一种基于改进BERT的文本蕴含关系识别方法与流程
一种基于改进bert的文本蕴含关系识别方法
技术领域
[0001]
本发明涉及自然语言处理技术领域,具体为一种基于改进bert的文本蕴含关系识别方法。
背景技术:
[0002]
文本蕴含关系识别是指识别两段文本之间的蕴含关系,即在给定前提文本p和假设文本h的情况下,若可以通过文本p的内容识别出文本h的内容是正确的,那么可以说前提文本p蕴含假设h,文本蕴含关系识别长期以来作为自然语言处理中的一项重要子任务,在问答系统、信息检索、信息抽取、阅读理解和文本推断等诸多领域都有着重要的应用。
[0003]
传统的文本蕴含关系识别方法主要包括基于词语相似度的无监督方法、基于特征抽取的分类方法和基于逻辑推断的方法等,由于这些方法往往需要依赖人工抽取的特征、人工设计的规则以及词性标注、句法分析等预处理工具,近年来,随着深度学习的快速发展,采用深层神经网络进行文本蕴含关系识别研究成为了主流,并在snli和cbt等多个文本蕴含关系识别语料上取得一系列新的最好效果,特别是近两年在bert的推动,基于预训练语言模型及预训练+微调的两阶段方法在多个自然语言处理任务上取得了突出的效果,许多相关工作证明了利用大规模无标注文本语料学习通用语言表示,并根据具体任务进行微调的两阶段方式是可行的,作为预训练语言模型的主要代表,bert采用多层transformer结构及自注意力机制,在海量的通用无标注文本基础上结合mlm和nsp(next sentence prediction)目标训练学习文本的语法和语义信息,但由于预训练的bert模型是基于一般的互联网文本训练所得,而且nsp(next sentence prediction)的目的是学习句子之间的相邻关系,而非前后顺序,这使得预训练bert模型一方面往往缺乏任务相关的领域知识,另一方面难以进一步刻画细粒度的文本蕴含关系,为此,我们提出一种基于改进bert的文本蕴含关系识别方法。
技术实现要素:
[0004]
本发明的目的在于提供一种基于改进bert的文本蕴含关系识别方法,首先针对bert中的nsp训练目标只学习文本句子之间的相邻关系,不适合刻画细粒度文本蕴含关系问题,提出改进后的bert模型ter-bert,ter-bert中采用新的针对文本蕴含关系预测训练目标(textual entailment relation,ter)及相应的损失函数代替传统的nsp,目的是使得多层transformer能够更好地学习文本之间的蕴含关系;接着,通过利用目标任务集中已标注的训练数据及验证数据构造无监督的待训练语料,给出相应的构造策略,并在公开预训练语言模型bert(bert-base或bert-large)的基础上,采用ter-bert模型进行再次预训练,目的是进一步增强任务相关的知识,最后,将经过任务相关数据预训练的ter-bert应用于相应的文本蕴含关系识别任务中,并通过微调的方式进一步学习任务相关知识,实验结果证明基于改进ter-bert及相应的预训练+任务相关预训练+微调的三阶段方法能够进一步提高bert模型在多个文本蕴含关系识别任务上的性能,并明显优于经典的bert模型。
[0005]
为实现上述目的,本发明提供如下技术方案:一种基于改进bert的文本蕴含关系识别方法,识别方法的具体步骤为:步骤一:提出针对文本蕴含关系识别的新训练目标(textual entailment relation,ter),将原来bert中基于nsp的句子间二元相邻关系的判断更改为基于ter的文本间三元关系的判断,即在ter训练目标中,模型区分两个句子之间的蕴含关系、冲突关系及中立关系,同时,对于ter训练目标利用三元交叉熵作为损失函数定义;最后,将整个bert模型的损失值定义为mlm和ter损失值的和;步骤二:根据目标任务语料集中已标注的训练数据和验证数据,通过以下策略构造相应的无标注任务相关训练语料,具体来说,若已标注数据中两个文本a和b之间为的蕴含关系(即a=>b),则在待训练语料中该文本为相邻关系;同时按50%的概率对调两个句子的先后顺序,且视对调后的句子对为非蕴含关系,即在待训练语料中为非相邻关系,记为a[sep]b;对于中立或冲突的文本对均视为非相邻关系,通过[sep]进行相隔,同时按50%的概率对调其先后顺序,为了使模型能够从标注为文本蕴含关系的句子对中学习其先后顺序关系,将待训练语料中所有相邻关系的文本均直接构造为句子对,即不采用50%的概率进行选择;步骤三:为了同时充分利用预训练语言模型bert在大规模通用文本上所学习到的语法和语义知识,在公开预训练语言模型bert-base(即不区分大小写、采用12层transformer和764维向量)的基础上,利用步骤一和二中构造的训练目标mlm+ter及任务相关语料对bert进行训练,目的是让模型进一步学习文本间的蕴含关系,增强任务相关的领域知识,并得到包含任务相关知识的预训练语言模型ter-bert;步骤四:对于待判断的两个句子,构造句子对作为步骤3中ter-bert的输入,并将ter-bert中最后一层的[cls]标志所对应的词向量h[cls]作为句子对的最终语义表示;步骤五:将h[cls]通过一个维度为100的全连接层和一个softmax函数进行分类和判断,同时采用多元交叉熵函数作为损失函数对模型中的待训练参数进行反向调整。
[0006]
优选的,改进bert是在原来bert及其nsp训练目标的基础上,针对细粒度文本蕴含关系提出新的训练目标ter,并将原来的nsp替换成为基于三元关系的ter训练目标和三元交叉熵函数。
[0007]
优选的,任务预训练方法是利用目标任务集中已标注的训练数据及验证数据构造无监督的待训练语料,并在公开预训练模型bert(bert-base或bert-large)的基础进行再次预训练,且句子的最大长度统一取128,学习率统一为5e-05,不区分大小写,并采用全词掩码的方式,目的是进一步增强任务相关的知识并得到相应的预训练模型ter-bert;在构造任务相关的预训练语料时,将包含蕴含关系的句子视为相邻关系;同时按50%的概率对调两个句子的先后顺序,且视对调后的句子对的标签为中立的,其目的是使得模型能够进一步学习两个句子在蕴含关系的先后顺序关系,对于中立或冲突的文本对均视为非相邻关系,通过空白行进行相隔,同时按50%的概率对调其先后顺序,且继续使用原来的标签;同时,为了使模型能够从标注为文本蕴含关系的句子对中学习其先后顺序关系,将待训练语料中所有相邻关系的文本均直接构造为标签为蕴含关系的句子对,即不采用50%的概率进行选择。
[0008]
优选的,预训练语言模型在ter-bert的基础利用目标任务集中的训练数据进行微调和验证,并直接将ter-bert最后一层中[cls]标志所对应的词向量作为句子对的最终语
义表示,最后通过一个全连接网络和一个softmax函数进行分类判断和输出。
[0009]
与现有技术相比,本发明的有益效果是:本发明设计合理,针对现有bert模型中采用的nsp无法学习细粒度文本蕴含关系问题,提出新的训练目标ter用于进一步学习文本蕴含关系中的蕴含、冲突和中立等关系,同时,为了进一步增强预训练语言模型中的任务相关知识,并有效缓解微调过程中因训练数据不足而导致模型难以得到充分训练问题,提出预训练+任务相关预训练+微调的三阶段方法,给出相应的任务相关预训练数据的构造方法;实验结果证明,该发明所提出的改进bert及相应的三阶段方法可以使得模型更好地学习文本蕴含关系任务的相关知识,在snli和cbt等多个相关语料库上都取得了优于经典bert及之前各相关方法的效果,并有效地提升了党建问答及党建新闻摘要等相关系统的性能,ter-bert中所提出的ter训练目标及三阶段方法不仅使得模型能够更好地学习文本蕴含关系,而且可以充分利用已标注的目标任务语料构造训练数据并增强模型的任务相关知识,从而提高模型在党建问答系统、党建文本识别及文本摘要等应用系统中的性能。
附图说明
[0010]
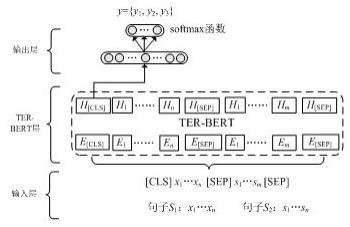
图1为本发明神经网络模型的总体架构图。
具体实施方式
[0011]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0012]
请参阅图1,本发明提供一种技术方案:一种基于改进bert的文本蕴含关系识别方法,识别方法的具体步骤为:步骤一:提出针对文本蕴含关系识别的新训练目标(textual entailment relation,ter),将原来bert中基于nsp的句子间二元相邻关系的判断更改为基于ter的文本间三元关系的判断,即在ter训练目标中,模型区分两个句子之间的蕴含关系、冲突关系及中立关系,同时,对于ter训练目标利用三元交叉熵作为损失函数定义;最后,将整个bert模型的损失值定义为mlm和ter损失值的和;步骤二:根据目标任务语料集中已标注的训练数据和验证数据,通过以下策略构造相应的无标注任务相关训练语料,具体来说,若已标注数据中两个文本a和b之间为的蕴含关系(即a=>b),则在待训练语料中该文本为相邻关系;同时按50%的概率对调两个句子的先后顺序,且视对调后的句子对为非蕴含关系,即在待训练语料中为非相邻关系,记为a[sep]b;对于中立或冲突的文本对均视为非相邻关系,通过[sep]进行相隔,同时按50%的概率对调其先后顺序,为了使模型能够从标注为文本蕴含关系的句子对中学习其先后顺序关系,将待训练语料中所有相邻关系的文本均直接构造为句子对,即不采用50%的概率进行选择;步骤三:为了同时充分利用预训练语言模型bert在大规模通用文本上所学习到的语法和语义知识,在公开预训练语言模型bert-base(即不区分大小写、采用12层transformer和764维向量)的基础上,利用步骤一和二中构造的训练目标mlm+ter及任务相关语料对bert
进行训练,目的是让模型进一步学习文本间的蕴含关系,增强任务相关的领域知识,并得到包含任务相关知识的预训练语言模型ter-bert;步骤四:对于待判断的两个句子,构造句子对作为步骤3中ter-bert的输入,并将ter-bert中最后一层的[cls]标志所对应的词向量h[cls]作为句子对的最终语义表示;步骤五:将h[cls]通过一个维度为100的全连接层和一个softmax函数进行分类和判断,同时采用多元交叉熵函数作为损失函数对模型中的待训练参数进行反向调整。
[0013]
改进bert是在原来bert及其nsp训练目标的基础上,针对细粒度文本蕴含关系提出新的训练目标ter,并将原来的nsp替换成为基于三元关系的ter训练目标和三元交叉熵函数;任务预训练方法是利用目标任务集中已标注的训练数据及验证数据构造无监督的待训练语料,并在公开预训练模型bert(bert-base或bert-large)的基础进行再次预训练,且句子的最大长度统一取128,学习率统一为5e-05,不区分大小写,并采用全词掩码的方式,目的是进一步增强任务相关的知识并得到相应的预训练模型ter-bert;在构造任务相关的预训练语料时,将包含蕴含关系的句子视为相邻关系;同时按50%的概率对调两个句子的先后顺序,且视对调后的句子对的标签为中立的,其目的是使得模型能够进一步学习两个句子在蕴含关系的先后顺序关系,对于中立或冲突的文本对均视为非相邻关系,通过空白行进行相隔,同时按50%的概率对调其先后顺序,且继续使用原来的标签;同时,为了使模型能够从标注为文本蕴含关系的句子对中学习其先后顺序关系,将待训练语料中所有相邻关系的文本均直接构造为标签为蕴含关系的句子对,即不采用50%的概率进行选择;预训练语言模型在ter-bert的基础利用目标任务集中的训练数据进行微调和验证,并直接将ter-bert最后一层中[cls]标志所对应的词向量作为句子对的最终语义表示,最后通过一个全连接网络和一个softmax函数进行分类判断和输出;上面所述基于改进bert的文本蕴含关系识别方法中的文本蕴含关系识别模型是在一个多层神经网络中完成的,多层神经网络的架构图如图1所示,其中各单元词向量的输出维度为768维,模型训练过程中采用多元交叉熵定义损失函数,并结合了adam优化器,其学习率统一为2e-05,句子长度取128,并采用全词掩码的方式,为避免过拟合,采用基于dropout的正则化策略,值统一设置为0.1。
[0014]
以上所述,仅为本发明专利较佳的实施例,但本发明专利的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明专利所公开的范围内,根据本发明专利的技术方案及其发明专利构思加以等同替换或改变,都属于本发明专利的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1