基于深度学习的沿海非法养殖目标识别方法与流程
[0001]
本公开涉及计算机视觉技术领域,特别是涉及基于深度学习的沿海非法养殖目标识别方法。
背景技术:
[0002]
本部分的陈述仅仅是提到了与本公开相关的背景技术,并不必然构成现有技术。
[0003]
海域非法养殖是指违反海域管理规定,非法占用海域资源从事海水养殖的行为。非法养殖行为严重破坏海域生态环境,因此对其及时有效的排查对保护海域生态环境、保障海域资源的合理利用具有重要意义。
[0004]
在实现本公开的过程中,发明人发现现有技术中存在以下技术问题:
[0005]
目前,对于海域非法养殖行为的排查通常采用人工识别方式,由于我国海域面积广大且许多地区人工难以到达,因而人工识别方式消耗大量人力资源却效率低下、效果差。
技术实现要素:
[0006]
为了解决现有技术的不足,本公开提供了基于深度学习的沿海非法养殖目标识别方法;通过对无人机拍摄的非养殖海域光学图像进行目标检测,实现对海域非法养殖行为的识别。所述目标检测是指对图像中的养殖设施进行检测,所述养殖设施是指筏架、绳索、网箱等通过视觉可见的养殖设施。
[0007]
基于深度学习的沿海非法养殖目标识别方法,包括:
[0008]
步骤(1):对无人机采集的沿海非养殖海域图像进行预处理;
[0009]
步骤(2):对预处理后的图像中的各类养殖设施目标分别进行标注;按照设定比例将标注过养殖设施目标的图像划分为训练集和验证集;
[0010]
步骤(3):利用训练集和验证集,对非法养殖目标识别模型进行训练;
[0011]
步骤(3)又分为:步骤(3-1)、步骤(3-2)和步骤(3-3);
[0012]
步骤(3-1):构建改进的faster rcnn网络;
[0013]
步骤(3-2):将训练集中每一类养殖设施目标的图像数据输入到改进的faster rcnn网络中进行训练,得到对应类别的养殖设施检测模型;
[0014]
步骤(3-3):将验证集中每一类养殖设施目标的图像数据,输入到训练得到的相应类别的养殖设施检测模型中,进行验证,得到验证效果最好的不同类别养殖设施的非法养殖目标识别模型;
[0015]
步骤(4):使用步骤(3)所得到的非法养殖目标识别模型,对无人机所拍摄的待检测区域的图像进行自动检测,识别图像中出现的非法养殖设施目标,输出含有非法养殖设施目标的图像及非法养殖设施目标的位置和拍摄时间。
[0016]
与现有技术相比,本公开的有益效果是:
[0017]
(1)本公开给出一种对海域非法养殖进行智能检测的方法。
[0018]
(2)本公开采用计算机视觉技术,通过对非养殖区域中养殖设施的特征识别,实现
rcnn网络中进行训练,得到对应类别的养殖设施检测模型;
[0037]
步骤(3-3):将验证集中每一类养殖设施目标的图像数据,输入到训练得到的相应类别的养殖设施检测模型中,进行验证,得到验证效果最好的不同类别养殖设施的非法养殖目标识别模型;
[0038]
步骤(4):使用步骤(3)所得到的非法养殖目标识别模型,对无人机所拍摄的待检测区域的图像进行自动检测,识别图像中出现的非法养殖设施目标,输出含有非法养殖设施目标的图像及非法养殖设施目标的位置和拍摄时间。
[0039]
进一步地,所述预处理,包括:图像去噪、图像增强和几何变换。
[0040]
进一步地,所述各类养殖设施目标,包括:养殖筏架、养殖箱、绳索、蚝排、蚝桩或网笼。
[0041]
进一步地,所述改进的faster rcnn网络,是指:对faster rcnn网络进行如下改进:
[0042]
步骤(3-1-1):改进faster rcnn中的特征提取网络,即:使用vgg16网络的若干层或全部层替换faster rcnn中的特征提取网络,vgg16网络的若干层或全部层每一层均用于提取图像中的特征图feature map,vgg16网络的每一层均提取出对应的特征图feature map;
[0043]
步骤(3-1-2):改进faster rcnn中的区域推荐网络rpn(region proposal networks),即:将训练集和vgg16网络的每一层输出的特征图feature map均输入到对应的rpn中,每一个rpn针对输入的特征图feature map生成若干个检测框并判断每个检测框内部的图像属于图像的前景还是后景;如果是前景,则视为检测框中有物体,前景视为正样本,如果是后景,则视为检测框中没有物体,后景视为负样本;进行边框回归后,通过非极大值抑制nms从每个特征图feature map的若干个检测框中挑选出最佳候选框;进而生成不同层的最佳候选推荐框proposal boxes;
[0044]
步骤(3-1-3):将步骤(3-1-2)中每一个rpn所得到的最佳候选推荐框proposal boxes和步骤(3-1-1)中vgg16网络的每一层输出的特征图feature map均输入到roi pooling层得到若干个推荐特征图proposal feature maps;
[0045]
步骤(3-1-4):将若干个推荐特征图proposal feature maps传给全连接层,通过全连接层和softmax分类器计算判断每一个推荐特征图proposal feature map的非法养殖目标的类别;
[0046]
通过非法养殖目标的类别与标注的实际情况进行对比得到位置偏移量,根据位置偏移量进行边框回归,然后使用非极大值抑制nms方法保留效果最好的预测框;
[0047]
通过rpn网络中进行的边框回归和在全连接层中进行的边框回归,两次边框回归提升了预测框精度,通过预测结果和验证集比对,再通过反向传播调整网络中的权重参数。
[0048]
非法养殖目标,包括:网箱、绳索。
[0049]
所述步骤(3-1-1)中的feature map是指:通过特征提取网络vgg16,vgg16网络共有conv1、conv2、conv3、conv4和conv5五层,每一层卷积和池化后均得到对应的feature map,或者将vgg16中若干层的feature map进行融合得到新的feature map。
[0050]
所述步骤(3-1-2)中的rpn,用于生成候选推荐框proposal boxes。
[0051]
所述步骤(3-1-2)中的非极大值抑制nms用于在多个候选框中挑出一个效果最好
的。
[0052]
所述步骤(3-1-3)中的roi pooling层是指:roi池化层,用来对传入的信息进行处理并得到统一大小的proposal feature maps.
[0053]
所述步骤(3-3)中的效果最好的模型是指:在验证集上准确率和召回率综合考量效果最好的模型。
[0054]
所述步骤(4)中的采集待检测区域的图像是指:使用无人机对待检测非养殖区进行航拍得到的图像,图像保留有拍摄时的经纬度和时间等信息。
[0055]
所述步骤(4)中的识别是指:将一张待检测图像输入到非法养殖目标识别模型中,并且设定概率阈值,输出一张带有养殖设施预测框和该预测框属于具体养殖设施类别概率的图像。
[0056]
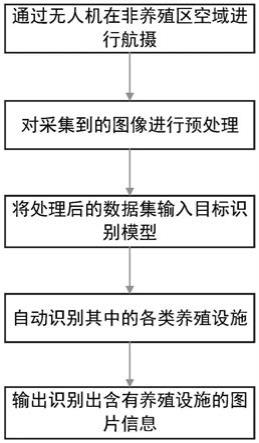
如图1所示,非法养殖目标识别流程如下:
[0057]
通过无人机在非养殖区空域进行航摄,对采集到的图像进行预处理,将处理后的数据集输入非法养殖目标识别模型,自动识别其中的各类养殖设施,如:筏架,绳索,网箱等,输出识别出含有养殖设施的图像信息。
[0058]
如图2所示,基于改进的faster rcnn的非法养殖识设施目标识别模型训练过程如下:
[0059]
(1)将训练集中的图像输入vgg16网络,保存将提取出的n层的feature map,将n层的feature map输入n个rpn网络中;
[0060]
(2)rpn网络通过提取到的feature map设置不同大小的锚框并对生成的锚框进行过滤和标记,当锚框与标注物体的区域重合度大于阈值时判断为前景,而小于阈值即为背景。
[0061]
(3)对锚框使用softmax进行分类,使用iou大小比较的方式进行nms非极大值抑制,并最终生成若干个候选推荐框,生成不同层的proposal boxes。
[0062]
(4)将每一个rpn网络生成的proposal boxes和之前提取出的feature map都传送到roi pooling层中,经过roi pooling层归一化得到proposal feature maps;
[0063]
(5)将proposal feature maps传给全连接层,通过全连接层和softmax计算出每个proposal的具体类别位置以及概率信息并获得每个proposal的位置偏移量用于边框回归,再次使用nms方法保留效果最好的预测框,通过预测结果和验证集比对再通过反向传播调整网络的权重参数;
[0064]
(6)多次训练后取在验证集上效果最好的模型保存:通过调整学习率等超参数多次训练,每经过一定的epoch保存一次模型,选择在验证集上取得综合准确率和召回率考量效果最好的模型。
[0065]
如图3所示,本公开对faster rcnn模型的改进内容为:
[0066]
(1)不同于传统的faster rcnn模型中直到vgg16中的conv5时取得feature map时才将feature map传入rpn网络,本公开将conv1到conv5中每一层或多层得到的feature map或其中若干层得到的融合feature map传入rpn网络中。(图3中为方便表示将每一层得到的feature map都传入)。
[0067]
本专利是使用了vgg16网络中的多层一同输出,比如输出conv1 conv2conv5三层的feature map,不仅仅是只采用最后的输出了,这么做的目的是因为底层比如conv1的
feature可以较好的保存小物体的特征,选择不同层输出,对于不同高度拍摄的照片有较好的效果。
[0068]
(2)不同于传统的faster rcnn模型中只有一个rpn,本公开由于使用了不同个数的feature map,所以使用了对应个数的rpn网络。
[0069]
(3)不同于传统的faster rcnn模型中一个rpn生成proposal boxes传入roi pooing层的模式,本公开不同个数的rpn产生的数个proposal boxes都传入到roi pooling中用以生成统一大小的proposal feature maps。
[0070]
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1