基于人工智能体决策的伦理虚拟仿真实验方法和机器人与流程
[0001]
本发明涉及人工智能技术领域,特别是涉及一种基于人工智能体决策的伦理虚拟仿真实验方法和机器人。
背景技术:
[0002]
在实现本发明过程中,发明人发现现有技术中至少存在如下问题::现有的人工智能体决策的人工智能伦理风险及其防范无法进行实验,因为该实验存在着人工智能伦理风险,会给参与实验的人员带来危险。
[0003]
因此,现有技术还有待于改进和发展。
技术实现要素:
[0004]
基于此,有必要针对现有技术的缺陷或不足,提供基于人工智能体决策的伦理虚拟仿真实验方法和机器人,以解决现有技术中人工智能体决策防范伦理风险实验无法进行的问题。
[0005]
第一方面,本发明实施例提供一种人工智能方法,所述方法包括:
[0006]
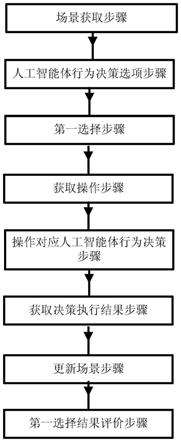
场景获取步骤:获取事件的场景;
[0007]
人工智能体行为决策选项步骤:获取人工智能体行为决策的多个选项,提示用户从所述多个选项中选择出在所述场景中符合人工智能伦理规则的人工智能体行为决策的正确选项;
[0008]
第一选择步骤:获取用户对所述多个选项在内的多种人工智能体行为决策进行虚拟实验的请求或用户对人工智能体行为决策的多个选项的第一选择结果;若获取到用户对所述多个选项在内的多种人工智能体行为决策进行虚拟实验的请求,则继续执行下一步;若获取到用户对所述多个选项的第一选择结果,则跳到第一选择结果评价步骤继续执行;
[0009]
获取操作步骤:获取用户对所述虚拟实验中场景的操作;
[0010]
操作对应人工智能体行为决策步骤:根据所述操作确定所述操作对应的人工智能体行为决策;
[0011]
获取决策执行结果步骤:从人工智能体行为决策执行知识库中检索所述人工智能体行为决策对应的执行结果;所述人工智能体行为决策执行知识库中包含人工智能体行为决策与执行结果的对应关系;若所述检索失败时,则所述人工智能体行为决策输入决策虚拟实验模型,将所述决策虚拟实验模型的输出作为所述执行结果;
[0012]
更新场景步骤:从人工智能体行为决策场景知识库中检索所述执行结果中执行后的场景状态对应的场景,根据所述场景更新所述虚拟实验中的场景;所述人工智能体行为决策场景知识库中包含执行结果中执行后的场景状态与场景的对应关系;若所述检索失败时,则所述执行结果中执行后的场景状态输入场景虚拟实验模型,将所述场景虚拟实验模型的输出作为场景,根据所述场景更新所述虚拟实验中的场景;
[0013]
第一选择结果评价步骤:获取在所述场景中符合人工智能伦理规则的人工智能体
行为决策的正确选项,将所述第一选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第一选择结果的评价结果。
[0014]
优选地,
[0015]
所述获取决策执行结果步骤还包括:将所述人工智能体行为决策执行知识库中每一人工智能体行为决策与对应的执行结果,分别作为深度学习模型的输入和预期输出,对所述深度学习模型进行训练和测试,得到决策虚拟实验模型;所述执行结果包括执行后的场景状态,执行后的场景是否符合人工智能伦理规则的判断,执行后的场景是否存在人工智能伦理风险的评定;显示所述执行结果;
[0016]
所述更新场景步骤还包括:将所述人工智能体行为决策场景知识库中每一执行结果与对应的场景,分别作为深度学习模型的输入和预期输出,对所述深度学习模型进行训练和测试,得到场景虚拟实验模型;根据所述执行结果更新所述场景中人工智能体的行为状态;根据所述执行结果更新所述场景中与所述执行结果相关的对象的行为状态;
[0017]
优选地,
[0018]
所述第一选择步骤还包括:获取需要进行虚拟实验的选项;
[0019]
所述获取操作步骤还包括:显示所述操作的内容;获取所述操作的操作位置和操作类型;
[0020]
所述操作对应人工智能体行为决策步骤还包括:根据所述操作位置和操作类型确定所述操作对应的人工智能体行为决策;获取用户对所述人工智能体行为决策进行执行的请求;若获取到用户对所述人工智能体行为决策进行执行的请求,则判断所述操作对应的人工智能体行为决策是否属于所述需要进行虚拟实验的选项:是,则显示当前操作属于所述选项的信息;若获取到用户对所述虚拟实验中场景的操作,则回到所述获取操作步骤继续执行。
[0021]
优选地,所述方法还包括:
[0022]
符合人工智能伦理规则原因选项步骤:显示人工智能体行为决策的正确选项,获取人工智能体行为决策的正确选项符合人工智能伦理规则的原因的多个选项,提示用户从所述多个选项中选择出人工智能体行为决策的正确选项符合人工智能伦理规则的原因的选项;
[0023]
第二选择步骤:获取用户对人工智能体行为决策的正确选项符合人工智能伦理规则的原因的多个选项的选择结果,作为第二选择结果;
[0024]
第二选择结果评价步骤:获取人工智能体行为决策的正确选项符合人工智能伦理规则的原因的正确选项,将所述第二选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第二选择结果的评价结果。
[0025]
优选地,所述方法还包括:
[0026]
人工智能伦理风险选项步骤:显示人工智能体行为决策的正确选项符合人工智能伦理规则的原因的正确选项,获取人工智能体行为决策的正确选项可能产生的人工智能伦理风险的多个选项,提示用户从所述多个选项中选择出人工智能体行为决策的正确选项可能产生的人工智能伦理风险的选项;
[0027]
第三选择步骤:获取用户对人工智能体行为决策的正确选项可能产生的人工智能伦理风险的多个选项的选择结果,作为第三选择结果;
[0028]
第三选择结果评价步骤:获取人工智能体行为决策的正确选项可能产生的人工智能伦理风险的正确选项,将所述第三选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第三选择结果的评价结果。
[0029]
优选地,所述方法还包括:
[0030]
人工智能体自动虚拟实验与决策请求步骤:获取用户进行人工智能体自动虚拟实验与决策的请求;
[0031]
人工智能体自动虚拟实验与决策动画步骤:播放人工智能体自动虚拟实验与决策的动画;所述人工智能体自动虚拟实验与决策的动画中包括输入场景、算法的执行、输出结果;所述人工智能体自动虚拟实验与决策的动画中输出结果包括符合人工智能伦理规则的场景预测、符合人工智能伦理规则的人工智能体行为预测、是否符合人工智能伦理规则的判断、人工智能体行为的人工智能伦理风险的评定;
[0032]
虚拟实验结果一致判断步骤:显示人工智能体自动虚拟实验与决策的动画中输出结果与用户进行虚拟实验的结果是否一致的判断的多个选项;
[0033]
第四选择步骤:获取用户对所述是否一致的判断的多个选项的选择结果,作为第四选择结果;
[0034]
第四选择结果评价步骤:显示所述是否一致的判断的正确选项,将所述第四选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第四选择结果的评价结果。
[0035]
优选地,所述方法还包括:
[0036]
重新虚拟实验步骤:获取用户重新进行所述虚拟实验的请求;在获取到用户重新进行所述虚拟实验的请求后回到所述获取操作步骤重新执行;
[0037]
退出虚拟实验步骤:获取用户退出所述虚拟实验的请求;在获取到用户退出所述虚拟实验的请求后回到所述人工智能体行为决策选项步骤重新执行;
[0038]
实验记录步骤:将所述用户、所述操作的时间、所述选择的时间、所述操作内容、所述执行结果、所述第一选择结果、所述第一选择结果的评价结果存入数据库并记录进实验报告。
[0039]
第二方面,本发明实施例提供一种人工智能装置(第二方面中的各模块的内容与第一方面各步骤的内容一一对应,所以第二方面中的各模块的内容不再赘述)
[0040]
所述装置包括:场景获取模块;人工智能体行为决策选项模块;第一选择模块;获取操作模块;操作对应人工智能体行为决策模块;获取决策执行结果模块;更新场景模块;第一选择结果评价模块。
[0041]
优选地,所述装置还包括:符合人工智能伦理规则原因选项模块;第二选择模块;第二选择结果评价模块。
[0042]
优选地,所述装置还包括:人工智能伦理风险选项模块;第三选择模块;第三选择结果评价模块。
[0043]
优选地,所述装置还包括:人工智能体自动虚拟实验与决策请求模块;人工智能体自动虚拟实验与决策动画模块;虚拟实验结果一致判断模块;第四选择模块;第四选择结果评价模块。
[0044]
优选地,所述装置还包括:重新虚拟实验模块;退出虚拟实验模块;实验记录模块。
[0045]
第三方面,本发明实施例提供一种人工智能伦理系统,所述系统包括第二方面实施例任意一项所述装置的模块。
[0046]
第四方面,本发明实施例提供一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现第一方面实施例任意一项所述方法的步骤。
[0047]
第五方面,本发明实施例提供一种机器人,包括存储器、处理器及存储在存储器上并可在处理器上运行的人工智能机器人程序,所述处理器执行所述程序时实现第一方面实施例任意一项所述方法的步骤。
[0048]
本实施例提供的基于人工智能体决策的伦理虚拟仿真实验方法和机器人,包括:场景获取步骤;人工智能体行为决策选项步骤;第一选择步骤;获取操作步骤;操作对应人工智能体行为决策步骤;获取决策执行结果步骤;更新场景步骤;第一选择结果评价步骤。上述方法、系统和机器人,通过不同的人工智能体行为决策选项的虚拟实验,使得用户能够通过虚拟实验来体验不同决策选项的执行效果,将实验与选择形式的考核结合起来,起到实验与考核相互促进的效果。而且还能通过深度学习模型来实现人工智能体行为决策的自动执行,并得到自动执行的结果,从而实现了人工智能体行为决策执行结果和执行后场景的预测。
附图说明
[0049]
图1为本发明的实施例提供的人工智能方法的流程图;图2为本发明的实施例提供的人工智能方法的流程图;图3为本发明的实施例提供的人工智能方法的流程图;图4为本发明的实施例提供的人工智能方法的流程图;图5为本发明的实施例提供的人工智能方法的流程图;图6为页面1和动画1;图7为页面2和动画2;图8为页面3和动画3;图9为页面4和动画4;图10为页面5和动画5;图11为页面6和动画6;图12为页面7和动画7;图13为页面8和动画8;图14为页面9和动画9;图15为页面10和动画10;图16为页面11和动画11;图17为页面12和动画12;图18为页面13和动画13;图19为页面14和动画14;图20为页面15和动画15;图21为页面16和动画16;图22为页面17和动画17;图23为页面18和动画18;图24为页面19和动画19;图25为页面20和动画20;图26为页面21和动画21;图27为页面22和动画22;图28为页面23和动画23;图29为页面24和动画24;图30为页面25和动画25;图31为页面26和动画26;图32为页面27和动画27;图33为页面28和动画28;图34为页面29和动画29;图35为页面30和动画30;图36为页面31和动画31;图37为页面32和动画32;图38为页面33和动画33;图39为页面34和动画34;图40为页面35和动画35左和动画35右;图41为页面36和动画36左和动画36右;图42为页面37和动画37左和动画37右;图43为页面38和动画38左和动画38右;图44为页面39和动画39;图45为页面40和动画40。
具体实施方式
[0050]
下面结合本发明实施方式,对本发明实施例中的技术方案进行详细地描述。
[0051]
本发明的基本实施例
[0052]
一种人工智能方法,如图1所示,所述方法包括:场景获取步骤;人工智能体行为决策选项步骤;第一选择步骤;获取操作步骤;操作对应人工智能体行为决策步骤;获取决策执行结果步骤;更新场景步骤;第一选择结果评价步骤。技术效果:所述方法通过不同的人
工智能体行为决策选项的虚拟实验,使得用户能够通过虚拟实验来体验不同决策选项的执行效果,从而为用户对决策选项的选择提供依据,使得用户能够带着选项的问题去做虚拟实验,然后又能根据虚拟实验的结果进行选项的选择,能够使得用户将实验和选项问题结合起来,将实验与选择形式的考核结合起来,起到实验与考核相互促进的效果。并且通过自动比对来判断用户的操作和对决策选项的选择是否正确,来提高用户的实验能力和实验成效。而且还能通过深度学习模型来实现人工智能体行为决策的自动执行,并得到自动执行的结果,从而实现了人工智能体行为决策执行结果和执行后场景的预测。
[0053]
在一个优选的实施例中,如图2所示,所述方法还包括:符合人工智能伦理规则原因选项步骤;第二选择步骤;第二选择结果评价步骤。技术效果:所述方法通过原因选项使得用户能够通过原因选项思考人工智能体决策能够防范伦理风险的原因,从而使得学生做完实验与考核之后,能够知其然,也能够知其所以然,从而提高实验的效果。并且通过自动比对来判断用户的对原因选项的选择是否正确,来提高用户的实验能力和实验成效。
[0054]
在一个优选的实施例中,如图3所示,所述方法还包括:人工智能伦理风险选项步骤;第三选择步骤;第三选择结果评价步骤。技术效果:所述方法通过风险选项来使得用户能够思考人工智能体决策选项可能产生的伦理风险,从而提高学生对伦理风险的判断能力。并且通过自动比对来判断用户的对风险选项的选择是否正确,来提高用户的实验能力和实验成效。
[0055]
在一个优选的实施例中,如图4所示,所述方法还包括:人工智能体自动虚拟实验与决策请求步骤;人工智能体自动虚拟实验与决策动画步骤;虚拟实验结果一致判断步骤;第四选择步骤;第四选择结果评价步骤。技术效果:所述方法通过自动虚拟实验来使得用户能够知晓人工智能体自动地进行虚拟实验的过程,并且能够将自动虚拟实验与用户进行的虚拟实验进行对比,从而加深用户对虚拟实验的理解,并且能增强用户对虚拟实验的掌握。
[0056]
在一个优选的实施例中,如图5所示,所述方法还包括:重新虚拟实验步骤;退出虚拟实验步骤;实验记录步骤。技术效果:所述方法通过执行人工智能体行为决策,让用户能真实地看到行为决策的执行结果,从而使得用户对实验有真实的体验感。
[0057]
本发明的优选实施例
[0058]
1获取事件的场景;获取人工智能体行为决策的多个选项,提示用户从所述多个选项中选择出在所述场景中符合人工智能伦理规则的人工智能体行为决策的正确选项;
[0059]
2获取用户对所述多个选项在内的多种人工智能体行为决策进行虚拟实验的请求或用户对人工智能体行为决策的多个选项的第一选择结果;若获取到用户对所述多个选项在内的多种人工智能体行为决策进行虚拟实验的请求,则继续执行下一步;若获取到用户对所述多个选项的第一选择结果,则跳到第10步继续执行;
[0060]
2.1显示虚拟实验的算法的输入、流程、输出的原理图;
[0061]
3获取用户对所述虚拟实验中场景的操作;
[0062]
3.1显示所述操作的内容;
[0063]
3.2获取所述操作的操作位置和操作类型;
[0064]
4根据所述操作确定所述操作对应的人工智能体行为决策;
[0065]
4.1根据所述操作位置和操作类型确定所述操作对应的人工智能体行为决策;
[0066]
4.3判断所述操作对应的人工智能体行为决策是否属于所述需要进行虚拟实验的
选项:是,则显示当前操作属于所述选项的信息;
[0067]
4.2获取用户对所述人工智能体行为决策进行执行的请求;若获取到用户对所述人工智能体行为决策进行执行的请求,则执行4.3;若获取到用户对所述虚拟实验中场景的操作,则跳到第3步继续执行;
[0068]
5从人工智能体行为决策执行知识库中检索所述人工智能体行为决策对应的执行结果;所述人工智能体行为决策执行知识库中包含人工智能体行为决策与执行结果的对应关系;若所述检索失败时,则所述人工智能体行为决策输入决策虚拟实验模型,将所述决策虚拟实验模型的输出作为所述执行结果。
[0069]
5.1所述执行结果包括执行后的场景状态(包括场景中人工智能体、人类及相关对象的行为状态),执行后的场景是否符合人工智能伦理规则的判断,执行后的场景是否存在人工智能伦理风险的评定。
[0070]
5.2显示所述执行结果;
[0071]
5.3将所述人工智能体行为决策执行知识库中每一人工智能体行为决策与对应的执行结果,分别作为深度学习模型的输入和预期输出,对所述深度学习模型进行训练和测试,得到决策虚拟实验模型。
[0072]
6从人工智能体行为决策场景知识库中检索所述执行结果中执行后的场景状态对应的场景,根据所述场景更新所述虚拟实验中的场景;所述人工智能体行为决策场景知识库中包含执行结果中执行后的场景状态与场景的对应关系;若所述检索失败时,则所述执行结果中执行后的场景状态输入场景虚拟实验模型,将所述场景虚拟实验模型的输出作为场景,根据所述场景更新所述虚拟实验中的场景。
[0073]
6.1根据所述执行结果更新所述场景中人工智能体的行为状态;
[0074]
6.1.1所述人工智能体包括机器人或无人车。
[0075]
6.1.2所述人工智能体的行为状态包括移动或射击或撞击或说话或受伤或其他行为状态或多种行为状态的组合。
[0076]
6.2根据所述执行结果更新所述场景中与所述执行结果相关的对象的行为状态。
[0077]
6.2.1所述相关的对象包括人类或装置。
[0078]
6.2.2所述相关的对象的行为包括移动或射击或撞击或说话或受伤或其他行为状态或多种行为状态的组合。
[0079]
6.3将所述人工智能体行为决策场景知识库中每一执行结果与对应的场景,分别作为深度学习模型的输入和预期输出,对所述深度学习模型进行训练和测试,得到场景虚拟实验模型。
[0080]
7获取用户重新进行所述虚拟实验的请求;在获取到用户重新进行所述虚拟实验的请求后回到步骤3重新执行。
[0081]
8获取用户退出所述虚拟实验的请求;在获取到用户退出所述虚拟实验的请求后回到步骤1重新执行。
[0082]
9获取在所述场景中符合人工智能伦理规则的人工智能体行为决策的正确选项,将所述第一选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第一选择结果的评价结果。
[0083]
10将所述用户、所述操作的时间、所述选择的时间、所述操作内容、所述执行结果、
所述第一选择结果、所述第一选择结果的评价结果存入数据库并记录进实验报告。
[0084]
11显示人工智能体行为决策的正确选项,获取人工智能体行为决策的正确选项符合人工智能伦理规则的原因的多个选项,提示用户从所述多个选项中选择出人工智能体行为决策的正确选项符合人工智能伦理规则的原因的选项;
[0085]
11.1播放人工智能体行为决策的正确选项对应的虚拟实验中的场景;
[0086]
12获取用户对人工智能体行为决策的正确选项符合人工智能伦理规则的原因的多个选项的选择结果,作为第二选择结果;
[0087]
13获取人工智能体行为决策的正确选项符合人工智能伦理规则的原因的正确选项,将所述第二选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第二选择结果的评价结果。
[0088]
14显示人工智能体行为决策的正确选项符合人工智能伦理规则的原因的正确选项,获取人工智能体行为决策的正确选项可能产生的人工智能伦理风险的多个选项,提示用户从所述多个选项中选择出人工智能体行为决策的正确选项可能产生的人工智能伦理风险的选项;
[0089]
14.1播放人工智能体行为决策的正确选项对应的虚拟实验中的场景;
[0090]
15获取用户对人工智能体行为决策的正确选项可能产生的人工智能伦理风险的多个选项的选择结果,作为第三选择结果;
[0091]
16获取人工智能体行为决策的正确选项可能产生的人工智能伦理风险的正确选项,将所述第三选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第三选择结果的评价结果。
[0092]
17显示人工智能体行为决策的正确选项可能产生的人工智能伦理风险的正确选项;
[0093]
18获取用户进行人工智能体自动虚拟实验与决策的请求;
[0094]
19播放人工智能体自动虚拟实验与决策的动画;
[0095]
19.1所述人工智能体自动虚拟实验与决策的动画中包括输入场景、算法的执行、输出结果。
[0096]
19.1.1所述人工智能体自动虚拟实验与决策的动画中输出结果包括符合人工智能伦理规则的场景预测、符合人工智能伦理规则的人工智能体行为预测、是否符合人工智能伦理规则的判断、人工智能体行为的人工智能伦理风险的评定。
[0097]
20显示人工智能体自动虚拟实验与决策的动画中输出结果与用户进行虚拟实验的结果是否一致的判断的多个选项;
[0098]
21获取用户对所述是否一致的判断的多个选项的选择结果,作为第四选择结果;
[0099]
22显示所述是否一致的判断的正确选项,将所述第四选择结果与所述正确选项进行对比,判断用户的选择是否正确作为对所述第四选择结果的评价结果。
[0100]
23获取用户对执行正确的人工智能体行为决策的请求;
[0101]
24播放执行正确的人工智能体行为决策的虚拟实验中的场景。
[0102]
25将所述用户、所述选择的时间、所述第二、三、四选择结果、所述第二、三、四选择结果的评价结果存入数据库并记录进实验报告。
[0103]
本发明的其他实施例
[0104]
如图6,左下角场景(可缩放)播放“从警车开始追赶逃犯车辆并射击直至出现等待区和阻止区”的动画,点击重播可重播该动画,点击进入实验场景后用户可与场景中对象进行交互。
[0105]
如图7,左下角播放“从警车开始追赶逃犯车辆并射击直至出现等待区和阻止区”的动画,点重新播放时可重播“从开始追赶直至出现等待区和阻止区”的动画。
[0106]
如图7,用户点击开始虚拟实验,则进入如下页面。如图8,左边的动画是“从警车开始追赶逃犯车辆并射击直至出现等待区和阻止区”,点重播时,重播该动画。
[0107]
如图8,用户点“进入虚拟实验”,则进入如图9。
[0108]
如图9,点放大,则进入如图10。
[0109]
如图10,若用户点击等待区,然后点击执行虚拟实验。如图11,画面显示无人车开到等待区,警车继续追赶无人车,不符合规则中的法则一,不存在风险。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0110]
如图11,若点击缩小,则复原到如图12。
[0111]
如图12,若点击重新开始虚拟实验,则进入如图13,虚拟实验时场景恢复到初始状态。
[0112]
如图13,若用户点击警车前面的阻止区,然后点击执行虚拟实验。如图14,画面显示警察被无人车阻止,逃犯车辆逃走,符合规则,存在“救助坏人”风险。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0113]
如图14,若点击重新开始虚拟实验,则进入如图15,虚拟实验时场景恢复到初始状态。
[0114]
如图16,若用户点击逃犯车辆前面的阻止区,然后点击执行虚拟实验,画面显示无人车挡住逃犯车辆,警车也开到逃犯车辆的前面挡住逃犯车辆,不符合规则中的法则一,不存在风险。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0115]
如图16,若点击重新开始虚拟实验,则进入如图17,虚拟实验时场景恢复到初始状态。
[0116]
如图18,若用户点击逃犯车辆,然后点击执行虚拟实验,画面显示无人车向逃犯车辆撞击,逃犯车辆内部罪犯被撞伤,不符合规则中的法则一,存在风险“无必要地伤害坏人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0117]
如图18,若点击重新开始虚拟实验,则进入如图19,虚拟实验时场景恢复到初始状态。
[0118]
如图20,若用户点击警车,然后点击执行虚拟实验,画面显示无人车向警车撞击,
警车内部警察被撞伤,不符合规则中的法则一,存在风险“伤害好人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0119]
如图20,若点击重新开始虚拟实验,则进入如图21,虚拟实验时场景恢复到初始状态。
[0120]
如图22,若用户点击警车前方的阻止区,并点击逃犯车辆,然后点击执行虚拟实验,画面显示无人车阻止警车,无人车向逃犯车辆撞击,逃犯车辆内逃犯被撞伤,不符合规则中的法则一,存在风险“救助坏人,无必要地伤害坏人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0121]
如图22,若点击重新开始虚拟实验,则进入如图23,虚拟实验时场景恢复到初始状态。
[0122]
如图24,若用户点击逃犯车辆前方阻止区,并点击逃犯车辆,然后点击执行虚拟实验,画面显示逃犯车辆被无人车阻止,无人车向逃犯车辆撞击,逃犯车辆内逃犯被撞伤,不符合规则中的法则一,存在风险“无必要地伤害坏人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0123]
如图24,若点击重新开始虚拟实验,则进入如图25,虚拟实验时场景恢复到初始状态。
[0124]
如图26,若用户点击警车前方的阻止区,并点击警车,然后点击执行虚拟实验,画面显示警车被无人车阻止,逃犯车辆逃走,无人车撞击警车,警车内警察被撞伤,不符合规则中的法则一,存在风险“救助坏人,伤害好人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0125]
如图26,若点击重新开始虚拟实验,则进入如图27,虚拟实验时场景恢复到初始状态。
[0126]
如图28,若用户点击逃犯车辆前方阻止区,并点击警车,然后点击执行虚拟实验,画面显示逃犯车辆被无人车阻止,无人车撞击警车,警车内警察被撞伤,不符合规则中的法则一,存在风险“伤害好人”。(说明:用户操作后,在下方显示操作内容,点击执行虚拟实验后,画面中显示出虚拟实验的结果,并在下方显示虚拟实验结果的内容。用户操作和虚拟实验的结果全部记录进该用户的虚拟实验数据表中。点击重新开始虚拟实验又进入等待操作的状态画面。)
[0127]
如图28,上面各虚拟实验的顺序可以进行改变,无固定的顺序。如图29,若用户点击退出虚拟实验,进入如下页面。如下页面,左下角播放“从警车开始追赶逃犯车辆并射击直至出现等待区和阻止区”的动画,点重新播放时可重播该动画。
[0128]
如图29,用户选择答案后点击“提交答案“,如图30,显示正确答案。如下页面,左下角播放“从出现等待区和阻止区直至无人车阻挡警车,逃犯车辆逃走”的动画,点重新播放时可重播该动画。
[0129]
如图30,点击“开始人工智能伦理判断”后,如图31,左侧循环播放“从出现等待区和阻止区直至无人车阻挡警车,逃犯车辆逃走”的动画,点重新播放时可重播该动画。
[0130]
如图31,用户点击“提交答案“后,显示如图32,左侧循环播放“从出现等待区和阻止区直至无人车阻挡警车,逃犯车辆逃走”的动画,点重新播放时可重播该动画。
[0131]
如图32,用户点击“开始风险评定“后进入如下页。如图33,左侧循环播放“从出现等待区和阻止区直至无人车阻挡警车,逃犯车辆逃走”的动画,点重新播放时可重播该动画。
[0132]
如图33,用户选择后点击提交答案,显示如图34。
[0133]
如图34,用户点击“开始自动虚拟实验与决策“,显示如图35。
[0134]
如图35,一秒后,自动进入如图36,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0135]
如图36,一秒后,自动进入如图37,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0136]
如图37,一秒后,自动进入如图38,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0137]
如图38,一秒后,自动进入如图39,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0138]
如图39,一秒后,自动进入如图40,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0139]
如图40,一秒后,自动进入如图41,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0140]
如图41,一秒后,自动进入如图42,标蓝的模块已执行完,标红的模块请红光闪烁表明正在执行
[0141]
如图42,用户点击提交,进入如图43
[0142]
如图43,用户点击执行决策,进入如图44
[0143]
如图44,用户点击“开始人类行为决策“后,进入如图45,动画播放“从警车开始追赶逃犯车辆直至出现等待区和阻止区”(注意:与动画1的区别在于,没有进行喊话示警和射击),点重播后重播该动画。
[0144]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,则对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1