一种金融电销场景中对负样本做消减的采样方法与流程
of the eleventh international conference of machine learning,pp.148
–
156san francisco,ca.morgan kaufmann.)、(ling,c.,&li,c.(1998).data mining for direct marketing problems and solutions.in proceedings of the fourth international conference on knowledge discovery and data mining(kdd-98)new york,ny.aaai press.)、(chawla,n.,bowyer,k.,hall,l.,&kegelmeyer,p.(2000).smote:synthetic minority over-sampling technique.in international conference of knowledge based com-puter systems,pp.46
–
57.national center for software technology,mumbai,india,allied press.)
7.上述两类方法着重的方向,使用的技术皆为不同。本发明基于第二类方法,本发明所提出的方法为非随机的,能准确的将多数的样例减少而同时控制少数的样例的减少,因此能同时保证auc不下降。
技术实现要素:
8.本申请所述的采样方法为非随机的算法,能精准的减少一类样例并同时控制另一类样例减少。相反于之前的方法使用随机的方式,随机的减少一类的样例,由于数据的极端不平衡,所需要减少的样例数量可能过大,使得机器学习的能力降低,在预测时不能准确的预测案例为正或反。随机的重复少量样本的个数来平衡训练集,也会使机器学习只学习到同样的样例,而产生记忆而不是学习。
9.本申请所采用的技术方案如下:
10.一种金融电销场景中对负样本做消减的采样方法,具体步骤如下:
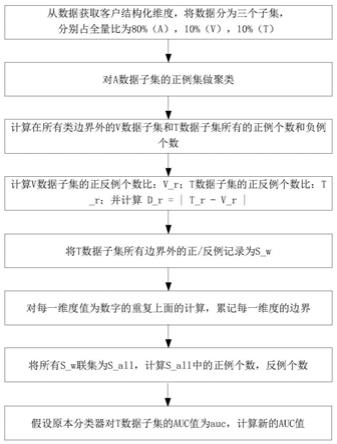
11.第一步、从金融场景营销的数据获取客户结构化维度,将数据分为三个子集,分别占全量比为80%(a),10%(v),10%(t);
12.第二步、对a数据子集的正例集做聚类,例如使用k-means或optics等聚类法,对数据集的单一一个维度做聚类;
13.第三步、计算在所有类边界外的v数据子集和t数据子集所有的正例个数和负例个数;
14.第四步、计算v数据子集的正反例个数比:v_r;t数据子集的正反例个数比:t_r;并计算d_r=|t_r-v_r|;
15.第五步:将t数据子集所有边界外的正/反例记录为s_w;
16.第六步:对每一维度值为数字的重复上面的计算,累记每一维度的边界;
17.第七步:将所有s_w联集为s_all,计算s_all中的正例个数,反例个数;
18.第八步:假设原本分类器对t数据子集的auc值为auc,计算新的auc值auc_new。
19.优选的,所述新的auc值的计算步骤如下:
20.设定t数据子集的样例数为t,其中正例个数为t_p,反例个数为t_n,设定s_all中的正例个数为p,反例个数为n,以及
21.x=p/t_p
22.y=n/t_n
23.所有p的正例与反例配对得分为0,即被视为错误分类—(1)
24.所有n的反例与正例配对得分为1,即被视为正确分类—(2)
25.上面的auc计算可以拆解为:
26.auc_new=s((t_p*(1-x)+x*t_p)*(t_n*(1-y)+y*t_n))/(t_p*t_n)
27.套入(1)和(2),和简化后
28.auc_new=(1-x)*(1-y)*auc+(1-x)*y+0.5*x*y。
29.与现有方法相比,本申请具有以下优势:
30.(1)使用网上公开的数据集,上述的算法可以有校的提升auc,例如拍拍贷的数据集(https://github.com/wepe/ppd_riskcontrolcompetition/),证明了smote的下样本方法对最终auc没有帮助,使用本申请的算法可以对数据集的最高auc再提升0.7%。
31.(2)在金融电销场景中对负样本做消减:使用聚类的方式对每一维度做正例的聚类,找出边界,将边界外的样例除去以降低负例样本。
32.(3)本发明所提出的方法为非随机的,能准确的将多数的样例减少而同时控制少数的样例的减少,因此能同时保证auc不下降。
附图说明
33.图1维度聚类边界说明图;
34.图2本申请采样方法流程图。
具体实施方式
35.下面结合附图和具体实施方式对本发明作进一步详细的说明。
36.模型评价标准:采用auc来评价模型的效果。auc即以falsepositiverate为横轴,truepositiverate为纵轴的roc(receiveroperatingcharacteristic)curve下方的面积的大小。
[0037][0038]
m为正样本个数,n为负样本个数,m
×
n为正负样本对的个数。s
i
为第i个正负样本对的得分,定义如下:
[0039][0040]
参见附图1、2所示,本发明具体实施流程步骤如下:
[0041]
一种金融电销场景中对负样本做消减的采样方法,具体步骤如下:
[0042]
第一步、从金融场景营销的数据获取客户结构化维度,将数据分为三个子集,分别占全量比为80%(a),10%(v),10%(t);
[0043]
第二步、对a数据子集的正例集做聚类,例如使用k-means或optics等聚类法,对数据集的单一一个维度做聚类;
[0044]
第三步、计算在所有类边界外的v数据子集和t数据子集所有的正例个数和负例个数;
[0045]
第四步、计算v数据子集的正反例个数比:v_r;t数据子集的正反例个数比:t_r;并计算d_r=|t_r-v_r|;
[0046]
第五步:将t数据子集所有边界外的正/反例记录为s_w;
[0047]
第六步:对每一维度值为数字的重复上面的计算,累记每一维度的边界;
[0048]
第七步:将所有s_w联集为s_all,计算s_all中的正例个数,反例个数;
[0049]
第八步:假设原本分类器对t数据子集的auc值为auc,计算新的auc值auc_new。
[0050]
其中,auc值的计算步骤如下:
[0051]
设定t数据子集的样例数为t,其中正例个数为t_p,反例个数为t_n,设定s_all中的正例个数为p,反例个数为n,以及
[0052]
x=p/t_p
[0053]
y=n/t_n
[0054]
所有p的正例与反例配对得分为0,即被视为错误分类—(1)
[0055]
所有n的反例与正例配对得分为1,即被视为正确分类.—(2)
[0056]
上面的auc计算可以拆解为:
[0057]
auc_new=s((t_p*(1-x)+x*t_p)*(t_n*(1-y)+y*t_n))/(t_p*t_n)
[0058]
套入(1)和(2),和简化后
[0059]
auc_new=(1-x)*(1-y)*auc+(1-x)*y+0.5*x*y
[0060]
当x趋近0时,
[0061]
auc_new~(1-y)*auc+y=auc+(1-auc)*y>auc
[0062]
所以如果能尽量的除去负例而不消去正例,则auc必定增高。当数据量够大,能够捕捉住数据的常态分布时,也就是a集能够捕捉所有正例的分布,上述的算法即能极少量的去除正例,而大量的除去负例。
[0063]
与现有方法相比,本申请具有以下优势:
[0064]
(1)使用网上公开的数据集,上述的算法可以有校的提升auc,例如拍拍贷的数据集(https://github.com/wepe/ppd_riskcontrolcompetition/),证明了smote的下样本方法对最终auc没有帮助,使用本申请的算法可以对数据集的最高auc再提升0.7%。
[0065]
(2)在金融电销场景中对负样本做消减:使用聚类的方式对每一维度做正例的聚类,找出边界,将边界外的样例除去以降低负例样本。
[0066]
(3)本发明所提出的方法为非随机的,能准确的将多数的样例减少而同时控制少数的样例的减少,因此能同时保证auc不下降。
[0067]
以上所述之实施例仅为本发明的较佳实施例,并非对本发明做任何形式上的限制。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,利用上述揭示的技术内容对本发明技术方案作出更多可能的变动和润饰,或修改均为本发明的等效实施例。故凡未脱离本发明技术方案的内容,依据本发明之思路所作的等同等效变化,均应涵盖于本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1