一种可行驶区域的检测方法及装置与流程
本发明涉及图像处理技术领域,更具体的说,涉及一种可行驶区域的检测方法及装置。
背景技术:
可行驶区域(freespace)检测技术是辅助驾驶系统和自动驾驶系统的关键技术。现有技术中,可行驶区域的检测方法为:对车辆摄像头采集的图像按照不同的物体分割成不同区域,然后从分割的区域中识别出可行驶区域。
由于传统方案在进行区域分割时,不仅对物体边界点进行标注,还对物体边界点内部区域进行标注,因此不仅需要花费较长时间,而且还需要复杂的后续处理,才能得到可行驶区域的边界信息,后续处理比如,对区域边缘进行提取以及对不同区域边缘重叠部分的归类,等等。
技术实现要素:
有鉴于此,本发明公开一种可行驶区域的检测方法及装置,在进行可行驶区域识别时,仅将目标对象和地面的接触点作为标注点进行标注,因此省去的大量的标注工作,从而不仅缩短了标注时间,而且在一定程度上减少了标注的后续处理工作量,进而提高了对可行驶区域的检测效率。
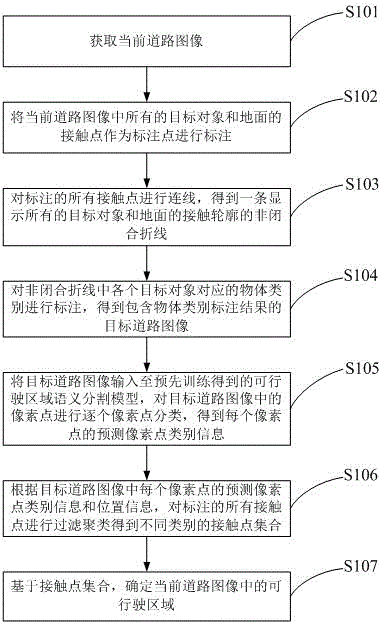
一种可行驶区域的检测方法,包括:
获取当前道路图像;
将所述当前道路图像中所有的目标对象和地面的接触点作为标注点进行标注;
对标注的所有接触点进行连线,得到一条显示所有的所述目标对象和所述地面的接触轮廓的非闭合折线;
对所述非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像;
将所述目标道路图像输入至预先训练得到的可行驶区域语义分割模型,对所述目标道路图像中的像素点进行逐个像素点分类,得到每个所述像素点的预测像素点类别信息;
根据所述目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合;
基于所述接触点集合,确定所述当前道路图像中的可行驶区域。
可选的,所述可行驶区域语义分割模型的训练过程包括:
将包含物体类别标注结果的道路图像作为模型输入的原图像,生成和所述原图像相同图像大小的真值图像,其中,所述真值图像中的每个像素点记录的是该像素点被标注的像素点类别信息;
将所述原图像作为训练样本,将所述真值图像作为样本标签,对深度学习模型进行训练得到可行驶区域语义分割模型。
可选的,所述像素点类别信息包括:车辆、行人、马路牙子、栅栏和非接触点。
可选的,所述基于所述接触点集合,确定所述当前道路图像中的可行驶区域,具体包括:
对所述接触点集合进行平滑滤波,得到所述当前道路图像中可行驶边界点序列和每个可行驶边界点对应的像素点坐标;
将每个所述可行驶边界点对应的像素点坐标转换到世界坐标系下,得到每个所述可行驶边界点的目标像素点坐标;
基于所述目标像素点坐标,将所述可行驶边界点序列连接成所述当前道路图像中可行驶区域的封闭曲线;
采用激光雷达辐射方式,从所述封闭曲线中采样出预设数量的距离本车辆最近的边界点作为目标边界点,并输出有所述目标边界点形成的所述可行驶区域。
一种可行驶区域的检测装置,包括:
获取单元,用于获取当前道路图像;
第一标注单元,用于将所述当前道路图像中所有的目标对象和地面的接触点作为标注点进行标注;
连线单元,用于对标注的所有接触点进行连线,得到一条显示所有的所述目标对象和所述地面的接触轮廓的非闭合折线;
第二标注单元,用于对所述非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像;
像素点分类单元,用于将所述目标道路图像输入至预先训练得到的可行驶区域语义分割模型,对所述目标道路图像中的像素点进行逐个像素点分类,得到每个所述像素点的预测像素点类别信息;
过滤聚类单元,用于根据所述目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合;
可行驶区域确定单元,用于基于所述接触点集合,确定所述当前道路图像中的可行驶区域。
可选的,还包括:模型训练单元;
所述模型训练单元具体用于:
将包含物体类别标注结果的道路图像作为模型输入的原图像,生成和所述原图像相同图像大小的真值图像,其中,所述真值图像中的每个像素点记录的是该像素点被标注的像素点类别信息;
将所述原图像作为训练样本,将所述真值图像作为样本标签,对深度学习模型进行训练得到可行驶区域语义分割模型。
可选的,所述像素点类别信息包括:车辆、行人、马路牙子、栅栏和非接触点。
可选的,所述可行驶区域确定单元具体包括:
平滑滤波子单元,用于对所述接触点集合进行平滑滤波,得到所述当前道路图像中可行驶边界点序列和每个可行驶边界点对应的像素点坐标;
坐标转换子单元,用于将每个所述可行驶边界点对应的像素点坐标转换到世界坐标系下,得到每个所述可行驶边界点的目标像素点坐标;
连接子单元,用于基于所述目标像素点坐标,将所述可行驶边界点序列连接成所述当前道路图像中可行驶区域的封闭曲线;
采样子单元,用于采用激光雷达辐射方式,从所述封闭曲线中采样出预设数量的距离本车辆最近的边界点作为目标边界点,并输出有所述目标边界点形成的所述可行驶区域。
从上述的技术方案可知,本发明公开了一种可行驶区域的检测方法及装置,将获取的当前道路图像中所有目标对象和地面的接触点作为标注点进行标注,对标注的所有接触点进行连线,得到一条显示所有的目标对象和地面的接触轮廓的非闭合折线,对非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像,将目标道路图像输入至可行驶区域语义分割模型,对目标道路图像中的像素点进行逐个像素点分类,得到每个像素点的预测像素点类别信息,根据目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合,基于接触点集合,确定当前道路图像中的可行驶区域。由此可以看出,本发明在进行可行驶区域识别时,仅将目标对象和地面的接触点作为标注点进行标注,因此,相对于传统方案将物体边界点以及边界点内部区域均作为标注点进行标注而言,本发明省去的大量的标注工作,从而不仅缩短了标注时间,而且在一定程度上减少了标注的后续处理工作量,进而提高了对可行驶区域的检测效率。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据公开的附图获得其他的附图。
图1为本发明实施例公开的一种可行驶区域的检测方法流程图;
图2为本发明实施例公开的一种基于接触点集合确定当前道路图像中的可行驶区域的方法流程图;
图3为本发明实施例公开的一种可行驶区域的检测装置的结构示意图;
图4为本发明实施例公开的一种可行驶区域确定单元的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
参见图1,本发明实施例公开的一种可行驶区域的检测方法流程图,该方法包括:
步骤s101、获取当前道路图像;
在实际应用中,可以通过安装在车辆上的摄像头采集当前道路图像。
步骤s102、将所述当前道路图像中所有的目标对象和地面的接触点作为标注点进行标注;
其中,目标对象包括:车辆、行人、马路牙子和栅栏等。
需要说明的是,相对于传统方案将物体边界点以及边界点内部区域均作为标注点进行标注而言,本发明仅将目标对象和地面的接触点作为标注点进行标注,从而省去了大量的标注工作。
本发明将目标对象和地面的接触点作为标注点进行标注,而不是将目标对象的边界点进行标注的原因为:便于后续测距方便。若标注作为目标对象的标注物体,那么,当标注物体的边界点不在地面上时,在测距的过程中会出现偏差。在自动驾驶领域,地面通常作为一个可靠的参考物,基于此,本发明将目标对象和地面的接触点作为标注点进行标注。
步骤s103、对标注的所有接触点进行连线,得到一条显示所有的所述目标对象和所述地面的接触轮廓的非闭合折线;
需要说明的是,非闭合折线指的是:所有标注点连线的头尾未相连。
那么,与非闭合折线对应的闭合折线指的是:所有标注点连线的头尾相连,比如现有技术中对某一区域标注的所有点的连线。
步骤s104、对所述非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像;
其中,标注的物体类别包括:车辆、行人、马路牙子和栅栏等。
步骤s105、将所述目标道路图像输入至预先训练得到的可行驶区域语义分割模型,对所述目标道路图像中的像素点进行逐个像素点分类,得到每个所述像素点的预测像素点类别信息;
其中,预测像素点类别信息包括:车辆、行人、马路牙子、栅栏和非接触点。由于标注时只标注车辆、行人、马路牙子、栅栏与地面的接触点,因此其他未被标注的像素点都自动归为非接触点。
步骤s106、根据所述目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合;
需要说明的是,当确定目标道路图像中每个像素点的预测像素点类别信息和位置信息后,即可确定标注的所有接触点相对应的预测像素点类别信息,从而得到各个接触点的类别预测信息。对相同类别的像素点预测信息的接触点进行聚类,即可得到各个不同类别的接触点集合。
步骤s107、基于所述接触点集合,确定所述当前道路图像中的可行驶区域。
在得到不同类别的接触点集合后,即可对当前道路图像中的各个区域进行识别,从而可以确定可行驶区域。
综上可知,本发明公开的可行驶区域的检测方法,将获取的当前道路图像中所有目标对象和地面的接触点作为标注点进行标注,对标注的所有接触点进行连线,得到一条显示所有的目标对象和地面的接触轮廓的非闭合折线,对非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像,将目标道路图像输入至可行驶区域语义分割模型,对目标道路图像中的像素点进行逐个像素点分类,得到每个像素点的预测像素点类别信息,根据目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合,基于接触点集合,确定当前道路图像中的可行驶区域。由此可以看出,本发明在进行可行驶区域识别时,仅将目标对象和地面的接触点作为标注点进行标注,因此,相对于传统方案将物体边界点以及边界点内部区域均作为标注点进行标注而言,本发明省去的大量的标注工作,从而不仅缩短了标注时间,而且在一定程度上减少了标注的后续处理工作量,进而提高了对可行驶区域的检测效率。
为进一步优化上述实施例,本发明还提供了可行驶区域语义分割模型的训练过程,具体如下:
按照步骤s102~步骤s104对道路图像进行物体类别标注。
(1)将包含物体类别标注结果的道路图像作为模型输入的原图像,生成和所述原图像相同图像大小的真值图像;
其中,所述真值图像中的每个像素点记录的是该像素点被标注的像素点类别信息。
需要说明的是,不同的像素点类别具有不同的像素点类别信息,像素点类别信息包括:车辆、行人、马路牙子、栅栏和非接触点。由于标注时只标注车辆、行人、马路牙子、栅栏与地面的接触点,因此其他未被标注的像素点都自动归为非接触点。
(2)将所述原图像作为训练样本,将所述真值图像作为样本标签,对深度学习模型进行训练得到可行驶区域语义分割模型。
其中,可行驶区域语义分割模型用于对原图像进行逐个像素点分类,得到每个像素点的预测像素点类别信息。
基于上述论述可知,可行驶区域语义分割模型为使用深度学习模型对样本图像进行语义分割训练后得到。
在获取可行驶区域的语义分割模型的训练样本时,本发明采集了4个主要城市,多个场景共100小时时长的车辆摄像头采集的道路视频数据,对所有的道路视频数据进行随机采样,生成100000的图像池,根据业务需求从图像池中选择出50000个图像作为训练样本,其中,训练样本中的图像需要尽量包含多场景的数据,比如,不同城市道路、不同天气、不同时间段,等等。与此同时,训练样本也需要考虑多物体类别之间的平衡。
其中,在进行模型训练之前,本发明对训练样本中的各个图像进行物体对象边缘标注,比如,对高道路边缘、低道路边缘、行人边缘、骑行人边缘,车辆边缘和路障边缘分别进行了标注。
本发明在进行模型训练时,采用的是pytorch平台,在多个服务器上实现多机多卡训练。其中,采用了u-shape的分割框架,结合预设计的主干网络得到可行驶区域检测模型。
需要说明的是,在实际应用中,本发明结合膨胀卷积和可分离卷积设计了主干网络,该主干网络就有更大视野和轻量化的特点。
采用非对称的u-shape编码解析网络结构,提升可行驶区域的语义分割模型对空间和语义信息的感知能力。
增加目标区域、随机反转、随机裁剪和随机阴影叠加等数据增强方式提升模型泛化能力
借助dice-loss,增加模型对分割区域的约束能力,并提高分割精度。
借助ohem(在线困难样本挖掘),提升模型对逐像素的分类能力,提升识别精度。
为进一步优化上述实施例,参见图2,本发明实施例公开的一种基于接触点集合确定当前道路图像中的可行驶区域的方法流程图,也即,图1所示实施例中的步骤s107具体可以包括:
步骤s201、对接触点集合进行平滑滤波,得到当前道路图像中可行驶边界点序列和每个可行驶边界点对应的像素点坐标;
步骤s202、将每个所述可行驶边界点对应的像素点坐标转换到世界坐标系下,得到每个所述可行驶边界点的目标像素点坐标;
步骤s203、基于所述目标像素点坐标,将所述可行驶边界点序列连接成所述当前道路图像中可行驶区域的封闭曲线;
步骤s204、采用激光雷达辐射方式,从所述封闭曲线中采样出预设数量的距离本车辆最近的边界点作为目标边界点,并输出有所述目标边界点形成的可行驶区域。
与上述方法实施例相对应,本发明还公开了一种可行驶区域的检测装置。
参见图3,本发明实施例公开的一种可行驶区域的检测装置的结构示意图,该装置包括:
获取单元301,用于获取当前道路图像;
在实际应用中,可以通过安装在车辆上的摄像头采集当前道路图像。
第一标注单元302,用于将所述当前道路图像中所有的目标对象和地面的接触点作为标注点进行标注;
其中,目标对象包括:车辆、行人、马路牙子和栅栏等。
需要说明的是,相对于传统方案将物体边界点以及边界点内部区域均作为标注点进行标注而言,本发明仅将目标对象和地面的接触点作为标注点进行标注,从而省去了大量的标注工作。
本发明将目标对象和地面的接触点作为标注点进行标注,而不是将目标对象的边界点进行标注的原因为:便于后续测距方便。若标注作为目标对象的标注物体,那么,当标注物体的边界点不在地面上时,在测距的过程中会出现偏差。在自动驾驶领域,地面通常作为一个可靠的参考物,基于此,本发明将目标对象和地面的接触点作为标注点进行标注。
连线单元303,用于对标注的所有接触点进行连线,得到一条显示所有的所述目标对象和所述地面的接触轮廓的非闭合折线;
需要说明的是,非闭合折线指的是:所有标注点连线的头尾未相连。
那么,与非闭合折线对应的闭合折线指的是:所有标注点连线的头尾相连,比如现有技术中对某一区域标注的所有点的连线。
第二标注单元304,用于对所述非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像;
其中,标注的物体类别包括:车辆、行人、马路牙子和栅栏等。
像素点分类单元305,用于将所述目标道路图像输入至预先训练得到的可行驶区域语义分割模型,对所述目标道路图像中的像素点进行逐个像素点分类,得到每个所述像素点的预测像素点类别信息;
其中,预测像素点类别信息包括:车辆、行人、马路牙子、栅栏和非接触点。由于标注时只标注车辆、行人、马路牙子、栅栏与地面的接触点,因此其他未被标注的像素点都自动归为非接触点。
过滤聚类单元306,用于根据所述目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合;
需要说明的是,当确定目标道路图像中每个像素点的预测像素点类别信息和位置信息后,即可确定标注的所有接触点相对应的预测像素点类别信息,从而得到各个接触点的类别预测信息。对相同类别的像素点预测信息的接触点进行聚类,即可得到各个不同类别的接触点集合。
可行驶区域确定单元307,用于基于所述接触点集合,确定所述当前道路图像中的可行驶区域。
在得到不同类别的接触点集合后,即可对当前道路图像中的各个区域进行识别,从而可以确定可行驶区域。
综上可知,本发明公开的可行驶区域的检测装置,将获取的当前道路图像中所有目标对象和地面的接触点作为标注点进行标注,对标注的所有接触点进行连线,得到一条显示所有的目标对象和地面的接触轮廓的非闭合折线,对非闭合折线中各个目标对象对应的物体类别进行标注,得到包含物体类别标注结果的目标道路图像,将目标道路图像输入至可行驶区域语义分割模型,对目标道路图像中的像素点进行逐个像素点分类,得到每个像素点的预测像素点类别信息,根据目标道路图像中每个像素点的预测像素点类别信息和位置信息,对标注的所有接触点进行过滤聚类,得到不同类别的接触点集合,基于接触点集合,确定当前道路图像中的可行驶区域。由此可以看出,本发明在进行可行驶区域识别时,仅将目标对象和地面的接触点作为标注点进行标注,因此,相对于传统方案将物体边界点以及边界点内部区域均作为标注点进行标注而言,本发明省去的大量的标注工作,从而不仅缩短了标注时间,而且在一定程度上减少了标注的后续处理工作量,进而提高了对可行驶区域的检测效率。
为进一步优化上述实施例,本发明还提供了可行驶区域语义分割模型的训练过程,检测装置还可以包括:模型训练单元;
所述模型训练单元具体用于:
将包含物体类别标注结果的道路图像作为模型输入的原图像,生成和所述原图像相同图像大小的真值图像,其中,所述真值图像中的每个像素点记录的是该像素点被标注的像素点类别信息;
将所述原图像作为训练样本,将所述真值图像作为样本标签,对深度学习模型进行训练得到可行驶区域语义分割模型。
其中,可行驶区域语义分割模型用于对原图像进行逐个像素点分类,得到每个像素点的预测像素点类别信息。
基于上述论述可知,可行驶区域语义分割模型为使用深度学习模型对样本图像进行语义分割训练后得到。
为进一步优化上述实施例,参见图4,本发明实施例公开的一种可行驶区域确定单元的结构示意图,可行驶区域确定单元包括:
平滑滤波子单元401,用于对所述接触点集合进行平滑滤波,得到所述当前道路图像中可行驶边界点序列和每个可行驶边界点对应的像素点坐标;
坐标转换子单元402,用于将每个所述可行驶边界点对应的像素点坐标转换到世界坐标系下,得到每个所述可行驶边界点的目标像素点坐标;
连接子单元403,用于基于所述目标像素点坐标,将所述可行驶边界点序列连接成所述当前道路图像中可行驶区域的封闭曲线;
采样子单元404,用于采用激光雷达辐射方式,从所述封闭曲线中采样出预设数量的距离本车辆最近的边界点作为目标边界点,并输出有所述目标边界点形成的所述可行驶区域。
需要说明的是,装置实施例中各组成部分的工作原理请参见方法实施例对应部分,此处不再赘述。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!