一种图像检测方法、设备及计算机可读存储介质与流程
[0001]
本申请涉及人工智能领域中的图像处理技术,尤其涉及一种图像检测方法、设备及计算机可读存储介质。
背景技术:
[0002]
随着人工智能技术的研究和进步,人工智能技术在多个领域展开了研究和应用;比如,在图像处理领域中,利用人工智能技术,通过网络模型对图像进行检测,以基于检测结果进行后续处理。然而,对图像进行检测时,所利用的网络模型在训练时的样本数量通常是有限的,从而,训练得到的网络模型对应的图像检测的精准度较低。
技术实现要素:
[0003]
本申请实施例提供一种图像检测方法、设备及计算机可读存储介质,能够提升图像检测的精准度。
[0004]
本申请实施例的技术方案是这样实现的:
[0005]
本申请实施例提供一种图像检测方法,包括:
[0006]
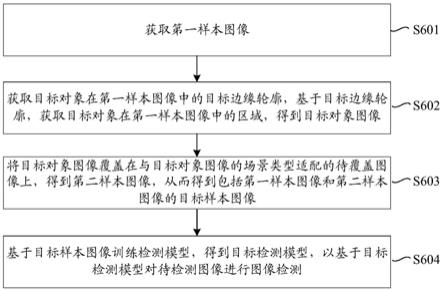
获取第一样本图像,其中,所述第一样本图像为检测模型对应的待增强样本图像,所述检测模型为用于检测图像的待训练网络模型;
[0007]
获取目标对象在所述第一样本图像中的目标边缘轮廓,基于所述目标边缘轮廓,获取所述目标对象在所述第一样本图像中的区域,得到目标对象图像,其中,所述目标对象属于目标类别,所述目标类别为图像检测的各个类别中待进行图像数量增强的类别;
[0008]
将所述目标对象图像覆盖在与所述目标对象图像的场景类型适配的待覆盖图像上,得到第二样本图像,从而得到包括所述第一样本图像和所述第二样本图像的目标样本图像;
[0009]
基于所述目标样本图像训练所述检测模型,得到目标检测模型,以基于所述目标检测模型对待检测图像进行图像检测。
[0010]
本申请实施例提供一种图像检测装置,包括:
[0011]
图像获取模块,用于获取第一样本图像,其中,所述第一样本图像为检测模型对应的待增强样本图像,所述检测模型为用于检测图像的待训练网络模型;
[0012]
图像分割模块,用于获取目标对象在所述第一样本图像中的目标边缘轮廓,基于所述目标边缘轮廓,获取所述目标对象在所述第一样本图像中的区域,得到目标对象图像,其中,所述目标对象属于目标类别,所述目标类别为图像检测的各个类别中待进行图像数量增强的目标类别;
[0013]
图像覆盖模块,用于将所述目标对象图像覆盖在与所述目标对象图像的场景类型适配的待覆盖图像上,得到第二样本图像,从而得到包括所述第一样本图像和所述第二样本图像的目标样本图像;
[0014]
模型训练模块,用于基于所述目标样本图像训练所述检测模型,得到目标检测模
型,以基于所述目标检测模型对待检测图像进行图像检测。
[0015]
在本申请实施例中,所述图像分割模块,还用于对所述第一样本图像进行边缘检测,得到边缘检测结果;获取所述边缘检测结果中的各个边缘轮廓对应的类别;基于所述各个边缘轮廓对应的类别,从所述边缘检测结果中,获取与所述目标类别适配的边缘轮廓,得到所述目标对象对应的所述目标边缘轮廓。
[0016]
在本申请实施例中,所述图像分割模块,还用于对所述第一样本图像进行实例分割,得到实例分割结果;从所述实例分割结果中,获取所述目标对象对应的所述目标对象掩膜;将所述目标对象掩膜中的边缘轮廓,确定为所述目标边缘轮廓。
[0017]
在本申请实施例中,所述图像分割模块,还用于从所述第一样本图像中,选择预设数量的图像作为待标注图像;获取所述待标注图像的实例分割标签;基于所述待标注图像和所述实例分割标签,训练实例分割模型,得到目标实例分割模型,其中,所述实例分割模型为用于对图像进行实例分割的待训练网络模型;基于所述目标实例分割模型,对所述第一样本图像中除所述待标注图像之外的剩余样本图像进行实例分割,得到对象掩膜,从而得到包括所述实例分割标签和所述对象掩膜的所述实例分割结果。
[0018]
在本申请实施例中,所述图像分割模块,还用于在掩膜标注客户端上呈现所述待标注图像;接收针对所述待标注图像的标注操作;响应于所述标注操作,生成所述待标注图像的描述文件,所述描述文件中包括所述实例分割标签。
[0019]
在本申请实施例中,所述描述文件中还包括所述实例分割标签对应的标注类别;所述图像分割模块,还用于基于所述目标实例分割模型,对所述剩余样本图像进行实例分割,得到所述对象掩膜对应的对象类别;
[0020]
在本申请实施例中,所述图像分割模块,还用于基于所述标注类别,确定所述实例分割标签中与所述目标类别适配的第一子目标对象掩膜;基于所述对象类别,确定所述对象掩膜中与所述目标类别适配的第二子目标对象掩膜,从而得到所述目标对象对应的包括所述第一子目标对象掩膜和所述第二子目标对象掩膜的所述目标对象掩膜。
[0021]
在本申请实施例中,所述图像检测装置还包括图像选择模块,用于获取初始待覆盖图像;对所述初始待覆盖图像进行场景类型划分,得到各个场景类型;从所述各个场景类型中,选择出与所述目标对象图像的场景类型匹配的目标场景类型;将所述初始待覆盖图像中与所述目标场景类型适配的图像,确定为所述待覆盖图像。
[0022]
在本申请实施例中,所述图像选择模块,还用于获取所述初始待覆盖图像在预设通道中的颜色通道信息对应的颜色通道值;比较所述颜色通道值与至少一个颜色通道阈值;基于比较结果,确定所述初始待覆盖图像所属的所述各个场景类型。
[0023]
在本申请实施例中,所述图像检测装置还包括样本选择模块,用于获取所述检测模型对应的训练样本图像;从所述训练样本图像中,获取与所述目标类别对应的所述第一样本图像。
[0024]
在本申请实施例中,所述图像获取模块,还用于获取所述训练样本图像中除所述第一样本图像之外的剩余训练样本图像;基于所述剩余训练样本图像和所述目标样本图像训练所述检测模型,得到所述目标检测模型。
[0025]
在本申请实施例中,所述模型训练模块,还用于获取所述目标样本图像对应的目标标注信息;基于所述检测模型,对所述目标样本图像进行图像检测,得到目标预测信息;
基于所述目标预测信息与所述目标标注信息之间的损失,迭代训练所述检测模型,获取迭代训练过程中各个类别对应的平均精度均值,直到所述平均精度均值达到平均精度均值阈值时,停止迭代训练,得到所述目标检测模型。
[0026]
在本申请实施例中,所述图像检测装置还包括模型应用模块,用于获取所述待检测图像;基于所述目标检测模型对所述待检测图像进行图像检测,得到所述待检测图像中的待检测对象信息,其中,所述待检测对象信息包括待检测对象的位置信息和所述待检测对象的类别。
[0027]
在本申请实施例中,当所述待检测图像为虚拟场景的渲染图像时,所述待检测对象的位置信息为虚拟目标的位置信息,所述待检测对象的类别为所述虚拟目标的类别;其中,所述虚拟目标包括虚拟对象和虚拟道具中的至少一种;所述图像检测装置还包括结果应用模块,用于基于所述虚拟目标的类别,确定针对所述虚拟目标的位置信息处的所述虚拟目标的交互操作。
[0028]
在本申请实施例中,当所述待检测图像为监控设备发送的监控图像时,所述待检测对象的位置信息为监控目标的位置信息,所述待检测对象的类别为所述监控目标的类别;其中,所述监控目标的类别为:车辆、生物体和智能设备中的至少一种;所述结果应用模块,还用于基于所述监控目标的类别,确定所述监控目标中的待监控目标;从所述监控目标的位置信息中获得所述待监控目标的目标位置信息,基于所述目标位置信息,确定所述待监控目标的活动轨迹信息。
[0029]
本申请实施例提供一种图像检测设备,包括:
[0030]
存储器,用于存储可执行指令;
[0031]
处理器,用于执行所述存储器中存储的可执行指令时,实现本申请实施例提供的图像检测方法。
[0032]
本申请实施例提供一种计算机可读存储介质,存储有可执行指令,用于引起处理器执行时,实现本申请实施例提供的图像检测方法。
[0033]
本申请实施例至少具有以下有益效果:基于目标对象在第一样本图像中的目标边缘轮廓,将目标对象在第一样本图像中的区域作为目标对象图像,贴附在与目标对象图像的场景类型适配的待覆盖图像上而得到第二样本图像,使得用于训练检测模型的目标样本图像不仅包括第一样本图像,还包括第二样本图像,实现了样本图像数量的增强;因此,训练得到的目标检测模型对应的图像检测的精准度较高,从而,能够提升图像检测的精准度。
附图说明
[0034]
图1是一种示例性的样本增强示意图;
[0035]
图2是另一种示例性的样本增强示意图;
[0036]
图3是又一种示例性的样本增强示意图;
[0037]
图4是本申请实施例提供的图像检测系统的一个可选的架构示意图;
[0038]
图5是本申请实施例提供的图4中的一种服务器的组成结构示意图;
[0039]
图6是本申请实施例提供的图像检测方法的一个可选的流程示意图;
[0040]
图7a是本申请实施例提供的一种示例性的获取第二样本图像的示意图;
[0041]
图7b是本申请实施例提供的又一种示例性的获取第二样本图像的示意图;
[0042]
图7c是本申请实施例提供的另一种示例性的获取第二样本图像的示意图;
[0043]
图8是本申请实施例提供的一种示例性的训练检测模型的流程示意图;
[0044]
图9是本申请实施例提供的一种示例性的实例标注示意图;
[0045]
图10是本申请实施例提供的图像检测方法的另一个可选的流程示意图;
[0046]
图11a为本申请实施例提供的一种示例性的划分场景类型的结果示意图;
[0047]
图11b是本申请实施例提供的一种示例性的标注目标样本图像的示意图;
[0048]
图11c是本申请实施例提供的图像检测方法的另一个可选的流程示意图;
[0049]
图12是本申请实施例提供的图像检测方法的一种示例性的实现流程图;
[0050]
图13是本申请实施例提供的一种示例性的实例分割模型的框架示意图;
[0051]
图14是本申请实施例提供的一种示例性的实例分割实现流程的示意图;
[0052]
图15是本申请实施例提供的一种示例性的增强样本的示意图;
[0053]
图16是本申请实施例提供的一种示例性的训练检测模型的流程示意图。
具体实施方式
[0054]
为了使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请作进一步地详细描述,所描述的实施例不应视为对本申请的限制,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本申请保护的范围。
[0055]
在以下的描述中,涉及到“一些实施例”,其描述了所有可能实施例的子集,但是可以理解,“一些实施例”可以是所有可能实施例的相同子集或不同子集,并且可以在不冲突的情况下相互结合。
[0056]
在以下的描述中,所涉及的术语“第一\第二”仅仅是是区别类似的对象,不代表针对对象的特定排序,可以理解地,“第一\第二”在允许的情况下可以互换特定的顺序或先后次序,以使这里描述的本申请实施例能够以除了在这里图示或描述的以外的顺序实施。
[0057]
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中所使用的术语只是为了描述本申请实施例的目的,不是旨在限制本申请。
[0058]
对本申请实施例进行进一步详细说明之前,对本申请实施例中涉及的名词和术语进行说明,本申请实施例中涉及的名词和术语适用于如下的解释。
[0059]
1)人工智能(artificial intelligence,ai):是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。
[0060]
2)机器学习(machine learning,ml),是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能;重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习通常包括人工神经网络、置信网络、强化学习、迁移学习和归纳学习等技术。
[0061]
3)人工神经网络,是一种模仿生物神经网络结构和功能的数学模型,本文中人工神经网络的示例性结构包括深度神经网络(deep neural networks,dnn)、卷积神经网络(convolutional neural network,cnn)和循环神经网络(recurrent neural network,
rnn)等。其中,dnn内部的神经网络层可以分为三类,输入层,隐藏层和输出层,并且层与层之间是全连接的,也就是说,第i层的任意一个神经元一定与第i+1层的任意一个神经元相连,i为大于1的正整数;在信息推荐领域中,能够对用户进行合理的兴趣推测和衍生,提升内容多样性。
[0062]
4)损失函数,又称代价函数,是将随机事件或其有关随机变量的取值映射为非负实数以表示该随机事件的“风险”或“损失”的函数;在本申请实施例中,通过损失函数计算损失函数值,以对网络模型进行训练。
[0063]
5)实例分割,从图像中分割出对象的边缘轮廓,基于对象的边缘轮廓输出图像中对象的掩膜的过程;而对象的掩膜,指图像中对象的边缘轮廓构成的封闭区域内的像素值为1,而边缘轮廓构成的封闭区域外的像素值为0的二值图像。
[0064]
需要说明的是,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
[0065]
另外,人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习等几大方向。
[0066]
随着人工智能技术的研究和进步,人工智能技术在多个领域展开了研究和应用;例如,常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗和智能客服等;随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。在本申请实施例中,将对人工智能在图像检测中的应用进行说明。
[0067]
然而,人工智能在图像检测中进行应用时,针对网络模型的训练,常常存在样本数量不足的情况;比如,针对一个网络模型的训练任务,样本数量为几十个;然而,完成神经网络中的网络模型的训练,往往需要成千上万的样本;在样本数量充足时,才能够使得网络模型中的参数以正确的方式调整,从而使得网络模型的损失函数值较低;而在网络模型中的参数较多的情况下,足够多的样本才能保证网络模型进行图像检测时,所获得的检测结果的精准度较高。因此,对样本进行数量增强,才能够获得泛化能力较强的网络模型。
[0068]
一般来说,为了对样本进行数量增强,常常对样本图像进行翻转(以横轴或纵轴为对称轴对样本图像进行翻转)、旋转(以样本图像的中心点为中心对图像进行一定角度的旋转)、比例缩放、裁剪(选择样本图像的一部分区域作为新样本图像)、移位(将样本图像中框选的目标对象移动到其他的位置)和添加噪声等。
[0069]
参见图1,图1是一种示例性的样本增强示意图;如图1所示,图像1-1为样本图像,即原图;图像1-21至图像1-26为基于图像1-1,进行翻转、旋转、比例缩放、裁剪和移位中的至少一种处理而获得的样本增强图像1-2。
[0070]
然而,在对样本图像进行翻转、旋转、比例缩放、裁剪、移位和添加噪声等处理,而获得样本增强图像时,所获得的样本增强图像中,存在失真性较小的样本增强图像,也存在失真性较大的样本增强图像;参见图2,图2是另一种示例性的样本增强示意图;如图2所示,图像2-1为样本图像,即原图;图像2-21至图像2-25依次为对图像2-1进行添加噪声、裁剪、
裁剪、缩放和缩放处理获得的样本增强图像;由图2易知,图像2-22和图像2-23均为失真性较小的样本增强图像;图像2-21、图像2-24和图像2-25为失真性较大的样本增强图像,和真实场景的差别较大。从而,依据增强后的样本图像进行网络模型的训练时,所获得的训练后的网络模型的图像检测的精准度较差。
[0071]
另外,为了对样本进行数量增强,还可以样本图像的标签部分进行翻转、旋转、比例缩放、裁剪、移位和添加噪声等处理,得到样本增强图像;然而,由于标签部分一般是矩形框,而目标对象是不规则的,所以矩形框内除了包括目标对象之外,还包括样本图像中的背景信息,使得样本增强图像的噪声较大。参见图3,图3是又一种示例性的样本增强示意图;如图3所示,样本图像3-1(即原图)中,区域3-11为标签部分;将区域3-11移位至另一幅图像上,得到样本增强图像3-2;易知,样本增强图像3-2中,包括样本图像3-1的背景部分3-12,且另一幅图像上的部分物体3-21被遮挡。从而,依据增强后的样本图像进行网络模型的训练时,所获得的训练后的网络模型的图像检测的精准度较差。
[0072]
本申请实施例提供一种图像检测方法、装置、设备和计算机可读存储介质,能够提升图像检测的精准度。下面说明本申请实施例提供的图像检测设备的示例性应用,本申请实施例提供的图像检测设备可以实施为笔记本电脑,平板电脑,台式计算机,机顶盒,移动设备(例如,移动电话,便携式音乐播放器,个人数字助理,专用消息设备,便携式游戏设备)等各种类型的用户终端,也可以实施为服务器。下面,将说明设备实施为服务器时的示例性应用。
[0073]
参见图4,图4是本申请实施例提供的图像检测系统的一个可选的架构示意图;如图4所示,为支撑一个图像检测应用,在图像检测系统100中,终端200(示例性示出了终端200-1和终端200-2)通过网络300连接服务器400,网络300可以是广域网或者局域网,又或者是二者的组合。另外,图像检测系统100中还包括数据库500,用于向服务器400提供数据支持。
[0074]
服务器400,用于从数据库500中获取第一样本图像,其中,第一样本图像为检测模型对应的待增强样本图像,检测模型为用于检测图像的待训练网络模型;获取目标对象在第一样本图像中的目标边缘轮廓,基于目标边缘轮廓,获取目标对象在第一样本图像中的区域,得到目标对象图像,其中,目标对象属于目标类别,目标类别为图像检测的各个类别中待进行图像数量增强的类别;将目标对象图像覆盖在与目标对象图像的场景类型适配的待覆盖图像上,得到第二样本图像,从而得到包括第一样本图像和第二样本图像的目标样本图像;基于目标样本图像训练检测模型,得到目标检测模型,以基于目标检测模型对待检测图像进行图像检测。还用于通过网络300从终端200中获取待检测图像,利用目标检测模型对待检测图像进行图像检测,并基于图像检测结果确定决策信息(交互操作对应指令或待监控目标的活动轨迹信息);通过网络300向终端200发送决策信息。
[0075]
终端200-1,用于通过拍摄装置获取监控图像,将监控图像作为待检测图像,通过网络300向服务器400发送待检测图像;还用于通过网络300接收服务器400针对待检测图像的待监控目标的活动轨迹信息,在图形界面200-11上显示活动轨迹信息。
[0076]
终端200-2,用于在图形界面200-21上渲染虚拟场景,将虚拟场景作为待检测图像,通过网络300向服务器400发送待检测图像;还用于通过网络300接收服务器400针对待检测图像的交互操作对应指令,执行该交互操作对应指令。
[0077]
在一些实施例中,服务器400可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、cdn(content delivery network,内容分发网络)、以及大数据和人工智能平台等基础云计算服务的云服务器。终端200可以是智能手机、平板电脑、笔记本电脑、台式计算机、智能音箱、智能手表等,但并不局限于此。终端以及服务器可以通过有线或无线通信方式进行直接或间接地连接,本发明实施例中不做限制。
[0078]
参见图5,图5是本申请实施例提供的图4中的一种服务器的组成结构示意图,图5所示的服务器400包括:至少一个处理器410、存储器450、至少一个网络接口420和用户接口430。服务器400中的各个组件通过总线系统440耦合在一起。可理解,总线系统440用于实现这些组件之间的连接通信。总线系统440除包括数据总线之外,还包括电源总线、控制总线和状态信号总线。但是为了清楚说明起见,在图5中将各种总线都标为总线系统440。
[0079]
处理器410可以是一种集成电路芯片,具有信号的处理能力,例如通用处理器、数字信号处理器(dsp,digital signal processor),或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等,其中,通用处理器可以是微处理器或者任何常规的处理器等。
[0080]
用户接口430包括使得能够呈现媒体内容的一个或多个输出装置431,包括一个或多个扬声器,或者,一个或多个视觉显示屏。用户接口430还包括一个或多个输入装置432,包括有助于用户输入的用户接口部件,比如键盘、鼠标、麦克风、触屏显示屏、摄像头、其他输入按钮和控件。
[0081]
存储器450可以是可移除的,不可移除的或其组合。示例性的硬件设备包括固态存储器,硬盘驱动器,光盘驱动器等。存储器450可选地包括在物理位置上远离处理器410的一个或多个存储设备。
[0082]
存储器450包括易失性存储器或非易失性存储器,也可包括易失性和非易失性存储器两者。非易失性存储器可以是只读存储器(rom,read only memory),易失性存储器可以是随机存取存储器(ram,random access memory)。本申请实施例描述的存储器450旨在包括任意适合类型的存储器。
[0083]
在一些实施例中,存储器450能够存储数据以支持各种操作,这些数据的示例包括程序、模块和数据结构或者其子集或超集,下面示例性说明。
[0084]
操作系统451,包括用于处理各种基本系统服务和执行硬件相关任务的系统程序,例如框架层、核心库层、驱动层等,用于实现各种基础业务以及处理基于硬件的任务;
[0085]
网络通信模块452,用于经由一个或多个(有线或无线)网络接口420到达其他计算设备,示例性的网络接口420包括:蓝牙、无线相容性认证(wi-fi)、和通用串行总线(usb,universal serial bus)等;
[0086]
呈现模块453,用于经由一个或多个与用户接口430相关联的输出装置431(例如,显示屏、扬声器等)使得能够呈现信息(例如,用于操作外围设备和显示内容和信息的用户接口);
[0087]
输入处理模块454,用于对一个或多个来自一个或多个输入装置432之一的一个或多个用户输入或互动进行检测以及翻译所检测的输入或互动。
[0088]
在一些实施例中,本申请实施例提供的图像检测装置可以采用软件方式实现,图5示出了存储在存储器450中的图像检测装置455,其可以是程序和插件等形式的软件,包括以下软件模块:图像获取模块4551、图像分割模块4552、图像覆盖模块4553、模型训练模块4554、图像选择模块4555、样本选择模块4556、模型应用模块4557和结果应用模块4558,这些模块是逻辑上的,因此根据所实现的功能可以进行任意的组合或进一步拆分。
[0089]
将在下文中说明各个模块的功能。
[0090]
在另一些实施例中,本申请实施例提供的图像检测装置可以采用硬件方式实现,作为示例,本申请实施例提供的图像检测装置可以是采用硬件译码处理器形式的处理器,其被编程以执行本申请实施例提供的图像检测方法,例如,硬件译码处理器形式的处理器可以采用一个或多个应用专用集成电路(asic,application specific integrated circuit)、dsp、可编程逻辑器件(pld,programmable logic device)、复杂可编程逻辑器件(cpld,complex programmable logic device)、现场可编程门阵列(fpga,field-programmable gate array)或其他电子元件。
[0091]
下面,将结合本申请实施例提供的服务器的示例性应用和实施,说明本申请实施例提供的图像检测方法。
[0092]
参见图6,图6是本申请实施例提供的图像检测方法的一个可选的流程示意图,将结合图6示出的步骤进行说明。
[0093]
s601、获取第一样本图像。
[0094]
在本申请实施例中,当服务器对检测模型的样本进行数量增强时,获取检测模型对应的待增强样本图像,也就得到了第一样本图像;也就是说,第一样本图像为检测模型对应的待增强样本图像,而待增强样本图像为待进行数量增强的样本图像。
[0095]
需要说明的是,第一样本图像可以为训练检测模型的全部图像,还可以为训练检测模型的部分图像,本申请实施例对此不作具体限定。当检测模型为多分类网络模型时,如果第一样本图像为训练检测模型的部分图像,则第一样本图像可以为相对于其他类别对应的样本数量较少的类别对应的样本图像;比如,当检测模型可以检测敌人和工具等类别时,如果工具对应的样本数量相对于敌人等对应的样本数量较少时,则第一样本图像为工具对应的样本图像。这里,检测模型为用于检测图像的待训练网络模型,比如,yolo(you only look once,一种基于深度神经网络的对象识别和定位算法)模型,cnn模型等。
[0096]
s602、获取目标对象在第一样本图像中的目标边缘轮廓,基于目标边缘轮廓,获取目标对象在第一样本图像中的区域,得到目标对象图像。
[0097]
在本申请实施例中,服务器获得了第一样本图像,基于第一样本图像进行样本数量增强时,是基于目标对象在第一样图像中的目标边缘轮廓实现的,其中,目标边缘轮廓即第一样图像中的目标对象的边缘轮廓。这里,服务器可以通过边缘检测获取目标对象在第一样本图像中的目标边缘轮廓,还可以通过实例分割获取目标对象在第一样本图像中的目标边缘轮廓,等等,本申请实施例对此不作具体限定。当服务器获得了目标边缘轮廓之后,分割或提取第一样本图像中目标边缘轮廓内的区域,也就得到了目标对象在第一样本图像中的区域,这里称为目标对象图像。
[0098]
另外,目标对象图像可以是第一样本图像中包括目标对象在第一样本图像的位置信息的目标对象的所在区域,还可以是第一样本图像中不包括目标对象在第一样本图像的
位置信息的目标对象的所在区域,本申请实施例对此不作具体限定,但目标对象图像是基于目标对象的边缘轮廓从第一样本图像中获得的目标对象的所在区域。
[0099]
需要说明的是,目标对象为第一样本图像中的各个对象中属于目标类别的对象,其中,各个对象指第一样本图像中的各个实体;目标类别为图像检测的各个类别中待进行图像数量增强的类别,其中,各个类别为检测模型进行图像检测时所能够检测出的类别。
[0100]
s603、将目标对象图像覆盖在与目标对象图像的场景类型适配的待覆盖图像上,得到第二样本图像,从而得到包括第一样本图像和第二样本图像的目标样本图像。
[0101]
在本申请实施例中,服务器获得目标对象图像之后,由于目标对象图像是目标对象对应的图像,从而,能够基于目标对象确定目标对象图像对应的场景类型;比如,目标对象为车时,场景类型为室外。接下来,服务器获得了目标对象图像的场景类型之后,基于目标对象图像进行样本数量增强时,获取与目标对象图像的场景类型适配的待覆盖图像,并将目标对象图像覆盖在待覆盖图像上而获得的图像即第二样本图像,作为增强的样本,从而,用于训练检测模型的目标样本图像则包括第一样本图像和第二样本图像。其中,覆盖是一种确定目标对象图像在待覆盖图像上的待覆盖区域,并将待覆盖区域中的各个像素点信息替换为目标对象图像中的各个像素点信息的处理。
[0102]
示例性地,当第一样本图像包括1000张图像时,如果从1000张图像中能够获得50个车的轮廓信息(目标对象图像);如果与车的场景类型室外适配的图像(待覆盖图像)有200张,则能够获得1000张包括车辆的样本图像(第二样本图像),如果每张图像中包括一辆车,则原有的车的样本图像数量由50扩展到了1050,达到了达到样本增强的目的。
[0103]
需要说明的是,待覆盖图像为场景类型与目标对象图像的场景类型相同的图像,可以是从样本数据库获得的,也可以是从网络中搜集到的图像,等等,本申请实施例对此不作具体限定。
[0104]
这里,服务器将目标对象图像覆盖在待覆盖图像上时,可以是将目标对象图像覆盖在待覆盖图像上的任意位置;也可以是将目标对象图像覆盖在待覆盖图像上仅包含背景的位置处;又可以将目标对象图像覆盖在待覆盖图像上与目标对象在第一样本图像上的位置信息对应的位置处;还可以将目标对象图像进行翻转、旋转、比例缩放、裁剪、移位和添加噪声等处理中的至少一种处理后,再将处理后的目标对象图像覆盖在待覆盖图像上;等等,本申请实施例对此不作具体限定。
[0105]
可以理解的是,由于目标对象图像是基于目标对象在第一样本图像中的目标轮廓信息获得的,从而目标对象图像中不包括第一样本图像中的背景信息,能够与待覆盖图像进行较好的融合,降低了失真率,增强了增强后的样本图像的真实性;从而,基于目标样本图像训练获得的目标检测模型的泛化能力较强,图像检测的精准度高。
[0106]
s604、基于目标样本图像训练检测模型,得到目标检测模型,以基于目标检测模型对待检测图像进行图像检测。
[0107]
在本申请实施例中,服务器完成样本数量的增强之后,基于增强后的样本图像即目标样本图像训练检测模型,当完成训练时,训练后的检测模型即目标检测模型,该目标检测模型用于对待检测图像进行图像检测;这里,目标检测模型用于对待检测图像中对象的类别进行检测。
[0108]
需要说明的是,服务器基于目标样本图像训练检测模型的过程,可以是模型训练
阶段的训练,还可以是模型优化阶段的训练,又可以是其他阶段的训练,等等,本申请实施例对此不作具体限定。
[0109]
示例性地,参见图7a,图7a是本申请实施例提供的一种示例性的获取第二样本图像的示意图;如图7a所示,样本图像3-1(参见图3)为第一样本图像中的一张图像,获取样本图像3-1中的车辆(目标对象)7a-1所在区域(目标对象图像),缩放车辆7a-1的所在区域后覆盖在待覆盖图像上,如样本增强图像7a-3中的车辆图像7a-2;这里,样本增强图像7a-3属于第二样本图像。
[0110]
下面继续对图7a的过程进行说明,参见图7b,图7b是本申请实施例提供的又一种示例性的获取第二样本图像的示意图;如图7b所示,样本图像3-1(参见图3)为第一样本图像中的一张图像,获取样本图像3-1中的车辆(目标对象)7a-1所在区域,得到车辆图像7b-1(目标对象图像),缩放车辆图像7b-1后覆盖在待覆盖图像7b-2上,得到样本增强图像7a-3,样本增强图像7a-3中包括缩放后的车辆图像7b-1即车辆图像7a-2;这里,样本增强图像7a-3属于第二样本图像。
[0111]
参见图7c,图7c是本申请实施例提供的另一种示例性的获取第二样本图像的示意图;如图7c所示,样本图像7c-1为待覆盖图像中的一张图像,将车辆图像7c-2(目标对象图像)覆盖在待覆盖图像上,得到样本增强图像7c-3;这里,样本增强图像7c-3属于第二样本图像。
[0112]
可以理解的是,基于目标对象在第一样本图像中的目标边缘轮廓,将目标对象在第一样本图像中的区域作为目标对象图像,贴附在与目标对象图像的场景类型适配的待覆盖图像上而得到第二样本图像,使得用于训练检测模型的目标样本图像不仅包括第一样本图像,还包括第二样本图像,实现了样本图像数量的增强;因此,训练得到的目标检测模型对应的图像检测的精准度较高,从而,能够提升图像检测的精准度。
[0113]
在本申请实施例中,s602中服务器获取目标对象在第一样本图像中的目标边缘轮廓,包括s6021-s6023,下面对各步骤分别进行说明。
[0114]
s6021、对第一样本图像进行边缘检测,得到边缘检测结果。
[0115]
在本申请实施例中,服务器基于边缘检测获取目标对象的目标边缘轮廓时,对第一样本图像中的各个对象的边缘轮廓进行检测,所获得的第一样本图像中的各个对象的边缘轮廓即边缘检测结果。
[0116]
需要说明的时,服务器对第一样本图像进行边缘检测时,可以通过训练完成的边缘检测模型实现;还可以采用边缘检测算法实现,比如,拉普拉斯边缘检测算法、索贝尔边缘检测算法和canny(多级)边缘检测算法;等等,本申请实施例对此不作具体限定。
[0117]
s6022、获取边缘检测结果中的各个边缘轮廓对应的类别。
[0118]
需要说明的是,边缘检测结果包括目标对象的目标边缘轮廓,而目标对象对应目标类别,服务器为了从边缘检测结果中获取目标对象对应的目标边缘轮廓,获取边缘检测结果中的各个边缘轮廓对应的类别;其中,各个边缘轮廓对应的类别包括目标类别。
[0119]
这里,服务器可以进行边缘检测的同时获得的各个边缘轮廓对应的类别,还可以是通过实体识别获得各个边缘轮廓对应的类别,又可以是通过人工标注的方式获得的各个边缘轮廓对应的类别,等等,本申请实施例对此不作具体限定。
[0120]
s6023、基于各个边缘轮廓对应的对象类别,从边缘检测结果中,获取与目标类别
适配的边缘轮廓,得到目标对象对应的目标边缘轮廓。
[0121]
需要说明的是,各个边缘轮廓对应的对象类别中与目标类别对应的类别所对应的边缘轮廓,即边缘检测结果中与目标类别适配的边缘轮廓,也就是目标对象对应的目标边缘轮廓。
[0122]
在本申请实施例中,s602中服务器获取目标对象在第一样本图像中的目标边缘轮廓,包括s6024-s6026,下面对各步骤分别进行说明。
[0123]
s6024、对第一样本图像进行实例分割,得到实例分割结果。
[0124]
需要说明的是,实例分割是从第一样本图像中分割出对象的边缘轮廓,基于对象的边缘轮廓输出第一样本图像中的对象的掩膜的过程;从而,实例分割结果为第一样本图像中的各个对象的掩膜。
[0125]
s6025、从实例分割结果中,获取目标对象对应的目标对象掩膜。
[0126]
需要说明的是,目标对象掩膜,是指第一样本图像中的目标对象的边缘轮廓构成的封闭区域内像素值为1,而边缘轮廓构成的封闭区域外的像素值为0的二值图像。这里,可以将目标对象掩膜作为目标边缘轮廓,此时,将不再执行s6026,根据目标对象掩膜获取目标对象图像;也可以将目标对象掩膜中的边缘轮廓作为目标边缘轮廓,即s6026。
[0127]
s6026、将目标对象掩膜中的边缘轮廓,确定为目标边缘轮廓。
[0128]
需要说明的是,目标对象掩膜中的边缘轮廓,即目标边缘轮廓。
[0129]
参见图8,图8是本申请实施例提供的一种示例性的训练检测模型的流程示意图;如图8所示,首先,服务器对第一样本图像8-1进行边缘检测或实例分割,获取目标对象图像8-2;然后,服务器获取待覆盖图像8-3,将目标对象图像8-2覆盖在待覆盖图像8-3上,得到第二样本图像8-4,从而,也就得到了包括第一样本图像8-1和第二样本图像8-4的目标样本图像8-5;最后,服务器基于目标样本图像8-5训练检测模型8-6,得到目标检测模型8-7。
[0130]
可以理解的是,由于实例分割是基于目标对象的边缘轮廓确定目标对象的掩膜的处理,因此,基于实例分割能够准确地获取到目标对象的所在区域,即目标对象图像;从而,能够降低目标对象图像的噪声;进而,将目标对象图像覆盖在场景类型相同的待覆盖图像时,所获得的增强的样本图像的失真率较低,能够提升检测模型的训练效果。
[0131]
在本申请实施例中,s6024可通过s60241-s60244实现;也就是说,服务器对第一样本图像进行实例分割,得到实例分割结果,包括s60241-s60244,下面对各步骤分别进行说明。
[0132]
s60241、从第一样本图像中,选择预设数量的图像作为待标注图像。
[0133]
需要说明的是,服务器对第一样本图像进行实例分割时,可以从第一样本图像中选择部分图像进行标注,以训练用于进行实例分割的网络模型,进而实现第一样本图像的实例分割。从而,服务器从第一样本图像中,选择预设数量的图像即从第一样本图像中选择部分图像,作为训练用于进行实例分割的网络模型的样本图像,这里称为待标注图像。
[0134]
s60242、获取待标注图像的实例分割标签。
[0135]
在本申请实施例中,当对待标注图像中的各个对象对应的掩膜进行标注时,服务器也就获得了待标注图像的实例分割标签。也就是说,实例分割标签为待标注图像中的各个对象对应的掩膜。这里,可以通过掩膜标注客户端(比如,“labelme”工具)获取待标注图像的实例分割标签。
[0136]
s60243、基于待标注图像和实例分割标签,训练实例分割模型,得到目标实例分割模型。
[0137]
需要说明的是,服务器获得了待标注图像的实例分割标签之后,利用实例分割模型预测待标注图像中的各个对象的掩膜,并基于预测出的待标注图像中的各个对象的边缘轮廓与实例分割标签之间的差异(比如,损失函数值),调整实例分割模型的参数,进而再基于参数调整后的实例分割模型预测待标注图像中的各个对象的掩膜,如此,对实例分割模型进行迭代训练,当训练结束时,当前训练得到的实例分割模型即目标实例分割模型。其中,实例分割模型为用于对图像进行实例分割的待训练网络模型,比如,mask r-cnn模型。
[0138]
在本申请实施例中,实例分割模型包括区域确定模型和分割模型,此时,s60243中服务器基于待标注图像和实例分割标签,训练实例分割模型,得到目标实例分割模型,包括:服务器基于区域确定模型,获取待标注图像的感兴趣区域;并基于分割模型,对感兴趣区域进行实例分割,得到分割预测结果;以及,基于分割预测结果和实例分割标签之间的差异,对实例分割模型进行迭代训练,直到满足训练截止条件(比如,损失函数值小于损失函数阈值,模型评估值达到了预设设置的值等)时,结束迭代训练,得到目标实例分割模型。
[0139]
s60244、基于目标实例分割模型,对第一样本图像中除待标注图像之外的剩余样本图像进行实例分割,得到对象掩膜,从而得到包括实例分割标签和对象掩膜的实例分割结果。
[0140]
需要说明的是,目标实例分割模型为用于进行实例分割的网络模型,从而,服务器获得了目标实例分割模型之后,就可以对第一样本图像中除待标注图像之外的剩余样本图像进行实例分割了,实例分割的结果即对象掩膜;这里,对象掩膜即剩余样本图像中的各个对象的掩膜。从而,待标注图像中的各个对象对应的掩膜和剩余样本图像中的各个对象的掩膜就构成了第一样本图像对应的实例分割结果;因此,实例分割结果包括实例分割标签和对象掩膜。
[0141]
示例性地,当第一样本图像包括1000张图像时,选取700(预设数量)张图像进行人工标注实例,进而基于标注的实例和700张图像训练实例分割模型,从而得到目标实例分割模型;再利用目标实例分割模型对剩余300张图像(剩余样本图像)进行实例分割。
[0142]
可以理解的是,本申请实施例通过对第一样本图像中的部分图像中的各个对象的掩膜进行标注以训练得到目标实例分割模型,进而利用目标实例分割模型对剩余样本图像进行实例分割;如此,能够提升对第一样本图像实例分割的效率和智能性。
[0143]
在本申请实施例中,s60242可通过s602421-s602423实现;也就是说,服务器获取待标注图像的实例分割标签,包括s602421-s602423,下面对各步骤分别进行说明。
[0144]
s602421、在掩膜标注客户端上呈现待标注图像。
[0145]
需要说明的是,服务器上安装有掩膜标注客户端,该掩膜标注客户端用于对图像中的各个对象的掩膜进行标注;这里,服务器通过在图像标注客户端上呈现待标注图像,以对待标注图像进行掩膜的标注。
[0146]
s602422、接收针对待标注图像的标注操作。
[0147]
在本申请实施例中,当用户对显示的待标注图像进行标注时,服务器也就接收到了针对待标注图像的标注操作。这里,标注操作用于借助掩膜标注客户端确定待标注图像中的各个对象的掩膜。
[0148]
s602423、响应于标注操作,生成待标注图像的描述文件,描述文件中包括实例分割标签。
[0149]
在本申请实施例中,服务器获得了标注操作之后,响应于该标注操作,也就获得了包括实例分割标签的描述文件。
[0150]
示例性地,参见图9,图9是本申请实施例提供的一种示例性的实例标注示意图;如图9所示,运行开源工具“labelme”,在开源工具“labelme”上呈现待标注图像9-11,如界面9-1所示;在界面9-1上对待标注图像9-11上的各个对象的边缘进行点击形成连线,获取待标注图像9-11上的各个对象的掩膜,如界面9-2中的掩膜9-21(实例分割标签)。这里,界面9-2中呈现的针对待标注图像9-11的掩膜9-21存储在“json”格式的描述文件中;其中,待标注图像中的一张图像对应描述文件中的一个描述文件。
[0151]
在本申请实施例中,描述文件中还包括实例分割标签对应的标注类别;该标注类别为每完成一个对象的掩膜的标注之后,响应于用户输入的标注类别而获得的;另外,s60243中服务器得到目标实例分割模型之后,该图像检测方法还包括s60245,下面对该步骤进行说明。
[0152]
s60245、基于目标实例分割模型,对剩余样本图像进行实例分割,得到对象掩膜对应的对象类别。
[0153]
需要说明的是,服务器基于目标实例分割模型,对剩余样本图像进行实例分割时,所获得的实例分割的结果中还包括对象掩膜对应的对象类别。也就是说,此时,目标实例分割模型还具备确定掩膜类别的功能,从而,实例分割标签对应的标注类别与实例分割标签,共同作为实例分割模型的训练样本。
[0154]
在本申请实施例中,s6025可通过s60251和s60252实现;也就是说,服务器从实例分割结果中,获取目标对象对应的目标对象掩膜,包括s60251和s60252,下面对各步骤分别进行说明。
[0155]
s60251、基于标注类别,确定实例分割标签中与目标类别适配的第一子目标对象掩膜。
[0156]
需要说明的是,标注类别与实例分割结果中的实例分割标签对应,从而,服务器获取标注类别中与目标类别匹配的类别所对应的掩膜,也就得到了实例分割标签中与目标类别适配的第一子目标对象掩膜。
[0157]
s60252、基于对象类别,确定对象掩膜中与目标类别适配的第二子目标对象掩膜,从而得到目标对象对应的包括第一子目标对象掩膜和第二子目标对象掩膜的目标对象掩膜。
[0158]
需要说明的是,对象类别与实例分割结果中的对象掩膜对应,从而,服务器获取对象类别中与目标类别匹配的类别所对应的掩膜,也就得到了对象掩膜中与目标类别适配的第二子目标对象掩膜;这里,目标对象掩膜包括第一子目标对象掩膜和第二子目标对象掩膜。
[0159]
参见图10,图10是本申请实施例提供的图像检测方法的另一个可选的流程示意图;如图10所示,在本申请实施例中,s603之前还包括s605-s608;也就是说,服务器将目标对象图像覆盖在与目标对象图像的场景类型适配的待覆盖图像上之前,该图像检测方法还包括s605-s608,下面对各步骤分别进行说明。
[0160]
s605、获取初始待覆盖图像。
[0161]
需要说明的是,初始待覆盖图像中包括与目标对象图像的场景类型适配的图像,还包括与目标对象图像的场景类型不适配的图像。
[0162]
s606、对初始待覆盖图像进行场景类型划分,得到各个场景类型。
[0163]
需要说明的是,服务器为了从初始待覆盖图像中获得待覆盖图像,对初始待覆盖图像进行场景类型划分,得到各个场景类型,以基于各个场景类型从初始待覆盖图像中筛选待覆盖图像。
[0164]
这里,服务器对对初始待覆盖图像进行场景类型划分时,可以通过像素点特征进行场景类型的划分。
[0165]
s607、从各个场景类型中,选择出与目标对象图像的场景类型匹配的目标场景类型。
[0166]
需要说明的是,服务器获得了各个场景类型之后,由于各个场景类型与初始待覆盖图像对应,从而,服务器先确定各个场景类型中与目标对象图像的场景类型匹配的场景类型,也就得到了目标场景类型。
[0167]
s608、将初始待覆盖图像中与目标场景类型适配的图像,确定为待覆盖图像。
[0168]
这里,初始待覆盖图像中与目标场景类型适配的图像即待覆盖图像。
[0169]
在本申请实施例中,s606可通过s6061-s6063实现;也就是说,服务器对初始待覆盖图像进行场景类型划分,得到各个场景类型,包括s6061-s6063,下面对各步骤分别进行说明。
[0170]
s6061、获取初始待覆盖图像在预设通道中的颜色通道信息对应的颜色通道值。
[0171]
需要说明的是,预设通道可以为rgb(red green blue,红绿蓝)颜色通道中至少一个通道,比如,g通道。而颜色通道值为基于预设通道中的颜色通道信息计算得到的值,比如,图像中像素点对应的g通道的颜色通道信息对应的众数或平均值等。
[0172]
s6062、比较颜色通道值与至少一个颜色通道阈值。
[0173]
在本申请实施例中,服务器中设置有至少一个颜色通道阈值,或服务器能够获取到至少一个颜色通道阈值,该至少一个颜色通道阈值用于确定各个场景类型。
[0174]
s6063、基于比较结果,确定初始待覆盖图像所属的各个场景类型。
[0175]
需要说明的是,根据颜色通道值与至少一个颜色通道阈值的比较结果,也就获得了初始待覆盖图像中每张图像所属的场景类型,从而得到初始待覆盖图像所属的各个场景类型。
[0176]
这里,当至少一个颜色通道阈值为一个目标颜色通道阈值(比如,绿色通道阈值200),服务器比较颜色通道值与目标颜色通道阈值比较时,当颜色通道值大于目标颜色通道阈值时,确定初始待覆盖图像属于第一场景类型(比如,室外);当颜色通道值小于或等于颜色通道阈值时,确定初始待覆盖图像属于第二场景类型(比如,室内);此时,各个场景类型包括第一场景类型和第二场景类型。
[0177]
示例性地,参见图11a,图11a为本申请实施例提供的一种示例性的划分场景类型的结果示意图;如图11a所示,初始待覆盖图像对应4种场景类型(各个场景类型):场景类型11a-1、场景类型11a-2、场景类型11a-3和场景类型11a-4。
[0178]
可以理解的是,本申请实施例通过对初始待覆盖图像进行场景类型的划分,使得
能够筛选出与目标对象图像的场景类型相适配的待覆盖图像,从而,当将目标对象图像覆盖在待覆盖图像上时,能够提升第二样本图像的真实性。
[0179]
在本申请实施例中,s601可通过s6011和s6012实现;也就是说,服务器获取第一样本图像,包括s6011和s6012,下面对各步骤分别进行说明。
[0180]
s6011、获取检测模型对应的训练样本图像。
[0181]
需要说明的是,训练样本图像为用于对检测模型进行训练的全部的样本图像,即各个类别对应的样本图像;该训练样本图像包括第一样本图像。
[0182]
s6012、从训练样本图像中,获取与目标类别对应的第一样本图像。
[0183]
在本申请实施例中,由于目标类别为各个类别中待进行样本数量增强的类别,因此,服务器从训练样本图像中,获取与目标类别对应的第一样本图像,以实现对第一样本图像的样本数量增强。
[0184]
相应地,在本申请实施例中,s604中服务器基于目标样本图像训练检测模型,得到目标检测模型,包括:获取训练样本图像中除第一样本图像之外的剩余训练样本图像;基于剩余训练样本图像和目标样本图像训练检测模型,得到目标检测模型。也就是说,服务器完成了对第一样本图像的样本数量增强之后,也就调节了各个类别的样本图像的比例,完成了各个类别的样本平衡的调节,进而基于调节后的样本库(剩余训练样本图像和目标样本图像)训练检测模型;如此,能够提升目标检测模型针对各个类别的检测结果的准确度。
[0185]
在本申请实施例中,s604可通过s6041-s6043实现;也就是说,服务器基于目标样本图像训练检测模型,得到目标检测模型,包括s6041-s6043,下面对各步骤分别进行说明。
[0186]
s6041、获取目标样本图像对应的目标标注信息。
[0187]
在本申请实施例中,服务器获取目标样本图像中目标对象图像的外接矩形框信息,并获取目标对象图像对应的目标对象类别,将外接矩形框信息和目标对象类别组合为目标标注信息。这里,目标标注信息为目标样本图像中目标对象对应的标注信息,比如,目标对象的位置信息和目标类别中的至少一种。另外,目标对象类别包括目标实例分割模型输出的对象类别和描述文件中的标注类别。
[0188]
示例性地,参见图11b,图11b是本申请实施例提供的一种示例性的标注目标样本图像的示意图;如图11b所示,图像11b-1为目标样本图像中的一张图像,对图像11b-1进行实例分割处理11b-2,得到图像11b-3,将图像11b-3经过“opencv”的“boundingrect”接口,也就获得了包括目标对应的外接矩形框的图像11b-4。
[0189]
s6042、基于检测模型,对目标样本图像进行图像检测,得到目标预测信息。
[0190]
需要说明的是,服务器获得了目标样本图像对应的目标标注信息之后,利用检测模型,对目标样本图像进行图像检测,所获得的图像检测结果即目标预测信息;比如,预测出的目标对象的位置信息,目标对象对应的类别。
[0191]
s6043、基于目标预测信息与目标标注信息之间的损失,迭代训练检测模型,获取迭代训练过程中各个类别对应的平均精度均值,直到平均精度均值达到平均精度均值阈值时,停止迭代训练,得到目标检测模型。
[0192]
需要说明的是,服务器基于目标预测信息与目标标注信息之间的损失(比如,损失函数值),调整检测模型的参数,进而再基于参数调整后的检测模型对目标样本图像进行图像检测,如此,对检测模型进行迭代训练,获取迭代训练过程中各个类别对应的平均精度均
值,直到平均精度均值达到平均精度均值阈值时,停止迭代训练,当前训练得到的检测模型即目标检测模型。
[0193]
参见图11c,图11c是本申请实施例提供的图像检测方法的另一个可选的流程示意图;如图11c所示,在本申请实施例中,s604之后还包括s609和s610;也就是说,基于目标样本图像训练检测模型,得到目标检测模型之后,方法还包括:
[0194]
s609、获取待检测图像。
[0195]
需要说明的是,当对图像中对象进行检测时,服务器也就获得了待检测图像;这里,待检测图像为虚拟场景的渲染图像或监控设备发送的监控图像等。
[0196]
s610、基于目标检测模型对待检测图像进行图像检测,得到待检测图像中的待检测对象信息。
[0197]
需要说明的是,由于目标检测图像用于对图像中的对象进行检测,因此,服务器获得了待检测图像之后,将待检测图像输入至目标检测模型,所获得的检测结果即待检测图像中的待检测对象信息。这里,待检测对象信息包括待检测对象的位置信息和待检测对象的类别。
[0198]
在本申请实施例中,当待检测图像为虚拟场景的渲染图像时,待检测对象的位置信息为虚拟目标的位置信息,待检测对象的类别为虚拟目标的类别,比如,敌人,队友,交通工具等;其中,虚拟目标包括虚拟对象和虚拟道具中的至少一种;此时,s610之后还包括s611;也就是说,服务器基于目标检测模型对待检测图像进行图像检测,得到待检测图像中的待检测对象信息之后,该图像检测方法还包括s611,下面对该步骤进行说明。
[0199]
s611、基于虚拟目标的类别,确定针对虚拟目标的位置信息处的虚拟目标的交互操作。
[0200]
需要说明的是,根据目标检测图像进行图像检测所获得的虚拟目标的位置信息和虚拟目标的类别,基于虚拟目标的类别,确定针对虚拟目标的位置信息处的虚拟目标的交互操作,以实现虚拟场景渲染应用的人工智能,比如,游戏ai。
[0201]
在本申请实施例中,当待检测图像为监控设备发送的监控图像时,待检测对象的位置信息为监控目标的位置信息,待检测对象的类别为监控目标的类别;其中,监控目标的类别为:车辆、生物体(比如,行人、宠物等)和智能设备(比如,机器人)中的至少一种;此时,s610之后还包括s612和s613;也就是说,服务器基于目标检测模型对待检测图像进行图像检测,得到待检测图像中的待检测对象信息之后,该图像检测方法还包括s612和s613,下面对该步骤进行说明。
[0202]
s612、基于监控目标的类别,确定待监控目标。
[0203]
需要说明的是,监控图像中包括各种类别的对象,比如,当监控图像中对应的监控目标的类别为车辆、生物体时,服务器根据监控请求,从车辆类别对应的对象中确定待监控目标为小汽车a。
[0204]
s613、从监控目标的位置信息中获得待监控目标的目标位置信息,基于目标位置信息,确定待监控目标的活动轨迹信息。
[0205]
需要说明的是,服务器确定了待监控目标之后,从监控目标的位置信息中获得待监控目标的目标位置信息,并基于目标位置信息,确定待监控目标的活动轨迹信息,进而实现对待监控目标的跟踪。
[0206]
下面,将说明本申请实施例在一个实际的应用场景中的示例性应用。
[0207]
示例性的,参见图12,图12是本申请实施例提供的图像检测方法的一种示例性的实现流程图;如图12所示,在游戏应用中,获取样本图像12-1(第一样本图像),从样本图像12-1中选择部分图像12-2(待标注图像)进行实例标注(参见图9),获得标注的实例12-3(实例分割标签);进而,基于部分图像12-2和标注的实例12-3训练分割模型12-4(实例分割模型),并利用训练好的分割模型12-5(目标实例分割模型)对样本图像12-1中的剩余图像12-6进行实例分割,以实现对样本图像12-1的实例分割;以及基于实例分割结果生成新样本图像12-7(第二样本图像),以实现样本增强;最后,利用样本图像12-1和新样本图像12-7训练检测模型12-8。
[0208]
下面,继续对图12描述的实现流程进行说明。其中,分割模型12-4的框架参见图13,图13是本申请实施例提供的一种示例性的实例分割模型的框架示意图;如图13所示,实例分割模型包括两个分支:目标检测分支13-1和预测目标掩膜的分支13-2,其中,目标检测分支13-1用于输出目标检测框和对应的类别,预测目标掩膜的分支13-2用于输出实例分割掩膜。图像13-3为分割模型12-4的输入,在分割模型12-4中,图像13-3经过感兴趣区域校准模块13-4(采用“roialign”技术实现的模块)之后,经过目标检测分支13-1输出目标检测框和对应的类别13-5,同时依次经过预测目标掩膜的分支13-2中的卷积层13-21和卷积层13-22,输出目标掩膜13-6(对象掩膜)。
[0209]
利用训练好的分割模型12-5对剩余图像12-6进行实例分割的过程参见图14,图14是本申请实施例提供的一种示例性的实例分割实现流程的示意图;如图14所示,待进行实例分割的图像14-1(剩余样本图像)输入至训练好的分割模型12-5,也就输出了图像14-1中的各个对象的掩膜14-2(对象掩膜)。
[0210]
样本增强的过程参见图15,图15是本申请实施例提供的一种示例性的增强样本的示意图;如图15所示,图12中样本图像12-1通过实例分割,获得实例分割结果15-1;接着基于实例分割结果15-1获取分割出的目标物(目标对象图像),并贴附在场景类型相同的图像15-2(待覆盖图像)上,从而,得到图12中的新样本图像12-7。
[0211]
训练检测模型12-8的过程参见图16,图16是本申请实施例提供的一种示例性的训练检测模型的流程示意图;如图16所示,利用样本库16-1(目标样本图像,包括图12中样本图像12-1和新样本图像12-7)训练检测模型12-8,得到预测检测结果16-2(目标预测信息)。这里,针对样本库16-1的图像16-11,所获得的预测检测结果为:目标检测框16-21(x0,y0,w0,h0)和类别16-22(敌人);针对样本库16-1的图像16-12,所获得的预测检测结果:目标检测框16-23(x1,y1,w1,h1)和类别16-24(交通工具)、目标检测框16-25(x2,y2,w2,h2)和类别16-26(交通工具)、以及目标检测框16-27(x3,y3,w3,h3)和类别16-28(敌人)。
[0212]
下面继续说明本申请实施例提供的图像检测方法在游戏应用中的应用。采用图12示出的图像检测方法时,如果原样本图像的数量为390,通过实例分割或边缘检测进行样本数量增强,使得增强后的样本图像的数量为1807,如表1所示:
[0213]
表1
[0214]
原样本图像的数量增强后的样本图像的数量3901807
[0215]
当检测模型12-8为“yolo v3”模型时,训练次数相同的情况下,增强后的样本图像
训练出的“yolo v3”模型的平均精度均值,比原样本图像训练出的“yolo v3”模型的平均精度均值高;如表2所示:
[0216]
表2
[0217]
训练次数原样本图像增强后的样本图像8万60.24%64.20%32万64.2%71.14%
[0218]
由表2可知,当训练次数为8万次时,增强后的样本图像训练出的“yolo v3”模型的平均精度均值,比原样本图像训练出的“yolo v3”模型的平均精度均值提升了3.96%;当训练次数为32万次时,增强后的样本图像训练出的“yolo v3”模型的平均精度均值,比原样本图像训练出的“yolo v3”模型的平均精度均值提升了6.94%。如此表明,通过实例分割或边缘检测进行样本数量增强,可有效的提升检测模型的精度。
[0219]
下面继续说明本申请实施例提供的图像检测装置455的实施为软件模块的示例性结构,在一些实施例中,如图5所示,存储在存储器450的图像检测装置455中的软件模块可以包括:
[0220]
图像获取模块4551,用于获取第一样本图像,其中,所述第一样本图像为检测模型对应的待增强样本图像,所述检测模型为用于检测图像的待训练网络模型;
[0221]
图像分割模块4552,用于获取目标对象在所述第一样本图像中的目标边缘轮廓,基于所述目标边缘轮廓,获取所述目标对象在所述第一样本图像中的区域,得到目标对象图像,其中,所述目标对象属于目标类别,所述目标类别为图像检测的各个类别中待进行图像数量增强的类别;
[0222]
图像覆盖模块4553,用于将所述目标对象图像覆盖在与所述目标对象图像的场景类型适配的待覆盖图像上,得到第二样本图像,从而得到包括所述第一样本图像和所述第二样本图像的目标样本图像;
[0223]
模型训练模块4554,用于基于所述目标样本图像训练所述检测模型,得到目标检测模型,以基于所述目标检测模型对待检测图像进行图像检测。
[0224]
在本申请实施例中,所述图像分割模块4552,还用于对所述第一样本图像进行边缘检测,得到边缘检测结果;获取所述边缘检测结果中的各个边缘轮廓对应的类别;基于所述各个边缘轮廓对应的类别,从所述边缘检测结果中,获取与所述目标类别适配的边缘轮廓,得到所述目标对象对应的所述目标边缘轮廓。
[0225]
在本申请实施例中,所述图像分割模块4552,还用于对所述第一样本图像进行实例分割,得到实例分割结果;从所述实例分割结果中,获取所述目标对象对应的所述目标对象掩膜;将所述目标对象掩膜中的边缘轮廓,确定为所述目标边缘轮廓。
[0226]
在本申请实施例中,所述图像分割模块4552,还用于从所述第一样本图像中,选择预设数量的图像作为待标注图像;获取所述待标注图像的实例分割标签;基于所述待标注图像和所述实例分割标签,训练实例分割模型,得到目标实例分割模型,其中,所述实例分割模型为用于对图像进行实例分割的待训练网络模型;基于所述目标实例分割模型,对所述第一样本图像中除所述待标注图像之外的剩余样本图像进行实例分割,得到对象掩膜,从而得到包括所述实例分割标签和所述对象掩膜的所述实例分割结果。
[0227]
在本申请实施例中,所述图像分割模块4552,还用于在掩膜标注客户端上呈现所
述待标注图像;接收针对所述待标注图像的标注操作;响应于所述标注操作,生成所述待标注图像的描述文件,所述描述文件中包括所述实例分割标签。
[0228]
在本申请实施例中,所述描述文件中还包括所述实例分割标签对应的标注类别;所述图像分割模块4552,还用于基于所述目标实例分割模型,对所述剩余样本图像进行实例分割,得到所述对象掩膜对应的对象类别;
[0229]
在本申请实施例中,所述图像分割模块4552,还用于基于所述标注类别,确定所述实例分割标签中与所述目标类别适配的第一子目标对象掩膜;基于所述对象类别,确定所述对象掩膜中与所述目标类别适配的第二子目标对象掩膜,从而得到所述目标对象对应的包括所述第一子目标对象掩膜和所述第二子目标对象掩膜的所述目标对象掩膜。
[0230]
在本申请实施例中,所述图像检测装置455还包括图像选择模块4555,用于获取初始待覆盖图像;对所述初始待覆盖图像进行场景类型划分,得到各个场景类型;从所述各个场景类型中,选择出与所述目标对象图像的场景类型匹配的目标场景类型;将所述初始待覆盖图像中与所述目标场景类型适配的图像,确定为所述待覆盖图像。
[0231]
在本申请实施例中,所述图像选择模块4555,还用于获取所述初始待覆盖图像在预设通道中的颜色通道信息对应的颜色通道值;比较所述颜色通道值与至少一个颜色通道阈值;基于比较结果,确定所述初始待覆盖图像所属的所述各个场景类型。
[0232]
在本申请实施例中,所述图像检测装置455还包括样本选择模块4556,用于获取所述检测模型对应的训练样本图像;从所述训练样本图像中,获取与所述目标类别对应的所述第一样本图像。
[0233]
在本申请实施例中,所述图像获取模块4551,还用于获取所述训练样本图像中除所述第一样本图像之外的剩余训练样本图像;基于所述剩余训练样本图像和所述目标样本图像训练所述检测模型,得到所述目标检测模型。
[0234]
在本申请实施例中,所述模型训练模块4554,还用于获取所述目标样本图像对应的目标标注信息;基于所述检测模型,对所述目标样本图像进行图像检测,得到目标预测信息;基于所述目标预测信息与所述目标标注信息之间的损失,迭代训练所述检测模型,获取迭代训练过程中各个类别对应的平均精度均值,直到所述平均精度均值达到平均精度均值阈值时,停止迭代训练,得到所述目标检测模型。
[0235]
在本申请实施例中,所述图像检测装置455还包括模型应用模块4557,用于获取所述待检测图像;基于所述目标检测模型对所述待检测图像进行图像检测,得到所述待检测图像中的待检测对象信息,其中,所述待检测对象信息包括待检测对象的位置信息和所述待检测对象的类别。
[0236]
在本申请实施例中,当所述待检测图像为虚拟场景的渲染图像时,所述待检测对象的位置信息为虚拟目标的位置信息,所述待检测对象的类别为所述虚拟目标的类别;其中,所述虚拟目标包括虚拟对象和虚拟道具中的至少一种;所述图像检测装置455还包括结果应用模块4558,用于基于所述虚拟目标的类别,确定针对所述虚拟目标的位置信息处的所述虚拟目标的交互操作。
[0237]
在本申请实施例中,当所述待检测图像为监控设备发送的监控图像时,所述待检测对象的位置信息为监控目标的位置信息,所述待检测对象的类别为所述监控目标的类别;其中,所述监控目标的类别为:车辆、生物体和智能设备中的至少一种;所述结果应用模
块4558,还用于基于所述监控目标的类别,确定所述监控目标中的待监控目标;从所述监控目标的位置信息中获得所述待监控目标的目标位置信息,基于所述目标位置信息,确定所述待监控目标的活动轨迹信息。
[0238]
本申请实施例提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行本申请实施例上述的图像检测方法。
[0239]
本申请实施例提供一种存储有可执行指令的计算机可读存储介质,其中存储有可执行指令,当可执行指令被处理器执行时,将引起处理器执行本申请实施例提供的图像检测方法,例如,如图6示出的图像检测方法。
[0240]
在一些实施例中,计算机可读存储介质可以是fram、rom、prom、eprom、eeprom、闪存、磁表面存储器、光盘、或cd-rom等存储器;也可以是包括上述存储器之一或任意组合的各种设备。
[0241]
在一些实施例中,可执行指令可以采用程序、软件、软件模块、脚本或代码的形式,按任意形式的编程语言(包括编译或解释语言,或者声明性或过程性语言)来编写,并且其可按任意形式部署,包括被部署为独立的程序或者被部署为模块、组件、子例程或者适合在计算环境中使用的其它单元。
[0242]
作为示例,可执行指令可以但不一定对应于文件系统中的文件,可以可被存储在保存其它程序或数据的文件的一部分,例如,存储在超文本标记语言(html,hyper text markup language)文档中的一个或多个脚本中,存储在专用于所讨论的程序的单个文件中,或者,存储在多个协同文件(例如,存储一个或多个模块、子程序或代码部分的文件)中。
[0243]
作为示例,可执行指令可被部署为在一个计算设备上执行,或者在位于一个地点的多个计算设备上执行,又或者,在分布在多个地点且通过通信网络互连的多个计算设备上执行。
[0244]
综上所述,通过本申请实施例,基于目标对象在第一样本图像中的目标边缘轮廓,将目标对象在第一样本图像中的区域作为目标对象图像,贴附在与目标对象图像的场景类型适配的待覆盖图像上而得到第二样本图像,使得用于训练检测模型的目标样本图像不仅包括第一样本图像,还包括第二样本图像,实现了样本图像数量的增强;因此,训练得到的目标检测模型对应的图像检测的精准度较高,从而,能够提升图像检测的精准度。
[0245]
以上所述,仅为本申请的实施例而已,并非用于限定本申请的保护范围。凡在本申请的精神和范围之内所作的任何修改、等同替换和改进等,均包含在本申请的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1