一种用于数值型数据的智能异常检测方法及装置与流程
[0001]
本发明涉及异常检测领域,尤其涉及一种用于数值型数据的智能异常检测方法及装置。
背景技术:
[0002]
异常检测,是从给定数据集中检测出特征或行为不同于预期的对象的过程,这种对象称为异常或离群。异常点检测的应用场景很多,但是目前尚未有一个较为智能的系统或方法,可以根据数据情况自主向用户推荐异常检测解决方案。
技术实现要素:
[0003]
针对现有技术中存在的不足,本发明提供了一种用于数值型数据的智能异常检测方法,包括以下步骤:
[0004]
步骤一:上传数据阶段读取用户上传数据的表头,获得数据内容;
[0005]
步骤二:将步骤一中上传的数据与数据池中的数据比对,根据数据特征分布进行分类整理,形成数据池子模块;
[0006]
步骤三:冷启动情况下,算法池阶段根据一定规则推荐适合当前数据的算法,用户在系统筛选出的算法中二次选择需要搭配使用的算法;热启动情况下,推荐该数据集所属数据池子模块中其余数据集在算法池中的最优算法搭配;
[0007]
步骤四:算法结果集成阶段将步骤三中各算法得出的离群度进行集成;
[0008]
步骤五:根据步骤四计算得到的离群度对步骤一的上传数据进行异常点判定;
[0009]
步骤六:对步骤五异常点判定的检测结果进行可视化展示。
[0010]
进一步的,所述步骤二通过以下子步骤来实现:
[0011]
2.1根据上传数据是否含有标签将其分为有监督数据集和无监督数据集;
[0012]
2.2对于有监督数据集,将特征维度跨越幅度较小的数据集归为一类,必要时对上传的数据进行降维处理;将有监督数据集中边缘分布距离小于阈值的样本归为一类,将条件分布距离小于阈值的样本归为另一类;
[0013]
2.3对于无监督数据集,将特征维度跨越幅度较小的数据集归为一类,必要时对上传的数据进行降维处理;将无监督数据集中边缘分布距离小于阈值的样本归为一类。
[0014]
进一步的,所述步骤三通过以下子步骤来实现:
[0015]
3.1冷启动时,综合数据有无标签与数据维度的情况,筛选出适合的算法;将筛选出的算法展示到界面上,供用户二次筛选;
[0016]
3.2热启动时,若在步骤二中匹配到同类数据,则跳过上述筛选步骤,直接向用户推荐同类数据历史常用算法,供用户二次筛选。
[0017]
进一步的,所述步骤四通过以下子步骤来实现:
[0018]
4.1使用步骤三中筛选出的算法,依次对原数据做处理并计算得出每个数据对应的离群度;
[0019]
4.2对每一种算法得出的全部数据的离群度做归一化处理;
[0020]
4.3冷启动环境下,对同一个数据不同算法求得的离群度取均值,作为最终离群度;
[0021]
4.4热启动环境下,根据数据池同一子模块中其余数据集中相似数据集赋予本次训练部分数据一组初始离群度标签,调整本次数据所使用的检测算法,利用神经网络计算每种算法的预期权重,并将权重结果(kernel)保存至算法池中的参数模块,利用各算法的权重对所有离群度进行加权集成并得到最终离群度,其中,权重结果(kernel)可反复利用并反复迭代以达到更优的效果。
[0022]
进一步的,所述步骤五通过以下子步骤来实现:
[0023]
5.1冷启动环境下,用户可从阈值法、topn法中选择一种方法对步骤四集成的离群度进行异常点判定,异常点判定阶段同时学习在该种数据下的异常点判定的模式;
[0024]
结合cantelli不等式推荐阈值与topn值,具体为:
[0025][0026]
其中,prob表示概率,y
i
表示步骤四中第i个算法计算出的离群度值,μ为步骤四集成的离群度的均值,δ为步骤四集成的离群度的方差,a是δ的倍数,以0.2的概率计算出阈值并以此为推荐阈值,同时以此阈值计算出推荐topn值;
[0027]
5.2热启动环境下,若在步骤二中匹配到同类数据,则异常点判定阶段使用已经学到的异常点判定模式对对步骤四集成的离群度进行异常点判定;同时用户也可如冷启动模式,自由选择异常点判定方法对对步骤四集成的离群度进行判定。
[0028]
进一步的,所述步骤六通过以下过程来实现:
[0029]
通过表格与柱状图,按照离群度从大到小的排序展示原数据及其对应的离群度;对于三维及以下的数据,额外绘制散点图并使用红色将异常点标记出来;同时对图表进行联动设计,选中表格中的单个数据时,柱状图与散点图会对选中点做高亮显示。
[0030]
本发明还提供了一种数值型数据的智能异常检测装置,自上而下包括:
[0031]
任务层,表示本装置适用的任务场景;
[0032]
热启动过程与冷启动过程,热启动过程包含数据池与算法池两部分,其中数据池包含含有相同特征数据的数据模块,算法池包含算法模块及其对应的参数,每种数据模块指向算法池中适合当前数据的多个算法模块;冷启动过程则通过数据类型、数据维度和人为经验判定的离群度量方式来筛选出合适的算法;两种启动过程完成后得到对应数据的多个离群度值;
[0033]
异常检测层,对冷、热启动过程后的得到的离群度值进行处理,将多个离群度值集成为最终离群度后,根据最终离群度,对数据中的异常点进行判定;
[0034]
服务器层,异常检测的结果通过服务器反馈给用户。
[0035]
本发明的有益效果是:本发明是面向异常检测领域的用于数值型数据的智能异常检测方法,具有如下特点:
[0036]
(1)本发明提出了一种智能异常检测方法。通过智能的流程设计,极大地优化了异常检测的流程,降低了异常检测的使用门槛,以及能够在更短的时间内得到更好的异常检测效果。
[0037]
(2)本发明中涉及的数据池部分,基于一定的策略对数据进行分类,以便后续过程对同类的数据进行模式复用,为用户提供先验经验的同时提高了异常检测的运行效率。
[0038]
(3)本发明中涉及的算法结果集成部分,通过对算法权重的复用与多次迭代,能够达到更好的异常检测效果,极大地提高了异常检测效率。
附图说明
[0039]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍。
[0040]
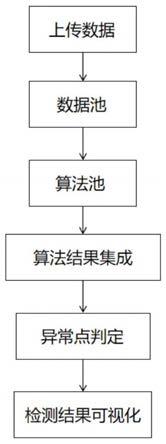
图1为本发明的方法流程图。
[0041]
图2为本发明的冷启动情况下算法选择部分的逻辑示意图。
[0042]
图3为本发明的冷启动情况下的离群度集成部分的逻辑示意图。
[0043]
图4为本发明的热启动情况下的离群度集成部分的逻辑示意图。
[0044]
图5为本发明的热启动过程中权重结果(kernel)更新过程的逻辑示意图。
[0045]
图6为本发明的用于数值型数据的智能异常检测装置框架图。
具体实施方式
[0046]
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释被发明,并非用于限定本发明的范围。
[0047]
如图1所示,本发明的用于数值型数据的智能异常检测方法,包括:上传数据阶段,实现数据上传,读取用户上传数据的表头与读取数据内容,并将读取内容传输至数据池;数据池阶段,实现数据存储与数据比对;算法池阶段,实现系统智能推荐多种适合当前数据的异常检测算法;算法结果集成阶段,实现汇总各算法的计算结果并得出最终计算结果;异常点判定阶段,实现自主选择异常点判定方法并做出判定;检测结果可视化阶段,实现可视化直观展示数据尤其是异常点。
[0048]
用于数值型数据的智能异常检测方法,具体包括以下步骤:
[0049]
步骤一:上传数据阶段读取用户上传数据的表头,获得数据内容;
[0050]
步骤二:将步骤一中上传的数据与数据池中的数据比对,根据其数据特征分布进行分类整理,形成数据池子模块;
[0051]
步骤三:冷启动情况下,算法池阶段根据一定规则推荐适合当前数据的算法,用户可在系统筛选出的算法中二次选择需要搭配使用的算法;热启动情况下,推荐该数据集所属数据池子模块中其余数据集在算法池中的最优算法搭配;
[0052]
步骤四:算法结果集成阶段将步骤三中各算法得出的离群度进行集成;
[0053]
步骤五:根据步骤四计算得到的离群度对步骤一的上传数据进行异常点判定;
[0054]
步骤六:对步骤五异常点判定的检测结果进行可视化的展示。
[0055]
所述数据池阶段,数据池由不同类型的子模块组成,子模块之间存在特征分布差异。根据上传数据是否含有标签将其分为有监督数据集和无监督数据集;对于有监督数据集,将特征维度跨越幅度较小的数据集归为一类,必要时对上传的数据进行降维处理;将有监督数据集中边缘分布距离小于阈值的样本归为一类,将条件分布距离小于阈值的样本归为另一类。对于无监督数据集,将特征维度跨越幅度较小的数据集归为一类,必要时对上传
的数据进行降维处理;将无监督数据集中边缘分布距离小于阈值的样本归为一类。
[0056]
所述算法池模块,当数据在数据池中匹配到同类数据时,系统自动推荐适合此类数据的算法供用户二次筛选;当数据未在数据池中匹配到同类数据时,系统自主选择算法过程如图2所示:首先判断数据是否含有标签,随后确定数据维度(如进行过降维操作,则以降维后的维度为准),综合数据有无标签与数据维度的情况,筛选出适合的算法。
[0057]
所述算法结果集成阶段,冷启动情况下的离群度集成基本实现如图3所示:首先使用从算法池中最终选定的m个算法对用户上传的数据求出m个离群度,接着对每一种算法得出的全部数据的离群度做归一化处理,最后对同一个数据不同算法求得的离群度取均值,从而求得每条数据的最终离群度。热启动情况下的离群度集成如图4所示:首先使用从算法池中最终选定的m个算法对用户上传的数据求出m个离群度,接着对每一种算法得出的全部数据的离群度做归一化处理,最后使用已知权重结果(kernel)对算法结果进行加权集成,从而求得每条数据的最终离群度。热启动过程中,权重结果(kernel)更新过程如图5所示:离群度归一化完成后,若有k个原数据可以在数据池子模块中匹配到临近点,则以这k个原数据的离群度为输入,对应临近点的离群度为训练目标,结合算法对应kernel,进入神经网络对kernel进行优化并将新的kernel更新到算法池子模块中。
[0058]
所述异常点判定阶段,冷启动环境下,用户可从阈值法、topn法中选择一种方法对步骤四集成的离群度进行异常点判定,异常点判定阶段同时学习在该种数据下的异常点判定的模式。结合cantelli不等式推荐阈值与topn值,具体为:
[0059][0060]
其中,prob表示概率,y
i
表示步骤四中第i个算法计算出的离群度值,μ为步骤四集成的离群度的均值,δ为步骤四集成的离群度的方差,a是δ的倍数,以0.2的概率计算出阈值并以此为推荐阈值,同时以此阈值计算出推荐topn值。热启动环境下,若在步骤二中匹配到同类数据,则异常点判定阶段使用已经学到的异常点判定模式对对步骤四集成的离群度进行异常点判定;同时用户也可如冷启动模式,自由选择异常点判定方法对对步骤四集成的离群度进行判定。
[0061]
所述检测结果可视化阶段,通过表格与柱状图,按照离群度从大到小的排序展示原数据及其对应的离群度。同时,对于三维及以下的数据,会额外绘制散点图并使用红色将异常点标记出来。同时对图表进行联动设计,选中表格中的单个数据时,柱状图与散点图会对选中点做高亮显示。
[0062]
如图6所示,本发明的数值型数据的智能异常检测装置,采用自上而下采用如下构建方式:
[0063]
最上层为任务层,表示本装置适用的任务场景。
[0064]
任务层之下分为热启动过程与冷启动过程。热启动过程包含数据池与算法池两部分,其中数据池包含含有相同特征数据的数据模块,算法池包含算法模块及其对应的参数,每种数据模块指向算法池中适合当前数据的多个算法模块。冷启动过程则通过数据类型、数据维度和人为经验判定的离群度量方式来筛选出合适的算法。两种启动过程完成后可以得到对应数据的多个离群度值。
[0065]
异常检测层对冷、热启动过程后的得到的数据离群度值进行处理。将多个离群度
值通过一定的方法集成为最终离群度后,根据最终离群度,对数据中的异常点进行判定。
[0066]
服务器层,异常检测的结果通过服务器反馈给用户。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1