一种基于条件互信息和交互信息的多标签特征选择方法与流程
1.本发明属于机器学习与模式识别领域,具体涉及一种基于条件互信息和交互信息的多标签特征选择方法。
背景技术:
2.在传统的监督学习任务中,每个样本被默认为只包含一种分类标签。然而,这样的假设往往与现实世界的真实情况不符,例如,在图片分类任务中,一张风景图片往往同时包含“花”“鸟”“树”等景物,由此可见,使用单一标签无法充分表达其信息,同样使用传统的单标签分类方法将很难对这种情况进行准确的分类,多标签分类应运而生,并在文本分类、音乐分类以及基因功能预测等领域取得了出色的成果。
3.随着多标签算法的广泛应用,多标签特征选择算法也激发人们的热情,使其被发展用于降维和提高分类性能。因为和传统的监督学习一样,多标签学习也存在着高维的数据,数据中存在着大量无关特征和冗余特征,降低多标签模型的准确性,浪费了模型的时间和空间。于是多标签特征选择就显得十分重要。
4.国内外现在有关多标签特征选择主要分成两个策略。一个是问题转化,将多标签数据集转化成单标签数据集,然后使用传统的单标签特征选择算法,选择一个特征子集。这个方面往往没有考虑到标签和标签之间的分类信息,所以效果不是很好。另一个策略就是算法适应,提出一个符合多标签数据集特征选择算法,直接进行选出特征子集。
技术实现要素:
5.本发明针对现有技术的不足,提出一种基于条件互信息和交互信息的多标签特征选择方法。
6.本发明包括以下步骤:
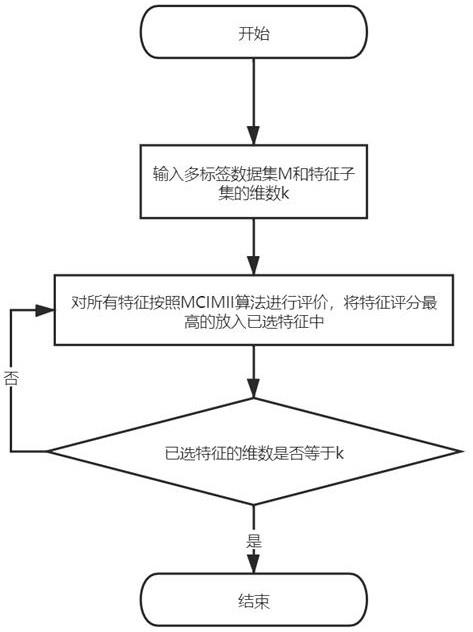
7.步骤1:给定多标签数据样本的集合m和指定特征子集维度k,其中集合m含有p个特征,q个标签。
8.步骤2:对所给的集合m进行预处理,包括缺失值填充和连续特征的离散化。然后按照训练集train与测试集test为3:1的比例,将集合m划分成两个部分。此时,已选特征集合s为空,候选特征集合j的元素为训练集train中p个特征。
9.步骤3:给出多标签特征选择算法j(x
k
);
[0010][0011]
其中x
k
表示候选特征,x
j
表示已选特征,y
i
表示标签,s是已选特征的集合,y是标签的集合,j(x
k
)表示候选特征在此算法下的得分,i(x
k
;y
i
|x
j
)表示在给定x
j
条件下,x
k
和y
i
的
相关性,i(x
j
;y
i
|x
k
)表示在给定x
k
条件下,x
j
和y
i
的相关性,i(x
k
;y
i
;y
j
)表示x
k
、y
j
和y
i
的相关性。
[0012]
步骤4:对候选特征集合j中所有的特征使用多标签特征选择算法进行评价。候选特征集合j中的每个候选特征都有属于自己的一个分数,选择得分最高的特征,将其索引加入到已选特征集合s中,同时在候选集合j中移除该特征,更新多标签特征选择算法。
[0013]
步骤5:如果已选特征集合中元素个数等于最开始指定特征子集的维度k,则停止。否则不断重复步骤4。
[0014]
步骤6:已选特征集合中的元素就是集合j中特征的索引,然后根据这些索引构建一个特征子集mm。
[0015]
步骤7:将构造好的特征子集输入到mlknn模型中,由特征子集训练得到mlknn模型mlknn_mm。
[0016]
本发明的有益效果:本发明基于条件互信息重新定义特征相关项,将已选特征的条件互信息纳入进来;又从特征交互的角度定义标签之间的冗余,将其纳入冗余项,定义了一个名为多标签特征选择算法,有效地选择特征子集,提高多标签分类模型的性能。
附图说明
[0017]
图1为发明整体流程图;
[0018]
图2为多标签特征选择方法进行多标签特征选择过程图。
具体实施方式
[0019]
本发明所采用的技术方案步骤如下:
[0020]
步骤1:给定多标签数据样本的集合m和指定特征子集维度k,其中集合m含有p个特征,q个标签。
[0021]
步骤2:对所给的集合m进行预处理,包括缺失值填充和连续特征的离散化。然后按照训练集train与测试集test为3:1的比例,将集合m划分成两个部分。此时,已选特征集合s为空,候选特征集合j的元素为训练集train中p个特征。
[0022]
步骤3:给出多标签特征选择算法j(x
k
)—maximum conditional interaction minimum information interaction(mcimii);
[0023][0024]
在这里x
k
表示候选特征,x
j
表示已选特征,y
i
表示标签,s是已选特征的集合,y是标签的集合,j(x
k
)表示候选特征在此算法下的得分,i(x
k
;y
i
|x
j
)表示在给定x
j
条件下,x
k
和y
i
的相关性,i(x
j
;y
i
|x
k
)表示在给定x
k
条件下,x
j
和y
i
的相关性,i(x
k
;y
i
;y
j
)表示x
k
、y
j
和y
i
的相关性。
[0025]
步骤4:对候选特征集合j中所有的特征使用多标签特征选择算法进行评价。候选特征集合j中的每个候选特征都有属于自己的一个分数,选择得分最高的特征,将其索引加入到已选特征集合s中,同时在候选集合j中移除该特征,更新多标签特征选择算法。
[0026]
步骤5:如果已选特征集合中元素个数等于最开始指定特征子集的维度k,则停止。否则不断重复步骤4。
[0027]
步骤6:已选特征集合中的元素就是集合j中特征的索引,然后根据这些索引构建一个特征子集mm。
[0028]
步骤7:将构造好的特征子集输入到multi-label k-nearest neighbor(mlknn)模型中,由特征子集训练得到mlknn模型mlknn_mm。
[0029]
步骤2中,缺失值填充和特征离散化具体是:
[0030]
所述缺失值填充是对每一列的缺失值,填充当列的众数。
[0031]
所述特征离散化是将特征的取值范围等间隔分割,从最小值到最大值之间,均分n等份。
[0032]
当存在某列缺失值过多,众数为nan的情况时,采取的策略是每列删除掉nan值后的众数。
[0033]
步骤3中,给出多标签特征选择算法的步骤包括:
[0034]
定义熵信息熵:
[0035]
信息熵是表示集合中的混乱程度,其中log是对数函数,一般以2为底
[0036]
条件熵:
[0037]
条件熵表示已知集合y,求x的混乱程度,其中p(xi,yi)表示联合概率,p(xi|yi)表示条件概率。
[0038]
互信息:i(x;y)=h(x)-h(x|y)
[0039]
互信息表示两个随机变量之间的相关程度。
[0040]
条件互信息:i(x;y|z)=h(x|z)+h(y|z)-h(x,y|z)
[0041]
条件互信息表示在给定z条件下,随机变量x和y的相关性。
[0042]
特征交互:i(x;y;z)=i(x;z)-i(x;z|y)
[0043]
特征交互表示三个随机变量之间的相关性。
[0044]
给出多标签特征选择算法j(x
k
);
[0045][0046]
步骤7中,训练mlknn分类器的步骤包括:
[0047]
新产生的特征子集mm输入mlknn模型中,此时mlknn模型的参数k的个数为10,其他参数保持默认,最终的得到优化的mlknn模型。
[0048]
实施例:
[0049]
首先观察数据集,emotions数据集是一个比较典型的多标签数据集。其根据tellegen-watson-clark的情绪模型,将音乐唤起的情绪进行分类:惊讶-惊奇、高兴-愉悦、放松-平静、安静-静止、悲伤-孤独和愤怒-怨恨。它由593首歌曲组成,共有6个等级。即emotions数据集有593个实例,标签有6个。且emotions数据集特征数目是72个。
[0050]
根据图1发明整体流程图和图2mcimii算法进行多标签特征选择过程图的步骤。可知此时输入的集合m为emotions,输入的特征子集维度k为35。之后,通过mcimii算法得到的
特征集合为:{4,28,49,3,17,58,26,39,23,57,0,71,1,25,40,22,53,38,46,5,16,60,56,24,36,52,30,61,55,35,44,21,70,51},然后根据已选特征集合创建特征子集mm,最后由特征子集mm来训练mlknn分类器模型,得到模型mlknn_mm。
[0051]
使用hamming loss、ranking loss、coverage error和average precision等作为评判多标签分类模型的标准。接下来做对比实验,用训练集train直接来训练mlknn模型,不经过mcimii特征选择,得到模型mklnn_train。代入测试集test,得到mlknn_train模型的四个指标。将以上数据汇聚成表格如下:
[0052]
表1特征子集mm与全部特征数据集emotions四种指标对比
[0053][0054]
表1中average precision指标是越大越好,而coverage error、hamming loss和ranking loss这三者的指标是越小越好。实验结果表明mlknn_mm分类器在多种指标上均比mlknn_train分类器要好。这表明了mcimii多标签特征选择算法,可以有效地提高多标签分类模型的性能。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1