数据的数据库进行质量评估,包括如下步骤:
[0110]
获取数据库采集数据的方式,根据每个数据库采集数据的方式获取数据来源的采集参数μ1,且
[0111]
获取数据库的所有历史浏览数据,计算所有历史数据每天浏览量的平均值n0,抽取历史数据中某一连续时间段t的浏览数据,计算该时间段浏览量的平均值n,获得使用程度μ2,
[0112]
获取数据库的用户评价信息,根据所获取的评价信息,得到使用效果的评价指数,
μ3,且
[0113]
根据采集方式、数据库的使用程度以及使用效果的评价建立评估指数p,
[0114]
其中
[0115]
当p=1时,视为完全置信度;当0.5≤p<1视为具有较高置信度,对应数据库中获得的实体信息作抽取后存入知识库;当p<0.5时,视为置信度低,去除从对应数据库中获得的实体信息。
[0116]
作为进一步优选的方案,本发明所述的实体消歧过程中,构建词向量模型计算词语的相似程度,将语义信息与预设应用场景所述领域信息进行必要的联系作用,取中心实体周围距离最近的n个实体构建实体关系图谱,如果待计算的两个实体都不在这个图谱中则将相似度设为0,反之,则用随机游走算法计算相似度:
[0117]
(1)给定初始化矩阵x,并令y=x;
[0118]
(2)根据实体间的转移概率,生成矩阵m;
[0119]
(3)计算c=σ
·
m
·
y+(1-σ)x;
[0120]
(4)令y=c;
[0121]
重复上述(3)和(4),直到c达到稳定状态或者迭代次数超过的第一预设阈值;
[0122]
其中σ为相似度权重,取值范围为(0-1),
[0123]
计算的目标关键词相似度可判断出值最大的是目标所选实体。
[0124]
进一步的,在上述实施例2的基础上,本发明所述的知识图谱的构建方法还包括
[0125]
多次实体消歧,在实体消歧去除的文本信息中与在备选实体所在的信息库中提取有限的相同数量的关键词,针对所提取的关键词计算相似度,抽取文本信息中相似度高于第二预设阈值的实体,其中第二预设阈值小于第一预设阈值,对抽取出来的这部分实体采用随机游走算法与三角函数余弦值结合的方式再次进行消歧或者与备选实体进行人工匹配,提取相似度高于第一预设阈值的实体对知识图谱进行更新。
[0126]
实施例3
[0127]
一种知识图谱的构建系统,包括
[0128]
数据源收集单元,用于收集预定场景的领域的相关数据源;
[0129]
实体建模单元,用于根据预定场景的领域的相关数据源建立实体模型;
[0130]
知识抽取单元,用于对数据源的实体进行命名实体识别,得到多个命名实体;对多个命名实体进行连接,得到多个实体关系;通过图数据库、关系型数据库以及文档数据库相结合的方式抽取的知识单元并进行存储;
[0131]
知识融合单元,用于标识相似实体,关联相同实体的不同表达形式;并对相同实体的不同属性或者相同实体相同属性不同的属性值进行合并,去掉重复的实体、属性以及关系;
[0132]
实体消歧单元,用于获取所有未被进行消歧处理的指代实体项的目标对象,利用数据库查询语句搜索到具有相同含义词语的链接页面,在未进行实体消歧的所在文本信息中与在备选实体所在的信息库中提取相同数量的关键词,针对所提取的关键词计算相似
度,去除文本信息中相似度低于第一预设阈值的实体;
[0133]
知识加工单元,通过知识推理、质量评价对知识图谱进行加工。
[0134]
进一步的,本发明还提供了一种计算机设备,所述计算机设备包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现本发明所述方法的步骤。
[0135]
进一步的,本发明还提供了一种存储介质,所述存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现本发明所述的方法的步骤。
[0136]
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1