一种基于深度学习的实木地板分类方法与流程
[0001]
本发明涉及木质地板分类,具体涉及一种基于深度学习的实木地板分类方法。
背景技术:
[0002]
随着国家经济的日益发展,越来越多人们在家装选择了木质地板,导致我国木质加工行业的实木地板数量的需求日益增长,在对原木进行加工制作后生产出来的实木地板进行快速准确的分类打包,成为了一个迫切需要解决的问题。在当下工业中,较多的实木地板分类方法仍然采用人工视觉进行纹理及颜色判断,然后进行手动分类,此方法较为落后,且效率较低,存在的不足之处主要有以下四种:(1)人工进行分类时,技工工作时间较长时,容易产生视觉疲劳,从而导致分类错误率增长;(2)对于大的纹理较为相似,但是在细小纹理存在差异的实木地板中,人工视觉会较难区分细小纹理特征的不同点,导致分类错误;(3)地板分类时由于不同工人视觉存在差异,对颜色的理解不同,导致分类的结果出现错误;(4)人工分类耗时较长且效率较低。
[0003]
在之前有学者有对地板的分类做一定的研究,如戴天虹等人通过实木地板的主要颜色特征,利用bp神经网络中的径向基神经网络(rbf)、k邻近算法(k-means)对实木地板种类进行分类处理;白瑞林等人提出基于颜色特征的地板层次分类方法;王克奇等人使用色彩与空间对木材的颜色进行测量从而达到分类的目的。
技术实现要素:
[0004]
针对现有技术中的缺陷,本发明的目的是提供一种基于深度学习的实木地板分类方法。本发明的技术方案如下:
[0005]
一种基于深度学习的实木地板分类方法,包括以下步骤:
[0006]
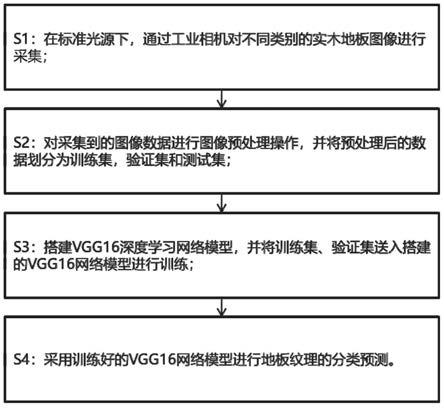
s1:在标准光源下,通过工业相机对不同类别的实木地板图像进行采集;
[0007]
s2:对采集到的图像数据进行图像预处理操作,并将预处理后的数据划分为训练集,验证集和测试集;
[0008]
s3:搭建vgg16深度学习网络模型,并将训练集、验证集送入搭建的vgg16网络模型进行训练;
[0009]
s4:采用训练好的vgg16网络模型进行地板纹理的分类预测。
[0010]
可选地,所述步骤s2进一步包括:
[0011]
s22:使用伽马矫正算法消除光照对图像的影响;
[0012]
s23:将伽马矫正后的图像使用大津算法进行粗纹理提取;
[0013]
s24:使用中值滤波算法对粗纹理提取后的图像进行图像噪点去除;
[0014]
s25:使用局部二值模式算法对滤波后的图像进行局部特征纹理增强,去除细小纹理;
[0015]
s26:使用自适应阈值大津算法,遍历地板图像并计算其像素值的加权平均值,此值将作为一个粗细纹理分隔值,使用阈值分割法将大于该分隔值的像素点增强加粗,反之
小于此分割值的像素则淡化;
[0016]
s27:使用opecv库中resize函数,将图片尺寸调整至模型预设的输入要求的大小;
[0017]
s28:将图像归一化后存储,待所有样本图像处理完成后,按照数据集划分标准,随机选择90%的数据作为训练集,剩下的10%的数据集作为最终评估模型的测试集,然后在训练集中随机选择原数据10%数量的数据作为训练时验证集。
[0018]
可选地,在步骤s22之前,还包括:
[0019]
s21:将采集到的实木地板图像通过重命名算法进行重新命名并进行类别标注。
[0020]
可选地,所述步骤s25进一步包括:
[0021]
以距离待测图像左上角32像素的点作为中心点;以中心点为圆心,32像素为半径的圆作为比较范围;获取中心点与比较范围内所有像素点的像素值的绝对值的差值,选取其差值最大的8个像素点作为比较点;将比较点的像素与中心点像素进行比较,若中心点像素大于比较点像素,则比较点像素标记为0,反之则标记为1。
[0022]
可选地,所述步骤s3中,在vgg16模型网络训练时,提供使用迁移学习进行训练和从头开始训练分类模型的权重参数两种选择。
[0023]
与现有技术相比,本发明具有如下的有益效果:
[0024]
本发明通过工业相机进行实木地板的图像采集,然后进行图像预处理操作之后,将图像送入预训练好的深度学习模型当中,实现快速且准确的对不同种类实木地板分类的目的,这种基于深度学习的分类方法有着高效、准确的特点。
[0025]
本发明克服了人工分类时效率较低和耗时长问题,进一步提高了木质地板分类的效率与准确性。
[0026]
为了提高实木地板在经过工业加工后,提高对未知类别实木地板样本分类的准确性并将其归类,本发明开发出了一种基于深度学习中卷积神经网络模型对不同纹理木质地板类种的分类模型。此次设计在图像预处理中在增强地板纹理中有着较为突出的表现,处理后的地板图像为后续的卷积神经网络模型训练的时间节省了很多时间;在木质地板纹理分类算法上其代码量少、预测速度快、准确率高、稳定性强,能够很好的提高木质地板分类的效率和准确率,并且大大降低了生产成本。
附图说明
[0027]
通过阅读参照以下附图对非限制性实施例所作的详细描述,本发明的其它特征、目的和优点将会变得更明显:
[0028]
图1为本发明具体实施例一种基于深度学习的实木地板分类方法的流程图;
[0029]
图2为本发明具体实施例模型训练时验证集与训练集上的精确度与损失值;
[0030]
图3为本发明具体实施例第一类实木地板预处理过程可视化图;
[0031]
图4为本发明具体实施例第二类实木地板预处理过程可视化图;
[0032]
图5为本发明具体实施例第三类实木地板预处理过程可视化图;
[0033]
图6为本发明具体实施例第四类实木地板预处理过程可视化图;
[0034]
图7为本发明具体实施例第五类实木地板预处理过程可视化图;
[0035]
图8为本发明具体实施例步骤s2的流程图;
[0036]
图9为本发明具体实施例改进的vgg16网络模型结构图;
[0037]
图10为本发明具体实施例根据具体实施参数进行模型训练的结果图。
具体实施方式
[0038]
下面结合具体实施例对本发明进行详细说明。以下实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。应当指出的是,对本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变化和改进。这些都属于本发明的保护范围。
[0039]
如图1,本实施例公开了一种基于深度学习的实木地板分类方法,包括如下步骤:
[0040]
s1:在标准光源下,通过工业相机对不同类别的实木地板图像进行采集;本实施例中,通过工业相机的视觉传感器对五种类别的木质地板图像进行rgb三通道彩色图像的数据采集,并对采集到的样本进行构建训练所需数据库;
[0041]
s2:对采集到的图像数据进行图像预处理操作,并将预处理后的数据划分为训练集,验证集和测试集;本实施例中,预处理过程的可视化如图3至图7,分别为5类不同的地板图像处理过程的可视化图;
[0042]
s3:搭建vgg16网络模型,并将训练集,验证集送入所述vgg16网络模型进行训练;vgg16网络是由13层卷积层加3层全连接层而组成的深度学习网络模型。本实施中,vgg16网络模型结构图如图9所示。
[0043]
s4:采用训练好的vgg16网络模型进行地板纹理的分类预测。本实施例中,验证其准确率如图2所示(虚线:训练集;实线:测试集)。
[0044]
其中,如图8,所述步骤s2进一步包括:
[0045]
s21:将采集到的实木地板图像通过重命名算法进行重新命名并进行类别标注;
[0046]
s22:使用伽马矫正算法消除光照对图像的影响;伽马校正就是对图像的伽马曲线进行编辑,以对图像进行非线性色调编辑的方法,检出图像信号中的深色部分和浅色部分,并使两者比例增大,从而提高图像对比度效果。
[0047]
s23:将伽马矫正后的图像使用大津算法进行粗纹理提取;大津算法(otsu):在图像处理领域,我们会遇到如下需求:把图像中的目标物体和背景分开。比如背景用白色表示,目标物体用黑色表示。此时我们知道目标物体的灰度值相互接近,背景灰度值相互接近,那么用大津算法能很好把目标从背景当中区分开来。
[0048]
s24:使用中值滤波算法对粗纹理提取后的图像进行图像噪点去除;本实施例中,使用核大小为15x15的滤波器对粗纹理提取后的图像进行中值滤波(medianblur),从而去除目标图像中的噪声对图像的影响;
[0049]
其中,中值滤波法是一种非线性平滑技术,它将每一像素点的灰度值设置为该点某邻域窗口内的所有像素点灰度值的中值。
[0050]
s25:使用局部二值模式算法对滤波后的图像进行局部特征纹理增强,去除细小纹理;其中,局部二值模式(lbp)首先是用来做图像局部特征比较的,传统的lbp方法,是首先通过阈值来标记中心点像素与其邻域像素之间的差别。
[0051]
s26:使用自适应阈值大津算法,遍历地板图像并计算其像素值的加权平均值,此值将作为一个粗细纹理分隔值,使用阈值分割法将大于该分隔值的像素点增强加粗,反之小于此分割值的像素则淡化;将等于该分隔值的像素点也进行淡化。
[0052]
s27:使用opecv库中resize函数,将图片尺寸调整至模型预设的输入要求的大小;本实施例为(224,244)。
[0053]
s28:将图像归一化后存储,待所有样本图像处理完成后,按照数据集划分标准,随机选择90%的数据作为训练集,剩下的10%的数据集作为最终评估模型的测试集,然后在训练集中随机选择原数据10%数量的数据作为训练时的验证集。
[0054]
以处理其中一幅图像为例,进行说明,如下:
[0055]
其中,步骤s22进一步包括:读入原图,使用opencv库将其转为灰度图像,对图像进行伽马(gama)矫正,去除光照因素对其的影响,设img
in
为输入图像,γ为校正系数(本发明选择矫正系数为1/4,进行图像补光操作),f(img
in
)为矫正后的图像:
[0056]
f(img
in
)=(img
in
)
γ
ꢀꢀꢀ
(1)
[0057]
伽马矫正后得到图像gama_image,即f(img
in
)。
[0058]
其中,开源计算机视觉(opencv)是一个主要针对实时计算机视觉的编程函数库。
[0059]
步骤s23进一步包括:使用大津算法进行阈值分割,得到纹理较为杂乱的图像,其中,sum为图像总的像素点个数,小于等于计算所得阈值像素点个数记为n0,大于该阈值记为n1,img(n,m)为图像中在点(n,m)的像素值大小:
[0060]
计算背景像素占比ω1:
[0061][0062]
计算前景像素占比ω2:
[0063]
ω2=1-ω1
ꢀꢀꢀ
(3)
[0064]
计算背景平均灰度值μ1:
[0065][0066]
计算前景平均灰度值μ2:
[0067][0068]
计算0~m灰度区间的灰度累计值μ:
[0069]
μ=μ1*ω1+μ2*ω2
ꢀꢀꢀ
(6)
[0070]
计算出类间方差g:
[0071]
g=ω1*ω2*(μ1-μ2)2ꢀꢀꢀ
(7)
[0072]
该算法将会遍历出图像的中使类间方差最大的阈值t,t即为分割阈值,从而将图像分为背景和目标两个部分,从而去除颜色对图像的影响,经过大津算法后得到二值化图像otus_image。
[0073]
步骤s24进一步包括:使用中值滤波算法对得到的图像进行噪点的去除,自样本图
像由上到下,由左至右,采用(15,15)的滤波窗口进行滑动(即采用核大小为15x15的滤波器进行滤波),将中心像素周围的224个像素连同选定的中心像素进行排序,然后选择排序好的中值赋予中心像素值,代替原有的像素值,用公式表示如(8)所示,x、y分别为其坐标点的值:
[0074]
g=median[(x-1,y-1)+f(x,y-1)+...+f(x,y+1)+f(x+1,y+1)]
ꢀꢀꢀ
(8)
[0075]
经过中值滤波后得到图像medianblur_image。
[0076]
步骤s25进一步包括:
[0077]
以距离待测图像左上角32像素的点作为中心点;以中心点为圆心,32像素为半径的圆作为比较范围;获取中心点与比较范围内所有像素点的像素值的绝对值的差值(即中心点的像素绝对值与比较范围内的像素点的像素绝对值的差值),选取其差值最大的8个像素点作为比较点;将比较点的像素与中心点像素进行比较,若中心点像素大于比较点像素,则比较点像素标记为0,同时对该点进行纹理增强(黑),反之则标记为1,同时对该点进行纹理淡化(白)。
[0078]
如公式(10)、(11)所示,其中(x
c
,y
c
)是中心点像素,i
c
为灰度值,i
p
为其相邻像素的灰度值,s为一个符号函数;
[0079][0080][0081]
经过lbp算法后得到图像lbp_image。
[0082]
步骤s26进一步包括:
[0083]
计算图像的像素权重平均值,进行二值化处理,去除图像不明显纹理,增强明显纹理;其中m为总像素点个数,f(x,y)为所有像素的加权和,其范围在s内,s为像素值范围,如公式(12)所示:
[0084][0085]
其中,fes代表f∈s,是f的元素属于s集合。
[0086]
计算后得到像素权重平均值g(x,y),然后根据该值对图像进行二值化处理,将大于该值的像素点的像素值置为255,小于该值的像素的像素值点置为0,公式如(13)所示,其中z
i
为当前像素值:
[0087][0088]
步骤s27进一步包括:
[0089]
将处理好的图片通过opencv库将尺寸调整为224x224大小,存入指定路径当中,得到out_image图像。
[0090]
以上6步是以一个图像为例进行说明,具体实施时,通过算法遍历采集的250张地
板图像,进行以上6步的操作
[0091]
对所有图像进行以上6步操作后,步骤s28进一步包括:
[0092]
经过图像预处理后,将处理好的图像根据指定比例分为训练集(train)、验证集(validation)和测试集(test),本实施例随机选择90%的数据作为训练集,剩下的10%的数据集作为最终评估模型的测试集,然后在训练集中随机选择原数据10%数量的数据作为训练时的验证集。,具体实施时,可以根据自己实际需要来调整此比例。
[0093]
步骤s3进一步包括:
[0094]
数据集划分完成后,进行数据增强,然后构建vgg16网络模型,设置好所需参数即可进行模型训练,具体步骤如下:
[0095]
第1步:通过tensorflow框架中的keras模块下imagedatagenerator函数进行数据增强,本实施例中,只使用了其中的rotation_range、shear_range、zoom_range三种图像变换进行图像增强,将数据增加至原有的3倍,最终数据总数为1000张。具体实施时,可以根据自己实际需要进行微调。
[0096]
第2步:构建vgg16网络模型,网络框架如图9所示,一个卷积神经网络主要包含输入层(input)、卷积层(conv2d)、池化层(pooling)、全连接层(dense),本实施例中,输入层使用的是宽高为224大小、通道为3的五种不同的地板样本;卷积层中使用了vgg16网络的前13层,其卷积层使用卷积核大小为3x3大小,步长为1,填补方式为
‘
same’,激活函数为relu方式,池化层使用了2x2大小的核,步长为2的滑动方式进行最大池化操作;在最后的全连接层,为使预测的实时性较好,在后2层的全连接层分别使用少量卷积核,分别为128,64个,激活函数为relu方式,在最后一层全连接层种选择地板种类数量的卷积核个数,并且使用的激活函数为softmax激活函数,输出为每一种地板种类预测的概率大小。
[0097]
使用relu激活函数的原因在于relu激活函数不会导致梯度较小时梯度爆炸的问题,其公式为(14)所示,其中x为输入特征:
[0098][0099]
使用softmax激活函数的原因在于,其输出为一个1xn维的向量,n个值分别为预测不同种类的概率值大小,值在0-1之间,其公式为(15)所示,其中α
j
代表n类中的第j个值,分母则为总种类的求和,因为e
x
指数函数恒大于0,所以可以确保输出在(0,1)之间不为负值:
[0100][0101]
图像预处理以及个参数调整好后,在pycharm编译器中点及开始即开始训练,训练集会按照预先在imagedatagenerator设定的各项参数,进行数据批量的送入模型训练。
[0102]
第3步:将训练好的权重参数以pre_floor.h5命名的文件存入当前路径即可。具体实施例时,可以根据自己的实际任务需求对上述最后一个全连接层的参数进行修改。
[0103]
其中,所述步骤s3中,在vgg16模型网络训练时,可根据当时用户使用的计算机配置与资源,提供使用迁移学习进行训练和从头开始训练分类模型的权重参数两种选择。
[0104]
步骤s4进一步包括:
[0105]
使用训练好的模型对未知样本进行种类的预测,其步骤如下:
[0106]
第1步:经过上述图像预处理一系列操作后,使用opencv将图像宽高改为224大小;
[0107]
第2步:加载模型,将训练时的得到的最佳权重参数加载至模型当中,具体代码实现如下所示:
[0108]
model.load_weights(
′
pre_floor.h5
′
)
[0109]
第3步:判断测试样本的类别:
[0110]
在输出结果中,将根据多数表决决定输入地板样本的类别y,公式如(16)所示:
[0111]
y=arg max(s
j
)
ꢀꢀꢀ
(16)
[0112]
其中s
j
见公式(15)
[0113]
实验与分析
[0114]
此次发明模型训练使用的实木地板图像样本库(见下表1),其中随机选择90%的数据作为训练集,剩下的10%的数据集作为最终评估模型的测试集,然后在训练集中随机选择原数据10%数量的数据作为训练时的验证集。,图像的宽高为224,rgb颜色深度为24位三通道数的彩色图像。
[0115][0116]
表1实木地板图像样本库
[0117]
关于上述实验,说明如下:
[0118]
1、样本经预处理后的纹理特征
[0119]
为了直观的将不同地板纹理特征表现出来,本实施例将图像预处理中每一步处理后的图像进行了可视化处理,具体特征区别可根据图3-图7很直观的表现出来。
[0120]
2、参数调优
[0121]
本次模型训练使用adam优化器,当优化器的学习率(learning rate)过小时,训练模型时模型收敛会很慢,导致收敛速度较慢;反之,学习率过大则会使模型训练时找不到最佳权重参数,找不到梯度下降最快的点,导致正确率较低。因此,为了找到最合适优化器的学习率,采用了动态学习率的方式,在训练模型时,模型在验证集的正确率或者损失值在训练五个epochs时没有下降时,则减小学习率,从而得到最优的学习率,使得模型收敛速度最快。
[0122]
3、损失函数的选择
[0123]
本次任务由于是多分类任务,选择多分类损失函数交叉熵损失(categorical crossentropy)为本次任务的损失判定函数,其公式如17所示;在模型训练时,网络所使用5个类别的标签值是经过矢量化的5维向量,这样就和训练时的出的5个概率值相对应,最后
经过argmax函数将预测概率最大的值所对应的标签输出。
[0124][0125]
其中n为地板样本数,m为分类个数。
[0126]
最终的实验效果:
[0127]
为了验证本发明提出的方法性能,对表1中五种不同纹理的木质地板分别进行了模型训练以及未知样本的测试。测试所用计算机操作系统:win10;cup:(core i5 10210u);内存:24g;测试软件:pycharm community 2020。实验效果:在训练时长2小时,训练轮数30个epochs后,正确率达到100%,loss值低至0.0000001849,模型在测试集上的正确率达到100%,loss值低至0.0000001192,如图10所示;模型在对未知样本进行与测时,分别对5个不同样本进行预测,正确率达到100%,平均用时5.05456秒。
[0128]
综上所述,本实施例的方法中,数据预处理阶段对图像进行的中值滤波、二值化、大津算法、局部二值模式、像素权重平均值对图像进行粗纹理增强、细纹理减弱操作、对图像进行改变尺寸、数据集划分算法(划分为训练集、验证集和测试集)等算法对数据集进行处理;在模型训练阶段包括对模型网络框架的搭建、卷积大小、池化方式、全连接层神经元个数的选择以及relu和softmax激活函数、优化器及学习率的调整等参数进行了算则及调优;在预测未知地板样本时包括数据预处理、模型加载、选择概率最大类别输出操作对未知样本进行预测。
[0129]
所述的图像预处理阶段使用软件为pycharm community2020版本,算法语言使用python 3.6版本,工具包opencv为3.4.2版本,工具包skikit-learn为0.16.2版本,工具包numpy为1.18.4版本,工具包pandas为1.0.3版本、工具包matplotlib为3.1.3版本;模型训练以及未知样本预测阶段使用工具包tensorflow为2.0.0版本,tensorboaed为2.0.2版本
[0130]
图像预处理过程中,根据已知地板样本的纹理特征,建立训练时所需的样本分类数据库;然后消除了每幅地板图像在拍摄过程中图像噪声的干扰、细小杂乱纹理的干扰,保留了每幅图像大纹理的特征,并且对其进行了纹理增强。
[0131]
根据搭建好的vgg16网络模型,adam优化器的动态学习率设定,以及训练时epochs及batch_size的参数设置,随后进行网络模型的训练,通过算法根据所需精度进行权重参数保存,便于对未知地板样本预测阶段时使用。
[0132]
在网络结构及其他参数不变的条件下,通过给网络加载训练时所得的最佳权重参数,来对未知样本进行预测,预测输出后将为一个1xn维向量,其内容为n种种类的每种类别预测后所得的概率值大小,最终通过argmax函数将所得概率最大的类别输出,即完成预测。
[0133]
以上对本发明的具体实施例进行了描述。需要理解的是,本发明并不局限于上述特定实施方式,本领域技术人员可以在权利要求的范围内做出各种变化或修改,这并不影响本发明的实质内容。在不冲突的情况下,本申请的实施例和实施例中的特征可以任意相互组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1