一种基于注意力机制的论文引用量预测方法与系统
1.本发明属于自然语言处理技术领域,更具体地,涉及一种基于注意力机制的论文引用量预测方法与系统。
背景技术:
2.在科技大数据中,占比最大、分量最重的莫过于学术论文。近年来,论文投稿量呈井喷式发展,拿计算机视觉领域的最重要会议之一cvpr来说,2001年投稿数不到一千,而2019年投稿量增长到五千以上,2020年投稿量更是超过6500。与此形成鲜明对比的是每年的录稿数,2019年录稿1300篇,2020年录稿1470篇,接收率仅在22%左右,且呈下降趋势。另外,2020年cvpr审稿人接近四千,可以预见的是,随着时间的发展,审稿的人力物力消耗将会越来越大。
3.近年来,基于nlp技术(如:transformer、bert)的文本理解技术取得了巨大的成功。然而,由于模型的参数过多,难以处理较长文本的输入(受限于gpu显存),更加无法处理整个文章。
技术实现要素:
4.本发明的目的在于提供一种基于注意力机制的论文引用量预测方法与系统,基于注意力机制的论文引用量预测模型——paperformer,实现了基于transformer的全文内容理解的论文引用量预测。该方法可以有效地获取论文中的关键信息,利用有限的硬件资源,得到高质量的引用量预测结果。
5.为实现上述目的,按照本发明的一个方面,提供了一种基于注意力机制的论文引用量预测方法,包括下述步骤:
6.(1)特征提取:
7.(1.1)使用预训练的词向量模型,将输入的每个单词转化为对应的词向量;
8.(1.2)句子中所有的词向量拼接后送入预训练的xlnet得到句子基础特征,其中xlnet中隐藏层的数目为12,注意力层的头数为12,特征的维度为768维。之后,要根据当前句子在文章中出现的位置,在xlnet预训练模型中找到对应位置的位置特征(position embedding),将此位置特征与句子基础特征相加后,得到句子特征;
9.(2)训练注意力模型(第一阶段):
10.(2.1)对文章中的每个句子通过注意力模型来计算注意力权重,输入步骤(1.2)中得到的句子特征,输出此句子的注意力权重。注意力模型中,注意力权重的计算公式如下:
[0011][0012]
其中h1,h2…
h
k
为步骤(1.2)得到的所有k个句子特征,即注意力模型的输入,k为文章中的句子数量;v,u,w为预设值,均为注意力模型中的参数;a
k
为输出的第k个句子的注意
力权重,0<a
k
<1且
[0013]
(2.2)对于步骤(1.2)得到的所有k个句子特征,都分别乘上步骤(2.1)得到的相应句子的注意力权重a
k
,再将它们相加。通过这种加权和的融合方式即可得到第一阶段文章特征;
[0014]
(2.3)根据论文发表的时间,首先构建独热编码。例如,我们使用的数据为2000年至2010年共11年的论文数据,因此我们构建的独热编码为11维,只有年份对应的数位为1,其他数位均为0,如2000、2001、
…
、2010年对应的编码为10000000000、01000000000、00000000001。将步骤(2.2)中得到的第一阶段文章特征,先与论文发表年份的独热编码拼接,再输入到一层全连接层来预测论文引用量的对数表示c
log
,其中c
log
=log(c
pred
+1),c
pred
为最终的预测的引用量。全连接层的输入维度为768,输出维度为1,最后可由公式c
pred
=exp(c
log
)
‑
1得到最终预测的引用量。
[0015]
(2.4)将从步骤(2.3)获取的论文引用量与真实引用量计算损失,损失函数的计算公式为l=|c
log
‑
log(c
gt
+1)|,其中c
log
为预测的引用量的对数表示,c
gt
为真实引用量。然后利用反向传播算法对注意力模型进行训练,得到训练好的注意力模型;
[0016]
(3)训练最终的引用量预测模型(第二阶段):
[0017]
(3.1)利用步骤(1.2)中提取的句子特征,和步骤(2)中训练好的注意力模型,得到文章中所有句子的注意力权重。然后按权重从大到小排序,在满足硬件资源限制的条件下,尽可能多地挑选出权重较大的若干关键句子,将这些关键句子拼接后,得到论文的精简文本;
[0018]
(3.2)将步骤(3.1)得到的论文的精简文本再次通过步骤(1)提取特征,送入xlnet得到第二阶段文章特征,之后与论文发表年份的独热编码拼接,再通过一层全连接层,来预测论文引用量的对数表示c
log
,经过转化即可得到最终预测的论文引用量c
pred
。关于发表年份的独热编码以及引用量的对数表示,具体见步骤(2.3);
[0019]
(3.3)将从步骤(3.2)获取的论文引用量与真实引用量计算损失,然后利用反向传播算法对最终的引用量预测模型进行训练,得到训练好的引用量预测模型。关于损失函数,具体见步骤(2.4);
[0020]
(4)利用上述训练好的引用量预测模型对输入论文进行引用量预测,包括如下子步骤:
[0021]
(4.1)对输入论文的每个句子进行步骤(1)中的特征提取,得到每个句子的特征,再经过步骤(3.1)得到论文的精简文本;
[0022]
(4.2)利用步骤(3)训练好的引用量预测模型,输入步骤(4.1)的精简文本后,即可得到预测的论文引用量c;
[0023]
按照本发明的另一方面,还提供了一种基于注意力机制的论文引用量预测系统,其特征在于,所述系统包括特征提取模块、注意力模型、最终引用量预测模型,训练过程包括注意力模型第一阶段、引用量预测模型第一阶段,其中:
[0024]
所述特征提取模块,用于对输入的论文进行统一的特征编码,得到统一的特征表达,具体包括词向量提取子模块和深度神经网络特征计算子模块,其中:
[0025]
所述词向量提取模块,用于将每个单词转化为对于的词向量;
[0026]
所述深度神经网络特征计算子模块,用于将词向量的拼接转化为更高维的句子特
征。
[0027]
所述注意力模型,用于根据输入的句子特征来计算其注意力权重,作为辅助来优化最后的预测结果。
[0028]
所述最终引用量预测模型,用于利用特征提取模块和注意力模型的输入,来对论文引用量做出较高精度的预测。
[0029]
所述注意力模型第一阶段,用于训练注意力模型,优化注意力模型内的参数。
[0030]
所述引用量预测模型第一阶段,用于训练特征提取模块和最终引用量预测模型,使其能最终做出较高精度的预测。
[0031]
通过本发明所构思的以上技术方案,与现有技术相比,本发明具有以下技术效果:
[0032]
(1)能适应任意长度的输入文本:本发明方法与以往的基于的预测方法相比,通过注意力权重只选取关键句子作为输入,不受输入文本长度过长的影响;
[0033]
(2)准确度高:论文长度一般较长,冗余信息较多,本发明方法与以往大多数方法只截取前面的句子的做法不同,通过网络去学习哪些句子对论文引用量有更大的影响,只考虑关键信息,忽视冗余的干扰信息,准确度更高;
[0034]
(3)节约成本:本发明方法不受限于文本长度过长导致的硬件资源不足的情况,降低了对硬件成本的要求;同时,由于只需要输入精简的文本,网络预测的时间成本也更低;
附图说明
[0035]
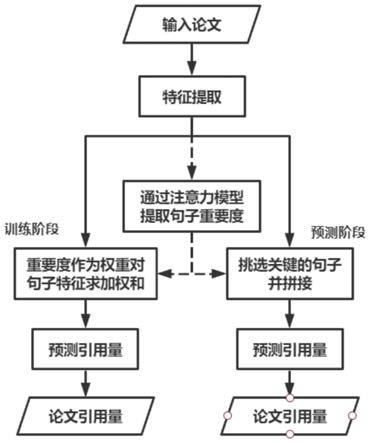
图1是本发明基于注意力机制的论文引用量预测方法的流程图;
[0036]
图2是模型预测的注意力分布趋势图,横轴从左往右表示句子在文章中的位置从前到后,纵轴表示最多选择64个词的情况下各个位置的句子被选中的次数,从图中可以看到,文章的开头和结尾由于有标题、摘要、总结这些关键信息,所以被选中的次数较多,这也验证了我们方法的有效性。
具体实施方式
[0037]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
[0038]
以下首先就本发明的技术术语进行解释和说明:
[0039]
s2orc数据集:该数据集是由艾伦人工智能研究院牵头制作的文章数据集,我们筛选了其中2000年到2010年的82k篇计算机领域论文,计算出它们在此数据集中8年内的引用量,作为我们的实验数据集。我们将其中90%用于训练,10%做测试。
[0040]
spearman rank评价指标:该评价指标公式为它专注于对排序准确性的评价。相比l2距离、l1距离这些直接的度量方法,此评价指标避免了论文引用量分布不均匀带来的评价不公平问题。
[0041]
如图1所示,本发明基于注意力机制的论文引用量预测方法包括以下步骤:
[0042]
(1)特征提取:
[0043]
(1.1)使用预训练的词向量模型,将输入的每个单词转化为对应的词向量;
[0044]
(1.2)句子中所有的词向量拼接后送入预训练的xlnet得到句子基础特征,其中xlnet中隐藏层的数目为12,注意力层的头数为12,特征的维度为768维。之后,要根据当前句子在文章中出现的位置,在xlnet预训练模型中找到对应位置的位置特征(position embedding),将此位置特征与句子基础特征相加后,得到句子特征;
[0045]
(2)训练注意力模型(第一阶段):
[0046]
(2.1)对文章中的每个句子通过注意力模型来计算注意力权重,输入步骤(1.2)中得到的句子特征,输出此句子的注意力权重。注意力模型中,注意力权重的计算公式如下:
[0047][0048]
其中h1,h2…
h
k
为步骤(1.2)得到的所有k个句子特征,即注意力模型的输入,k为文章中的句子数量;v,u,w为预设值,均为注意力模型中的参数;a
k
为输出的第k个句子的注意力权重,0<a
k
<1且
[0049]
(2.2)对于步骤(1.2)得到的所有k个句子特征,都分别乘上步骤(2.1)得到的相应句子的注意力权重a
k
,再将它们相加。通过这种加权和的融合方式即可得到第一阶段文章特征;
[0050]
(2.3)根据论文发表的时间,首先构建独热编码。例如,我们使用的数据为2000年至2010年共11年的论文数据,因此我们构建的独热编码为11维,只有年份对应的数位为1,其他数位均为0,如2000、2001、
…
、2010年对应的编码为10000000000、01000000000、00000000001。将步骤(2.2)中得到的第一阶段文章特征,先与论文发表年份的独热编码拼接,再输入到一层全连接层来预测论文引用量的对数表示c
log
,其中c
log
=log(c
pred
+1),c
pred
为最终的预测的引用量。全连接层的输入维度为768,输出维度为1,最后可由公式c
pred
=exp(c
log
)
‑
1得到最终预测的引用量。
[0051]
(2.4)将从步骤(2.3)获取的论文引用量与真实引用量计算损失,损失函数的计算公式为l=|c
log
‑
log(c
gt
+1)|,其中c
log
为预测的引用量的对数表示,c
gt
为真实引用量。然后利用反向传播算法对注意力模型进行训练,得到训练好的注意力模型;
[0052]
(3)训练最终的引用量预测模型(第二阶段):
[0053]
(3.1)利用步骤(1.2)中提取的句子特征,和步骤(2)中训练好的注意力模型,得到文章中所有句子的注意力权重。然后按权重从大到小排序,在满足硬件资源限制的条件下,尽可能多地挑选出权重较大的若干关键句子,将这些关键句子拼接后,得到论文的精简文本;
[0054]
(3.2)将步骤(3.1)得到的论文的精简文本再次通过步骤(1)提取特征,送入xlnet得到第二阶段文章特征,之后与论文发表年份的独热编码拼接,再通过一层全连接层,来预测论文引用量的对数表示c
log
,经过转化即可得到最终预测的论文引用量c
pred
。关于发表年份的独热编码以及引用量的对数表示,具体见步骤(2.3);
[0055]
(3.3)将从步骤(3.2)获取的论文引用量与真实引用量计算损失,然后利用反向传播算法对最终的引用量预测模型进行训练,得到训练好的引用量预测模型。关于损失函数,具体见步骤(2.4);
[0056]
(4)利用上述训练好的引用量预测模型对输入论文进行引用量预测,包括如下子步骤:
[0057]
(4.1)对输入论文的每个句子进行步骤(1)中的特征提取,得到每个句子的特征,再经过步骤(3.1)得到论文的精简文本;
[0058]
(4.2)利用步骤(3)训练好的引用量预测模型,输入步骤(4.1)的精简文本后,即可得到预测的论文引用量c;
[0059]
以下通过实验实例来证明本发明的有效性,实验结果证明本发明能够提高论文引用量预测的准确率。
[0060]
本发明在我们基于s2orc生成的数据集上,与之前的朴素方法进行了对比,表1是本发明方法和用于比较的4种对比方法在该数据集上的spearman rank指标的表现,结果的数值越大表示论文引用量预测的准确率越高,从表中可以看到,本发明方法paperformer提升非常明显。
[0061]
表1不同方法的spearman rank指标表现
[0062][0063]
图2是本发明模型预测的注意力分布趋势图,横轴从左往右表示句子在文章中的位置从前到后,纵轴表示最多选择64个词的情况下各个位置的句子被选中的次数。从图中可以看到,文章的开头和结尾由于有标题、摘要、总结这些关键信息,所以被选中的次数较多,这也验证了我们方法的有效性。
[0064]
进一步地,本发明还提供了一种基于注意力机制的论文引用量预测系统,所述系统包括特征提取模块、注意力模型、最终引用量预测模型,训练过程包括注意力模型第一阶段、引用量预测模型第一阶段,其中:
[0065]
所述特征提取模块,用于对输入的论文进行统一的特征编码,得到统一的特征表达,具体包括词向量提取子模块和深度神经网络特征计算子模块,其中:
[0066]
所述词向量提取模块,用于将每个单词转化为对于的词向量;
[0067]
所述深度神经网络特征计算子模块,用于将词向量的拼接转化为更高维的句子特征。
[0068]
所述注意力模型,用于根据输入的句子特征来计算其注意力权重,作为辅助来优化最后的预测结果。
[0069]
所述最终引用量预测模型,用于利用特征提取模块和注意力模型的输入,来对论文引用量做出较高精度的预测。
[0070]
所述注意力模型第一阶段,用于训练注意力模型,优化注意力模型内的参数。
[0071]
所述引用量预测模型第一阶段,用于训练特征提取模块和最终引用量预测模型,使其能最终做出较高精度的预测。
[0072]
本领域的技术人员容易理解,以上所述仅为本发明的较佳实施例而已,并不用以
限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1