全栈式的前向型神经网络深度学习系统安全分析与检测方法与流程
[0001]
本发明涉及了人工智能神经网络的一种安全分析与测评方法,具体是一种全栈式的前向型神经网络深度学习系统安全分析与检测方法。
背景技术:
[0002]
随着海量数据的增加以及计算硬件的高速发展,深度学习在很多领域已经取得了巨大成功,例如图像处理,语音处理和医疗诊断。然而,尽管目前神经网络可以获得较高的准确率,但是其仍然面临着质量、可靠性以及安全问题。例如对于一个识别正确的输入数据,通过微小的扰动其很容易让深度神经网络出错。当其被应用到很安全相关的场景时,对于其质量、可靠性以及安全性的保障变得尤为重要。
[0003]
在传统软件上已经有多种成熟的技术以保障传统程序的安全与可靠性,然而,由于深度神经网络的独特性,现有的技术很难直接应用到神经网络的分析上。因此,为了保障深度神经网络的质量以及其真正落地,研究新的分析与测评技术是十分必要的。
[0004]
深度学习系统的生命周期通常包含数据收集、神经网络设计、神经网络训练以及神经网络部署等阶段。而在周期的每个阶段都容易出现问题从而导致整个系统的不安全,例如测试数据不充分、模型不鲁棒以及模型在部署环境的兼容性问题等。
技术实现要素:
[0005]
为了保障深度学习系统的安全与可靠性,需要对其进行安全检测,本发明提出了一种全栈式的前向型神经网络深度学习系统安全分析与检测方法,从数据到神经网络再到部署阶段等多维度来对深度学习系统进行测评。
[0006]
本发明解决上述问题所采用的技术方案为:
[0007]
针对前向型神经网络,采用包含数据敏感度分析测试、神经网络质量分析测试和神经网络部署测试的三个深度学习系统全生命周期的分析检测步骤。
[0008]
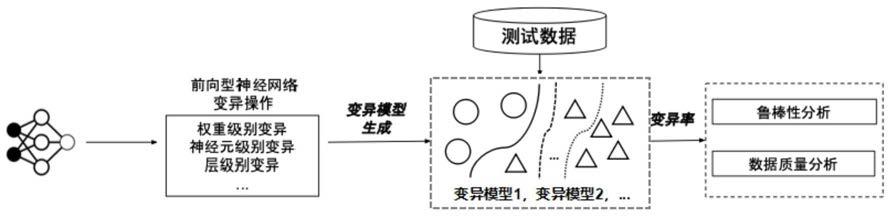
针对前向型神经网络进行变换、变异处理生成多个高质量的改变的神经网络,将测试数据输入到各个改变的神经网络中获得输出结果,根据所有输出结果处理获得变异率,通过测试数据在多个改变的神经网络中获得的变异率作为测试数据的敏感度参数;
[0009]
在各个神经网络的处理过程中计算获得覆盖率,利用覆盖率生成更多大量的测试用例;再将生成的测试用例输入到神经网络中获得错误率,以错误率作为质量参数,评估作为鲁棒性的结果;
[0010]
采用遗传算法对原始的测试数据进行变异,在遗传算法的每一轮演化中,通过收益函数对变异后的测试数据进行筛选以进行下一轮演化,最终获得在部署环境与开发环境中不一致率大于预设一致阈值的变异后的测试数据,以测试数据输入到神经网络中以输出结果的错误率作为兼容性结果。不一致率是指变异后的测试数据经原始的神经网络处理后获得的输出结果的较小数不一致的占比例。
[0011]
前向型神经网络中,神经网络质量分析中采用但不限于神经网络权重变换、神经
元阻断(neuron effect block)、神经元激活反转(neuron activation inverse)、神经元互换(neuron switch)、层删除(layer remove)、层增加(layer addition)和层复制(layer duplication)来生成多个高质量的变异神经网络。
[0012]
给定一个神经网络,首先通过微小的变化来对目标神经网络进行变异以生成多个神经网络,然后用多个神经网络分别去预测处理测试数据获得输出结果,根据输出结果的变化率来分析判断处理。
[0013]
具体来说,对于前向型神经网络,提出了三个不同级别的变异操作:
[0014]
a)神经网络权重级别变化,例如对现有神经网络的权重添加高斯噪声;
[0015]
b)神经元级别变化,包括随机去除部分神经元的作用、翻转神经元的结果或者更换两个神经元的输出结果;
[0016]
c)层级别变化,包括删除某个层、添加新层或者复制某个层。
[0017]
通过以上变异操将一个神经网络生成多个改变的神经网络,这些改变的神经网络的决策边界与原始神经网络的决策边界很相近。
[0018]
对于一个测试数据,通过其在多个变异神经网络预测结果的不一致性来判断其敏感性与质量。如果一个测试数据在多个改变的神经网络的预测结果不一致率高,高于预设阈值,则该测试数据质量较高,其能抓取模型微小扰动带来的影响。相反,如果所有改变的神经网络的结果预测一致,则该测试数据是不敏感的,其无法抓取模型的不同行为。
[0019]
前向型神经网络中,通过随机生成方式生成测试用例,将测试用例输入到原始的神经网络中,将测试用例输入到原始的神经网络的处理过程中通过度量原始的神经网络中激活的神经元以及激活值来计算覆盖率,然后以覆盖率为导向以筛选有效的测试数据,将覆盖率提高的测试用例保留,覆盖率提高是指测试用例输入到改变的神经网络后相比训练数据输入到原始的神经网络后获得的覆盖率结果提高,将覆盖率未提高的测试用例删除,最后将保留的测试用例加入到测试数据中。
[0020]
在测试过程中,随机生成大量的测试用例,再用测试标准来筛选有用的测试用例,也就是保留那些可以提升覆盖率的测试数据,这些数据可以触发神经网络的新行为,从而更有可能发现神经网络的缺陷。
[0021]
在神经网络测评方面,本发明提出了多种测试标准以度量一组测试数据的覆盖率。
[0022]
前向型神经网络中,用该模型预测所有的训练数据并记录神经网络的神经元在训练数据下的输出值,接着统计每个神经元在所有训练数据下的输出分布,例如最大值、最小值或者均值等,采用以下多种覆盖率方法的其中一种:
[0023]
1)统计多少神经元被激活(neuron coverage);
[0024]
2)将神经元的输出值分布分为k份,则对每个神经元计算有多少份可以被覆盖(k-multisection neuron coverage);
[0025]
3)统计神经元的边界区域的覆盖率(neuron boundary coverage);神经元的边界区域是指神经元输出值的最小值到最大值之间范围靠近输出值的最小值到最大值固定阈值范围内的数值区域。
[0026]
4)将大于神经元的输出最大值的部分分为k份,从而统计有多少份可以被覆盖(strong neuron activation coverage)
[0027]
5)统计在单个神经网络层中被激活前k个神经元的覆盖率(top-k neuron coverage)。
[0028]
神经网络均是由多个神经网络层构成,例如卷积层、全连接层,每个神经网络层包括了多个神经元。
[0029]
神经网络部署测试包含检测不同神经网络输出结果的不一致性、同一神经网络在不同深度学习框架(例如,tensorflow,pytorch)的输出结果的不一致性、同一神经网络在不同硬件之间输出结果的不一致性,神经网络部署测试将上述不一致性检测问题转换为寻找离神经网络边界较近数据的问题。
[0030]
在神经网络部署阶段,本发明提出了一种利用遗传算法的差异测试方法来生成测试用例,这些测试用例反应相同数据在开发环境与部署环境中的不一致性,从而可以高效的发现兼容性问题。
[0031]
当给定多个进行相同任务的神经网络或者一个神经网络但其在不同环境下运行时,通过遗传算法以搜索离神经网络决策边界较近的数据,其更有可能导致神经网络预测的不一致性。
[0032]
所述的收益函数采用的基本收益函数、k-收益函数和目标收益函数中的其一。这些收益函数可以引导生成高质量的数据,从而抓取神经网络的兼容性问题。
[0033]
本发明提出了一种基于变异测试的方法,为一个训练好的神经网络生成一定数量的变异神经网络,基于变异神经网络来计算数据的变异情况以估算测试数据的质量。当神经网络训练好后,对神经网络进行测评的测试,采用覆盖率导向的自动化测试方法,以对神经网络的鲁棒性进行测试。当神经网络部署后,采用差异测试的方法以检测神经网络在部署环境中的兼容性问题。
[0034]
本发明支持前向型神经网络,通过从数据收集到神经网络开发再到神经网络部署阶段的系统分析与测试,从而更好的检测深度学习系统的质量与安全问题,确保深度学习系统在真正部署阶段的安全性。
[0035]
本发明其有益效果为:
[0036]
本发明将深度学习开发过程中的多个步骤的分析与检测集成在一个平台下,可以更高效更系统的对其进行分析与测试。在每一步完成之后,可以快速地对其进行分析与测试,从而更早的发现深度学习系统的缺陷。
[0037]
生成的测试用例可以帮助开发者更高效的理解与发现神经网络中的问题,例如数据不平衡、模型结构不恰当或者训练超参等问题。
[0038]
对于一个训练十分完美的模型,也可以快速发现其在部署阶段的兼容性问题,以减少其在真正部署后带来的严重后果,例如无人车驾驶。
附图说明
[0039]
图1为数据分析过程的示意图。
[0040]
图2为神经网络测试标准示意图。
[0041]
图3为基于覆盖率引导的测试流程示意图。
[0042]
图4为兼容性测试的流程示意图。
具体实施方式
[0043]
下面结合附图对本发明进一步说明。
[0044]
如图1所示,具体实施给定一组测试数据以及一个目标神经网络,针对神经网络的类型先采用对应的变异操作生成多个变异神经网络,变异操作使得变异神经网络的决策边界与目标神经网络十分相似。该变异神经网络用来预测测试数据,其结果可以反应测试数据的敏感性以及其质量。例如给定一张图片,如果其在多个变异模型的预测结果变化率高,则该图片在神经网络的敏感度较高,其可以反应多个变异神经网络的不同预测行为。
[0045]
如图2所示,给定一个待测神经网络,首先,对所有的训练数据输入处理预测,以抓取该神经网络的内部行为。对于前向型神经网络,得到每个神经元的输出结果。基于神经网络的输出结果采用不同的的度量处理方式(例如,neuron coverage)获得给定测试数据的覆盖率。
[0046]
如图3所示,基于测试标准,对一个目标神经网络进行覆盖率引导的测试。给定初始的测试种子,使用一个队列来存储以提高覆盖率的测试用例。在每一轮测试时选取一个测试用例,基于该测试用例来随机生成大量新的测试数据。
[0047]
本发明提出了三种不同的测试用例选取方法:在队列中随机选取一个、在队列中选取最新生成的测试用例以及基于测试用例曾经被选取次数的策略。当一个测试用例被选取后,通过不同的数据变换方式来生成新的测试用例,例如图像变换、语音变换以及文字变换等。如果这些数据可以带来新的覆盖率,则其被加入测试用例队列。否则,其被删除。
[0048]
如图4所示,当神经网络部署时,其开发环境与部署环境会有差异,其会导致在两个环境下的决策边界有微小的差异。例如神经网络优化后其行为会发生变化,神经网络在手机端与服务器上预测的行为同时会发生变化。本发明方法能够优化生成靠近决策边界的数据,这些数据更容易捕获系统在部署时的兼容性问题。具体来说,给定一个初始输入,通过随机变异的方法构造一个种群,然后进行标准的子代选取、交叉与变异以生成更优良的后代,利用不同的收益函数进行优秀子代的选取。
[0049]
本发明的具体实施过程如下:
[0050]
在使用本发明时,用户准备待测神经网络、训练数据集以及测试集。
[0051]
在神经网络训练好后,首先进行数据分析。将训练好的神经网络作为输入,本方法通过变异算子生成大量的变异神经网络并存储到本地服务器。用户提供相应的测试集或者其子集,数据分析模块度量测试集的敏感度以及质量。
[0052]
下一步,对于训练好的神经网络进行自动化测试。用户需要准备初始测试种子以及目标神经网络。对于本发明的前向型神经网络,首先需要利用训练集来收取神经元行为,该结果存储在本地服务器。接下来,本发明会对其进行自动化测试,并生成大量的高覆盖率的测试用例,包含可以被神经网络正确预测的测试用例以及预测错误的测试用例。
[0053]
最后,在神经网络测评结束后,需要测试其在部署阶段的兼容性。用户需要提供目标部署环境的接口,也就是给定一组输入,得到目标部署环境的输出结果。给定一组初始数据,本发明生成一组新的数据,其在训练开发环境与部署环境具有不同的输出结果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1