提升Spark结构化流文件数据源读取性能方法及装置与流程
提升spark结构化流文件数据源读取性能方法及装置
技术领域
[0001]
本发明涉及大数据技术领域,具体涉及一种提升spark structured streaming文件数据源读取性能的方法以及装置。
背景技术:
[0002]
spark structured streaming(spark结构化流)是用于实时数据处理的大数据计算引擎,可针对海量数据进行计算、分析。
[0003]
使用spark structured streaming监控文件目录时,目录下的文件会源源不断的增加,由于spark structured streaming在每个批次读取数据时,需要列出目录下的所有文件,以遍历最新的文件进行实时读取。这就带来了以下问题:
[0004]
(1)、每个批次都需要列出目录下所有文件,如果文件数量非常多,很有可能会导致内存溢出;
[0005]
(2)、遍历所有文件,成本开销大,降低实时处理的性能;
[0006]
(3)、当手工清理目录下已经处理完成的文件时,面临无法识别哪些文件已经处理完成的问题。
[0007]
针对上述问题,目前尚未提出有效的解决方案。
技术实现要素:
[0008]
本发明通过在生成数据源文件的时候,同步生成一份描述文件的基本信息的元数据,存储在专用的元数据文件中。每个批次在读取文件时,只需要遍历该元数据文件即可。同时,增加数据清理的逻辑,将已完成处理的文件执行删除或者移动至备份的目录,减少文件数据源目录下的文件数量,提升了读取性能。
[0009]
为实现上述目的,提供了如下方案:
[0010]
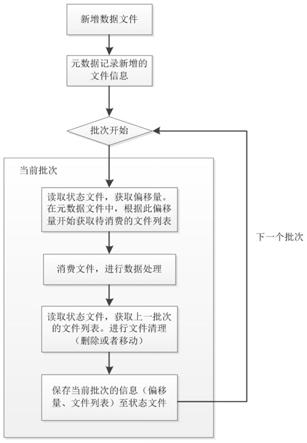
一种提升spark structured streaming文件数据源读取性能的方法,其步骤为:
[0011]
(1)对新增的待监控文件数据源同步生成一份配置其基本信息的元数据文件;
[0012]
(2)读取存储上一批次任务对应的文件列表以及上一批次任务消费的文件在元数据文件中偏移量的状态文件,在元数据文件中,根据此偏移量,获取待消费的文件列表,进行处理;
[0013]
(3)读取状态文件列表,根据清理策略对上一批次的文件进行数据清理,并更新状态文件。
[0014]
进一步的,将上述步骤发布为二进制jar包,在项目中调用,经过开发提交至spark的集群运行。
[0015]
进一步的,将上述元数据文件和状态文件的路径作为改造过的spark structured streaming的filestreamsource数据源类的构造参数来用于读取文件列表;
[0016]
进一步的,如果清理策略为删除,则删除上一批次对应的数据文件。如果清理策略为移动,则将上一批次对应的已完成处理的文件移动至已设置的目录进行备份;
[0017]
进一步的,上述生成的元数据文件包括文件名、文件大小、修改时间、文件的状态等基本信息。
[0018]
本发明还提供一种提升spark structured streaming文件数据源读取性能的装置,包括:
[0019]
元数据生成模块,用于对新批次的待监控数据源文件同步生成一份元数据文件;
[0020]
数据源读取模块,用于读取存储上一批次任务对应的文件列表以及上一批次任务消费的文件在元数据文件中偏移量的状态文件,在元数据文件中,根据此偏移量,获取待消费的文件列表,进行处理;
[0021]
数据源清理模块,用于根据状态文件列表,根据清理策略对上一批次的文件进行数据清理,并更新状态文件。
[0022]
本发明实施例在每个批次的任务执行完成后,只需要在检查点文件中保存已完成处理的文件在元数据文件中的偏移量,而不需要保存所有的已完成文件的列表,大幅降低检查点文件的大小。每个批次的任务,在获取最新的文件时,不需要列出数据源目录的所有文件,只需要从上一次消费的元数据文件的偏移量开始读取文件列表。文件清理逻辑减少了数据源目录下文件的数量,提升了每个批次数据读取的性能和稳定性,避免文件过多导致性能下降甚至内存溢出。
附图说明
[0023]
为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
[0024]
图1是本发明实施例中一种提升spark structured streaming文件数据源读取性能的方法和装置的数据源读取流程图;
[0025]
图2是本发明实施例中一种提升spark structured streaming文件数据源读取性能的方法和装置的偏移量说明图。
[0026]
图3是本发明实施例中一种提升spark structured streaming文件数据源读取性能的方法和装置的项目实施流程图。
具体实施方式
[0027]
为使本发明实施例的目的、技术方案和优点更加清楚明白,下面结合附图对本发明实施例做进一步详细说明。在此,本发明的示意性实施例及其说明用于解释本发明,但并不作为对本发明的限定。
[0028]
如前所述,spark structured streaming在读取监控文件目录时,目录下的文件会源源不断的增加,如果遍历所有文件的话,那么当文件数量非常多的时候,很有可能会导致内存溢出;而且,成本开销会很大,降低实时处理的性能;其次,在当手工清理目录下已经处理完成的文件时,面临无法识别哪些文件已经处理完成的问题。
[0029]
为了提高数据处理效率,减少处理工作量,降低成本,本发明实施例提供一种提升spark structured streaming文件数据源读取性能的方法,如图1所示,该方法可以包括以下步骤:
[0030]
(1)对新增的待监控文件数据源同步生成一份配置其基本信息的元数据文件;
[0031]
(2)读取存储上一批次任务对应的文件列表以及上一批次任务消费的文件在元数据文件中偏移量的状态文件,在元数据文件中,根据此偏移量,获取待消费的文件列表,进行处理;
[0032]
(3)读取状态文件列表,根据清理策略对上一批次的文件进行数据清理,并更新状态文件。
[0033]
具体实施时,新增一个专用的文件或者目录,存储文件的基本信息,包括文件名、文件大小、修改时间等元数据信息。
[0034]
数据在写入spark structured streaming的监控目录时,在元数据文件中生成一条该文件的记录。
[0035]
配置示例可参考如下:
[0036]
{"path":"/data/input/part001.csv","size":34,"modificationtime":1599100115000}
[0037]
{"path":"/data/input/part002.csv","size":134,"modificationtime":1599100116022}
[0038]
{"path":"/data/input/part003.csv","size":37,"modificationtime":1599100117045}
[0039]
必须保证在生成数据源文件的时候,同步生成一份元数据。
[0040]
实施例中,在读取文件列表时,新增spark structured streaming的文件数据源类,该类基于原生的filestreamsource的数据源类(注:该类是实时监控输入目录的核心功能类)进行改造。将元数据文件路径和状态文件的路径作为构造参数。
[0041]
如下,红色部分的metapath和statuspath参数为新增的参数,metapath指定元数据文件的路径,statuspath指定状态文件的路径。
[0042]
class filestreamsourcenew(
[0043]
sparksession:sparksession,
[0044]
path:string,
[0045]
fileformatclassname:string,
[0046]
override val schema:structtype,
[0047]
partitioncolumns:seq[string],
[0048]
metapath:string,
[0049]
statuspath:string,
[0050]
options:map[string,string])
[0051]
在读取数据时,从元数据文件读取文件列表,从状态文件读取上一个批次任务对应的文件列表以及上一批次的任务消费的文件在元数据文件中的偏移量(对偏移量的说明见图3)。
[0052]
状态文件的格式示例:
[0053]
{"batchid":122,"offset":145,"files":["/data/a11.json","/data/a22.json","/data/a33.json"]}
[0054]
batchid指定上一个批次的编号。offset指定了上一批次的任务消费的文件在元
数据文件中的偏移量。files指定了上一个批次消费的文件列表。
[0055]
实施例中,当structured streaming每个批次的任务启动后,从文件列表中筛选未处理的文件进行消费。
[0056]
在状态文件中,存储的是上一批次任务消费的文件列表在元数据文件的中的偏移量。本次消费时,从上一次提交的偏移量开始读取文件列表即可。这样可避免读取元数据文件中的所有的文件列表,因为文件数过多,将导致文件列表非常大,读取时需要消耗更多的cpu和内存资源,甚至可能会内存溢出。简单说,通过偏移量读取数据,可避免把整个文件加载到内存,从而避免文件过大导致的内存溢出。
[0057]
具体实施时,在数据源的类中,增加一个方法,在该方法中进行任务完成的通知以及数据源的清理。
[0058]
(1)、获取数据清理的方式
[0059]
在数据源的options参数(该参数即步骤中第二步的构造参数)中获取数据源清理的方式。
[0060]
(2)、清理文件
[0061]
从状态文件中,获取上一个批次任务对应的状态文件列表。
[0062]
如果清理策略为删除,则删除这个批次对应的数据文件,其代码为:
[0063]
val stream=spark.readstream
[0064]
.option(map(
[0065]
"clean"->"delete",//参数:表示将已处理的文件删除。
[0066]
).csv("/data/csv")//注释部分:监控/data/csv目录下的文件。
[0067]
这里以csv为例,还可以监控orc、parquet、json、text等多种文件格式的目录。
[0068]
如果清理策略为移动,则还需要从上面options参数中获取文件移动至哪个目录,然后将这个批次对应的已完成处理的文件移动至该目录进行备份。其代码为:
[0069]
>"move",//参数1:表示将已处理的文件移动至备份目录。
[0070]
"archivedir"->"file:///tmp/aa"//参数2:配置备份目录的路径
[0071]
).format("org.spark.userdefined.filesource").
[0072]
load("/data/csv")//注释部分:监控/data/csv目录下的文件。
[0073]
这里以csv为例,还可以监控orc、parquet、json、text等多种文件格式的目录。
[0074]
(3)、更新状态文件
[0075]
完成任务消费后,更新状态文件,将本批次的数据写入状态文件。包括当前批次的编号,当前批次消费的文件在元数据文件中的偏移量,以及当前批次对应的文件列表。当前批次的状态文件供下一个批次的任务读取并使用。
[0076]
例如:
[0077]
{"batchid":123,"offset":146,"files":["/data/a11.json","/data/a22.json","/data/a33.json"]}
[0078]
通过上面的流程,实现了一个具备元数据管理和文件清理功能的数据源,将上面实现的代码发布为具体的二进制jar包。在任何需要该功能的项目中,引用上面生成的jar包,进行数据开发。
[0079]
可以构建为spark的执行jar包,按照spark任务提交的规范,提交至spark的集群
运行。具体流程见图3。
[0080]
基于同一发明构思,本发明实施例中还提供了一种提升spark structured streaming文件数据源读取性能的装置,由于其原理与一种提升spark structured streaming文件数据源读取性能的方法相似,因此一种提升spark structured streaming文件数据源读取性能的装置的实施可以参见上述用于一种提升spark structured streaming文件数据源读取性能的方法的实施,重复之处不再赘述。以下所使用的,术语“模块”可以实现预定功能的软件和/或硬件的组合。尽管以下实施例所描述的装置较佳地以软件来实现,但是硬件,或者软件和硬件的组合的实现也是可能并被构想的。
[0081]
一种提升spark structured streaming文件数据源读取性能的装置,包括:
[0082]
元数据生成模块,用于对新批次的待监控数据源文件同步生成一份元数据文件;
[0083]
数据源读取模块,用于读取存储上一批次任务对应的文件列表以及上一批次任务消费的文件在元数据文件中偏移量的状态文件,在元数据文件中,根据此偏移量,获取待消费的文件列表,进行处理;
[0084]
数据源清理模块,用于根据状态文件列表,根据清理策略对上一批次的文件进行数据清理,并更新状态文件。
[0085]
本发明实施例提供技术方案可以达到的有益技术效果是:通过在生成数据源文件的时候,同步生成一份描述文件的基本信息的元数据,并存储在专用的元数据文件中。每个批次在读取文件时,只需要遍历该元数据文件即可。同时,文件清理逻辑减少了数据源目录下文件的数量,提升了每个批次数据读取的性能和稳定性,避免文件过多导致性能下降甚至内存溢出。
[0086]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1