结合集成学习与加权极限学习机的煤矿瓦斯浓度预测方法与流程
1.本发明涉及一种煤矿瓦斯浓度预测方法,属于瓦斯浓度预测技术领域。
背景技术:
2.煤矿瓦斯防护属于高危行业,极易造成群死群伤。据统计,我国瓦斯爆炸事故占重大事故次数60以上,瓦斯事故防治是煤矿安全工作重中之重。随着人工智能技术的发展,瓦斯浓度的智能预测成为防范瓦斯爆炸事故的主要手段。目前,瓦斯浓度预测方法主要包括1)时间序列方式预测,如指数平滑和曲线拟合等,这种方法参数较多、预测精度低,模型更新难。2)采用bp神经网络等技术进行预测,此类方法训练时间长,动态调整较为复杂。上述方法只考虑单一分类器的情况,单一分类器间存在一定的差异性,这会导致分类可能存在错误。那么若将多个若分类器合并后,就可以减少整体预测的错误率,实现更好的瓦斯安全监测。
技术实现要素:
3.发明目的:为了克服现有技术中存在的不足,本发明提供一种结合集成学习与加权极限学习机的煤矿瓦斯浓度预测方法,可以对未来3小时的瓦斯浓度及其走势进行相对准确的预测,可提升煤矿安全生产的智能化水平。
4.技术方案:为实现上述目的,本发明采用的技术方案为:
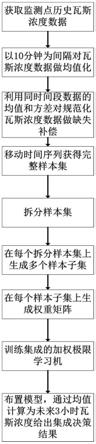
5.一种结合集成学习与加权极限学习机的煤矿瓦斯浓度预测方法,包括以下步骤:
6.步骤1,针对矿井下某个监测点,获取其历史瓦斯浓度监测数据。
7.步骤2,数据预处理与缺失数据填充:对于一个监测点每间隔10分钟计算一次瓦斯浓度均值,得到规整的瓦斯浓度监测数据,提取同一时间段非缺失瓦斯浓度数据,计算得到均值与方差,并利用计算得到的均值与方差对所有缺失值进行填充,得到规整的瓦斯浓度监测时间序列。
8.步骤3,样本集生成:取连续24小时的瓦斯浓度数据作为特征x,其后3小时的瓦斯浓度数据作为预测目标y,并按照单点顺序移动的方式逐一生成训练样本,若在规泛化的瓦斯浓度监测数据时间序列中遇到断点,则新样本的提取在断点后重新开始,得到样本集φ。
9.步骤4,样本集拆分:对样本集φ中预测目标y进行拆分,使预测目标y中的每一列数据均与x结合,构成t个拆分子集,分别记为φ1,φ2,...,φ
i1
,...,φ
t
。
[0010][0011]
其中,φ
i1
表示第i1个拆分子集,y
i1j1
表示第i1个样本在第j1个时间点的预测输出。
[0012]
步骤5,训练子集生成:利用bootstrap方法在每个拆分子集上分别生成kt个训练
子集φ
ij
, i∈{1,2,..,t}为拆分子集号,j∈{1,2,..,kt}为采样子集号,共生成t
×
kt个样本子集。
[0013]
步骤6,模型训练:在每个训练子集上以预测目标值越大,赋予的权重越小为原则训练加权极限学习机模型,进一步提取每个拆分子集上kt个模型的预测结果,采用计算kt个模型预测结果均值的方式得出最终的集成预测结果,按照时间顺序排列拆分子集顺序,形成对未来3小时的瓦斯浓度预测结果。
[0014]
步骤61,对于每一个训练子集φ
ij
,为其中每一个预测输出值y
ij
‑
m
,分配对应的权重:
[0015]
w
ij
‑
m
=(y
ij
‑
m
)
‑
norm
[0016]
其中,w
ij
‑
m
表示第j个样本在第i决策输出上的权重,即w
ij
‑
m
为y
ij
‑
m
对应的权重,norm 表示范数。
[0017]
步骤62,对于任一训练子集φ
ij
,令表示其目标输出矩阵,其中s为训练子集中样本的数量。
[0018]
步骤63,设定极限学习机中的隐层节点个数l与惩罚因子c,随机生成输入层到隐层之间的权重与偏置序列,a=[a1,a2,...,a
i2
,...,a
l
]和b=[b1,b2,...,b
i2
,...,b
l
],其中,a
i2
∈[
‑
1,1],b
i2
∈[
‑
1,1],利用sigmoid激活函数将任一训练子集φ
ij
转化为隐层输出矩阵:
[0019][0020]
其中,h(a1,...,a
l
,b1,...,b
l
,x1,...,x
s
)表示,h(x
j2
)表示第j2个样本在隐层矩阵的变换, j2∈[
‑
1,s],g为sigmoid激活函数,其计算方式如下:
[0021][0022]
其中,g(a
i2
,b
i2
,x
j2
)表示。
[0023]
最优参数取值组合采用加权的均方误差最小化原则确定,即:
[0024][0025]
其中,wrmse表示加权的均方误差,w
ij
表示第j个样本在第i决策输出上的权重。哪一个l与c的取值组合具有最小的wrmse,则将对应值最为最优参数分别分配给l和c。
[0026]
利用步骤s61提取的权重生成对应的加权矩阵w
ij
:
[0027]
w
ij
=diag(w
ij
‑1,w
ij
‑2,
…
,w
ij
‑
s
)
[0028]
求解下式:
[0029][0030]
subject to:h(x
k
)β=t
k
‑
ξ
k
,k=1,2,...,s
[0031]
其中,welm
ij
表示,h(x
k
)表示,c表示,ξ
k
表示第k个样本的训练误差,t
k
表示,s 表示,β表示连接隐层与输出层间的权重矩阵。
[0032]
根据karush
–
kuhn
–
tucker(kkt)理论,β可求解如下:
[0033][0034]
其中,h表示,h
t
表示矩阵h的转置,w表示,t表示,l表示,通过上述过程,可逐一训练各拆分子集模型。
[0035]
步骤64,集成决策:对于任一拆分子集ф
i
中的每一个样本,分别将其置于k个对应的已训练好的模型中,得到对应的预测值y'
ij
‑1,y'
ij
‑
2,...,y'
ij
‑
k
,i∈{1,2,...,18},j∈{1,2,...,n},通过均方根值计算得到集成预测值y'
ij
:
[0036][0037]
步骤7,数据预测:实时接收最新的瓦斯浓度数据,导入到训练好的模型中,形成对未来3小时的瓦斯浓度趋势预测。
[0038]
实时获取过去24小时的瓦斯浓度监测数据,做规范化处理后,记为x',通过保存的18
ꢀ×
k个模型中的输入层权重和偏置a和b,分别将x'转化为18
×
k个h',结合保存的18
×ꢀ
k个隐层权重矩阵β,通过计算各个h'
×
β并利用集成决策原则,逐一得到对应的未来三小时各时间段预测结果,并按照时间顺序拼接为y'。
[0039]
优选的:步骤1中对于一个监测点,至少应包括30天的历史瓦斯浓度监测数据。
[0040]
优选的:所述步骤2中得到规整的瓦斯浓度监测时间序列方法,包括以下步骤:
[0041]
步骤21,读取历史瓦斯浓度监测数据,从第一个数据开始,提取10分钟内的所有数据,并做均值计算,生成规整监测瓦斯浓度数据x1,以此类推,每10分钟进行一次计算,最终得到规整的瓦斯浓度监测时间序列数据x1,x2,...,x
m
,其中,m为规整监测数据的总数。
[0042]
步骤22,若瓦斯浓度监测时间序列数据x1,x2,...,x
m
中存在缺失数据,假设x
t1
缺失,则提取与x
t1
监测日期不同而时间段相同的数据,并计算其均值μ与均方差σ,通过下式对x
t1
进行填充:
[0043]
x
t1
=μ+3ησ
[0044]
其中,x
t1
表示,η为[
‑
1,1]之间的随机数,且保证p(x
t1
)=p(3σ)>99%,p(x
t1
)表示,p(3σ) 表示。
[0045]
优选的:所述步骤s3中得到样本集φ的方法:针对规整的瓦斯浓度监测数据时间序列 x1,x2,...,x
m
,首先从起始位置取连续24小时的瓦斯浓度数据作为特征x1=[x1,
x2,...,x
144
],其后3小时的瓦斯浓度数据作为对应的预测目标y1=[x
145
,x
146
,...,x
162
],生成第一个样本,然后通过单点移动的方式生成第二个样本,即x2=[x2,x3,...,x
145
],y2=[x
146
,x
147
,...,x
163
],以此类推,不断生成样本,直至数据序列耗尽,得到样本集φ:
[0046][0047]
其中,n表示生成的样本个数。
[0048]
优选的:所述步骤s5采用bootstrap方法对每一个拆分子集进行k次采样,每次采集原始n个样本的60%,得到多个不同的样本训练子集φ
ij
。
[0049]
优选的:范数norm取值的范围在(0,1)之间的数。
[0050]
优选的:范数norm取2/3。
[0051]
优选的:步骤63中隐层节点数l及惩罚因子c通过格搜索方法在整体数据集上确定, l∈{20,40,...,180,200},c∈{10
‑2,10
‑1,...,106}。
[0052]
优选的:所述步骤s7中训练好的模型要求在使用时实时读取同一监测点最新24小时的瓦斯浓度监测数据。
[0053]
本发明相比现有技术,具有以下有益效果:
[0054]
1.本发明结合了集成学习与加权极限学习机,实现了对未来一段时间的瓦斯浓度趋势预测,实现简单,时间复杂度低,准确度高,泛化能力强。
附图说明
[0055]
图1是本发明的流程图。
[0056]
图2是本发明实施例的流程图
[0057]
图3是本发明方法上线运行的流程图。
具体实施方式
[0058]
下面结合附图和具体实施例,进一步阐明本发明,应理解这些实例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
[0059]
一种结合集成学习与加权极限学习机的煤矿瓦斯浓度预测方法,如图1
‑
3所示,包括以下步骤:
[0060]
a、提取传感器采集的某煤矿监测点瓦斯浓度监测历史数据,按10分钟等间隔计算均值,得到规范化的瓦斯浓度监测数据,并分析监测数据是否存在缺失,如果存在缺失数据则进入步骤b。
[0061]
b、提取同一时间段非缺失瓦斯浓度数据,计算得到均值与方差,并利用上述两个参数值对所有缺失值进行填充,得到规整的瓦斯浓度监测时间序列,然后进入步骤c。
[0062]
c、从规范化数据时间序列头开始取连续24小时的瓦斯浓度数据作为特征x,其后3小时的瓦斯浓度数据作为预测目标y,并按照单点顺序移动逐一生成训练样本,若在规泛化的瓦斯浓度监测数据时间序列中遇到断点,则新样本的提取在断点后重新开始,最终得到
样本集φ:
[0063][0064]
其中,n表示生成的样本个数。
[0065]
d、将ф拆分为18个子集φ1,φ2,...,φ
18
,其中:
[0066][0067]
其中,φ
i1
表示第i1个拆分子集,y
i1j1
表示第i1个样本在第j1个时间点的预测输出。
[0068]
e、采用bootstrap对每一个拆分子集进行k次采样,每次采样原始n个样本的60%,得到多个不同的训练子集φ
ij
,其中:i∈{1,2,..,18}为拆分子集号,j∈{1,2,..,k}为采样子集号,共生成18
×
k个样本子集。
[0069]
f、对于每一个训练子集φ
ij
,为其中每一个预测输出值y
ij
‑
m
,分配对应的权重,计算公式如下:
[0070][0071]
其中,w
ij
‑
m
为y
ij
‑
m
对应的权重。
[0072]
g、对于任一训练子集φ
ij
,令表示其目标输出矩阵,其中s为样本子集中样本的数量。
[0073]
h、设定极限学习机中的隐层节点个数l与惩罚因子c,随机生成输入层到隐层之间的权重与偏置序列,a=[a1,a2,...,a
i2
,...,a
l
]和b=[b1,b2,...,b
i2
,...,b
l
],其中,a
i2
∈[
‑
1,1],b
i2
∈[
‑
1,1],利用sigmoid激活函数将任一训练子集φ
ij
转化为隐层输出矩阵:
[0074][0075]
其中,h(a1,...,a
l
,b1,...,b
l
,x1,...,x
s
)表示,h(x
j2
)表示第j2个样本在隐层矩阵的变换,j2∈[
‑
1,s],g为sigmoid激活函数,其计算方式如下:
[0076][0077]
其中,g(a
i2
,b
i2
,x
j2
)表示。
[0078]
利用步骤f提取的权重向量生成对应的加权矩阵w
ij
:
[0079][0080]
进一步,求解下式:
[0081][0082]
其中,welm
ij
表示,h(x
k
)表示,c表示,ξ
k
表示第k个样本的训练误差,t
k
表示,s 表示,β表示连接隐层与输出层间的权重矩阵。
[0083]
根据karush
–
kuhn
–
tucker(kkt)理论,β可求解如下:
[0084][0085]
其中,h表示,h
t
表示矩阵h的转置,w表示,t表示,l表示,。通过上述过程,可逐一训练各子模型。
[0086]
i、对于任一样本集ф
i
中的每一个样本,分别将其置于k个对应的已训练好的模型中,得到对应的预测值y'
ij
‑1,y'
ij
‑2,...,y'
ij
‑
k
,i∈{1,2,...,18},j∈{1,2,...,n},进一步通过均值计算得到集成预测值y'
ij
:
[0087][0088]
j、实时获取过去24小时的瓦斯浓度监测数据,做规范化处理后,记为x',通过保存的18
×
k个模型中的输入层权重和偏置a和b,分别将x'转化为18
×
k个h',结合保存的 18
×
k个隐层权重矩阵β,通过计算各个h'
×
β并利用集成决策(公式(9))原则,逐一得到对应的未来三小时各时间段预测结果,并按照时间顺序拼接为y'。
[0089]
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1