一种地址信息数据的处理方法与流程
[0001]
本发明涉及地理信息处理领域,尤其涉及一种地址信息数据的处理方法。
背景技术:
[0002]
地址信息在邮政通信、城市规划建设和对外交流方面具有重要的作用。
[0003]
但在地址信息数据的实际应用场景中,诸如民政、住建和公安等不同部门数据标准不一,且各部门之间未形成地址数据联动更新机制,导致地址信息数据来源多样化、地址信息数据编码标准不统一以及地址信息数据重复等现象普遍存在,这给人们的工作生活以及经济社会的正常有序发展带来不便。面对地址信息数据编码标准不统一以及地址信息数据重复等现象,各地现已开展地址信息数据融合和数据清洗工作,目前多采用自动融合或者半自动融合的方式进行,得到标准化的地址信息数据,并进行地址解析,将地址空间化,匹配到相对应的空间位置。
[0004]
在实际的处理工作中,面对庞大的地址信息数据,在半自动融合处理和地址解析过程中通常会存在误差或者错误,目前多采用在使用过程中随机发现错误并改正方式,或以人工遍历的方式在庞大的地址信息数据库中查找出现误差或者错误的地址信息数据,并且标记出存疑地址信息数据以及改正这些存疑地址信息数据。
[0005]
然而,采用人工遍历地址信息数据库及标记存疑地址信息数据的方法不仅效率低,而且无法满足在海量地址信息数据库中快速查找存疑地址点的实际需求,也无法确保地址信息数据库中的地址信息数据准确性。
技术实现要素:
[0006]
本发明所要解决的技术问题是针对上述现有技术提供一种地址信息数据的处理方法。
[0007]
本发明解决上述技术问题所采用的技术方案为:一种地址信息数据的处理方法,其特征在于,包括如下步骤:
[0008]
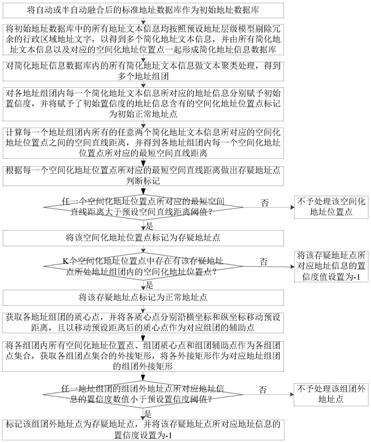
步骤1,将自动或半自动融合后的标准地址数据库作为初始地址数据库;其中,初始地址数据库为地址信息按照预设地址层级标准化及空间化处理后的地址数据库,初始地址数据库内的每条地址信息均含有一个地址文本信息以及一个与该地址文本信息相对应的空间化地址位置点;
[0009]
步骤2,将初始地址数据库中的所有地址文本信息均按照预设地址层级模型剔除冗余的行政区域地址文字,以得到多个简化地址文本信息,并由所有简化地址文本信息以及对应的空间化地址位置点一起形成简化地址信息数据库;其中,简化地址信息数据库内的任一条地址信息均含有一个简化地址文本信息以及与该简化地址文本信息相对应的空间化地址位置点;
[0010]
步骤3,对简化地址信息数据库内的所有简化地址文本信息做文本聚类处理,得到多个地址组团;
[0011]
步骤4,对各地址组团内每一个简化地址文本信息所对应的地址信息分别赋予初始置信度,并将赋予了初始置信度的地址信息含有的空间化地址位置点标记为初始正常地址点;其中,针对任一个地址组团,初始置信度的数值为该地址组团内所有地址信息的总数量;
[0012]
步骤5,计算每一个地址组团内所有的任意两个简化地址文本信息所对应的空间化地址位置点之间的空间直线距离,并得到各地址组团内每一个空间化地址位置点所对应的最短空间直线距离;
[0013]
步骤6,根据每一个空间化地址位置点所对应的最短空间直线距离做出存疑地址点判断标记:
[0014]
当任一个空间化地址位置点所对应的最短空间直线距离大于预设空间直线距离阈值时,将该空间化地址位置点标记为存疑地址点,转入步骤7;否则,不予处理该空间化地址位置点;
[0015]
步骤7,求解与该存疑地址点最临近的k个空间化地址位置点,并根据求解结果做出判断处理:
[0016]
当所得k个空间化地址位置点中存在有该存疑地址点所处地址组团内的空间化地址位置点时,将该存疑地址点标记为正常地址点,转入步骤8;否则,将该存疑地址点所对应地址信息的置信度值设置为-1;
[0017]
步骤8,获取各地址组团的质心点,并将各质心点分别沿横坐标和纵坐标移动预设距离,且以移动预设距离后的质心点作为对应组团的辅助点;
[0018]
步骤9,将各组团内所有空间化地址位置点、组团质心点和组团辅助点作为各组团点集合,获取各组团点集合的外接矩形,将各外接矩形作为对应地址组团的组团外接矩形;其中,位于组团外接矩形范围内的非该组团的空间化地址位置点为对应地址组团的组团外地址点;
[0019]
步骤10,对各地址组团外接矩形范围内的组团外地址点做出判断处理:
[0020]
当任一地址组团的组团外地址点所对应地址信息的置信度数值小于预设置信度阈值时,标记该组团外地址点为存疑地址点,并将该存疑地址点所对应地址信息的置信度设置为-1;否则,不予处理该组团外地址点。
[0021]
改进地,为了进一步降低错误空间化地址位置点的漏查率,在该发明的所述地址信息数据的处理方法中,在步骤10之后还包括:设置针对所有空间化地址位置点所对应地址信息置信度数值的核验阈值;以及将置信度数值小于所述核验阈值的地址信息对应的空间化地址位置点标记为奇异点,并进行奇异点人工核验操作。其中,在针对奇异点人工核验操作过程中,优先遍历存疑地址点的人工检核,而后再进行奇异点的人工核验操作。
[0022]
进一步地,在所述地址信息数据的处理方法中,所述k的数值可以根据需要进行调整设置。例如,可以将k的数值设置为2或3。
[0023]
进一步地,在所述地址信息数据的处理方法中,所述预设置信度阈值可以根据需要进行调整设置。例如,可以将预设置信度阈值的数值设置为10。
[0024]
再进一步地,在所述地址信息数据的处理方法中,所述核验阈值可以根据需要进行调整设置。例如,可以将上述核验阈值的数值设置为4或5。
[0025]
为了避免经聚类处理后得到的地址组团点集无法直接生成外接矩形(例如组团内
只有2个空间化地址位置点,或者因地址组团内的空间化地址位置点呈直线分布),改进地,在所述地址信息数据的处理方法中,步骤8中的所述预设距离可以根据需要进行调整设置。例如,可以将该预设距离的数值设置在区间(0.1m,1m)以内。
[0026]
作为改进地,为了在形成的初始地址数据库内筛选出具有较大概率发生地址错误或地理编码过程中出错的空间化地址位置点,在该发明中,步骤6中的所述预设空间直线距离阈值也可以根据需要进行调整设置。例如,该发明中的预设空间直线距离阈值设置为150m。
[0027]
在实际的地址信息数据处理操作中,所述预设空间直线距离阈值的设置规则可改进为:当地址信息文本分词中含有道路名称时,预设空间直线距离阈值设置为100m;含有小区名称时,预设空间直线距离阈值设置为80m;其余不含上述字样(地址文本分词既不含道路名称,又不含小区名称的情况)时,预设空间直线距离阈值设置为150m。
[0028]
与现有技术相比,本发明的优点在于:该发明通过将自动或半自动融合后的标准地址数据库作为初始地址数据库,且对该初始地址数据库的所有地址文本信息做冗余简化处理,得到简化地址信息数据库,然后对简化地址信息数据库内所有地址文本做聚类处理,得到多个地址组团,而后根据地址组团内各空间化地址位置点所对应的最短空间直线距离与预设空间直线距离阈值的比较判断出存疑地址点,再求得与存疑地址点最临近的k个空间化地址位置点以及各地址组团外接矩形,最终根据组团外地址点判断出存疑地址点,从而实现在海量地址信息数据中筛选出部分存疑数据,有利于降低地址信息数据查错过程中的工作量,提高针对存疑地址点的查找标记效率,进一步提高了处理后地址信息数据的准确性。
附图说明
[0029]
图1为本发明实施例中地址信息数据的处理方法流程示意图。
具体实施方式
[0030]
以下结合附图实施例对本发明作进一步详细描述。
[0031]
本实施例提供一种地址信息数据的处理方法,用来在大量的地址信息数据中找到可能出现错误或者不准确的存疑地址信息数据。具体地,参见图1所示,该实施例中的地址信息数据的处理方法,包括如下步骤:
[0032]
步骤1,将自动或半自动融合后的标准地址数据库作为初始地址数据库;其中,初始地址数据库为地址信息按照预设地址层级标准化及空间化处理后的地址数据库,初始地址数据库内的每条地址信息均含有一个地址文本信息以及一个与该地址文本信息相对应的空间化地址位置点;
[0033]
空间化地址位置点也称之为地址点,初始地址数据库内的地址文本信息为初始地址文本信息;此处的预设地址层级标准化为含有预设行政区域地址文字和详细地址文字的地址文本信息,预设行政区域地址文字为省级、市级、区县级和乡镇街道级行政区域地址词条;
[0034]
例如,针对某城市内部,其初始地址数据库中的大量的初始地址信息,假设初始地址信息的总数量标记为n,且按照预设地址层级标准化及空间化处理后,初始地址文本信息
示例如下:
[0035]
初始地址文本信息1:x省y市s1区w1街道u1路p1号;
[0036]
初始地址文本信息2:x省y市s1区w2街道u2路p2号;
[0037]
初始地址文本信息3:x省y市s2区w3街道u3路p3号;
[0038]
初始地址文本信息4:x省y市s3区w4街道u2路p4号;
[0039]
以此类推;
[0040]
初始地址文本信息n-1:x省y市s3区w4街道u3路p
i
号;i>0,且i∈z,z为正数;
[0041]
初始地址文本信息n:x省y市s1区w1街道u1路p
j
号;j>0,且i∈z,z为正数;
[0042]
步骤2,将初始地址数据库中的所有地址文本信息均按照预设地址层级模型剔除冗余的行政区域地址文字,以得到多个简化地址文本信息,并由所有简化地址文本信息以及对应的空间化地址位置点一起形成简化地址信息数据库;其中,简化地址信息数据库内的任一条地址信息均含有一个简化地址文本信息以及与该简化地址文本信息相对应的空间化地址位置点;冗余的地址文字为全部或部分行政区域词条。
[0043]
在实际的应用场景中,例如,针对某城市内部,信息冗余的行政区域文字为省级、市级行政区域地址词条。简化处理是将初始地址文本信息前方的省和市行政区域剔除掉,简化处理后的地址信息为形成简化地址信息数据库的简化地址文本信息;那么,所得到的简化地址文本信息示例如下:
[0044]
简化地址文本信息1:s1区w1街道u1路p1号;
[0045]
简化地址文本信息2:s1区w2街道u2路p2号;
[0046]
简化地址文本信息3:s2区w3街道u3路p3号;
[0047]
简化地址文本信息4:s3区w4街道u2路p4号;
[0048]
以此类推;
[0049]
简化地址文本信息n-1:s3区w4街道u3路p
i
号;
[0050]
简化地址文本信息n:s1区w1街道u1路p
j
号;
[0051]
步骤3,对简化地址信息数据库内的所有简化地址文本信息做文本聚类处理,得到多个地址组团;其中,在该实施例中,每一个地址组团内至少具有两个简化地址信息,每一个简化地址信息对应着一个简化地址文本和一个空间化地址位置点;
[0052]
需要说明的是,针对所得到的上述简化地址信息数据库,可以根据需求选用文本聚类方法,实例中采用k-means算法,将所得到的这n个简化地址文本信息做文本聚类分组,从而得到了m个地址组团。例如,这m个地址组团分别是地址组团c1、地址组团c2、地址组团c3、
…
、地址组团c
m-1
和地址组团c
m
;
[0053]
并且再假设,经聚类处理后,地址组团c1内的简化地址信息数据是简化地址文本1、简化地址文本2、简化地址文本3、简化地址文本4、简化地址文本5和简化地址文本6,地址组团c2内的简化地址信息数据是简化地址文本8、简化地址文本9和简化地址文本10,地址组团c
m
内的简化地址信息数据是简化地址文本n-3、简化地址文本n-2、简化地址文本n-1、简化地址文本n,其他地址组团内的简化地址信息数据也类似;
[0054]
其中,在地址组团c1内,该地址组团c1内初始地址信息所对应的地址点分别是地址点1、地址点2、地址点3、地址点4、地址点5和地址点6;
[0055]
在地址组团c2内,该地址组团c2内简化地址信息数据所对应的地址点是地址点8、
地址点9和地址点10;
[0056]
在地址组团c
m
内,该地址组团c
m
内简化地址信息数据所对应的地址点分别是地址点n-3、地址点n-2、地址点n-1和地址点n;
[0057]
步骤4,对各地址组团内每一个简化地址文本信息所对应的地址信息分别赋予初始置信度,并将赋予了初始置信度的地址信息含有的空间化地址位置点标记为初始正常地址点;其中,针对任一个地址组团,初始置信度的数值为该地址组团内所有地址信息的总数量;
[0058]
例如,在实例中地址组团c1共有6个地址信息,分别是地址信息1、地址信息2、地址信息3、地址信息4、地址信息5和地址信息6,则地址信息1、地址信息2、地址信息3、地址信息4、地址信息5和地址信息6的初始置信度是6。同理,可得其他组团各地址信息的初始置信度值。
[0059]
步骤5,计算每一个地址组团内所有的任意两个简化地址文本信息所对应的空间化地址位置点之间的空间直线距离,并得到各地址组团内每一个空间化地址位置点所对应的最短空间直线距离;
[0060]
例如,针对地址组团c1,地址点1与c1组团内其他地址点的空间直线距离分别为l
12
、l
13
、l
14
、l
15
和l
16
,求解地址点1的最短距离l
1min
:
[0061]
l
1min
=min(l
12
,l
13
,l
14
,l
15
,l
16
)。
[0062]
同理,分别得到地址组团c1内其他地址点的最短空间直线距离分别为l
2min
、l
3min
、l
4min
、l
5min
和l
6min
。
[0063]
同样地,再分别计算得到地址组团c2至地址组团c
n
内各地址点的最短空间直线距离;
[0064]
步骤6,根据每一个空间化地址位置点所对应的最短空间直线距离做出存疑地址点判断标记:
[0065]
当任一个空间化地址位置点所对应的最短空间直线距离大于预设空间直线距离阈值时,将该空间化地址位置点标记为存疑地址点(或称为存疑点),转入步骤7;否则,不予处理该空间化地址位置点;
[0066]
在该实施例中,预设空间直线距离阈值l
g
为150m,当任一个空间化地址位置点i所对应的最短空间直线距离l
imin
大于预设空间直线距离阈值l
g
时,说明该空间化地址位置点距离同一组团内的所有空间化地址位置点的距离都较远,该空间化地址位置点错误或地址编码中出错的概率较大,标记为存疑地址点。
[0067]
针对地址组团c1,如果经过比较判断,地址点1所对应的两个最短空间直线距离中的最短空间直线距离l
1min
大于预设空间直线距离阈值150m,那么,就将该地址点1标记为存疑地址点,然后转入步骤7;当然,如果l
1min
小于预设空间直线距离阈值150m,则不处理地址点1;同理,按照同样的方式来判断标记c1组团内剩余地址点及其他地址组团内各地址点。
[0068]
作为改进的,在实际的地址信息数据处理操作中,此处的预设空间距离阈值设置规则可进一步设置为:含有地址文本分词含有道路名称时,预设空间距离阈值l
g
设置为100m;含有小区名称时,预设空间距离阈值l
g
设置为80m,其余不含上述字样(既不含地址文本分词,又不含道路名称的情况)时,预设空间距离阈值l
g
设置为150m。
[0069]
步骤7,求解与该存疑地址点最临近的k个空间化地址位置点,并根据求解结果做
出判断处理:
[0070]
当所得k个空间化地址位置点中存在有该存疑地址点所处地址组团内的空间化地址位置点时,将该存疑地址点标记为正常地址点,转入步骤8;否则,将该存疑地址点所对应地址信息的置信度值设置为-1;
[0071]
其中,k的数值可以根据需要进行调整设置,此处k的数值为2或3,比如假设为k=3;
[0072]
在该实施例中,假设组团c1中地址点5被标记为存疑地址点,此处以被标记为存疑地址点的地址点5来进行说明:
[0073]
通过常规邻近算法计算出与地址点5最临近的3个空间化地址位置点,假设这3个空间化地址位置点分别是地址点q1、地址点q2和地址点q3;
[0074]
一旦判断这三个地址点(地址点q1、地址点q2和地址点q3)中的任一个地址点是地址组团c1内的地址点时,那么就将该地址点5标记为正常地址点,转入步骤8;若这三个地址点(地址点q1、地址点q2和地址点q3)中不存在位于地址组团c1内的地址点时,就将该存疑地址点(即地址点5)所对应地址信息5的置信度值做调整处理,将地址点5所对应地址信息5的置信度值标记为-1;
[0075]
需要说明的是,该步骤7处通过求解该存疑点最临近的k个空间化地址位置点,可以避免将一些偏远地区的飞点类型的地址错判为存疑点,从而降低了存疑点的误判概率,提高了后续的地址点是否为存疑点的判断准确性;
[0076]
步骤8,获取各地址组团的质心点,并将各质心点分别沿横坐标和纵坐标移动预设距离d,且以移动预设距离d后的质心点作为对应组团的辅助点;
[0077]
其中,该实施例中的预设距离d的取值位于区间(0.1m,1m)以内;其中,通过如此设置该预设距离d的取值区间,可以避免经聚类处理后得到的地址组团内只有一个地址点,或者因地址组团内的地址点呈直线分布而导致无法得到最小面积外接矩形的情况发生;
[0078]
具体到该步骤8,针对m个地址组团中的地址组团c1,通过常规技术手段获取到该地址组团c1的质心点,假设地址组团c1的质心点标记为o1(x
o
,y
o
),然后再把质心点o1的横坐标x
o
和纵坐标y
o
分别移动预设距离0.5m,从而得到一个对应原来质心点o1的质心点o1’
(x
o’,y
o’);可以知道,x
o’=x
o
+0.5,y
o’=y
o
+0.5;然后,再将该质心点o1’
作为对应地址组团c1的辅助点;同理,可以得到其他各地址组团的质心点以及对应的辅助点,此处不再赘述;
[0079]
步骤9,将各组团内所有空间化地址位置点、组团质心点和组团辅助点作为各组团点集合,获取各组团点集合的外接矩形,将各外接矩形作为对应地址组团的组团外接矩形;其中,位于组团外接矩形范围内的非该组团的空间化地址位置点为对应地址组团的组团外地址点;
[0080]
具体地,以上述的m个地址组团为例,针对地址组团c1,以该地址组团c1内所有的地址点(即地址点1、地址点2、地址点3、地址点4、地址点5和地址点6)以及该地址组团c1的质心点o1、该地址组团c1的辅助点o1’
作为地址组团c1的点集合,该点集合所处空间位置所形成的外接矩形作为该地址组团c1的组团外接矩形;同理,可以得到其他各地址组团所对应的组团外接矩形;
[0081]
步骤10,对各地址组团外接矩形范围内的组团外地址点做出判断处理:
[0082]
当任一地址组团的组团外地址点所对应地址信息的置信度数值小于预设置信度
阈值时,标记该组团外地址点为存疑地址点,并将该存疑地址点所对应地址信息的置信度设置为-1;否则,不予处理该组团外地址点。
[0083]
在该实施例中,假设预设置信度阈值标记为g,预设置信度阈值g的数值可以根据需要进行调整设置。例如,可以将预设置信度阈值g的数值设置为10。
[0084]
针对上述m个地址组团,假设地址组团c1的组团外地址点t所对应地址信息t的置信度数值小于预设置信度阈值10时,判定组团外地址点t为存疑点且标记组团外地址点t为存疑地址点,并将该存疑地址点t所对应地址信息t的置信度设置为-1;否则,不予处理该组团外地址点t。
[0085]
为了进一步降低错误地址的漏查率,在步骤10之后,该实施例还会设置针对所有空间化地址位置点所对应地址信息置信度数值的核验阈值r;以及将置信度数值小于核验阈值r的地址信息对应的空间化地址位置点标记为奇异点,并进行奇异点人工核验操作。其中,在针对奇异点人工核验操作过程中,优先遍历存疑地址点的人工检核,而后再进行奇异点的人工核验操作。
[0086]
尽管以上详细地描述了本发明的优选实施例,但是应该清楚地理解,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1