一种通信网络风险评估的分布式随机森林方法与流程
[0001]
本发明涉及一种数据处理领域,具体是一种通信网络风险评估的分布式随机森林方法。
背景技术:
[0002]
目前,随着通信网络的快速稳定发展,5g网络时代的到来,使得传统2g、3g、4g网络的规模迅速扩大并且网络结构更为复杂,对通信网络进行风险评估有着至关重要的作用,它不仅确保运营商的正常运行,还可以为运营商提供准确、高效的运营保障。
[0003]
已有的风险评估方法在评估通信网络的安全时大多采用主观性判断,例如模糊综合评价法、层次分析法、专家打分法等,通过人为设定风险因素的权值以判断整个通信网络的安全程度,其缺点是显而易见的,在很大程度上影响评估结果的准确性。随着机器学习技术的迅速发展,以及日益增长的数据量,使得传统的主观性风险评估方法不在适用,基于大数据及机器学习方法的风险评估技术受到广泛关注。在面对处理海量数据时,集中式的机器学习方法的效率则令人担忧,并且容易造成通信过载,损毁设备。
[0004]
因此,为了得到一种既能高效处理海量数据,又能避免产生通信过载的通信网络风险评估方法,需要考虑分布式处理技术。利用分布式机器学习方法,既能避免集中式的低效率,又能防止通信过载,从而达到一种最优的数据处理模式,针对这种情况,现提出一种通信网络风险评估的分布式随机森林方法。
技术实现要素:
[0005]
本发明的目的在于提供一种通信网络风险评估的分布式随机森林方法,旨在提高风险评估中大数据的处理效率,同时避免集中式的通信过载问题,解决了传统通信网络风险评估方法的缺点,使得风险评估的结果更为可靠,此外该方法提高了集中式机器学习方法处理大数据的效率,节约了时间成本。
[0006]
本发明的目的可以通过以下技术方案实现:
[0007]
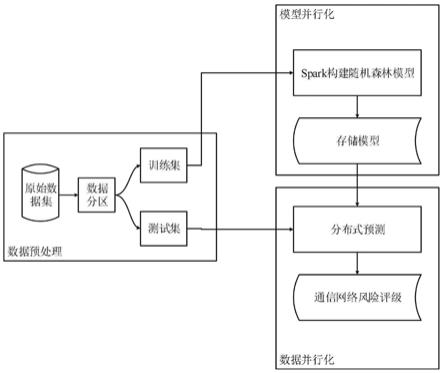
一种通信网络风险评估的分布式随机森林方法,包括数据预处理阶段、模型的离线训练阶段以及在线预测阶段,通过数据预处理阶段将训练数据划分为最佳数量的分区,使所提出的模型能够加速并行和分布式训练任务,将分区后的数据划分为训练集和测试集,然后利用spark构建随机森林模型进行训练,最后利用训练后的模型进行在线预测。
[0008]
进一步地,所述数据预处理阶段由于跨节点的数据分布对于并行和分布式计算的效率至关重要,利用spark中的rdd技术进行分区操作,并且将训练数据划分为最佳数量的分区,使所提出的模型能够加速并行和分布式训练任务,设置n
p
为分区数目的集合,time(rdd
train
,n
p
)表示根据参数n
p
计执行训练任务所需的计算时间的函数,最优分区数为:
[0009]
使得
[0010]
其中是分区的最佳数,得到最优分区后,对分区后的数据进行训练集和测试集的划分,以最终进行模型的训练和测试。
[0011]
进一步地,所述离线训练阶段利用spark构建随机森林模型,在模型构建过程中,利用bootstrap对训练数据进行采样生成新的训练数据,并从新的训练数据中根据基尼指数选择最优的特征以进行树的划分,最后集成每棵树构建随机森林模型,具体步骤如下
[0012]
step 1:输入分区的训练数据集
[0013]
for train of each partition do
[0014]
step 2:
[0015]
step 3:生成随机森林模型{h
i
,i=1,2,...,n
tree
}。
[0016]
进一步地,所述在线预测阶段基于数据的并行化,以及python多线程编程和spark的并行框架,将测试集的每个样本并行分配到工作节点中,利用离线训练过的模型进行最终的预测。
[0017]
本发明的有益效果:
[0018]
1、本发明解决了传统通信网络风险评估方法的缺点,使得风险评估的结果更为可靠,此外该方法提高了集中式机器学习方法处理大数据的效率,节约了时间成本;
[0019]
2、本发明提高风险评估中大数据的处理效率,同时避免集中式的通信过载问题。
附图说明
[0020]
下面结合附图对本发明作进一步的说明。
[0021]
图1是本发明通信网络风险评估的分布式随机森林方法实施流程图;
[0022]
图2是本发明通信网络风险评估的分布式随机森林方法运行效率对比图;
[0023]
图3是本发明在真实数据集上的roc曲线图。
具体实施方式
[0024]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
[0025]
一种通信网络风险评估的分布式随机森林方法,如图1所示,通过运用spark中的rdd技术将数据集进行分区操作,利用spark分布式计算框架建立随机森林模型,并最终进行预测,该方法旨在提高集中式环境中进行通信网络风险评估时大数据处理的效率,并且避免单个处理单元的通信过载问题,如图1所示,在数据预处理阶段,由于跨节点的数据分布对于并行和分布式计算的效率至关重要。此步骤的主要目标是将训练数据rdd
train
划分为
最佳数量的分区,使所提出的模型能够加速并行和分布式训练任务,设置n
p
为分区数目的集合,time(rdd
train
,n
p
)表示根据参数n
p
计执行训练任务所需的计算时间的函数。最优分区数为:
[0026]
使得其中是分区的最佳数。得到最优分区后,对分区后的数据进行训练集和测试集的划分,以最终进行模型的训练和测试。
[0027]
模型的并行化离线训练阶段利用spark构建随机森林模型,具体步骤如下
[0028]
step 1:输入分区的训练数据集
[0029]
for train of each partition do
[0030]
step 2:
[0031]
step 3:生成随机森林模型{h
i
,i=1,2,...,n
tree
}
[0032]
模型的在线预测阶段利用数据的并行化,基于python多线程编程和spark的并行框架,将测试集的每个样本并行分配到工作节点中,利用离线训练过的模型进行最终的预测。
[0033]
考虑该方法的运行效率问题,如图2所示,在真实数据集上进行实验,选取accuracy、recall、f1 score、roc曲线、pr为该方法评价指标,实验结果从图中可以看出,该方法在分布式环境下的运行时间约为集中式环境中的一半,从而表明该算法在处理通信网络大数据时的高效性。
[0034]
为了衡量该方法的有效性,在真实数据集上进行实验,选取roc曲线作为评价指标,运行结果如图3所示,从图中可以看出,该方法在roc曲线中的auc面积高于另外两个竞争的算法,从而体现出所提方法在实际处理问题时有更好的性能。
[0035]
在本说明书的描述中,参考术语“一个实施例”、“示例”、“具体示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不一定指的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任何的一个或多个实施例或示例中以合适的方式结合。
[0036]
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1